更新
2023/04/27時点最新バージョンv5.0.3においても、以下の作業の内容は変わりません。
モデルのサイズが大きくなり、より精度が上がっています!
GUIベースの使いやすいアプリに「Ultimate Vocal Remover」がありますが、同等かそれ以上の効果があるように思います。
個人的にはこちらのモデル(この記事のモデル)の方が好きで愛用しています!
しかも、手元にボーカル入り+オリジナルカラオケの音源があれば、独自のモデルも学習できます^^
はじめに
唐突ですが、「ボーカル入り音楽から歌声だけを消したい」「歌声だけ取り出してみたい」と思ったことはありませんか?
AI、ディープラーニングと聞くと、よく画像や動画を変換したり認識したりするものが多いと思います。
実は画像処理だけでなく、音声処理においても研究が盛んにおこなわれており、
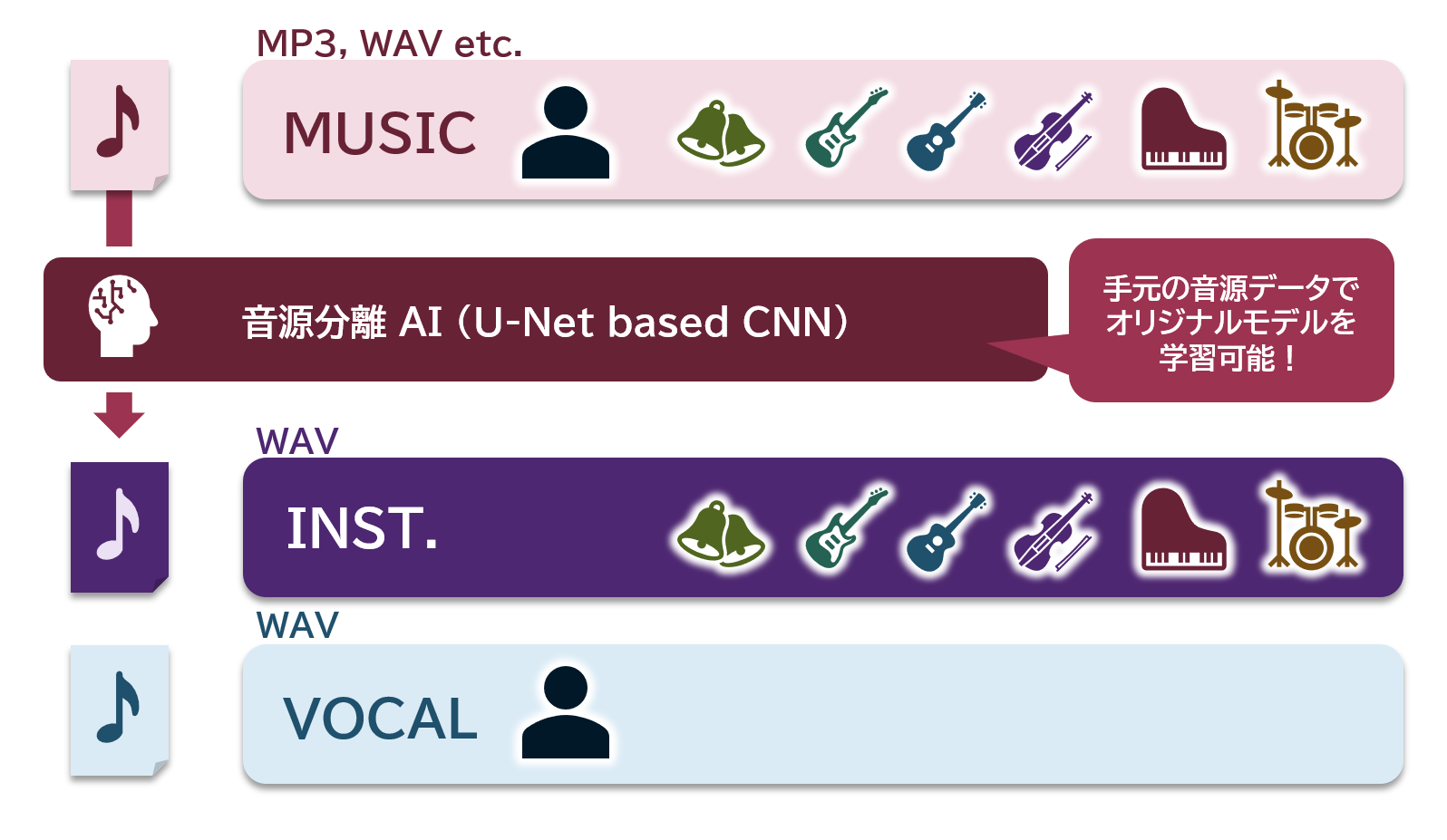
歌入り音源からインスト音源(伴奏、バッキング・トラック、オリジナル・カラオケとも言われます)と、歌声のみの音源に分離することもできます!!
