はじめに
忙しいとなかなか見たい動画を見る余裕がありません。だけど見ておかないと友達との会話にもついていけないしどうしよう。。そんな時活躍するであろう、GPT-4 × GPT-4V を組み合わせて動画を“見てもらう”ツールを作ってみました。
注意
音声には対応していませんので、あくまで視覚的な範囲で教えてくれます。
アルゴリズム
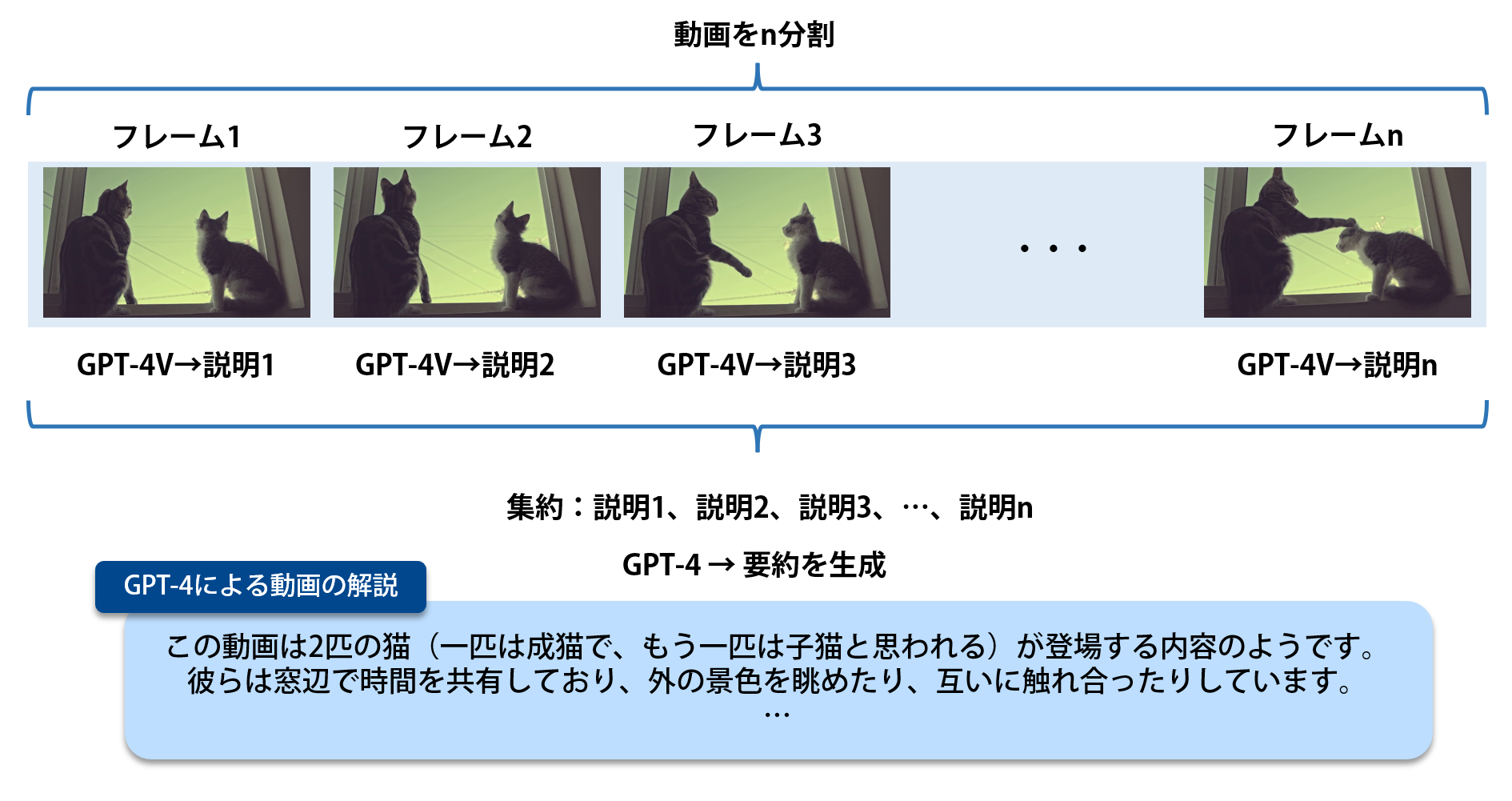
単純な仕組みで、大まかには以下の3点です。
① 対象の動画を任意に$n$分割し、その位置のフレームを抽出します。
② 各フレームが何を意味しているのか、GPT-4Vを用いて簡単に説明させます。
③ ②で得られたフレームごとの説明を集約し、GPT-4に要約させて完成です。
Python実装
OpenCVで動画を読み込み、任意のフレーム数を抽出します。高解像度の動画にも対処するため、リサイズのパラメータも用意しました。
import os
import argparse
import base64
import cv2
from tqdm import tqdm
from openai import OpenAI
def extract_frames(video_path, num_frames, width):
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_gap = total_frames // num_frames
os.makedirs("tmp", exist_ok=True)
for i in range(num_frames):
cap.set(cv2.CAP_PROP_POS_FRAMES, i * frame_gap)
ret, frame = cap.read()
if ret:
# アスペクト比を保ったままリサイズ
height, old_width = frame.shape[:2]
aspect_ratio = height / old_width
new_height = int(width * aspect_ratio)
resized_frame = cv2.resize(frame, (width, new_height))
cv2.imwrite(f'tmp/frame_{i:04d}.jpg', resized_frame)
cap.release()
GPT-4VのAPIを使って画像データをBASE64でエンコードして送信するための関数です。
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
GPT-4V、GPT-4を使ってAPIをたたくメインの関数です。API_KEYをご自身のものに変更してください。
def main(args):
# 動画からフレームを抽出
extract_frames(args.input, args.n_split, args.resize_w)
client = OpenAI(
api_key="API_KEY",
)
explanations = ""
