Note
- 現在はこちらの方法の方がより簡単に環境構築できます ChainerRL + Minecraftで深層強化学習 ハンズオン [MineRL version]
Minecraft
みなさん、ご存知Minecraft。私は知らなかったですが、マイクラって略されるんですね。公式のPR動画としては以下のようなものもあります。
— Keisuke Umezawa (Chainer Evangelist) (@kmechann) 2018年12月12日
また、Minecraft Japan Wikiでは下記の通り説明されています。
Minecraftは、2009年5月10日にNotch氏(本名:Markus Persson)が開発を始めた、サンドボックス型のものづくりゲームです。
レトロゲーを想起させるドットテイストのブロックが溢れる世界で、プレイヤーは建物やその他のものを自由に創造することが出来ます。
未開の土地を探索したり、洞窟を探検したり、モンスターと戦ったり、植物を育てたり、新しいブロックを手に入れ配置することで、様々なものを作ることができます。
創造(想像)力次第で小さな家から、ドット絵、地下基地、巨大な城まで何でも作ることができます。マルチプレイでは、協力して巨大な建築物を作ったり、Player VS Player(PvP)で他プレイヤーと戦うことも出来ます。
この説明にあるようにいくつか、現在の強化学習に適したキーワードがあります。
- 建物やその他のものを自由に作ることできる
- 色々なゲームができる
- マルチプレイできる
このあたりの特性がMinecraftにあるからこそ、Minecraftで強化学習をしようというモチベーションが生まれたのだと思います。
Marlo Project
このハンズオンでは、Minecraftをシミュレーター環境として深層強化学習を行います。現在、Minecraftを活用したMARLOという深層強化学習のコンテストが行われています。今回はこのコンテストで活用されいるmarLoというOpenAI's Gym互換のMinecraft環境を使います。OpenAI's Gym互換のため、ChainerRLなどの強化学習フレームワークを簡単に使用することができます(完全ではないが・・・例えば動画の保存に使うwrapperが使えなかったりする)。
marLoでは下記のような環境が用意されており、例えば溶岩の上の一本道を歩くAIを深層強化学習で作ることが出来ます。今回はMarLo-FindTheGoal-v0で説明を行い、その後皆さんに新しい課題にチャレンジしていただきます。
MarLo-MazeRunner-v0 
|
MarLo-CliffWalking-v0 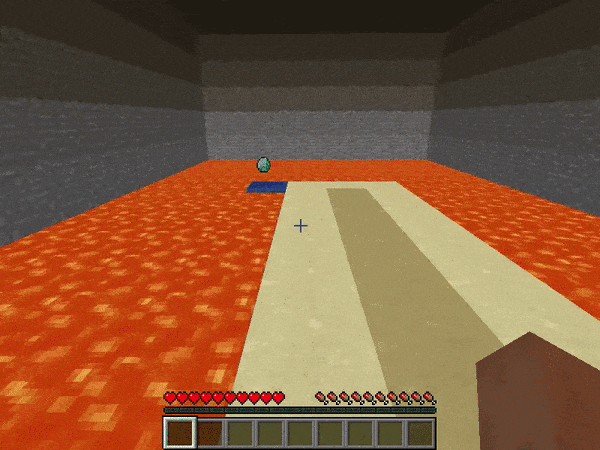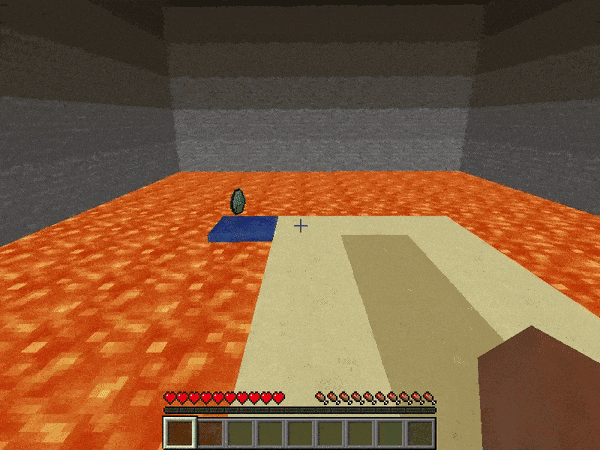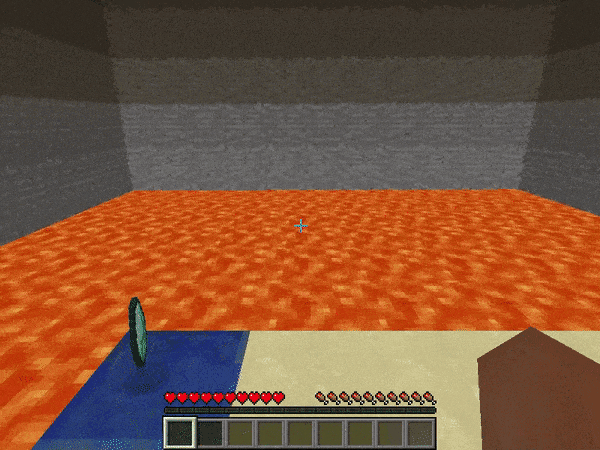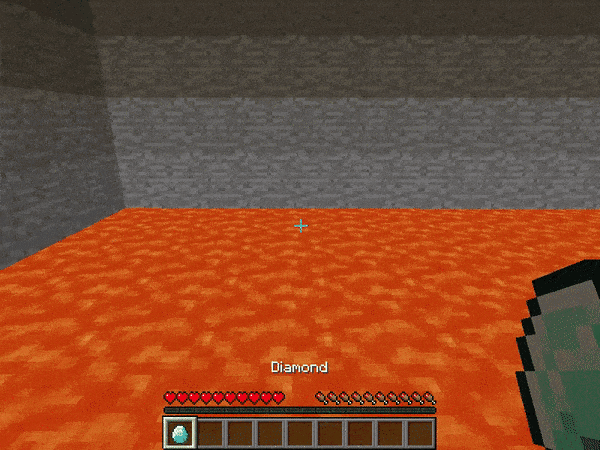
|
MarLo-CatchTheMob-v0 
|
MarLo-FindTheGoal-v0 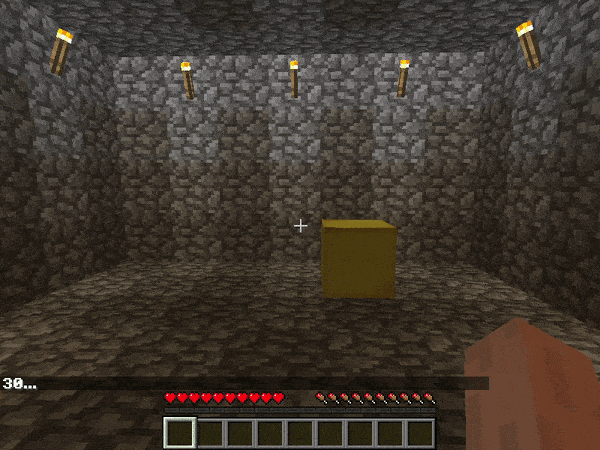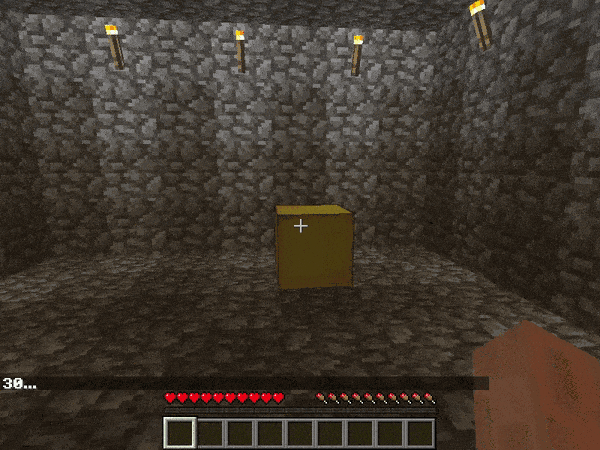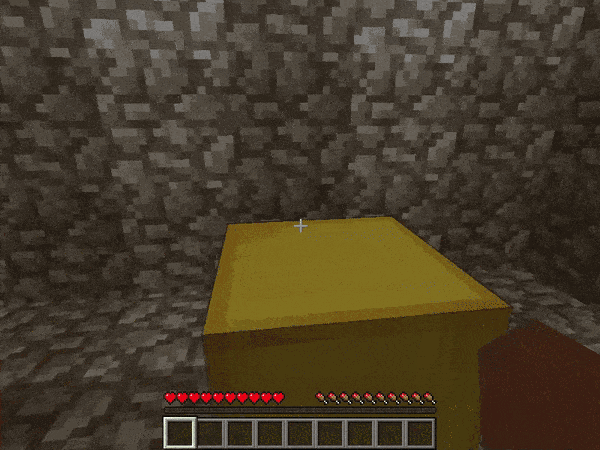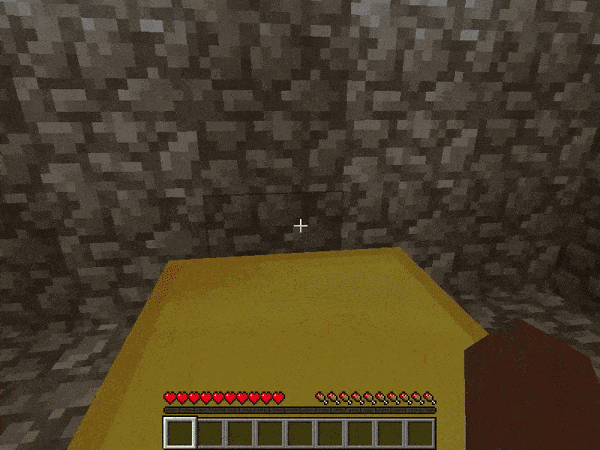
|
MarLo-Attic-v0 
|
MarLo-DefaultFlatWorld-v0 
|
MarLo-DefaultWorld-v0 
|
MarLo-Eating-v0 
|
MarLo-Obstacles-v0 
|
MarLo-TrickyArena-v0 
|
MarLo-Vertical-v0 
|
ハンズオンの内容
※ このハンズオンは、https://github.com/keisuke-umezawa/marlo-handson を元に作成しています。
Requirement
2018/12/14時点では以下が必要です。
- Python 3.5+ environment with
- Chainer v5.0.0
- CuPy v5.0.0
- ChainerRL v0.4.0
