これは何?
競技プログラミングをPythonでやるときに注意すべき点をまとめました。
numbaやcythonについてはあまり触れないので、別の記事も併せてご利用ください。
言語選択編
PythonがAtCoderには5種類ある
AtCoderにはPythonの処理系が5つ入っています。具体的には
- Python (CPython 3.11.4)
- Python (Mambaforge / CPython 3.10.10)
- Python (PyPy 3.10-v7.3.12)
- Python (Cython 0.29.34)
- SageMath (SageMath 9.5)
の5つです。それぞれ特徴があります。
Python (CPython 3.11.4)
一番オーソドックスなPythonです。
一般に(競プロ界隈でなく)Pythonというときはこれを指すと思います。
Python (Mambaforge / CPython 3.10.10)
mambaforge経由で導入されたpythonです。
もともと、numbaというライブラリがまだ最新バージョンのCPythonに対応していないということで用意されたバージョンでした。(が、numbaは言語アップデートの間にPython3.11に対応しました...)
インストール方法によってNumPyが内部に使う数値計算ライブラリが異なり、conda経由のほうがpip経由よりも高速なライブラリが用いられるということでmambaforge経由でのインストールがなされているようです。
Python (PyPy 3.10-v7.3.12)
PyPyはRPythonによって記述されているPythonの処理系です。
競プロerがPythonと言うとき、このPyPyを指していることも少なくないです。
JITコンパイルを用いており、普通のCPythonよりも(一部の例外を除き、)非常に高速です。CPythonで動くコードはPyPyでも変更なしで動作することが(少なくとも競技プログラミングの範囲では)ほとんどであり、コードの書き換えをすることなく高速化を行うことができます。
Python (Cython 0.29.34)
CythonはPythonにC言語やC++の型を追加したような言語で、元々Python向けのライブラリを作るために開発されました。
実行前にC言語やC++を経由してコンパイルされるため適切な記述をすればC言語やC++と同等の速度を出すことができる言語です。が、適切な書き方をしないとpythonと同等程度の速度しか出ないため、pythonのコードをそのままC言語同等の速度にできるというわけではないです。
SageMath (SageMath 9.5)
2023年にAtCoderで行われた言語アップデートで新たに追加された言語です。
Pythonが内部で利用されているソフトウェアで、多様な数学ライブラリを用いることができます。
競技プログラミング的には起動時のオーバーヘッドが非常に大きく、処理を一切しなくても800ms程度の時間が起動時にかかってしまうため常用は厳しそうである一方で、ライブラリは非常に強力でありライブラリを使いこなせたら強い、そんな言語です。
で、どれで出せばよいの?
基本的にpythonで競技プログラミングをするときはPyPyで提出をすればよいです。
CPythonやmambaforge、Sagemathは基本的に遅いですし、Cythonは特殊な書き方をしないと速くないためです。
が、いくつか例外が存在します。それを紹介していきます。
PyPyの再帰関数は遅い
PyPyで再帰関数を書くと、CPythonよりも遅くなることがあります。
たとえば、こちらのケースでは再帰関数を用いた同じコードをPyPyとCPythonで提出していますが、CPythonではそこそこの余裕をもってACしているのに対して、PyPyではTLEしてしましました。
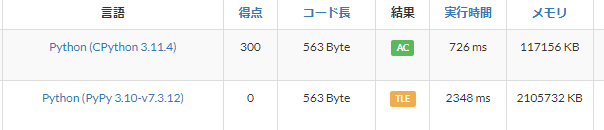
では、どのように対策をすればよいのでしょうか。
1.CPythonで提出する
前述したとおり、再帰関数に関してはPyPyよりもCPythonのほうが一般に高速であるといわれています。
しかし、CPythonも高速な言語ではないため、これでもTLEしてしまうようなケースも存在します。
2.PyPyの"おまじない"を書く
import pypyjit
pypyjit.set_param("max_unroll_recursion=-1")
を書くと、pypyでも再帰関数がある程度速くなると言われています。
試しに上でTLEしてしまったコードを投げてみましょう
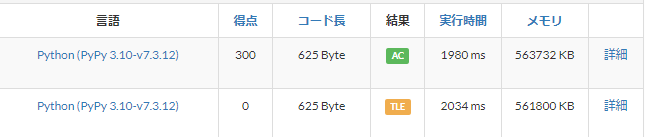
......確かに速くなっていますし、二回同じものを投げたらACできたのですが、コンテスト中に使うには抵抗のある遅さですね...
