
この記事はアドベントカレンダーRubyプログラミング問題にチャレンジ! -改訂版・チェリー本発売記念- Advent Calendar 2021の12/17の記事になります。
はじめに
皆さん、点字って読めますか?
私は読めません。(でした)
点字とは視覚障害者が文字を読んだり、書いたりするために使う文字です。
エレベータ、電車の券売機、家電等あらゆる生活で見かけることがありますよね。
実はこの点字、ちょっとした法則があることに気づきました。
この記事では点字の法則を解説して、点字を出力するRubyの点字メーカプログラムについて紹介したいと思います。
Rubyのプログラムもそこまで複雑ではないので、Rubyで簡単なプログラムを作ってみたい方にも参考になるかなと思います。
点字メーカプログラのソースコード
RubyのプログラムはこちらのPRにコミットしています。
コードを先に確認したい方はこちらを参照してください。
想定される読者
- 点字について知りたい!
- Rubyのプログラムで何か作ってみたい!
前提
今回の対象文字はあ〜んの点字になります。
あいうえお、かきくけこ、(省略)、やゆよ、らりるれろ、わ、ん
点字の法則
点字の構成
まずは点字の構成について簡単に説明します。
2列3行の⚫の組み合わせで一文字を表現します。
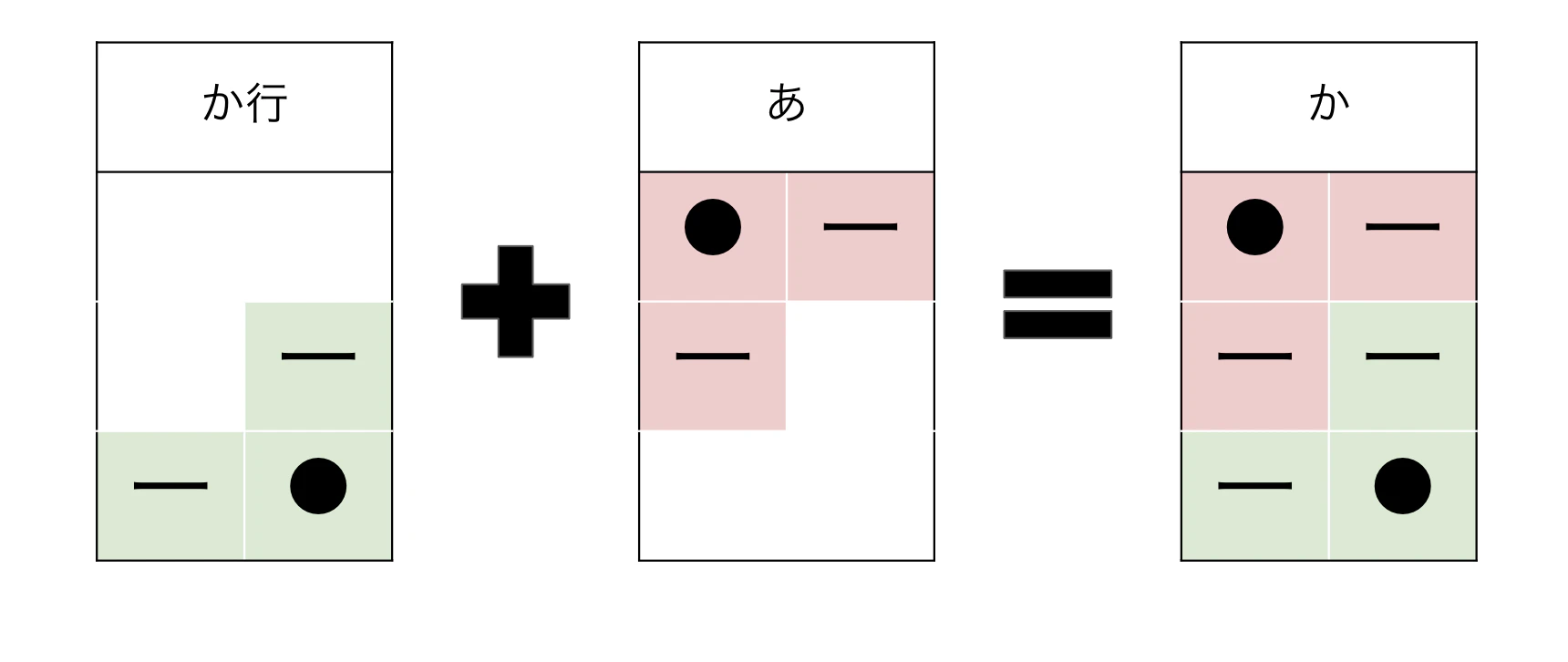
ちなみにかの場合は以下になります。

※詳細はこちらを参照
引用 全視情協:点字とは - 点字のしくみ
法則
実は点字はローマ字のように母音と子音の組み合わせで成り立っています。
ただし、や、ゆ、よ、わ、を、んは例外です。(後ほど説明します。)
母音と子音は以下の通り分けられています。

母音の表現方法は以下の通りです。

子音の表現方法は以下の通りです。
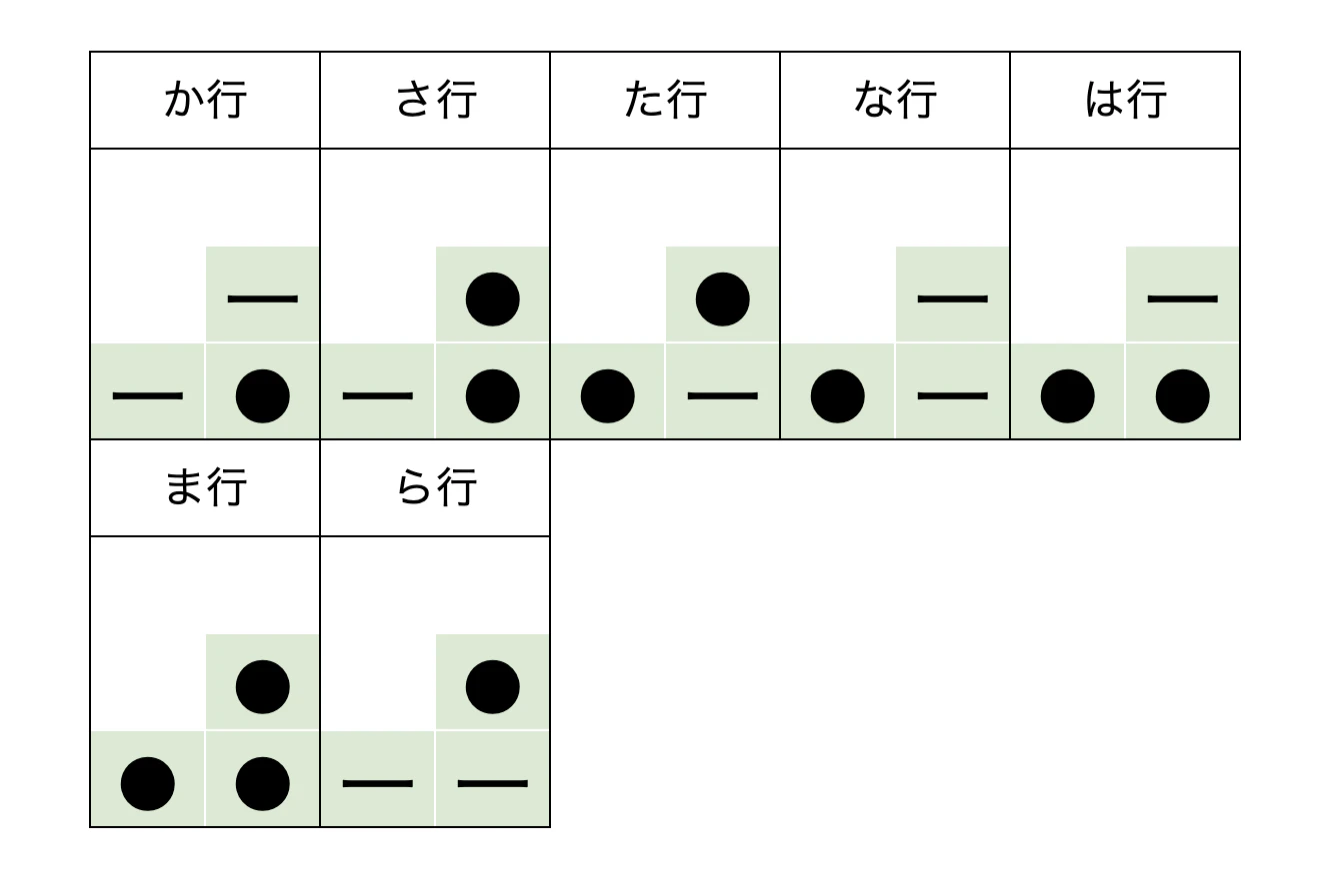
つまりかは以下の通り構成されることになります。
この法則を利用するとほとんどの文字が点字が表現できます。
ただし、や、ゆ、よ、わ、を、んは法則がなく固定の表現方法になります。

以上を理解すれば点字を表現できます。
なんだか身近に感じてきましたね。
点字メーカプログラム
それでは点字メーカプログラムの解説をします。
再掲となりますが、ソースコードはこちらです。
設計方針は前述の点字の法則を利用しています。
今回は空白区切りのローマ字を引数に点字の情報を文字列で出力するメソッドを実装します。
TenjiMaker.new.to_tenji('O SA KE')
# 出力結果
# -o o- oo
# o- -o o-
# -- -o -o
環境
ruby 3.0.1p64
ファイル構成
責務を明確にするためにファイル分割しました。
├── lib
│ ├── romaji.rb
│ ├── tenji_maker.rb
│ └── tenji_map.rb
| ファイル名 | 説明 |
|:-|:-|:-|
| romaji.rb | ローマ字のクラス。母音、子音を取得するインスタンスメソッドを実装。 |
| tenji_maker.rb | ローマ字の羅列から点字情報をテキストで出力するメソッドを実装 |
