TL;DR
ChainerのMNISTのコードをPyTorchに書き直して見た感想は、ほとんど違いがなかったです。
違いがあった部分は、Chainerで言うUpdaterより上位層、PyTorchで言うIgnite層でした。
しかも、実はchainer-pytorch-migrationを使うと、Chainerで使っていたExtentionsをIgniteでも使えたりして、かなりChainerライクにPyTorch+Igniteを使うことができます。
今までChainerを使っていた方も自然とPyTorch+Igniteに慣れることができるのではと思います。
PFNによるChainerの開発停止とPyTorch採用
ここ[1]に記載されているように、PFNはChainerの開発を終了し、PyTorchに移行することが発表されました。
株式会社Preferred Networks(本社:東京都千代田区、代表取締役社長:西川徹、プリファードネットワークス、以下、PFN)は、研究開発の基盤技術である深層学習フレームワークを、自社開発のChainer™から、PyTorchに順次移行します。同時に、PyTorchを開発する米FacebookおよびPyTorchの開発者コミュニティと連携し、PyTorchの開発に参加します。なお、Chainerは、本日公開されたメジャーバージョンアップとなる最新版v7をもってメンテナンスフェーズに移行します。Chainerユーザー向けには、PyTorchへの移行を支援するドキュメントおよびライブラリを提供します。
今すぐにChainerを使えなくなるわけではないですが、Chainerユーザは徐々に他のフレームワークに移行せざるを得ない状況になっています。
PFNによるChainerからPyTorch移行のサポート
Chainer開発終了は急な発表で多くのユーザは困惑したと思いますが、PFNもその状況を想定してPyTorchへの移行を支援するドキュメント [2]およびライブラリ [3]を提供しています。
上記、ドキュメントを見ると、ChainerとPyTorch+Igniteの対応関係は以下のようです。
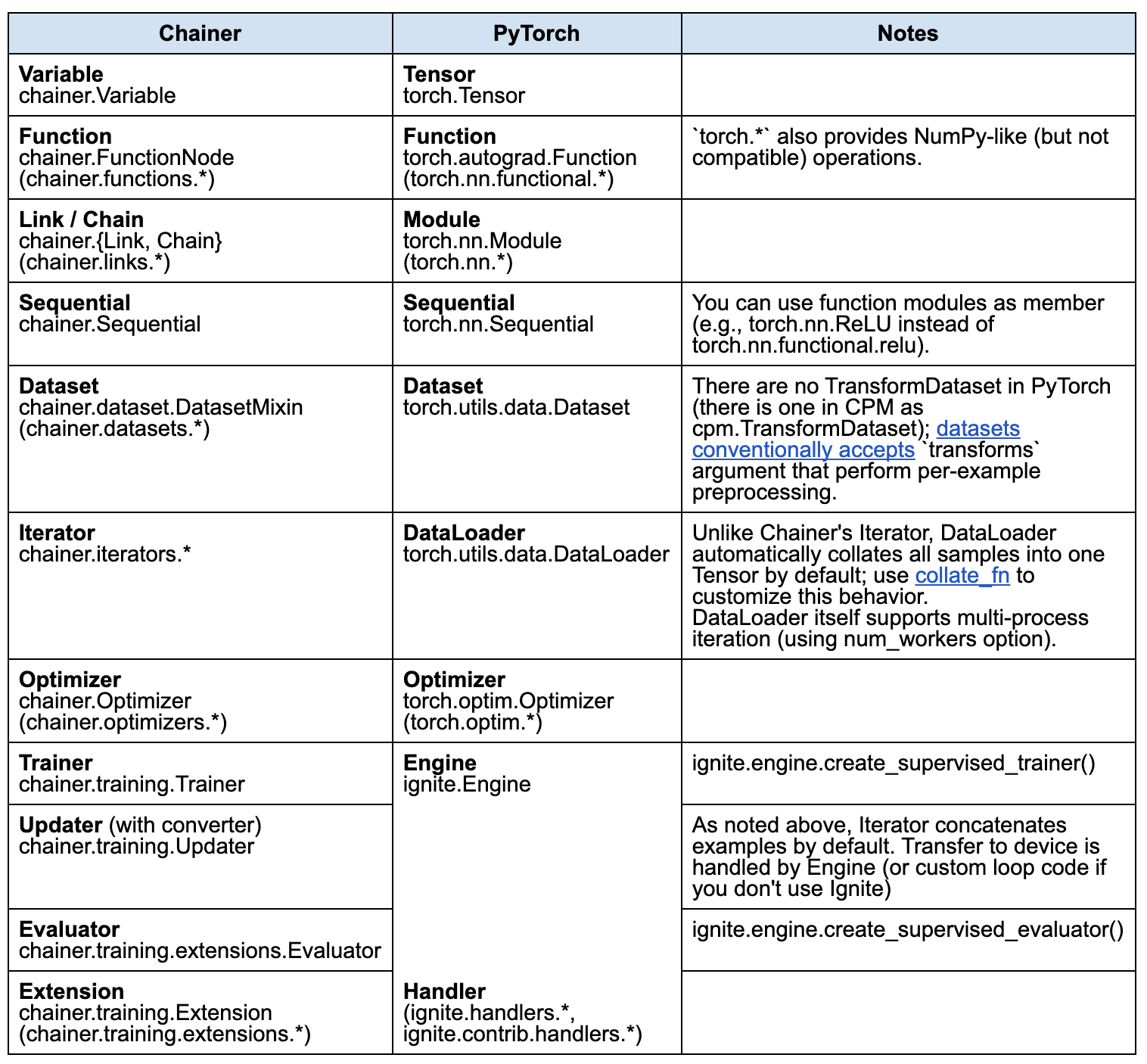 cited from [2]
cited from [2]
上記からわかることは、
- ChainerのOptimizerまでの役割は、PyTorchが対応している
- ChainerのUpdater・Trainerの役割は、Igniteが対応している
なので、学習ステップを自分で書く場合はPyTorchのみで書けるが、ChainerのTrainerのように学習ステップもフレームワークで対応してもらいたい場合はPyTorch+Igniteを使う必要があることがわかります。
さっそくChainerからPyTorch+Igniteへ移行してみた
移行対象となるコード
下記リンク先にChainerのTrainerを使って、MNISTの訓練・推論を行うNotebookがあります。
今回は上記コードをPyTorch+Igniteを使って書き直してみたいと思います。
各ステップの移行方法
サンプルデータセットの読み込み部分
from chainer.datasets import mnist
train, test = mnist.get_mnist()
↓
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
data_transform = ToTensor()
train = MNIST(download=True, root=".", transform=data_transform, train=True)
test = MNIST(download=False, root=".", transform=data_transform, train=False)
- 違い
- ここはサンプルデータセットの読み込み部分なのでそれなりに違いがある部分だと思いますが、実用途では違いがあってもあまり関係がない部分です。
Iterator -> DataLoader
from chainer import iterators
batchsize = 128
train_iter = iterators.SerialIterator(train, batchsize)
test_iter = iterators.SerialIterator(test, batchsize, False, False)
↓
from torch.utils.data import DataLoader
batch_size = 128