ほかにも、ローカル環境にpypyを入れていないとローカルでコードを試すときにエラーが出てしまったり、再帰関数以外の時にこれを書くと実行が遅くなるなどの注意点があります。
3.再帰関数用デコレータを用いる
再帰関数をジェネレーターで書いて、専用のデコレータを用いて呼び出すことで、PyPyでも高速に再帰をすることができるテクニックがあるようです。

上でTLEしてしまったPyPyのコードもこのデコレータを用いるとなんと728msで処理が終了しました。
提出コード
このデコレータを用いるためには、再帰のreturnをyieldに変更することと、再帰内で自分自身を呼び出す部分の前にyieldを書く必要があります。
例えば、フィボナッチ数列などは、このように書きます
@bootstrap
def fib(x):
if x <= 2:
yield 1
else:
yield (yield fib(x-2)) + (yield fib(x-1))
少しの変更は必要ですが、PyPyでここまで再帰が速くなるのはすごいですね。
なお、深さがそこまで深くない計算においては、普通の再帰のほうが速いようです。
例えば、フィボナッチ数列を愚直に計算するコードはこのデコレータを用いないほうが10倍高速でした。
(情報を提供していただいたtitan23さん、ありがとうございます!)
4.再帰を使わずに書く
本末転倒なのですが、再帰を使わずにstackを用いて処理を書くと当然高速です。
簡単なDFSはBFSと同じ要領で書けますし、関数を抜けるときに処理しないといけないオイラーツアーなども工夫することで非再帰で記述することができます。
詳しくは、Kiri8128さんの記事が非常にわかりやすいのでこちらもご確認ください。
decimalが遅い
decimalというのは、Pythonの標準ライブラリで正確に小数を計算するためのライブラリです。
デフォルトの有効桁数は28桁で、誤差を気にしないといけないような問題もdecimalを使うと簡単にACできることもある強力で便利なライブラリです。
が、PyPyではこのdecimalを用いたコードの実行速度がCPythonに比べて非常に遅くなります。
対策として以下の二つが考えられます。
1.CPythonで出す
decimalはCPythonのほうが高速なので、CPythonで出しましょう。
2.整数で計算する
本末転倒ですね...
誤差を気にしなくてはいけないような問題は基本的にdecimalなどの特殊なライブラリを用いることなくACできることがほとんどです。整数で計算することはできないか、考えてみましょう。
外部ライブラリのimportや実行が遅い
ジャッジサーバーのpythonにはNumpyなどの非常に便利で強力なライブラリがたくさん搭載されています。が、それらは基本的にCPythonで実行されることを前提に作成されたものであるためPyPyから呼ぶと動作が低速になったり、importにかなりの時間がかかってしまうことがあります。
外部ライブラリを用いたいときはCPythonやmambaforgeを用いたほうがよいでしょう。
setの仕様がCpythonとPyPyで異なる
実はsetの仕様がCPythonとPyPyで異なります。
PyPyではsetの中身は挿入順となっていますが、Pythonではそうとは限りません。
これに限らず、PyPyとCPythonは若干仕様が異なる点があります。以下のサイトにまとまっています。
ライブラリのバージョン
言語によって搭載されているライブラリが違ったり、同じライブラリでも若干バージョンが異なるケースがあります。
詳しくはAtCoderの言語一覧からライブラリ欄をご覧ください。
参照編
リストのコピー
競技プログラミングをやっていると、リストを複製したいときがたまにあります。
では、以下のようなコードを書いてみましょう
A = [1,2,3]
B = A
A[1] = 100
print(A) #[1, 100, 3]
print(B) #[1, 100, 3]
Aが[1,100,3]になったのは良いですが、Bも[1,100,3]になってしまいました。なぜでしょうか?