| tenji_map.rb | 点字情報をHash形式で定義している定数専用のファイル。法則がある文字は母音・子音の点字情報を定義。法則がない文字(や、ゆ、よ、わ、を、ん)は個別で用意する |
コードの解説
処理の流れに沿って解説していきます。
トップレベルで呼ばれるTenjiMaker.to_tenjiは大きく2つの処理を行います。
- ローマ字から点字ブロックの情報を取得
- 点字ブロックの情報を指定フォーマットに変換
実際のコードは以下の通りです。
def to_tenji(text)
# ローマ字から点字ブロックの情報を取得
tenji_blocks = text.split.map do |char|
Romaji.new(char).tenji_block
end
# 点字ブロックの情報を指定フォーマットに変換
format(tenji_blocks)
end
ローマ字から点字ブロックの情報を取得
引数に設定されたローマ字を配列の各要素に展開します。
空白区切りなので、splitをつかいます
text.split
# ['O', 'SA', 'KE']
各ローマ字を点字情報に変換します。
tenji_blocks = text.split.map do |char|
Romaji.new(char).tenji_block
end
Romajiクラス
Romajiクラスについて解説します。
ローマ字から母音・子音を抽出する処理が必要となりました。
そこで、再利用性と可読性を考慮してRomajiクラスを実装しました。
class Romaji
include TenjiMap
attr_accessor :char
def initialize(char)
@char = char
end
def length
char.length
end
# 母音(末尾の文字)
def vowel
char[-1]
end
# 子音(2文字以上の場合は末尾の文字だけ除けば子音となる)
def consonant
length >= 2 ? char[0..-2] : ''
end
# ローマ字から点字情報を作成する
def tenji_block
# (省略)
end
end
| メソッド| 説明 |
|:-|:-|:-|
| length | 文字列の長さを返す
例)SAの場合は2
例)Oの場合は1 |
| vowel | 母音はローマ字の末尾の文字
例)SAの場合最後の文字のAを返す |
| consonant | 2文字以上の場合は末尾の文字だけ除けば子音となる
例)SAの場合末尾の文字Aを除いてSを返す
例)Oの場合は一文字なので空文字''を返す |
| tenji_block | ローマ字から点字情報を作成する (後ほど詳細を説明)|
Romaji#tenji_block
Romaji#tenji_blockは点字情報を返します。
データ構造はHash型で、点字⚫を表示する箇所を保持しています。
6つの配置は以下の通り定義します。

SAの場合は以下のデータ構造になります。
Romaji('SA').new.tenji_block
# 以下出力
{
1 => 'o', 4 => '-',
2 => '-', 5 => 'o',
3 => '-', 6 => 'o',
}
Romaji#tenji_blockの処理について掘り下げていきます。
実際のコードは以下の通りです。
