はじめに
令和の今も広く使われている、古くから存在するオーディオ形式としてMP3(MPEG-1 Audio Layer 3)、M4A(MPEG-4 Audio)があると思いますが、CD音源などを非可逆圧縮して持ち歩きたいとき結局どちらが良いのか、どれくらいのビットレートが妥当なのか調べたくなり、簡単に実験してみました。
今回は1曲のみを様々なビットレートで比較した結果を記載しています。
エンコードの品質や、楽曲によって結果が異なる可能性がありますので参考としてご覧ください。
分析内容
- 巷では、「M4AはMP3よりも後に開発された形式のため同じビットレートでもM4Aの方が音質が良い」 と言われていますが、手元の音楽データで本当か試してみました。
- また、「圧縮音源は人間の耳に聞こえにくい高周波数成分を削ることでサイズを小さくしている」 ということで、高周波成分の損失を比較できるようにしました。
比較に使用した楽曲
特にハイハットやシンバルが効果的に使われている曲が良いと思い、こちらを選びました。
(+CDを持っていて非圧縮音源が手元にあること)
令和の時代、配信が主になっている中で「非圧縮音源を円盤として持っているぞ!」と思えるのはロマンがあると思います。
(最近FLAC形式もオンラインで買えますが、やはり物理的に所有しているのは良いですね)
「サインはB -New Arrange Ver.- / B小町」
TVアニメ「【推しの子】」キャラクターソングCD Vol.2
使用したヘッドフォン・イヤホン
趣味の範囲ですが、普段の音源制作で愛用している以下の2機種を使って音を聴きました。
- ソニー MDR-MV1
- Final A5000
MP3・M4A変換処理
CDから取り込んだFLAC音源(=オリジナル音源)から、ffmpegを使い、今回は以下のコマンドで変換を実施しました(=圧縮音源)。より品質の高いエンコーダを使うことでさらに音質が上がることが期待できます。
ffmpeg -i "A.flac" -vn -acodec aac -ab 320k -aac_coder twoloop "B_320.m4a"
ffmpeg -i "A.flac" -vn -acodec libmp3lame -ab 320k "B_320.mp3"
分析処理の実装
定量評価指標
今回の実験では以下の指標を計算しました。
| 指標 | 意味 | 単位 | 値が小さい/大きいほど良い |
|---|---|---|---|
| MSE | オリジナルと圧縮音源の振幅差の二乗平均 | 無次元 | 小さいほど良い |
| PSNR | ノイズ耐性の評価。音質の良さをdBで表現 | dB | 大きいほど良い |
| MAE | オリジナルと圧縮音源の振幅差の絶対値平均 | 無次元 | 小さいほど良い |
| SNR | 信号エネルギーとノイズエネルギーの比 | dB | 大きいほど良い |
| High Freq Loss | 高周波帯域におけるオリジナルと圧縮音源のスペクトルエネルギーの差分 | 無次元 | 小さいほど良い |
1. 平均二乗誤差 (MSE: Mean Squared Error) ↓
- オリジナル音源と圧縮音源の振幅差の二乗平均を計算する指標。
- 値が小さいほど、2つの信号が近いことを示す。
- 直感的には「圧縮による音声の劣化の総量」を表す。
$$
\text{MSE} = \frac{1}{N} \sum_{i=1}^N (x_i - y_i)^2
$$
- $ N $: 信号のデータ点数
- $ x_i $: オリジナル音源の振幅値
- $ y_i $: 圧縮音源の振幅値
2. ピーク信号対雑音比 (PSNR: Peak Signal-to-Noise Ratio) ↑
- オリジナル音源に対して、圧縮音源がどれだけノイズに耐えているかを評価する指標。
- 単位はデシベル (dB) で、値が大きいほど音質が良いとされる。
$$
\text{PSNR} = 10 \cdot \log_{10} \left(\frac{\max(x_i)^2}{\text{MSE}}\right)
$$
- $\max(x_i)$: オリジナル音源の振幅の最大値
- $\text{MSE}$: 平均二乗誤差
3. 平均絶対誤差 (MAE: Mean Absolute Error) ↓
- オリジナル音源と圧縮音源の振幅差の絶対値の平均を計算する指標。
- MSEよりも極端な外れ値に対して影響を受けにくい。
$$
\text{MAE} = \frac{1}{N} \sum_{i=1}^N |x_i - y_i|
$$
- $ N $: 信号のデータ点数
- $ x_i $: オリジナル音源の振幅値
- $ y_i $: 圧縮音源の振幅値
4. 信号対雑音比 (SNR: Signal-to-Noise Ratio) ↑
- オリジナル音源の信号エネルギーに対して、圧縮によるノイズエネルギーの割合を示す。
- 単位はデシベル (dB) で、値が大きいほど音質が良い。
$$
\text{SNR} = 10 \cdot \log_{10} \left(\frac{\sum_{i=1}^N x_i^2}{\sum_{i=1}^N (x_i - y_i)^2}\right)
$$
- $ x_i $: オリジナル音源の振幅値
- $ y_i $: 圧縮音源の振幅値
5. 高周波エネルギー損失 (オリジナル) ↓
- 10kHz~20kHzの高周波帯域におけるオリジナル音源と圧縮音源のエネルギー差を示す。