- marlo v0.0.1.dev23
Azureで環境設定
※ 以下の手順を踏むためには、Azureのsubscriptionが必要です。
※ 他の環境での構築方法の記事もあるのでご参考ください。
1. Azure CLIのインストール
環境に合わせて下記から選択ください。
- Windowsの場合
-
Homebrew(macOS)の場合
$ brew update && brew install azure-cli -
pythonを使用する場合
$ pip install azure-cli
2. Azureにログイン
$ az login
3. subscriptionの選択
以下のコマンドで、あなたがお持ちのsubscriptionをリストアップできます。
$ az account list --all
あなたのアカウントに選択したいsubscriptionを設定しましょう。もちろん、[A SUBSCRIPTION ID]はあなたのsubscription IDに置き換えてください。
$ az account set --subscription [A SUBSCRIPTION ID]
4. GPU VMの起動
次に、以下のコマンドでデータサイエンスVMを作成します。--generate-ssh-keysは、VMに接続するための鍵を自動で作成し、~/.ssh/以下に秘密鍵id_rsa、公開鍵id_rsa.pubとして保存します。
$ AZ_USER=[好きなuser名 e.g. kumezawa]
$ AZ_LOCATION=[resource-groupを作ったlocation e.g. eastus]
$ AZ_RESOURCE_GROUP=[resource-groupを作ったlocation e.g. marmo]
$ az vm create \
--location ${AZ_LOCATION} \
--resource-group ${AZ_RESOURCE_GROUP} \
--name ${AZ_USER}-vm \
--admin-username ${AZ_USER} \
--public-ip-address-dns-name ${AZ_USER} \
--image microsoft-ads:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest \
--size Standard_NC6 \
--generate-ssh-keys
うまくいくと、以下のようなメッセージがでてくるはずです。
{
"fqdns": "[YOUR USERNAME].eastus.cloudapp.azure.com",
"id": "/subscriptions/[YOUR SUBSCRIPTION ID]/resourceGroups/marLo-handson/providers/Microsoft.Compute/virtualMachines/vm",
"location": "eastus",
"macAddress": "AA-BB-CC-DD-EE-FF",
"powerState": "VM running",
"privateIpAddress": "10.0.0.4",
"publicIpAddress": "123.456.78.910",
"resourceGroup": "marLo-handson",
"zones": ""
}
publicIpAddressを次の手順で使うので覚えておいてください。
Note
~/.ssh/以下に秘密鍵id_rsa、公開鍵id_rsa.pubがある場合、上記コマンドがエラーを起こします。
その場合は自分で鍵を作成し、それを指定して作成することができます。
$ az vm create \
--location ${AZ_LOCATION} \
--resource-group ${AZ_RESOURCE_GROUP} \
--name ${AZ_USER}-vm \
--admin-username ${AZ_USERER} \
--public-ip-address-dns-name ${AZ_USER} \
--image microsoft-ads:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest \
--size Standard_NC6 \
--ssh-key-value [公開鍵のpath e.g. ~/.ssh/id_rsa.pub]
Note
もし、GPUではなく、CPUインスタンスで起動したい場合は、例えば--size Standard_D2s_v3としてください。他の使えるVMのサイズを調べたい場合は、こんな感じで調べられます。
az vm list-sizes --location eastus --output table
5. アクセスに必要なportのopen
$ az vm open-port --resource-group ${AZ_RESOURCE_GROUP} --name ${AZ_USER}-VM --port 8000 --priority 1010 \
&& az vm open-port --resource-group ${AZ_RESOURCE_GROUP} --name ${AZ_USER}-VM --port 8001 --priority 1020 \
&& az vm open-port --resource-group ${AZ_RESOURCE_GROUP} --name ${AZ_USER}-VM --port 6080 --priority 1030
6. VMにssh接続
$ AZ_IP=[あなたのvmのIPアドレス e.g. "40.121.36.99"]
$ ssh ${AZ_USER}@${AZ_IP} -i ~/.ssh/id_rsa
7. MarLoのためのConda環境の作成
VM環境で以下のコマンドを実行してください。
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list \
&& sudo apt-get update \
&& sudo apt-get install -y libopenal-dev
$ conda config --set always_yes yes \
&& conda create python=3.6 --name marlo \
&& conda config --add channels conda-forge \
&& conda activate marlo \
&& conda install -c crowdai malmo matplotlib ipython numpy scipy opencv \
&& pip install git+https://github.com/crowdAI/marLo.git
現在インストールされているcudaのバージョンに応じて、適切なcupyとchainerをインストールしましょう。例えば、cuda9.0の場合は、cupy-cuda90です。
$ nvcc --version
$ pip install chainer==5.1.0 cupy-cuda90==5.1.0 chainerrl==0.5.0
8. DockerによるMinecraft clientの起動
$ sudo docker pull ikeyasu/marlo:latest
$ VNC_PW=[適当なpassword]
$ sudo docker run -it --net host --rm --name robo6082 -d -p 6080:6080 -p 10000:10000 -e VNC_PW=${VNC_PW} ikeyasu/marlo:latest
http://あなたのvmのIP:6080 にアクセスし、自分で設定したパスワード${VNC_PW}を入力してみてください。
VNC接続によりリモート環境に接続し、その中でMinecraftが起動することを確認できるはずです!
ハンズオンをはじめよう
0. Conda環境がactivateされているか確認
$ conda info -e
# conda environments:
#
base /anaconda
marlo * /anaconda/envs/marlo
py35 /anaconda/envs/py35
py36 /anaconda/envs/py36
もし、先ほど作ったmarloがactivateされていない場合は、下のコマンドを実行してください。
$ conda activate marlo
1. Hands-on レポジトリのClone