train_loader = DataLoader(train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test, batch_size=batch_size, shuffle=False)
- 違い(ほとんど同じですね)
- 引数がちょっと違うくらいですかね。
モデルの準備
import chainer
import chainer.links as L
import chainer.functions as F
class MLP(chainer.Chain):
def __init__(self, n_mid_units=100, n_out=10):
super(MLP, self).__init__()
with self.init_scope():
self.l1=L.Linear(None, n_mid_units)
self.l2=L.Linear(None, n_mid_units)
self.l3=L.Linear(None, n_out)
def forward(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
gpu_id = 0 # Set to -1 if you don't have a GPU
model = L.Classifier(model)
if gpu_id >= 0:
model.to_gpu(gpu_id)
↓
from torch import nn
import torch.nn.functional as F
import torch
class MLP(nn.Module):
def __init__(self, n_mid_units=100, n_out=10):
super(MLP, self).__init__()
self.l1 = nn.Linear(784, n_mid_units)
self.l2 = nn.Linear(n_mid_units, n_mid_units)
self.l3 = nn.Linear(n_mid_units, n_out)
def forward(self, x):
x = torch.flatten(x, start_dim=1)
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = self.l3(h2)
return F.log_softmax(h3, dim=1)
device = 'cuda:0'
model = MLP()
- 違い(ほとんど同じですね)
- PyTorchの場合は、
Linearのin_featuresをNoneとして省略することができないようです。 - PyTorchの場合は、Chainerの
L.Classifierが存在しないので、最終層でF.log_softmax(h3, dim=1)を明示的に計算している。 - (フレームワークの違いというよりはデータセットの形式の違い)PyTorchのMNISTのデータは2次元なので、
x = torch.flatten(x, start_dim=1)として1次元にしている。
- PyTorchの場合は、
Optimizerの準備
from chainer import optimizers
lr = 0.01
optimizer = optimizers.SGD(lr=lr)
optimizer.setup(model)
↓
from torch import optim
lr = 0.01
# 最適化手法の選択
optimizer = optim.SGD(model.parameters(), lr=lr)
- 違い(ほとんど同じですね)
- 引数がちょっと違うくらいですかね。
Updater -> Ignite
from chainer import training
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
↓
from ignite.engine import create_supervised_trainer
trainer = create_supervised_trainer(model, optimizer, F.nll_loss, device=device)
- 違い(ほとんど同じですね)
- 引数がちょっと違うくらいですかね。
拡張機能の追加
from chainer.training import extensions
trainer = training.Trainer(
updater, (max_epoch, 'epoch'), out='mnist_result'
)
trainer.extend(extensions.LogReport())
.