- 高音域(ハイハットやシンバル)の劣化を定量的に評価できる。
$$
\text{High Frequency Loss} = \sum_{f=10 \text{kHz}}^{20 \text{kHz}} |S_x(f) - S_y(f)|
$$
- $ S_x(f) $: オリジナル音源の周波数 $ f $ におけるスペクトル振幅
- $ S_y(f) $: 圧縮音源の周波数 $ f $ におけるスペクトル振幅
実装全体
import argparse
import numpy as np
import matplotlib.pyplot as plt
import librosa
def load_audio(file_path, sample_rate=44100):
# 音声ファイルを読み込み
audio, sr = librosa.load(file_path, sr=sample_rate, mono=True)
return audio, sr
def calculate_spectrum(audio, sample_rate, n_fft=512):
# STFT(短時間フーリエ変換)を使用して周波数スペクトルを計算
# n_fftを小さくすることで時間分解能を高め、一瞬の高音成分を捉える
spectrum = np.abs(librosa.stft(audio, n_fft=n_fft))
freqs = np.linspace(0, sample_rate / 2, spectrum.shape[0])
return freqs, np.mean(spectrum, axis=1)
def calculate_metrics(original, compressed, freqs):
# MSE(平均二乗誤差)
mse = np.mean((original - compressed) ** 2)
# PSNR(ピーク信号対雑音比)
psnr = 10 * np.log10(1 / mse) if mse > 0 else float('inf')
# MAE(平均絶対誤差)
mae = np.mean(np.abs(original - compressed))
# SNR(信号対雑音比)
signal_power = np.sum(original ** 2)
noise_power = np.sum((original - compressed) ** 2)
snr = 10 * np.log10(signal_power / noise_power) if noise_power > 0 else float('inf')
# 高音域(10kHz〜20kHz)のエネルギー損失
high_freq_loss = np.sum(np.abs(original[(freqs >= 10000) & (freqs <= 20000)] -
compressed[(freqs >= 10000) & (freqs <= 20000)]))
return mse, psnr, mae, snr, high_freq_loss
def plot_results(freqs, spectrum_a, spectrum_b, spectrum_diff, metrics):
plt.figure(figsize=(16, 8))
# オリジナル音源と圧縮音源のスペクトルを重ねてプロット
plt.plot(freqs, spectrum_a, label="Original (A)", color="blue", alpha=0.7)
plt.plot(freqs, spectrum_b, label="Compressed (B)", color="orange", alpha=0.7)
# X軸・Y軸を対数スケールに設定
plt.xscale("log")
plt.yscale("log")
plt.xlim(20, 20000) # 20Hz - 20kHz
plt.xlabel("Frequency (Hz) (Log Scale)")
plt.ylabel("Amplitude (Log Scale)")
plt.title("Frequency Spectrum (Logarithmic Scale)")
plt.legend()
plt.grid(which="both", linestyle="--", linewidth=0.5)
# メトリクス表示
metrics_text = (
f"MSE: {metrics[0]:.6f}\n"
f"PSNR: {metrics[1]:.2f} dB\n"
f"MAE: {metrics[2]:.6f}\n"
f"SNR: {metrics[3]:.2f} dB\n"
f"High-Frequency Loss (10kHz-20kHz): {metrics[4]:.6f}"
)
plt.gcf().text(0.7, 0.5, metrics_text, fontsize=12, bbox=dict(facecolor="white", alpha=0.5))
plt.show()
def main():
# コマンドライン引数のパーサーを設定
parser = argparse.ArgumentParser(description="Compare the frequency spectrum of two audio files.")
