はじめに
好きなアバターを使って理想の対話ができるアプリを作りたい...
がしかし、3DCGアプリケーションで制作したアバターを使ったAI対話アプリの構築は、アプリを動かすPCのリソース要件が高かったり(特にGPU)、BlenderやUnityといった3DCGを扱うソフトのスキルが必須で、私にとってハードルが高い。。
ということで、今回は以下のコンセプトで対話システムを構築してみました。
- できる限り実装はPythonだけで完結させたい
- リップシンク、発話スピードなど対話システムとしての質はいったん無視
- dGPUを搭載していないPC環境でもアプリを動かしたい
- 手元のデスクトップにはGPUがあるので、VTuber向けの3Dアバター制作ソフトは一応動く
このコンセプトでサンプルアプリを作ったところ、こんな感じになりました。
- アバター:VRoid Studio → 3tene → 動画キャプチャー
- 対話生成:GPT-4o
- 音声認識:whisper-mic
- 音声合成:VOICEVOX ローカルAPI
機能
- リアルタイムの音声認識チャット
- チャット履歴の画面表示
- 対話に応じた画像表示
- 最初の挨拶、会話の終了検知

実装はGitHubにありますので、ぜひ改造したうえでご活用ください!
実装したアプリの概要
「イージービデオチャットボット」アプリ
- アバターをキャプチャした動画や、人間が話している様子を撮影した動画を使ったチャットボットのサンプルアプリです。
- 「待機中(口を閉じている)」「発話中(口を動かしている)」「対話開始(お辞儀、挨拶など)」の動画を用意するだけで、簡単にそのアバターや人間がAI対話アシスタントになります。
- 動画を用意する際は、ループ再生してもできるだけ最初と最後のつながりが自然になるように考慮してください。アシスタントの待機中または発話中の時間が長かった場合、その分動画がループ再生されるためです。
特徴
- 会話状況に応じて再生する動画を切り替えることで、疑似的に動画のアバター/人間がリアルタイムに話しているように見せることができる、「なんちゃって」対話アプリです。
- フリーの音声認識ライブラリ、フリーの音声合成ソフトを使い、リアルタイムに対話を行うことができます。