実は、A = Bと書くと、AもBも同じリストを参照するようになります。同じリストなので、Aを変更したらBも変更されてしまったのですね。
詳しい話は、tatyamさんの以下の記事が図付きでわかりやすいです。
一次元配列の中身をコピーしたいときは、以下のようにすると良いです。
A = [1,2,3]
B = A[:]
A[1] = 100
print(A) #[1, 100, 3]
print(B) #[1, 2, 3]
想定通りの動作になりましたね!
リストに対してスライスを用いることで、新たなリストが生成されるため二つの参照する先のリストは別々のものとなり、Aを変更してもBが変更されなくなりました。
多次元配列のコピー / deepcopyは遅い
一次元配列のコピーはスライスを用いることで簡単にできることがわかりました。では、多次元配列はどうでしょうか。先ほどのコピーを用いてみましょう。
A = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
B = A[:]
A[1][1] = 100
print(A) #[[1, 2, 3], [4, 100, 6], [7, 8, 9]]
print(B) #[[1, 2, 3], [4, 100, 6], [7, 8, 9]]
どちらのリストも変更されてしまいました。
このコピー方法では、一番外のリストが別のリストになっていても、その内部で参照しているリストは一緒のものになってしまうのです。(つまり、浅いコピーです。) idを使ってみるとわかりやすいですね。
A = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
B = A[:]
print(id(A)) #139814505792256
print(id(B)) #139814505062592
print(id(A[1]))#139814505139008
print(id(B[1]))#139814505139008
リストの中身がintやstrのイミュータブルなオブジェクトであるなら問題はないですが、中身がリストである多次元配列ではこのように想定しない動作をしてしまいます。
では、どのようにすれば多次元配列を複製できるのでしょうか?
少し検索をすると出てくるのがcopy.deepcopy()です。こちらはオブジェクトを深いコピーでコピーしてくれる便利なライブラリです。
実際に先ほどのコードを下記のように書き換えると想定していた動作をすることでしょう。
import copy
A = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
B = copy.deepcopy(A)
A[1][1] = 100
print(A) #[[1, 2, 3], [4, 100, 6], [7, 8, 9]]
print(B) #[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
が、 このdeepcopyめちゃくちゃ遅いです...(実際にこれが原因でTLEする程に遅いです)
なぜ、そこまで遅いのか。pythonで参照のループが起きていないかというのをしっかりと調べるように実装されているらしく、多次元配列程度に使うには高級すぎるほど丁寧な実装がされているのです。
競技プログラミング以外では便利かもしれませんが、競技プログラミングにおいてはあまりに遅すぎるので使わないことを強く推奨します。
では、どうすればいいのでしょうか。中のリストがコピーされていないなら、中のリストからコピーすればいいのです。
A = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
B = [a[:] for a in A]
print(A) #[[1, 2, 3], [4, 100, 6], [7, 8, 9]]
print(B) #[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
リスト内包表記を用いることで、Aに含まれるリストというのをコピーして新たなリストを作ることができます。
次元が高くなったらその分だけ内包表記を深くしましょう。
B = [a1[:] for a1 in A]
B = [[a1[:] for a1 in a2] for a2 in A]
B = [[[a1[:] for a1 in a2] for a2 in a3] for a3 in A]
B = [[[[a1[:] for a1 in a2] for a2 in a3] for a3 in a4] for a4 in A]
#などなど...
多次元配列の初期化
pythonで一次元配列を初期化するときは以下のように書きます。
DP = [0]*N
上記のように書くと、長さがNですべての要素が0であるようなリストを作ることができます。
では、多次元配列はどうでしょうか。例えば、3×3の二次元配列を作ってみましょう。
上のコードを見ると、二次元は以下のように書けそうです。
A = [[0]*3]*3
print(A) #[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
良さそうですね!一件落着!...とはいきません。リストの要素を変えてみましょう。
A[1][1] = 100
print(A) #[[0, 100, 0], [0, 100, 0], [0, 100, 0]]
中にあるすべてのリストが変わってしまいました...