parser.add_argument("--input_a", type=str, required=True, help="Path to the original audio file (A).")
parser.add_argument("--input_b", type=str, required=True, help="Path to the compressed audio file (B).")
args = parser.parse_args()
# 音声データを読み込む
audio_a, sr_a = load_audio(args.input_a)
audio_b, sr_b = load_audio(args.input_b)
# 両方の音源のサンプリングレートが異なる場合、リサンプリング
if sr_a != sr_b:
audio_b = librosa.resample(audio_b, orig_sr=sr_b, target_sr=sr_a)
# 周波数スペクトルを計算
freqs, spectrum_a = calculate_spectrum(audio_a, sr_a)
_, spectrum_b = calculate_spectrum(audio_b, sr_a)
# 差分スペクトルを計算
spectrum_diff = np.abs(spectrum_a - spectrum_b)
# メトリクスを計算
mse, psnr, mae, snr, high_freq_loss = calculate_metrics(spectrum_a, spectrum_b, freqs)
# 結果をプロット
plot_results(freqs, spectrum_a, spectrum_b, spectrum_diff, (mse, psnr, mae, snr, high_freq_loss))
if __name__ == "__main__":
main()
分析結果(FLAC vs 各形式・ビットレート)
FLAC vs M4A
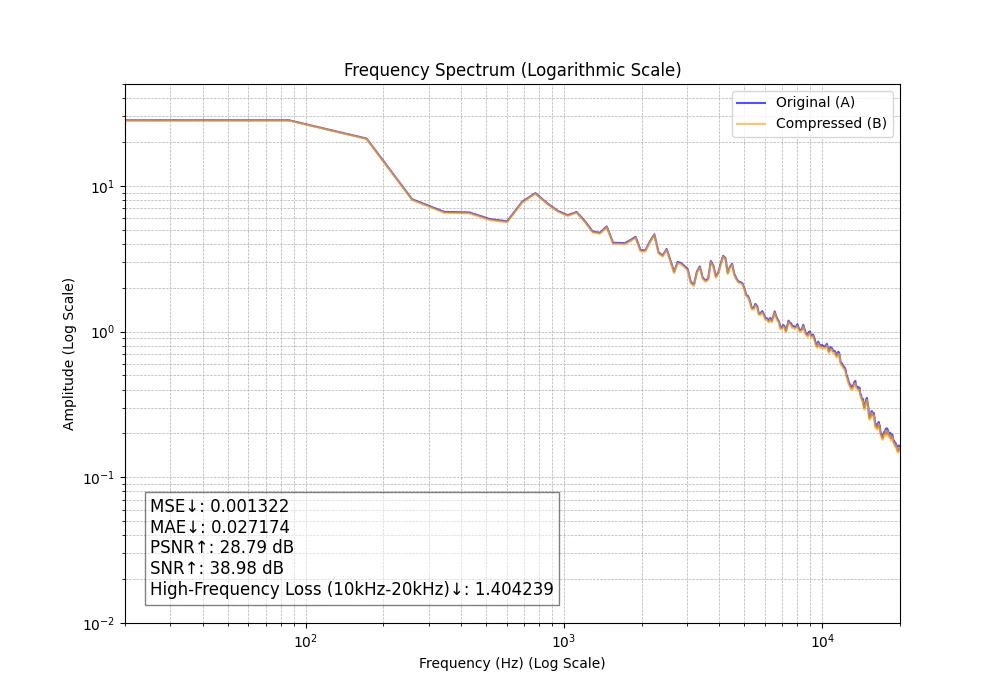
M4A 320kbps
グラフが少しずれていて損失がすでに発生しています。聞いた感じではほぼ違いがわかりません。
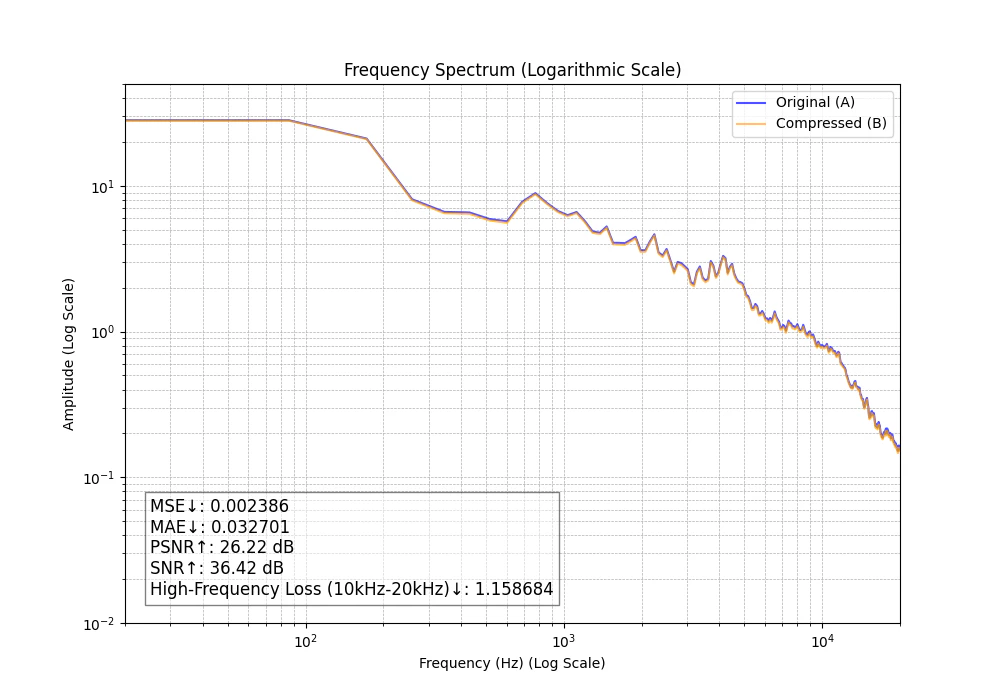
M4A 256kbps
グラフのずれは320kbpsとあまり変化がないように見えますが、定量評価上は損失が大きくなっています。
こちらもほぼ違いがわかりませんが、言われてみると「FLACと比べると音が少し違うかも」という印象が出てきましたがあまり気になりません。
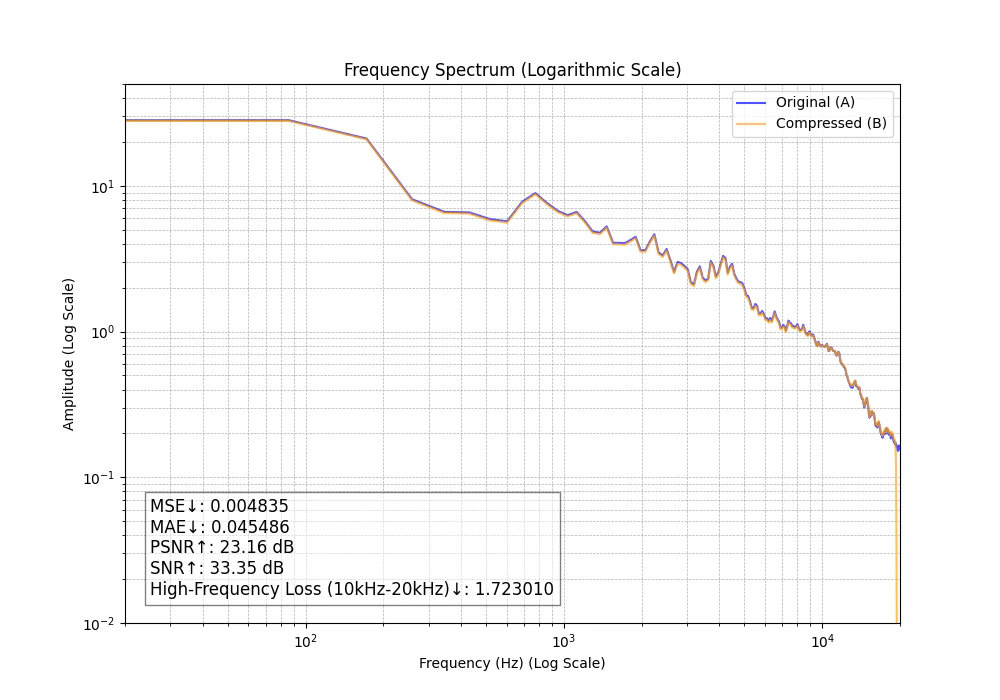
M4A 192kbps