# ローマ字から点字情報を作成する
# @return [Hash]
def tenji_block
# 規則性がないローマ字の場合は点字情報を指定して返却
return UNIQUE[char] if UNIQUE.keys.include?(char)
# 初期値(全て'-')
tenji = BLANK.dup
# 母音の点字情報を反映
tenji.merge!(VOWEL[vowel])
# 子音の点字情報を反映
tenji.merge!(CONSONANT[consonant] || {})
end
法則がないローマ字の場合は固定の点字情報を指定して返却します
例)YAの場合
UNIQUEは tenji_map.rbに定義されている定数です。
法則制がないや、ゆ、よ、わ、を、んの点字情報が定義されています。
```ruby:YAの場合
規則性がないローマ字の場合は点字情報を指定して返却
return UNIQUE['YA'] if UNIQUE.keys.include?('YA')
返却する点字情報
{
1 => '-', 4 => 'o',
2 => '-', 5 => '-',
3 => 'o', 6 => '-',
}
`や、ゆ、よ、わ、を、ん`以外の場合は法則が適用できます。
母音と子音の情報から点字情報を返却します。
例)`SA`の場合
`VOWEL`は `tenji_map.rb`に定義されている定数です。
母音の点字情報が定義されています。
```ruby:母音が`A`
# 点字情報に母音情報を追加
tenji.merge!(VOWEL['A'])
# 点字情報
{
1 => 'o', 4 => '-',
2 => '-'
}
CONSONANTは tenji_map.rbに定義されている定数です。
子音音の点字情報が定義されています。
```ruby:子音がS
点字情報に子音情報を反映
tenji.merge!(CONSONANT['S'] || {})
点字情報
{
1 => 'o', 4 => '-',
2 => '-' 5 => 'o',
3 => '-', 6 => 'o'
}
これでローマ字から点字情報を作成することができました。
### 点字ブロックの情報を指定フォーマットに変換
各ローマ字を点字情報に変換できたので、その情報を元に出力フォーマットへと変換します。
```:出力フォーマット
-o o- oo
o- -o o-
-- -o -o
TenjiMakerクラスに定義したprivateメソッドformatで行います。
# 点字ブロックの情報を指定フォーマットに変換
format(tenji_blocks)
tenji_blocksは前述の ローマ字から点字ブロックの情報を取得の最終結果を格納しています。
複数のHash型の点字情報を配列の格納しています。
[
# お(O)
{
1 => '-', 4 => 'o',
2 => 'o', 5 => '-',
3 => '-', 6 => '-',
},
# さ(SA)
{
1 => 'o', 4 => '-',
2 => '-', 5 => 'o',
3 => '-', 6 => 'o',
},
# け(KE)
{
1 => 'o', 4 => 'o',
2 => 'o', 5 => '-',
3 => '-', 6 => 'o',
},
]
TenjiMaker#format