images = sorted([f for f in os.listdir("tmp") if f.endswith((".jpg"))])
for i, image in enumerate(tqdm(images)):
base64_image = encode_image(os.path.join("tmp", image))
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "100文字以内で画像を説明してください"},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{base64_image}"},
],
}
],
max_tokens=args.max_token_v,
)
# フレームごとの説明を蓄積
exp = response.choices[0].message.content
explanations += f"動画の{i + 1}/{len(images)}の位置の説明:{exp}\n"
# GPT-4で要約する
prompt = f"""以下は、ある動画を等間隔に区切ったときのそれぞれの説明です。
これらを最大で300字程度に要約し、この動画がどのような内容なのかまとめてください。
{args.instruction}
与えられた説明だけでは内容が不明確な場合、どのようなものが考えられるか推測してください。
以下、動画の説明です:
{explanations}
"""
with open("prompt.txt", "a", encoding="UTF-8") as f:
f.writelines(prompt + "\n")
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "user", "content": prompt},
],
max_tokens=args.max_token_s,
)
summary = response.choices[0].message.content
print(summary)
with open("results.txt", "a", encoding="UTF-8") as f:
f.writelines(summary + "\n")
さいごに、コマンドライン引数を使う設定です。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--input", type=str, required=True)
parser.add_argument("--instruction", type=str, default="")
parser.add_argument("--n_split", type=int, default=10)
parser.add_argument("--resize_w", type=int, default=800)
parser.add_argument("--max_token_v", type=int, default=300)