グラフにも高周波数のカットが見えてきました(オレンジ線右端)。ヘッドフォン、イヤホンで聞いても、ハイハットやシンバルの音が若干ギザギザして耳に刺さります。
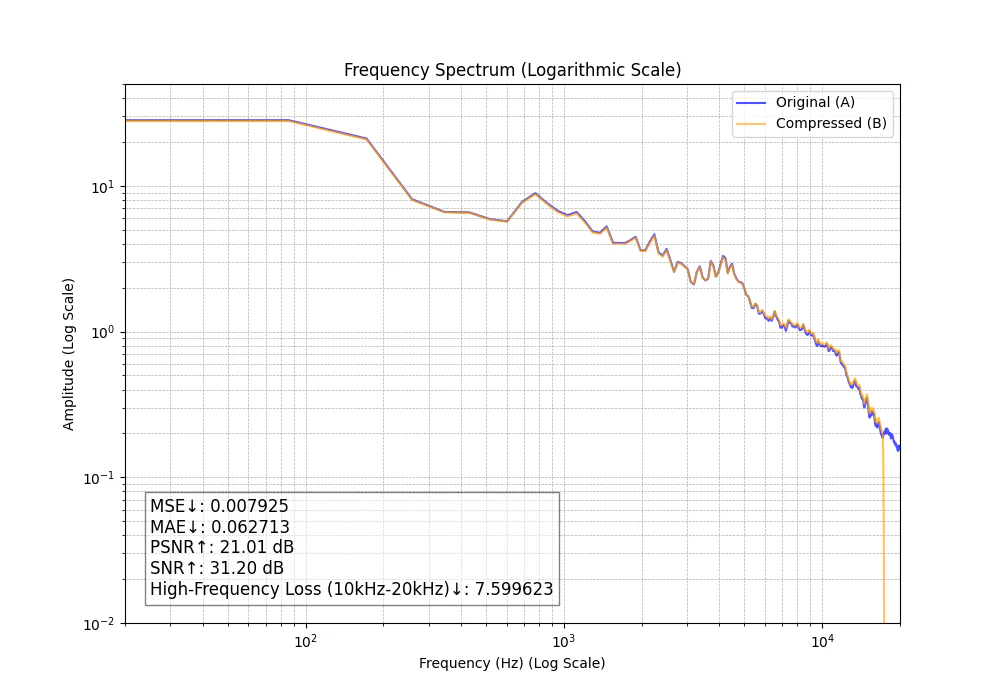
M4A 128kbps
高周波数のカット位置が左にずれています。やはり高い音がザラザラして音楽として劣化してしまいました。
FLAC vs MP3
MP3 320kbps
こちらもグラフが少しずれていて損失が発生していますが、M4A 320kbpsより損失が小さい指標が多い反面、若干グラフの右端に20kHzのカットが見えます。
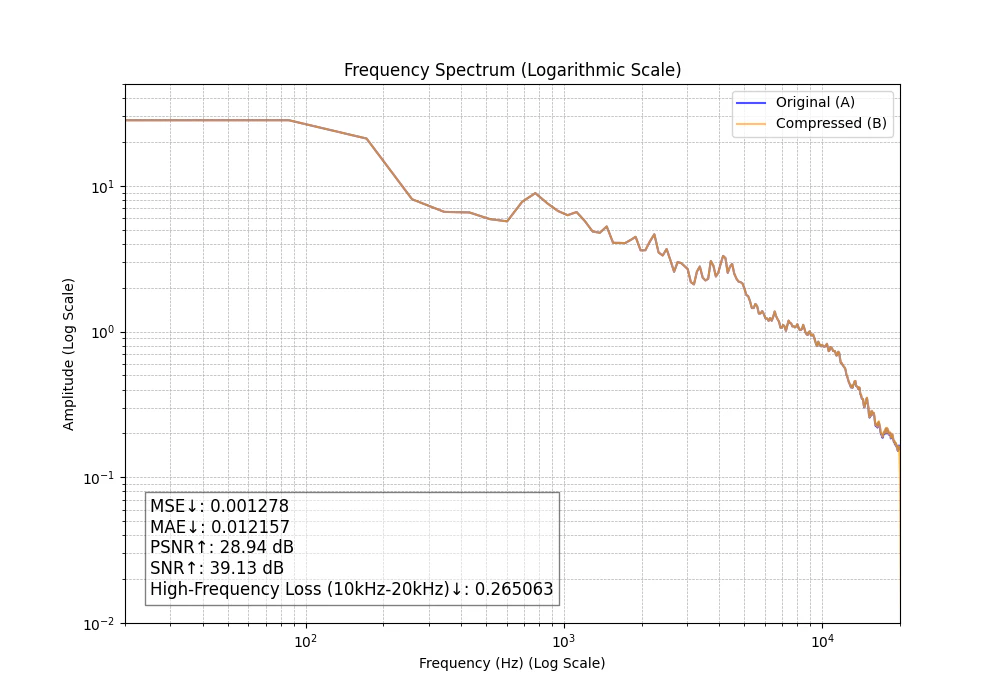
MP3 256kbps
M4A 256kbpsと比べると、高周波数カットが早い段階で見えてきています。
定量指標ではM4Aとあまり変わりませんが、高周波数の損失が大きくなっています。耳で聞いても、M4Aの192kbpsくらいの音質(パーカッションが少しザラザラ)に聞こえることがあります。
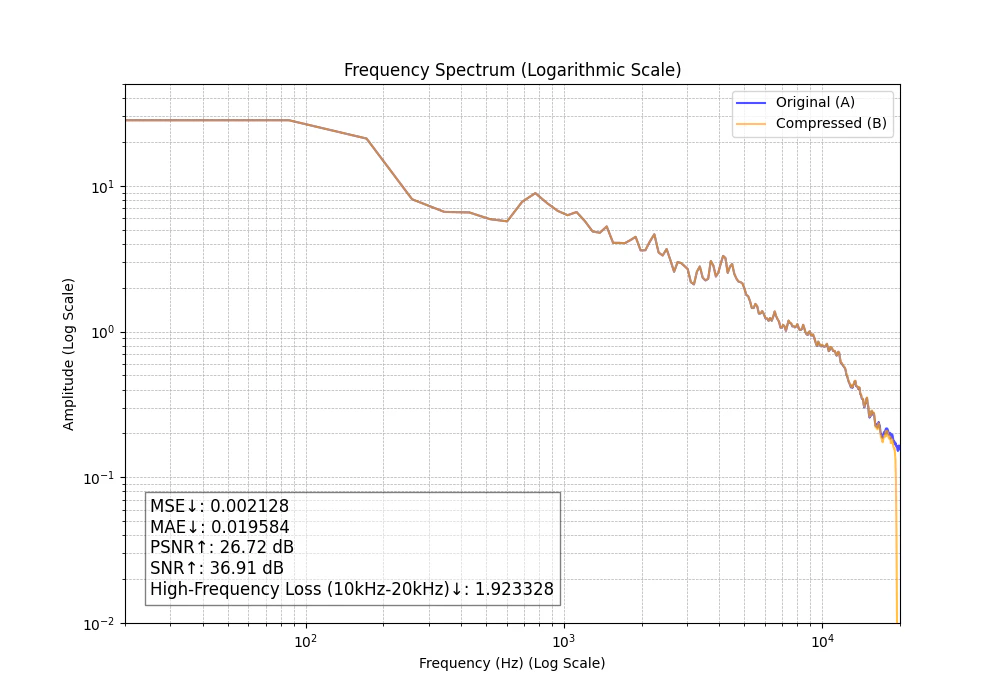
MP3 192kbps
高周波数のカット位置が左に移動し大きく崩れました。特にオープンハイハットの音のザラザラが気になります。
定量評価の結果も含め「MP3 192kbpsはないな」と確信が持てます。
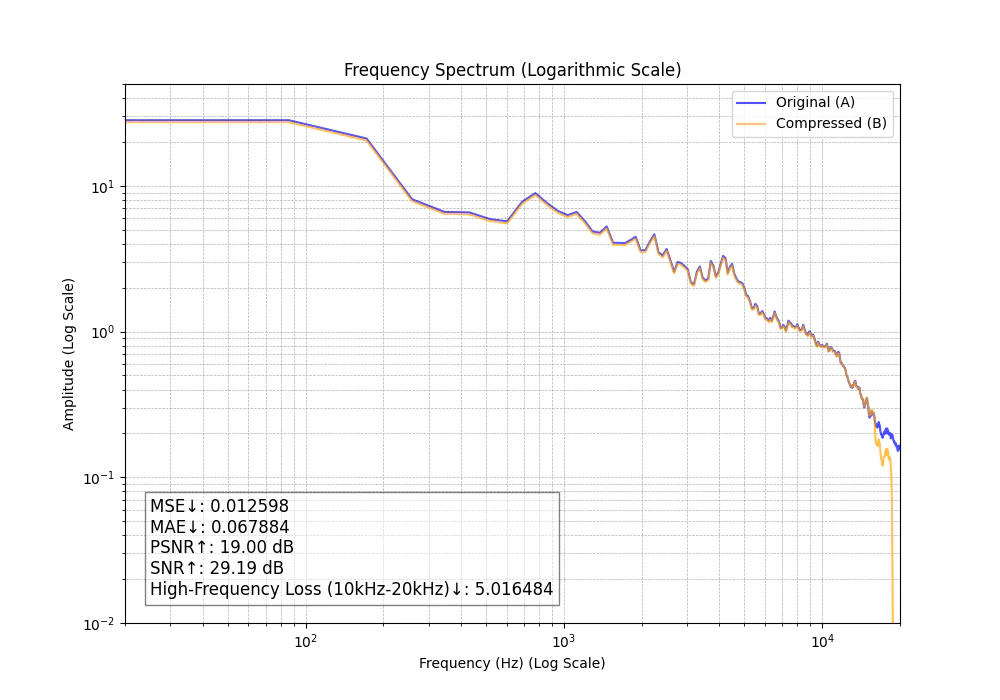