$ git clone https://github.com/keisuke-umezawa/marlo-handson.git
$ cd marlo-handson
2. malroテストスクリプトの実行
$ python test_malmo.py
暫く待つと以下のような画面が表示されるはずです。
これは以下のpythonスクリプトを実行します。
import marlo
def make_env(env_seed=0):
join_tokens = marlo.make(
"MarLo-FindTheGoal-v0",
params=dict(
allowContinuousMovement=["move", "turn"],
videoResolution=[336, 336],
kill_clients_after_num_rounds=500
))
env = marlo.init(join_tokens[0])
obs = env.reset()
action = env.action_space.sample()
obs, r, done, info = env.step(action)
env.seed(int(env_seed))
return env
env = make_env()
obs = env.reset()
for i in range(10):
action = env.action_space.sample()
obs, r, done, info = env.step(action)
print(r, done, info)
-
"MarLo-FindTheGoal-v0"を変更すると環境を変更できます -
obsはnumpy形式の画像データです。 -
rは前回の行動に対する報酬です -
doneはゲームが終了したか真偽値です。 -
infoはその他情報が入っています。
課題1: 上記などを確認したり、変更したりして、遊んでみてください。
3. ChainerRLによるDQNの訓練スクリプトの実行
まずは以下のコマンドを実行してみてください。そうすると、ChainerRLでDQNという強化学習のモデルの訓練を0から開始できます。
$ python train_DQN.py
適当なタイミングでCTRL+Cを押して、スクリプトを止めてみましょう。そうすると以下のようなディレクトリができているはずです。xxxx_exceptに今まで学習したモデルが保存されています。
$ ls results/
3765_except scores.txt
Note
cpuのみで動作させたい場合は、以下のオプションを追加して動かしてみてください。
$ python train_DQN.py --gpu -1
3. 保存したモデルの動作確認
以下のコマンドで、学習したモデルのロードと、その動作確認ができます。
$ python train_DQN.py --load results/3765_except --demo
どうでしょうか。たいして学習させていないのでちゃんと動かないはずです。
4. 保存したモデルから訓練の開始
以下のコマンドを使用すれば、以前保存したモデルから学習を再開できます。
$ python train_DQN.py --load results/3765_except
また、こちらである程度訓練したモデルを用意したので、そこから学習を開始することもできます。ただし、単にpython train_DQN.pyを実行して作成されたモデルですので、コードに変更を加えたり、環境を変更したりした場合動かないことがあります。
$ wget https://github.com/keisuke-umezawa/marlo-handson/releases/download/v0.2/157850_except.tar.gz
$ tar -xvzf 157850_except.tar.gz
$ python train_DQN.py --load 157850_except
課題2: train_DQN.pyのコードを読もう
このスクリプト自体は以下の通りです。
# ...省略...
def main():
parser = argparse.ArgumentParser()
# ...省略...
# Set a random seed used in ChainerRL.
misc.set_random_seed(args.seed, gpus=(args.gpu,))