formatメソッドの実際のコードです。
private
# 点字ブロックの情報を指定フォーマットに変換
# @param [Array] 点字ブロックの情報
# @return [String] フォーマットされた点字情報
def format(tenji_blocks)
first, second, third = [[], [], []]
# ブロック情報から各行に出力する点字情報を保持
tenji_blocks.each do |tb|
first << "#{tb[1]}#{tb[4]}"
second << "#{tb[2]}#{tb[5]}"
third << "#{tb[3]}#{tb[6]}"
end
<<~"TENJI".chomp
#{first.join(" ")}
#{second.join(" ")}
#{third.join(" ")}
TENJI
end
出力フォーマットは3行で構成されるため、各行に出力する情報をfirst, second, thirdに格納していきます。
first, second, third = [[], [], []]
次に引数で渡された複数の点字情報tenji_blocksから各行に表示する情報を文字列にしてfirst, second, thirdに追加していく。
# ブロック情報から各行に出力する点字情報を保持
tenji_blocks.each do |tb|
first << "#{tb[1]}#{tb[4]}"
second << "#{tb[2]}#{tb[5]}"
third << "#{tb[3]}#{tb[6]}"
end
例えばおさけ(O SA KE)の場合は以下の通り格納されます。
first = ['-o', 'o-', 'oo'] # (1,4の点字)
second = ['o-', '-o', 'o-'] # (2,5の点字)
third = ['--', '-o', '-o'] # (3,6の点字)
最後にスペースで区切られた各行の情報を文字列として結合します。
スペースの区切りはArray#joinを使いました。
各行の情報を結合するのにヒアドキュメント<<~"TENJI".chompを使いました。
<<~"TENJI".chomp
# {first.join(" ")}
# {second.join(" ")}
# {third.join(" ")}
TENJI
この結果がformatメソッドの返却値となり、TenjiMaker#to_tenjiの処理は以下の結果を返します。
-o o- oo
o- -o o-
-- -o -o
解説は以上となります。
コードのアピールポイント
全体的に可読性の高いコードを意識して実装しました。
そこまでトリッキーなことはしていないので、直感的にコードを理解できるかと思います。
可読性を上げるために工夫したことは以下の3点です。
全てのメソッドの処理を11行以内に収められた
メソッドの責務がはっきりしているほど、可読性はより良くなると思います。
こちらの記事でもステップ数が少ないことのメリットについて語られています。
関数・メソッドの行数を短く保つと色々と捗る件
各メソッドで何をしているのかひと目で把握できるように、ステップ数を極力減らすようにしました。
その結果全てのメソッドを11行以内に収めることができました!
