はじめに
Pythonだけで、簡易的にサウンド入力デバイス/ループバックの出力デバイスを選択し、その音を録音できるアプリを作ってみました(主にWindows向け)。
GUIの実装にはTKinterの拡張モジュール「CustomTKinter」を利用しました。
※ 現時点の実装には不具合があるため、一度に長時間の録音や(10分以上)、消失したくない重要な音声の録音には使わないでください。
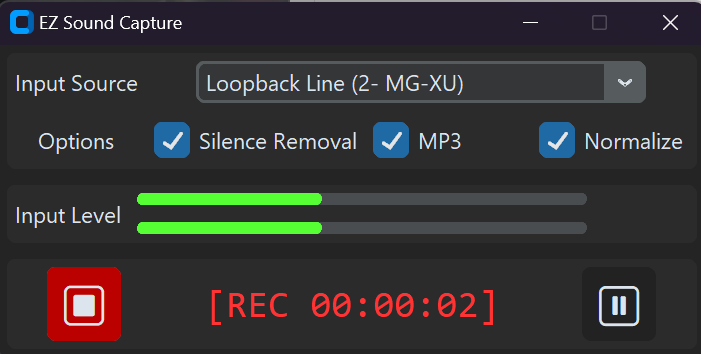
「EZ Sound Capture」という名前でGitHubにアップロードしました。ぜひ環境に合わせて機能拡張や改造していだだければと思います!
PCから流れる音を録音する時によく出てくる「ステレオミキサー」は不要です。非搭載の環境でも動作します! 「ステレオミキサー」は以下のようなもので、PCに搭載している物理的なサウンドカードが対応していないと表示されません。

開発にあたり、以下の記事を参考にさせていただきました。
作成に至った経緯
仕事の都合で、PCから流れる音を録りたいけれど、Windows標準の録音アプリにはそんな機能はないし、会社のPCには勝手にフリーソフトを入れられない。。
そうだ、うちの会社はPythonは使っていいんだった。なら、自分で作って動かしましょう!!
実装した機能
- 録音デバイスまたはループバックオーディオ出力デバイスからオーディオを録音
- オーディオ入力レベルのモニタリング(対数スケール)
- バックアップされたデータの保存(numpy配列として)
- 自動的な無音部分の削除
- MP3として保存(FFmpegが必要)
- 正規化(FFmpegが必要)
今後の検討: バックアップnpzファイルから.wavを出力する機能を追加
実装の抜粋
グローバル変数が行ったり来たりで汚いですが、各機能をスレッドに分けて非同期にさせています。
実装全体はGitHubをご覧ください。
メインの録音機能
- 任意の時点で録音の一時停止/再開、録音停止ができるように対処
def record_from_mic(recording_ftame):
global data, input_souce_id, pause, is_silence_cut
data = None
with sc.get_microphone(id=input_souce_id, include_loopback=True).recorder(samplerate=SETTINGS.recording.sample_rate) as mic:
while recording:
_data = mic.record(numframes=SETTINGS.recording.sample_rate)
if not pause:
if data is None:
data = _data
else:
if is_silence_cut.get():
if not np.all(np.abs(_data) < SETTINGS.recording.silence_threshold):
data = np.concatenate((data, _data))
else:
data = np.concatenate((data, _data))
sec = data.shape[0] / SETTINGS.recording.sample_rate
str_l = "[REC " if int(sec) % 2 == 0 else "[ "
str_r = "]"
t = convert_seconds(sec)
recording_ftame.label_time.configure(text=str_l + t + str_r, text_color="#ff3333")
else:
recording_ftame.label_time.configure(text=LANG.labels.RecordingFrame.text_pause, text_color="#888888")
else:
# Finished recording
recording_ftame.label_time.configure(text="00:00:00", text_color="#ffffff")
定期的に録音データをバックアップ
def backup_data_every(interval, backup_dir):
global recording, data
t = 0
while recording:
time.sleep(1)
t += 1
if interval == t:
# Save the data to a npy file with the current date and time in the file name
# np.save(f"./{backup_dir}/backup_{datetime.now().strftime('%Y%m%d_%H%M%S')}.npy", data)
np.savez_compressed(f"./{backup_dir}/backup_{datetime.now().strftime('%Y%m%d_%H%M%S')}.npz", data)
t = 0
実行準備
FFmpegの準備(オプション)
FFmpegを必要とする機能を使用するには、ffmpegをインストールするか、すでにffmpeg.exeがある場合は、そのパスpath/to/ffmpeg.exeをPATHに設定してください。
1. Python環境の作成
cd ez-sound-capture
python -m venv venv
.\venv\Scripts\activate.ps1 # Windowsの場合
pip install -r requirements.txt
2. settings.jsonの編集
{
"gui":{
"lang": "en" # 使用したいアプリの言語(enとjaを用意しました)
},
"recording":{
"sample_rate": 44100,
"backup_interval": 60, # バックアップ間隔(秒)
"silence_threshold": 0.05
}
}
3. アプリの起動
python ez-sound-capture.py
このアプリの使い方
- 入力ソースの選択: 利用可能なすべてのマイク(ループバックデバイスを含む)がリストアップされます。録音に使用したいものを選択してください。
最初に「Loopback」とつくものがPCから出力される音です。PCに繋げたイヤホンや内蔵のスピーカー、BlueToothスピーカー等から出る音をそのまま録音できます。
- 録音オプションの設定: 録音をMP3形式でも保存するか、オーディオを正規化するか、無音部分をカットするかを選択できます。該当するオプションのチェックボックスを選択して有効にしてください。
- オーディオレベルのモニタリング: 音声入力レベルをリアルタイムでモニタリングすることができます。これにより、適切な音量でオーディオがキャプチャされていることを確認できます。ログスケールにすることで小さな音でも反応するようにしています。
- 録音の開始/停止: '録音開始’ボタン(⏺️)をクリックして録音を開始します。録音中はボタンが’Stop’ボタン(⏹️)に変わります。再度クリックして録音を停止します。プログラムは一時停止/再開のための’Pause’ボタン(⏸️)も提供しています。
- 録音の保存: 録音を停止すると、プログラムは自動的にオーディオファイルを./recordings/<録音日時>/output.wavに保存します。MP3形式で保存する場合、同じディレクトリにmp3ファイルも保存されます。
既知の不具合
任意のタイミングで録音を停止できるようにチャンクに分けて録音することを繰り返し、単純に結合しているため、チャンク同士の連続性が失われることがあります。
出力された音を聞くとブツブツと途切れた音が聞こえることがあり、改善の余地ありです。。
soundcard\mediafoundation.py:772: SoundcardRuntimeWarning: data discontinuity in recording
warnings.warn("data discontinuity in recording", SoundcardRuntimeWarning)
さいごに
一部不具合はありますが、簡単に録音ができるPythonベースのGUIアプリを作成しました。同じ境遇の方の参考になれば幸いです!
余談
アプリのアートワークを、文字を正しく描けると話題のStable Diffusion 3に作成させてみました。Captureのtuの部分が惜しいですが、美麗&壮大すぎてアプリの内容がちゃっちく見えますね。。。

参考文献