MP3 128kbps
綺麗に崖のように高周波数がカットされています。ハイハットやシンバルの音が気になるどころか、埋もれて聞き取れなくなる部分もありました。
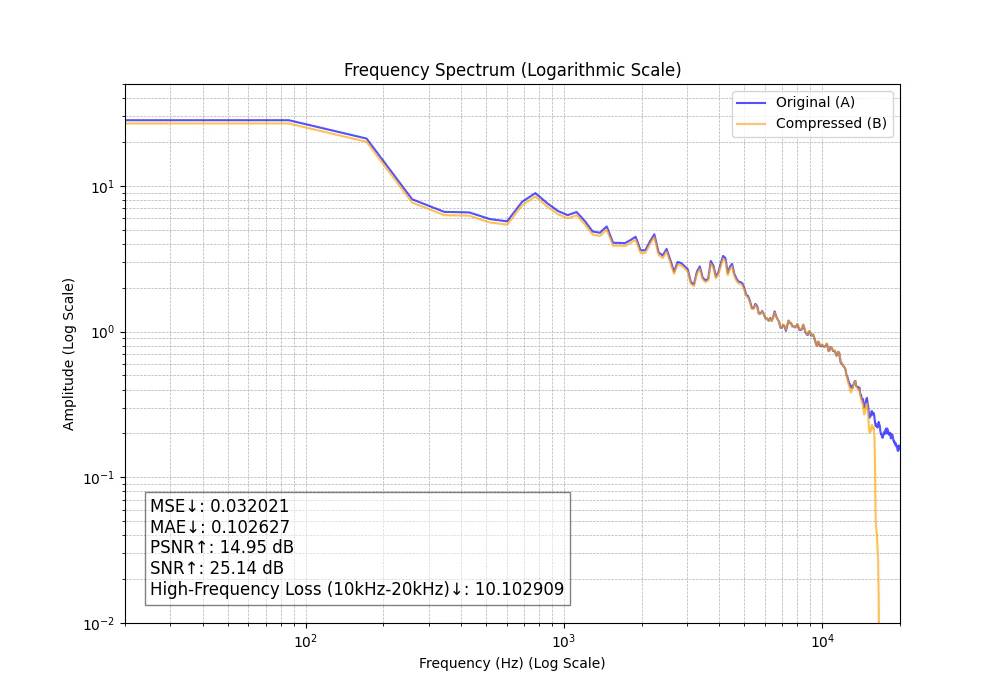
分析結果比較
形式・ビットレートごとの比較
この評価結果からは、MP3 320kbpsがすべての指標で最も良い結果でした。
しかし、MP3の192kbps以下は顕著に劣化が表れています。一方、M4Aは192kbpsを下回ってもMP3程劣化していないということも分かりました。
MP3、M4Aに変換する際のエンコーダによって結果が異なる可能性があります。
| ビットレート (kbps) | 形式 | MSE ↓ | MAE ↓ | PSNR ↑ | SNR ↑ | High Freq Loss ↓ |
|---|---|---|---|---|---|---|
| 320 | m4a | 0.00132 | 0.0272 | 28.79 | 38.98 | 1.404 |
| 256 | m4a | 0.00239 | 0.0327 | 26.22 | 36.42 | 1.159 |
| 192 | m4a | 0.00484 | 0.0455 | 23.16 | 33.35 | 1.723 |
| 128 | m4a | 0.00792 | 0.0627 | 21.01 | 31.20 | 7.600 |