idを用いるとわかりやすいのですが、これは3つの別々のリストがあるように見えて、実は同じリストを参照しています。
print(id(A[0]) == id(A[1]) == id(A[2]))#True
多次元配列を初期化するときは以下のように書きましょう
A = [[0]*3 for _ in range(3)]
A[1][1] = 100
print(A) #[[0, 0, 0], [0, 100, 0], [0, 0, 0]]
内包表記で[0]*3というリストを作るというのが3回行われるため、それぞれのリストは別のオブジェクトとなります。
デフォルト引数
デフォルト引数は便利ですよね。引数を入れなかった場合は自動でその値が入ってくれます。
では、以下のようなコードを実行してみましょう。
def add_sheep(arr = []):
arr.append("sheep")
return arr
A = add_sheep(["dog","cat"])
B = add_sheep()
C = add_sheep()
print(A) #['dog', 'cat', 'sheep']
print(B) #['sheep', 'sheep']
print(C) #['sheep', 'sheep']
羊が二匹のリストが二つできてしまいました。何故でしょう?
実は、デフォルト引数は関数が定義された時点でセットされ、引数がないときはずっと同じオブジェクトが使われます。intやstrなどなら良いのですが、リストではこのように予期せぬ動作をするのですね。
print(id(B) == id(C)) #True
対策としては、arr = Noneなどと書き、arrがNoneならarr = []をするような処理を書くとうまく動作するようになります。
ところで...
上記の関数はリストを受け取って、"sheep"を追加したリストを返すような関数でした。では、渡したリストはどうなるでしょうか
def add_sheep(arr = []):
arr.append("sheep")
return arr
A = ["dog", "cat"]
B = add_sheep(A)
print(A) #['dog', 'cat', 'sheep']
print(B) #['dog', 'cat', 'sheep']
print(id(A) == id(B)) #True
もしかすると、Aは["dog", "cat"]が出力されることを期待された方もいらっしゃるかもしれません。
リストを引数にするときは引数にリストに破壊的な変更をしていないか、してよいのかなどを気にするようにしましょう。
上限系
再帰上限
Pythonではデフォルトで再帰関数の深さの上限が1000に設定されています。
この1000という設定は競技プログラミングにおいて小さすぎます。上限を上げないとREしてしまうでしょう...
上限はsys.setrecursionlimit()で変更可能なので再帰関数を用いるときは必ず大きめの値に変更しておきましょう。
import sys
sys.setrecursionlimit(10**7)
4300桁制限
pythonのintは多倍長整数であり、数千桁といったとても大きい数も扱うことができます。が、CPython3.10.7, 3.9.14, 3.8.14, 3.7.14以降のバージョンではなんと文字列と整数の変換が4300桁に制限されました。これは文字列を整数、整数を文字列のどちらの変換でも発生し、10進数以外(2進数や16進数など)でも発生します。
最近のアップデートで追加された制限であり、実際に2023年の言語アップデート以前はなかった制限でした。ローカルにあるPythonのバージョンによっては、エラーが発生しないためなぜREが出ているのか長い間わからないケースもあるでしょう。
桁数の制限はsys.set_int_max_str_digits()で変更できます。特に、引数に0を指定すると制限自体がなくなります。多倍長整数を使いたいときは注意しましょう。
import sys
sys.set_int_max_str_digits(0)
文字列編
文字列結合
pythonの文字列はイミュータブルです。つまり、何らかの処理をするたびにオブジェクトの作り直しが発生しています。オブジェクトを作り直すときに文字をコピーしないといけないため、文字列の長さを$N$として、$O(N)$だけ文字列の作り直しにかかってしまいます。
詳細は、NaHCO3さんの記事に詳しく載っています。
文字列の末尾に文字を追加するような操作は$O(N)$かかるので、$N$回やると$O(N^2)$かかってしまいます。
#めっちゃ遅い...