- 対話状況に応じて、画像を表示することができます。(カスタマイズには
main.pyを変更する必要があります) - 高性能なGPUを必要とする3DCGエンジンは不要です。より快適な動作のためにGeForce RTXシリーズ等のディスクリートGPUがあるとより良いですが、CPUのみのPCでも最低限動作するように設計しています。
制限
- Tkinterを利用し、GUI部品の画像を高速に再描画することで動画再生を実現しているため、CPUのスペックにより再生の滑らかさが異なります。
- 音声認識、音声合成にはローカルのモデルを利用しますので、アプリを実行するPCのスペックによって反応が遅くなることがあります。
- 対話画面は1920x1080で固定しています。画面のスケーリング設定によって対話画面が拡大され、ディスプレイからはみ出すことがあります。その場合、OSの表示倍率の設定を100%に変更してください。
- フルHD未満のディスプレイには非対応です。
実装方法
Pythonにデフォルトで搭載されているGUIモジュール「Tkinter」を活用して対話ウィンドウを実装しました。
主要な処理のシーケンスは以下のようにしました。
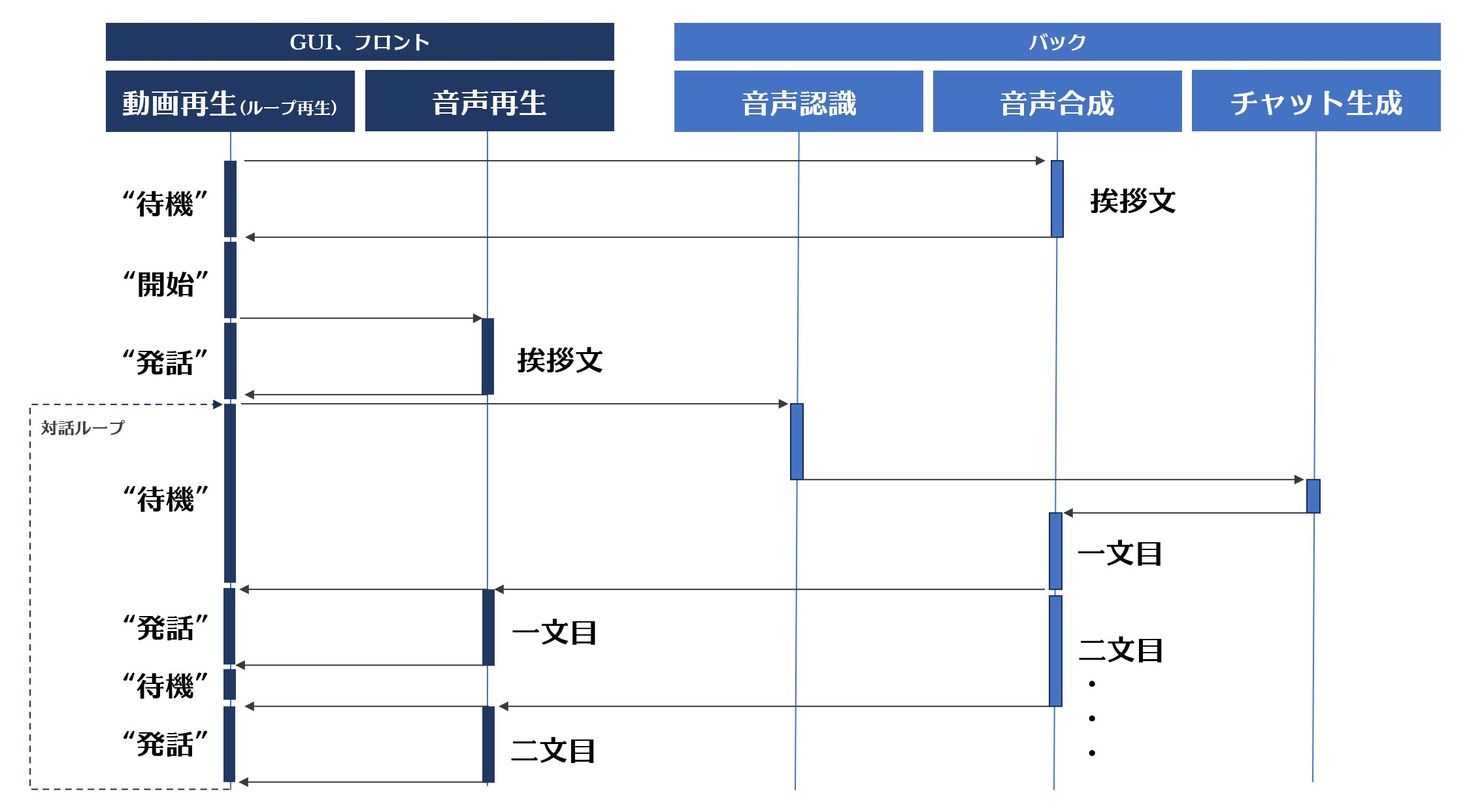
対話開始時の挙動
非同期に行いたい部分はthreading.Thread()を多用しています。。
-
初期メッセージを追加:
self.messagesにアシスタントの初期メッセージを追加 - メッセージを分割: 初期メッセージをセグメントに分割
- 音声生成スレッドの開始: 音声生成のためのスレッドを開始
- チャットバブルの作成: 各セグメントに対してチャットバブルを作成
SNSによくあるチャットの吹き出しを「チャットバブル」と定義します。


- ラベルの変更: アシスタントの状態を示すラベルを変更
- 音声ファイルの存在確認: 音声ファイルが存在するか確認
- ビデオの再生: 必要に応じてビデオを再生
- チャット表示の更新: チャットの表示を更新
- 音声の再生: 音声ファイルを再生
class EZVideoChatBotApp:
# ..(中略)..
def start_chat(self):
self.messages.append(
{"role": "assistant", "content": self.init_message}
)
assistant_respose_segments = tools.split_text(self.init_message)
gen_thread = threading.Thread(target=tts.generate_voice, args=(assistant_respose_segments,))
gen_thread.daemon = True
gen_thread.start()
for i, seg in enumerate(assistant_respose_segments):
if len(assistant_respose_segments) == 1:
mode = "single"
elif i == 0:
mode = "start"
elif i == len(assistant_respose_segments) - 1:
mode = "end"
else:
mode = "middle"
create_chat_bubble(seg, role="assistant", mode=mode)
self.change_label("assistant", Constants.GENERATING_VOICE_TEXT)
while True:
if os.path.exists(f"./audio/{i}.wav"):
break
if i == 0:
self.play_video(self.starting_video)
sleep(2.5)
self.change_label("assistant", Constants.ASSISTANT_SPEAKING_TEXT)
self.update_chat_display()
self.play_video(self.speaking_video)
tts.play_sound(f"./audio/{i}.wav")
self.play_video(self.waiting_video)
対話ループ
-
./chatsと./audioフォルダ内のファイルを削除 - チャット画面を更新し、チャットを開始
- 無限ループ内で以下の処理を実行:
-
./audioフォルダ内のファイルを削除 - ユーザーの音声入力を取得し、テキストに変換
- ユーザーの入力をチャットバブルに分割して表示
- チャット画面を更新
- アシスタントの応答を生成し、チャットバブルに分割して表示
- 特定のキーワードに応じて画像をオーバーレイ表示
- アシスタントの応答を音声に変換し、再生
- 必要に応じてチャット履歴と音声ファイルをリセット
-
def main_chat(self):
tools.delete_files_in_folder("./chats")
tools.delete_files_in_folder("./audio")
self.update_chat_display()
self.start_chat()
while True:
try:
tools.delete_files_in_folder("./audio")
self.change_label("user", Constants.LISTENING_TEXT)
user_input = self.stt_model.listen()
self.change_label("assistant", Constants.GENERATING_CHAT_TEXT)
self.messages.append(
{"role": "user", "content": user_input}
)
user_input_segments = tools.split_text(user_input)
for i, seg in enumerate(user_input_segments):
if len(user_input_segments) == 1:
mode = "single"
elif i == 0:
mode = "start"
elif i == len(user_input_segments) - 1:
mode = "end"
else:
mode = "middle"
create_chat_bubble(seg, role="user", mode=mode)
self.update_chat_display()
assistant_respose, reset = chat.run_completion(self.messages)
self.messages.append(
{"role": "assistant", "content": assistant_respose}
)
# Customize image display
if "クリーンマスター" in assistant_respose:
overlay_image = "./images/cleanmaster.png"
elif "エアロブック" in assistant_respose:
overlay_image = "./images/aerobook.png"
else:
overlay_image = None
assistant_respose_segments = tools.split_text(assistant_respose)
gen_thread = threading.Thread(target=tts.generate_voice, args=(assistant_respose_segments,))
gen_thread.daemon = True
gen_thread.start()
for i, seg in enumerate(assistant_respose_segments):
if i == 0:
mode = "start"
elif i == len(assistant_respose_segments) - 1:
mode = "end"
else:
mode = "middle"
create_chat_bubble(seg, role="assistant", mode=mode)
self.change_label("assistant", Constants.GENERATING_VOICE_TEXT)
while True:
if os.path.exists(f"./audio/{i}.wav"):
break
self.change_label("assistant", Constants.ASSISTANT_SPEAKING_TEXT)
self.update_chat_display(overlay_image=overlay_image)
self.play_video(self.speaking_video)
tts.play_sound(f"./audio/{i}.wav")
self.play_video(self.waiting_video)
if reset:
tools.delete_files_in_folder("./chats")
tools.delete_files_in_folder("./audio")
self.messages = [
{"role": "system", "content": self.system_prompt}
]
self.update_chat_display()
self.start_chat()
except Exception as e:
print(e)
対話生成
Llama-indexでGPT-4oのAPIを利用して、RAGデータを用いた会話生成を実装しました。
import openai
from llama_index.llms.openai import OpenAI
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.llms import ChatMessage
from constants import Constants
openai.api_key = Constants.OPENAI_API_KEY