parser.add_argument("--max_token_s", type=int, default=1000)
args = parser.parse_args()
main(args)
実行例
サンプルのネコの動画

GPT-4Vによる各フレームの説明(全10枚に設定)
動画の1/10の位置の説明:窓辺に座る2匹の猫が外を見ています。左の猫は横を向いており、右の猫は上を見上げています。
動画の2/10の位置の説明:窓辺で向かい合う二匹の猫。一匹は室内、もう一匹は外にいる様子です。
動画の3/10の位置の説明:窓辺に座る2匹の猫が、向かい合っている様子。
動画の4/10の位置の説明:二匹の猫が窓辺に座っていて、外を見ています。左の猫は立っており、右の猫は座っています。
動画の5/10の位置の説明:窓辺で片方の猫がもう片方の猫の頭に手を置いている様子。
動画の6/10の位置の説明:窓辺で一匹の猫がもう一匹の猫の頭に手を置いているシルエット風の写真です。
動画の7/10の位置の説明:窓辺で片方が立ち、もう片方が座っている2匹の猫。立っている猫が前足で座っている猫の頭を軽く触れている。
動画の8/10の位置の説明:2匹の猫が窓辺で向かい合っており、片方がもう一方に手を伸ばしている様子です。
動画の9/10の位置の説明:二匹の猫が窓辺に座り、外を見つめています。大きな猫と小さな子猫です。
動画の10/10の位置の説明:写真は窓辺に座る2匹の猫を示しており、一方が成猫で、もう一方が子猫です。両方とも外を見ています。
GPT-4による動画全体の要約:短い動画ではありますが、「2匹の猫が窓辺で時間を共有している」ことがわかります。

音楽のMV
例として、「YOASOBI「アイドル」Official Music Video HIKAKIN Ver.」をお借りしました。
今回は「HIKAKINがMVをパロディしている」ことが動画タイトルからわかるので、GPT-4による要約時、「MVのパロディ」であることを考慮させてみます。
--instruction "この動画はYouTuber・HIKAKINが「アイドル」という名前の音楽MVをパロディしたものです。HIKAKINがどのような恰好なのかも合わせて教えてください。また、この動画で映し出される「アイドル」とはどのような雰囲気ですか?"
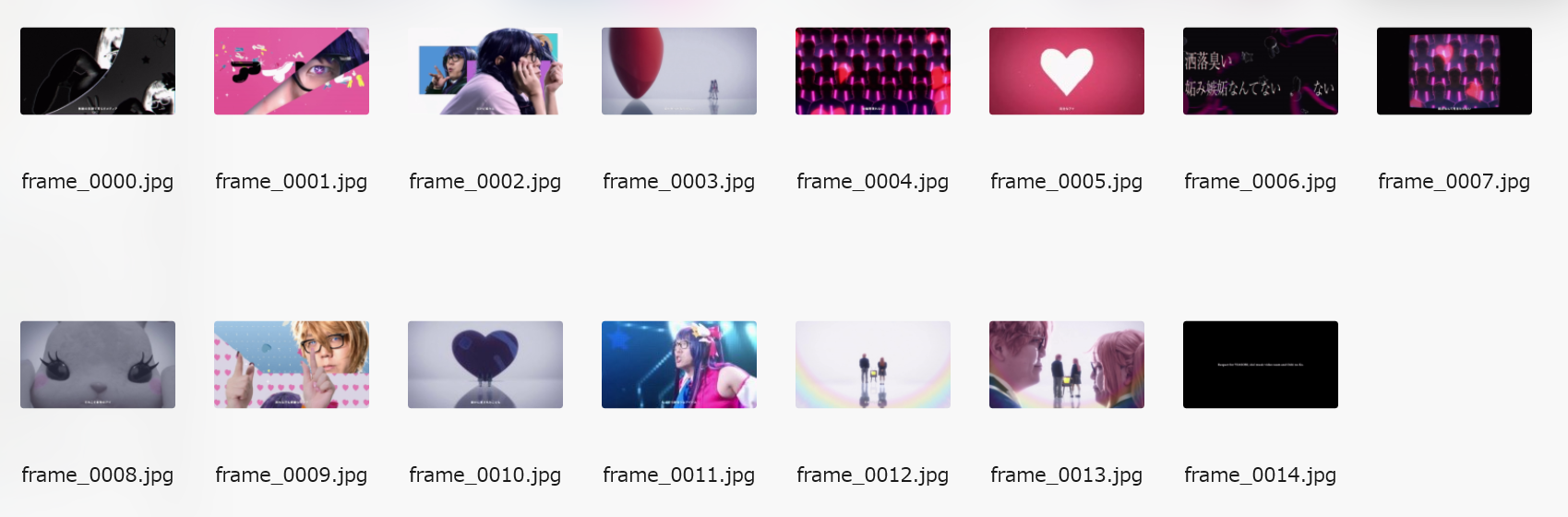
GPT-4Vによる各フレームの説明(全15枚に設定)
動画の1/15の位置の説明:モノクロのアートスタイルで、壊れた鏡の中と外にいる女性の顔の一部が映し出されています。アート的な雰囲気が感じられます。
動画の2/15の位置の説明:ピンクの背景にアニメ風のグラフィックと実写の目が映された画像。目には特徴的な模様があるコンタクトレンズが見えます。
動画の3/15の位置の説明:二人の姿がコラージュされた画像です。左は青い背景にメガネをかけた人物がピースサインをして、右はピンクの服を着た思い詰めた表情の人物がいます。