(もう少しで10行..)
例えばトップレベルのメソッドTenjiMaker#to_tenjiについてはわずか4行になります。
(コメントと空行は抜かしています。)
def to_tenji(text)
# ローマ字から点字ブロックの情報を取得
tenji_blocks = text.split.map do |char|
Romaji.new(char).tenji_block
end
# 点字ブロックの情報を指定フォーマットに変換
format(tenji_blocks)
end
上記を見ればわかるように、一目でこのメソッドが何をしているのか理解できると思います。
※余談
今回の話とは逸れてしまいますが、メソッドがシンプルだとテストもしやすい形になります。
その点では保守制も高くなります。
if等の分岐を極力なくした
コードが見づらくなる要因の一つしてif等の分岐処理がが多いことが挙げられます。
例えば以下のようなネストが深い処理が多いと読むのに少し時間がかかります。
if hoge?
if piyo? || fuga?
# 処理
elsif hogera?
# 処理
end
end
rubyは便利なメソッドがあるので、分岐を作らずにシンプルに書けることができます。
今回のプログラムは分岐処理は以下の2つだけに減らすことができました。(一つは三項演算子)
return UNIQUE[char] if UNIQUE.keys.include?(char)
length >= 2 ? char[0..-2] : ''
上記2つについても1行で書けるシンプルな内容なので、読むのに負担ではないかと思います。
点字の配置がひと目わかるようにインデントを調整
可読性を上げるためにはインデントや空白の使い方にも気を配ると良いです。
例えば以下はどちらが見やすいかは言うまでもありません。
# bad
first = {1 => 'a', 2 => 'b'}
second = { 1 => 'a', 2 => 'c'}
third= { 1 => 'a', 2 => 'b'}
# good
first = { 1 => 'a', 2 => 'b' }
second = { 1 => 'a', 2 => 'c' }
third = { 1 => 'a', 2 => 'b' }
全体的にインデントには気をつけていますが、点字情報を定数で定義する際にも少し工夫しました。
(母音、子音等の点字情報をTenjiMapのmoduleに定義しています。)
例えば母音A',子音'K'を表現するためには以下になります
'A' => {
1 => 'o', 4 => '-',
2 => '-'
},
'K' => {
5 => '-',
3 => '-', 6 => 'o'
},
少し変な書き方に思えるかもしれませんが、あえて以下の形に併せてインデントを調整しました。
このようにひと目で理解できる形式にプログラムを書いてあげるとより可読性が上がると思います。
※余談
母音と子音の点字の配置がわかることから、TenjiMapモジュールを見返すことでプログラムを通さなくても点字をイメージできるようになります。
ちょっとした設計書のようになるため、保守性についても良い点かと思います。
伊藤さんにメッセージ
今回Rubyのプログラムを通して、点字について真剣に考えられる機会ができました。
点字の仕組みを少しでも理解できたことにとても感謝しています。
今回の企画とても楽しかったので、来年もぜひ企画していただきたいなと思っています!
チェリー本はすでに購入済みです ![]()