llm = OpenAI(
model="gpt-4o",
temperature=0.5,
max_tokens=512,
streaming=True
)
documents = SimpleDirectoryReader("./rag").load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever()
def check_reset_strings(input_string, keywords):
return int(any(substring in input_string for substring in keywords))
def run_completion(messages):
user_query = messages[-1]["content"]
if check_reset_strings(user_query, Constants.RESET_KEYWORDS_USER):
return Constants.RESET_MESSAGE, 1
_messages = [
ChatMessage(
role=item['role'],
content=item['content']
)
for item in messages
]
nodes = retriever.retrieve(user_query)
context = "\n".join([node.node.text for node in nodes])
_messages[0].content = Constants.SYSTEM_PROMPT.replace("{{context}}", context)
response_text = ""
response_stream = llm.stream_chat(_messages)
for response in response_stream:
response_text += response.delta
return response_text, check_reset_strings(response_text, Constants.RESET_KEYWORDS_ASSISTANT)
def run_completion_simple(messages):
user_query = messages[-1]["content"]
if check_reset_strings(user_query, Constants.RESET_KEYWORDS_USER):
return Constants.RESET_MESSAGE, 1
response = openai.chat.completions.create(
model="gpt-4o",
messages=messages,
)
assistant_text = response.choices[0].message.content
return assistant_text, check_reset_strings(assistant_text, Constants.RESET_KEYWORDS_ASSISTANT)
音声認識(STT)
Whisperのラッパーモジュール「whisper-mic」を使うことで、特別な実装をしなくてもマイクからの入力を自動的に受け取りSTTができました。
チャットバブルの生成のため、文章の分割を行っています。
from whisper_mic import WhisperMic
class STTModel:
def __init__(self):
self.model = WhisperMic(model="small")
def listen(self):
result = self.model.listen()
result = result.replace(" ", "。").replace("「", "").replace("」", "")
if not result.endswith(("。", "!", "?", "!", "?")):
result += "。"
return result
音声合成(TTS)
フリーの高機能音声合成ソフト「VOICEVOX」のローカルホストに起動するAPIを活用して、Pythonからも簡単に音声合成を投げることができました。
①文章の解析、②音声合成の2つの処理を投げる必要があります。今回はイントネーションなどのパラメータ調整はせずに、①で受け取ったパラメータをそのまま②に渡して生成を行いました。
import requests
from pydub import AudioSegment
from pydub.playback import play
from constants import Constants
def play_sound(sound_path):
audio = AudioSegment.from_wav(sound_path)
play(audio)
def generate_voice(texts):
for i, text in enumerate(texts):
url = Constants.VOICEVOX_HOST + "/audio_query"
params = {
'text': text,
'speaker': Constants.VOICEVOX_SPEAKER_ID
}
response = requests.post(url, params=params)
query = response.text
# query = query.replace('"pitchScale":0.0', '"pitchScale":0.02') # Customize parameters
print(query)
query = query.encode('utf-8')
url = Constants.VOICEVOX_HOST + "/synthesis"
headers = {
'Content-Type': 'application/json'
}
params = {
'speaker': Constants.VOICEVOX_SPEAKER_ID
}
response = requests.post(url, headers=headers, params=params, data=query)
if response.status_code == 200:
with open(f'./audio/{i}.wav', 'wb') as file:
file.write(response.content)
print("Command executed successfully.")
else:
print(f"Error executing command: {response.status_code}")
# generate_voice("こんにちは。")
チャットバブルの生成
ビジュアル的にも、この後連続して吹き出しが出るかどうかを分かりやすくするためにも、吹き出しが連結したような見た目になるように実装しました。
場合分けなどでコードが冗長な見た目になってしまったので、詳しくはGitHubのリポジトリをご覧ください。
開始の吹き出し
- 一辺を角張るようにして、下に続くことを伝えます。

中間の吹き出し

終了の吹き出し
- 下側は角を丸くして、会話の終了を示します。

単一の吹き出し
- 全部の角を丸くして、単体の吹き出しを表現します。

アバター動画の用意
今回はVRoid Studioで作ったアバターを3teneで動かし、それをキャプチャーしてAviUtlで簡単に整えました。
今回は対話を表現するため、以下の3つを動画ファイルとして書き出しました。
- 待機中(口を閉じて待っている)
- 発話中(少し頭を動かしながら口を動かす)
- 最初の挨拶(お辞儀)
おわりに
VOICEVOX、VRoid Studio等比較的簡単に使えるアプリを活用して、Pythonだけで対話システムを実装することができました!
今回全く無視したリップシンク、会話の生成速度、発話速度、感情表現、、、などを考えると「対話システム」といえるかどうかはわかりませんが、簡単に動作する対話アプリとしてはいろいろな用途で使えそうです。