動画の4/15の位置の説明:大きな赤いバルーンと小さな2人の人物がいるシンプルな背景です。
動画の5/15の位置の説明:この画像は複数の人物のシルエットを赤と紫のネオンライトで照明したもので、未来的な雰囲気を持っています。画像に「金融資産類似なし」と書かれています。
動画の6/15の位置の説明:ピンクの背景に大きな白いハート形があり、周囲に小さな星がちりばめられていて、画像の下部に日本語の文字が書かれています。
動画の7/15の位置の説明:暗い背景にピンクとパープルの抽象的な模様があり、白い輪郭で描かれたさまざまな形の浮遊するオブジェクトと日本語のテキストが特徴のアートワークです。
動画の8/15の位置の説明:画像はカレイドスコープ効果を使用し、複数の男性の顔が対称的に繰り返されるデザインで、周囲はピンクと紫のネオンライトで照らされています。画面下には「夢みたんじゃ足りない」というテキストがあります。
動画の9/15の位置の説明:黒い大きな目とピンクのほっぺたがある、白っぽいぬいぐるみのクローズアップ写真です。
動画の10/15の位置の説明:写真はカラフルな背景とハート模様があり、メガネをかけた金髪の人物が指で何かを作っているポーズをしています。
動画の11/15の位置の説明:巨大なハート形のオブジェクトの前に二人の人物が手を繋いで立っています。光と影が幻想的な雰囲気を醸し出しています。
動画の12/15の位置の説明:メガネとカラフルなコスチュームを着た人物が、驚いた表情で何かを見ています。彼らはステージにいるようです。
動画の13/15の位置の説明:白い背景の前に、スーツケースを持った男性と女性が立っており、彼らの前には古い黄色いテレビがある。虹色の光が画面を照らしている。
動画の14/15の位置の説明:ピンク髪の二人が対峙し、中央にはその二人の背面があります。柔らかな光で満たされた幻想的な雰囲気が漂います。
動画の15/15の位置の説明:画像は、暗い背景に白い文字で「Respect for YOASOBI, idol music video team and Oshi no Ko.」と記載されており、特定のミュージカルアーティストやプロジェクトへの敬意を表しています。
GPT-4による動画全体の要約

指示を追加したことで、HIKAKINの恰好も教えてくれました。また、最後のフレームに「Oshi no ko」と表示されていたことから、表記は間違っているとは言え元の作品名までくみ取ることができていました。
動画は全く見ていないのに、GPT-4Vに動画見てもらったことで『あのMV、HIKAKINのカラフルな衣装ヤバいよねw』『ネオンの配色良くない?』『急に出てくるピンクのほっぺたのぬいぐるみ好き』というような会話ができてしまうのです。
忙しくて動画を見られないときにも、全力で『見た気になって友達に話したくなる』ツールができあがりました。
おわりに
お遊び程度に実装しましたが、動画の内容をテキストに起こすツールとしてはかなり有効であることがわかりました。GPT-4Vをうまく使うことで、さらに高度なことができそうですね!
最後までご覧いただきありがとうございました!