S = ""
for i in range(10000000):
S += "x"
print(S)
では、文字列をたくさん結合したいような時にはどのようにすればよいのでしょうか?そんな時は"".join()を使いましょう。結合する文字列を保持しておくためのリストを作ります。
S = []
for i in range(10000000):
S.append("x")
print("".join(S))
inputが遅い
pythonの標準入力はinput()を使います。が、このinput()が結構遅いです。
普通の問題では問題ありませんが、クエリ問題やグラフ問題などで入力が$10^6$行など非常に多いときには入力だけでかなりの時間を使ってしまい、TLEの原因になることがあります。
sys.stdin.readline()をつかって入力を行うとinputよりも速く入力を受け取ることができます。が、input()と違い最後に文字列の改行が入るので、文字列として扱うときは注意してください。
input = sys.stdin.readline
のように書いてinputで書いてしまったコードの書き換えずとも入力を高速化することもできます。
便利なライブラリ編
Fractions
Fractionsは有理数を扱うPythonの標準ライブラリです。割り算をしても分子と分母をもっているので誤差が生まれないので正確な計算をすることができるのですが、滅茶苦茶に遅いです。
CPythonでもPyPyでも遅いです。何回も有理数同士の比較を行うとすぐにTLEしてしまいます。
有理数ライブラリは自作しましょう...
networkx
networkxはAtCoder上のジャッジに搭載されているグラフライブラリです。
たくさんのグラフアルゴリズムが入っていますが、とても低速です...
基本的にコンテスト中に使うのが怖いレベルで低速なので、ご利用は計画的に...
defaultdict
defaultdictはその名の通り、デフォルトの設定されているdictです。
存在しないキーでアクセスをしようとしたときに、設定したデフォルト値を代入してそれが返ってきます。
競プロではとても便利なのですが、このアクセスしようとしたときにキーがなかったら代入されるという仕様のせいで、存在しないキーの値を何回も何回も呼び出そうとすると遅くなってしまうケースがあります。(具体的には$10^7$回呼び出そうとして、TLEしたことがあります。)
デフォルト値を呼び出す回数が多そうである場合は、そのキーがdefaultdictのキーとして設定されているかをinなどを用いて判定したほうが良いでしょう。
deque
pythonでcollections.deque()はqueue.Queue()よりも高速であることから、BFSなどによく使われています。が、このdequeのランダムアクセスにかかる平均計算量はサイズを$N$として$O(N)$になります。このことから、C++などのdequeと同じ感覚で使うと計算量が異なることからTLEの原因となってしまいます。
recuraki(Akira Kanai)さんの記事に詳しい話が載っています。
ランダムアクセスが$O(1)$であるようなdequeを作成されている方もいます。
例えば、prd_xxxさんの記事に実装例があります。
その他
roundは四捨五入じゃない
ABC-AやABC-Bにはたまに小数を四捨五入するような問題があります。
検索するとそれっぽい関数としてround関数が出てきます。
指定した桁数で丸めることができ、例えば整数に丸めるときはround(1.2)などと書くことができます。
丸め方は、丸める桁が5より小さければ切り捨て、5より大きければ切り上げます。これだけを見ると四捨五入?と思うかもしれませんが、5と等しいときは偶数のほうに丸められます。例えばround(1.5)は2ですが、round(0.5)は0になります。
また、小数の誤差によって予想と反する結果となる場合があります。例えば、round(2.675, 2)は2.68ではなく2.67になります。
四捨五入をしたいときはdecimalのquantize()を用いましょう。第一引数に丸める桁を指定します。
roundingにROUND_HALF_UPを指定すると四捨五入となります。
from decimal import Decimal,ROUND_HALF_UP
print(Decimal('0.5').quantize(Decimal('1'),rounding = ROUND_HALF_UP)) #1
print(Decimal('1.55').quantize(Decimal('1.0'),rounding = ROUND_HALF_UP)) #1.6
多倍長整数を頼りすぎる
pythonのintは多倍長整数です。が、過信は厳禁です。
例えば、998244353でmodを取った値を求める問題をmodを取らずに解いて、最後にmodを取ることだって可能です。が、多倍長整数は当然大きくなれば大きくなるほど演算にかかるコストが大きくなっていきます。また、pypyでは64bit整数を超えない範囲と、超える範囲で大きく演算の速度に差があります。
めんどくさいですが、毎回ちゃんとmodを取ってあげましょう。
型変換のコストは無視できない
結果がfloatになるようなDPなどで、初期値を10**18などで初期化してしまうと、毎回intをfloatに変換するコストがかかってしまい、結果的に低速になります。floatで計算したいものは初めから初期値もfloatにしましょう。