if not os.path.exists(args.out_dir):
os.makedirs(args.out_dir)
experiments.set_log_base_dir(args.out_dir)
print('Output files are saved in {}'.format(args.out_dir))
env = make_env(env_seed=args.seed)
n_actions = env.action_space.n
q_func = links.Sequence(
links.NatureDQNHead(n_input_channels=3),
L.Linear(512, n_actions),
DiscreteActionValue
)
# Use the same hyper parameters as the Nature paper's
opt = optimizers.RMSpropGraves(
lr=args.lr, alpha=0.95, momentum=0.0, eps=1e-2)
opt.setup(q_func)
rbuf = replay_buffer.ReplayBuffer(10 ** 6)
explorer = explorers.LinearDecayEpsilonGreedy(
1.0, args.final_epsilon,
args.final_exploration_frames,
lambda: np.random.randint(n_actions))
def phi(x):
# Feature extractor
x = x.transpose(2, 0, 1)
return np.asarray(x, dtype=np.float32) / 255
agent = agents.DQN(
q_func,
opt,
rbuf,
gpu=args.gpu,
gamma=0.99,
explorer=explorer,
replay_start_size=args.replay_start_size,
target_update_interval=args.target_update_interval,
update_interval=args.update_interval,
batch_accumulator='sum',
phi=phi
)
if args.load:
agent.load(args.load)
if args.demo:
eval_stats = experiments.eval_performance(
env=env,
agent=agent,
n_runs=args.eval_n_runs)
print('n_runs: {} mean: {} median: {} stdev {}'.format(
args.eval_n_runs, eval_stats['mean'], eval_stats['median'],
eval_stats['stdev']))
else:
experiments.train_agent_with_evaluation(
agent=agent,
env=env,
steps=args.steps,
eval_n_runs=args.eval_n_runs,
eval_interval=args.eval_interval,
outdir=args.out_dir,
save_best_so_far_agent=False,
max_episode_len=args.max_episode_len,
eval_env=env,
)
if __name__ == '__main__':
main()
課題3: 性能をあげよう
強化学習の性能を改善するには以下のような手段があります。
- モデルの変更
- ReplayBufferの変更
- そのたパラメータの変更
また、Rainbow: Combining Improvements in Deep Reinforcement Learningという、強化学習に関する手法を色々試して、その性能向上を評価した論文もあります。これによると以下によって性能向上を試すことができる可能性があります。
- PrioritizedReplayBufferの使用
- DDQNの使用
- etc