| 320 | mp3 | 0.00128 | 0.0122 | 28.94 | 39.13 | 0.265 |
| 256 | mp3 | 0.00213 | 0.0196 | 26.72 | 36.91 | 1.923 |
| 192 | mp3 | 0.0126 | 0.0679 | 19.00 | 29.19 | 5.016 |
| 128 | mp3 | 0.0320 | 0.1026 | 14.95 | 25.14 | 10.10 |
同じビットレートの差分(M4A - MP3)
- 「↓」の指標については、マイナス値になっていればM4Aの方が評価が高い
- 「↑」の指標については、プラス値になっていればM4Aの方が評価が高い
となります。
| ビットレート | 形式 | MSE↓ | MAE↓ | PSNR↑ | SNR↑ | High Freq Loss↓ |
|---|---|---|---|---|---|---|
| 320 | m4a | 4.381E-05 | 0.0150 | -0.1464 | -0.1464 | 1.1392 |
| 256 | m4a | 2.580E-04 | 0.0131 | -0.4970 | -0.4970 | -0.7646 |
| 192 | m4a | -7.763E-03 | -0.0224 | 4.1590 | 4.1589 | -3.2935 |
| 128 | m4a | -2.410E-02 | -0.0399 | 6.0646 | 6.0646 | -2.5033 |
この結果を見ると、320kbps、256kbpsではMP3の方がよいという結果になりましたが、192kbps以下では明らかにM4Aの方が評価が良いことが分かります。
まとめ
今回は1曲のみの比較のため一概にこれが良いとは言えませんが、定量評価の傾向として以下をつかめました。
- 192kbps以下ならM4Aの方が劣化を抑えられる傾向にある
- 256~320kbpsならMP3とM4Aはあまり変わらないが、MP3 256kbpsは劣化が分かるときがある
しかしながら、M4Aの192kbpsでも損失(特に高周波数成分)がほんの若干耳にわかるレベルでしたので、たとえ劣化をMP3より抑えられたとしても、あまり音楽の保存用途として使えるビットレートではなさそうです。
ということで、個人的な私の環境においては、もし非可逆圧縮するなら「256kbpsならM4A、320kbpsならMP3・M4Aどちらでも好きな方」を選ぶという方向性に至りました。
(ほかの曲でも試してみてさらに詳しい傾向をつかみたいですが、どのくらいのファイルサイズを許容できるかの観点も入ってきます)
楽曲やエンコーダの品質に依存する部分だと思いますので、ぜひお手元のデータで試していただければと思います。