私の趣味ではよく音楽を耳コピで打ち込み(音源を聴いてパソコン上で各楽器を譜面に起こすことをいいます)、カラオケ音源を制作して歌の練習に使ってもらったり、VTuberやライバーの方々の配信活動に使っていただいたりという活動を行っていますが、この技術を利用して生成した伴奏音源が打ち込みに非常に重宝しています。(特にオリジナル・カラオケトラックが配信・販売されていない曲)
Pythonを使うことで、ローカル環境で簡単に音源を分離させることができます。この記事ではその方法をご紹介します。
1. 動作確認環境
以下の環境で動作することを確認しました。
| 項目 | |
|---|---|
| OS | Windows 10 ver 22H2 |
| CPU | intel Core i7-7700 |
| GPU | NVIDIA GeForce RTX 2080 Ti (VRAM 11GB) |
| メインメモリ | 16GB |
| CUDA | 11.0 |
| Python | WinPython 3.8.7 |
| PyTorch | 1.12.1+cu113 |
2. 利用する技術の簡単な解説
この記事では以下のGitHubリポジトリを利用させていただきました。
「vocal-remover」/tsurumeso
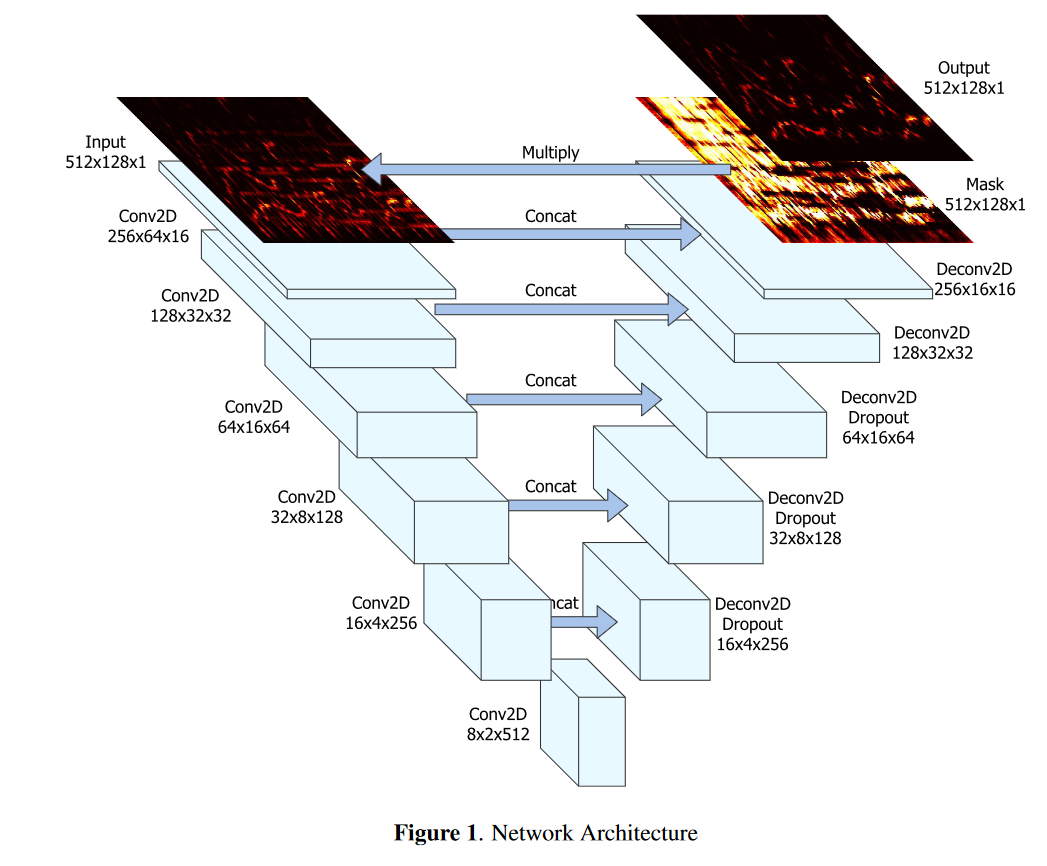
このリポジトリは、以下の論文が主にベースになっています。以下、引用している図はこの論文が出典です。
Jansson, Andreas, et al. "Singing voice separation with deep u-net convolutional networks." (2017).
音声処理の分野では、フーリエ変換による周波数領域のデータを扱うことが多く、この技術もこれを利用しています。
数年前「pix2pix」で注目を浴びた「U-Net」構造のCNNを応用しています。
ポイント
音楽は時系列データとして見ることができるため近年はRNNを応用している例も多いですが、この技術は時間と周波数領域間のデータを画像として見立てています。
