前提
最近機械学習の勉強を始めた超初心者による記事なので、間違った認識をしていることがあるかもしれません。
そしてもっといい分類方法があるかもしれません。
問題
- 顔の写った写真が複数枚ある(今回は1枚につき顔は1つの写真を想定するが、複数写っていても問題ない)
- 同じ顔が別の写真に映っている
- 同じ顔が写っている写真をグループ化したい
- ユニークな顔がいくつかは知らない(ここが難しそうなポイント)
どうやって解くか
とりあえず流れとしては、
- 顔を検出
簡単に顔認識ができるライブラリであるface_recognitionを用いる
- 顔をテンソル化
face_recognitionの128次元テンソルを用いる
- テンソルを2次元に圧縮
PCAで圧縮する。t-SNEを用いてみたがうまく行かなかった。
- クラスタリング
顔がいくつあるかわかっていれば、k-meansなどが使えるが、今回は不明なのでDBSCANを用いる
という感じで良さそう。
コード
予めpipでface_recognition、scikit-learn、matplotlibをインストールしておくこと
main.py
import face_recognition
from sklearn.decomposition import PCA
from sklearn.cluster import DBSCAN
import glob
from matplotlib import pyplot as plt
import numpy as np
filelist = glob.glob('./faces/*[jpg|JPG|png]') # とりあえずfacesディレクトリの中にある画像を対象に読み込む(適宜書き換えてください)
images = [face_recognition.load_image_file(i) for i in filelist]
faces = [] # 顔の128次元テンソルを格納
for i in images:
faces += face_recognition.face_encodings(i) # テンソルを取得
faces = np.array(faces)
# PCAで128次元→2次元に圧縮
compressed = PCA(n_components=2).fit_transform(faces)
# DBSCANでクラスタリング
db = DBSCAN().fit(faces)
labels = db.labels_ # 各顔がどのグループに属するのかというラベル情報
# グループごと点をプロット & print
cluster_max = np.max(labels)
for i in range(0, cluster_max+1):
points = compressed[labels == i]
plt.scatter(points[:, 0], points[:, 1])
# ファイル名をプロット
for i, xy in enumerate(compressed):
# 今回は1画像1顔なのでこれができる
plt.annotate(filelist[i], xy)
# labelsが-1のものは分類に失敗したノイズなのでグレーでプロット
points = compressed[labels == -1]
plt.scatter(points[:, 0], points[:, 1], color="gray")
print('\nNoise')
for i, v in enumerate(labels == -1):
if v == True:
print(filelist[i])
plt.show()
結果
facesフォルダの中に、適当にネット上から引っ張ってきたオバマ、トランプ、ヒラリー・クリントンが写った写真を5枚づつ突っ込んでおいた。
黒人、白人、男性、女性ということでかなり分類しやすいはずだ。
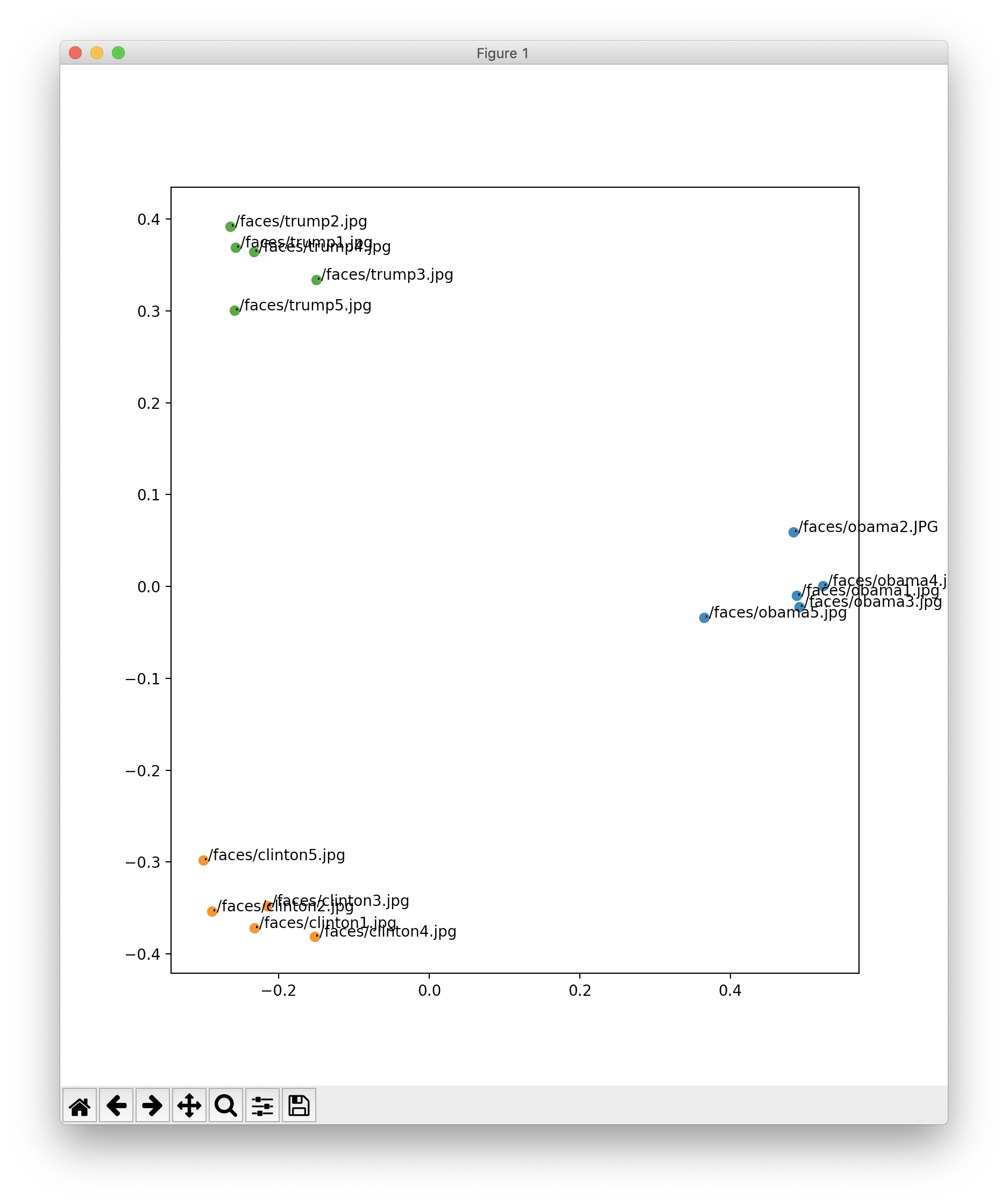
完全に分類できています。めでたしめでたし。