.
.
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu_id))
↓
from ignite.engine import create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from ignite.engine import Events
evaluator = create_supervised_evaluator(
model,
metrics={
'accuracy': Accuracy(),
'nll': Loss(F.nll_loss),
},
device=device,
)
training_history = {'accuracy':[],'loss':[]}
validation_history = {'accuracy':[],'loss':[]}
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
evaluator.run(train_loader)
metrics = evaluator.state.metrics
avg_accuracy = metrics['accuracy']
avg_nll = metrics['nll']
training_history['accuracy'].append(avg_accuracy)
training_history['loss'].append(avg_nll)
print(
"Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}"
.format(engine.state.epoch, avg_accuracy, avg_nll)
)
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(engine):
evaluator.run(test_loader)
metrics = evaluator.state.metrics
avg_accuracy = metrics['accuracy']
avg_nll = metrics['nll']
validation_history['accuracy'].append(avg_accuracy)
validation_history['loss'].append(avg_nll)
print(
"Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}"
.format(engine.state.epoch, avg_accuracy, avg_nll))
# Create snapshot
from ignite.handlers import ModelCheckpoint
checkpointer = ModelCheckpoint(
'./models',
'MNIST',
save_interval=1,
n_saved=2,
create_dir=True,
save_as_state_dict=True,
require_empty=False,
)
trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpointer, {'MNIST': model})
- 違い
- ためしに、Igniteで以下をしてみたのですが、Chainerと書き方はだいぶ異なります。ただ、実装さえすれば今までできたことができないということはなさそうです。
- 訓練データでの精度・ロスを表示・保存
- 検証データでの精度・ロスを表示・保存
- 1epoch ごとにスナップショットを保存
- ためしに、Igniteで以下をしてみたのですが、Chainerと書き方はだいぶ異なります。ただ、実装さえすれば今までできたことができないということはなさそうです。
訓練の実行
trainer.run()
↓
max_epochs = 10
trainer.run(train_loader, max_epochs=max_epochs)
- 違い(ほとんど同じですね)
- 引数がちょっと違うくらいですかね。
移行後のコード
実際に移行してColaboratoryで動くNotebookは以下にあります。上記で説明したコードだけでなく、以下も含まれているのでよろしければお手元で実行してみてください。
- 訓練・検証データでの精度・ロスのプロットする
- スナップショットからモデルをロードし、推論する
おまけ
実は、chainer-pytorch-migrationを使うと、Chainerで使っていたextensionsをIgniteでも使えます! Chainerのextensionsが恋しい方はchainer-pytorch-migrationを使ってみてください。
import chainer_pytorch_migration as cpm
import chainer_pytorch_migration.ignite
from chainer.training import extensions
optimizer.target = model
trainer.out = 'result'
cpm.ignite.add_trainer_extension(trainer, optimizer, extensions.LogReport())
cpm.ignite.add_trainer_extension(trainer, optimizer, extensions.ExponentialShift('lr', 0.9, 1.0, 0.1))
cpm.ignite.add_trainer_extension(trainer, optimizer, extensions.PrintReport(
['epoch', 'iteration', 'loss', 'lr']))
max_epochs = 10
trainer.run(train_loader, max_epochs=max_epochs)