私も大学時代の研究でU-Netには大変お世話になりました。
IEEE国際会議「SMC 2020」採択論文「単一スナップショット画像からの全天球画像生成」
Keisuke Okubo, and Takao Yamanaka. "Omni-Directional Image Generation from Single Snapshot Image." 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2020.
実際の伴奏音源とボーカル入り音源、ボーカルのみ音源を学習データとし、教師あり学習で学習させています。
3. 実行準備
- GitHubリポジトリから最新版をダウンロードし、任意のフォルダに配置します。
- 必要なライブラリをインストールします。
cd C:\hoge\hoge\vocal-remover
pip install -r requirements.txt
- 推論時に実行するinference.pyを必要に応じて変更します。
- 出力時に画像を一緒に保存する(周波数領域のデータを画像として保存できます)ここではデフォルトで無効にしておきます。
p.add_argument('--output_image', '-I', action='store_true', default=False)
- 出力フォルダを変更する(デフォルトで新しく作った「output」フォルダ内に分離後の音源が保存されるようにします)
p.add_argument('--output_dir', '-o', type=str, default="output")
- デフォルトでGPUを利用する
p.add_argument('--gpu', '-g', type=int, default=0)
4. 実行
推論プログラムがあるフォルダと同じ場所に、分離させたい音源データをコピーします。
あとは、以下のコマンドを実行して十数秒待つだけで分離できます!
python inference.py -i "input.mp3"
分離が完了すると以下のようなファイル名で音源データが保存されます。
output\input_Instruments.wav # インスト音源
output\input_Vocals.wav # ボーカルのみ音源
音楽再生ソフトで聴いてみてください。
5. 実行結果
分離結果の音源をこの場で共有したいところですが、一般の楽曲の場合著作権の問題や、無料音楽素材サイトの場合でもAIを利用した音源の扱いは難しいため控えさせていただきます。
ある楽曲の波形だけを見るとこのような形になっています。
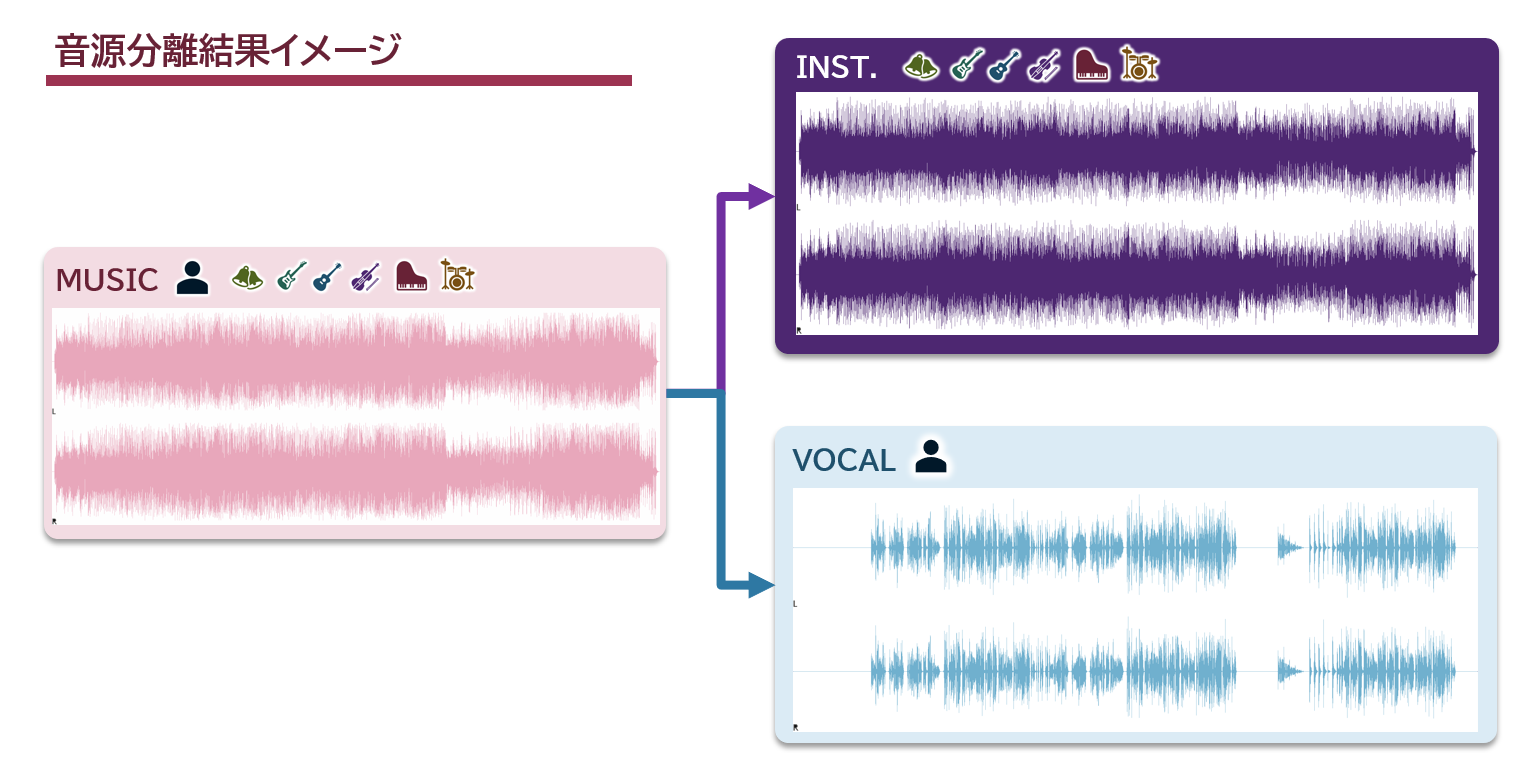
あくまで個人的な感覚ですが、非常にきれいに歌声を分離できています。

おわりに
Pythonを使って簡単に音源を分離する方法をご紹介しました。
こちらの実装は手元の音源データを用いてオリジナルモデルを学習することもできるため、ぜひお試しください。
「歌声を消す/だけ抽出する」というタスクだけでなく、特定の楽器の音を抽出するようなモデルも作成できるかもしれません。