[1710.11417] TreeQN and ATreeC: Differentiable Tree Planning for Deep Reinforcement Learning
メタ情報
-
ICLR2018 にポスター採用 された論文
- レビューコメントを眺めた感じ、だいたい次のようなことが言われている:
- 実験結果が良いとは言い難いが、シンプルで新規性のあるアプローチなので将来性がある
- やろうとしていることと、提案・実装したモデルとの関係性が本当にちゃんと対応しているのかよくわからん、もっと調査してほしい
- レビューコメントを眺めた感じ、だいたい次のようなことが言われている:
概要
- モデルフリーの深層強化学習とオンラインプラニングを組み合わせることは将来性がある
- 遷移モデルが既知の場合、木による先読みを使ったオンラインプラニングが成功している
- 遷移モデルが未知の場合のアプローチとして、TreeQN を提案する
- TreeQN は、どんな離散行動の深層強化学習モデルにも適用できる、微分可能で再帰的な木構造である
導入
- 伝統的には、木探索を使ったオンラインプラニングは、環境が既知の場合しか使われてこなかった
- たとえばボードゲームやカードゲーム
- 複雑で高次元な状態空間と遷移モデルを持つ環境を学習させてオンラインプラニングをすることは難しいことがわかっている
- Q関数や方策に微分可能な木構造を組み合わせることで、環境モデルの推定を含むエージェントの訓練を end-to-end におこなう手法を提案する
- 我々の手法をアーキテクチャとして実現しようとすると、「DQN の全結合層を再帰的ネットワーク 1 に置き換える」ということになる
背景
- 今回は、環境を $n_{\text{env}}=16$ 個用意し、それぞれを $n=5$ タイムステップずつ進めたあとの結果を学習に用いる (つまり n=5 の n-step Q-learning を 16 並列でおこなう):
 - ただしエピソードが終端したときはブートストラップをおこなわずに残りのエピソードの収益をそのまま目標値として用いる[^2]
- 上式の A2C 版の勾配は次の通り:
- ただしエピソードが終端したときはブートストラップをおこなわずに残りのエピソードの収益をそのまま目標値として用いる[^2]
- 上式の A2C 版の勾配は次の通り:
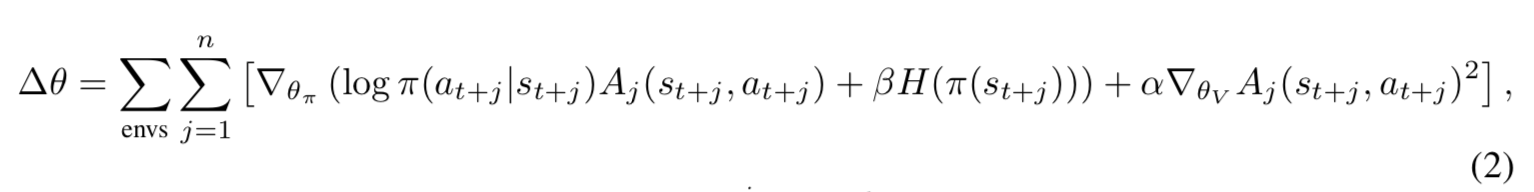 - ただし、アドバンテージ $A_j = $
- ただし、アドバンテージ $A_j = $ 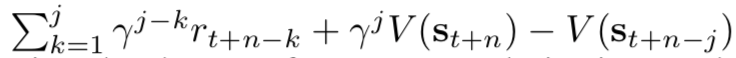 、$H$ は方策のエントロピー、$\beta$ はその係数 (ハイパーパラメータ)、$\alpha$ はアクターとクリティックの学習率の割合制御の係数 (ハイパーパラメータ)
- 今回は単純のためと計算時間との兼ね合いからアルゴリズムを選んでいるが、TreeQN は他のアルゴリズムにも適用可能である
、$H$ は方策のエントロピー、$\beta$ はその係数 (ハイパーパラメータ)、$\alpha$ はアクターとクリティックの学習率の割合制御の係数 (ハイパーパラメータ)
- 今回は単純のためと計算時間との兼ね合いからアルゴリズムを選んでいるが、TreeQN は他のアルゴリズムにも適用可能である
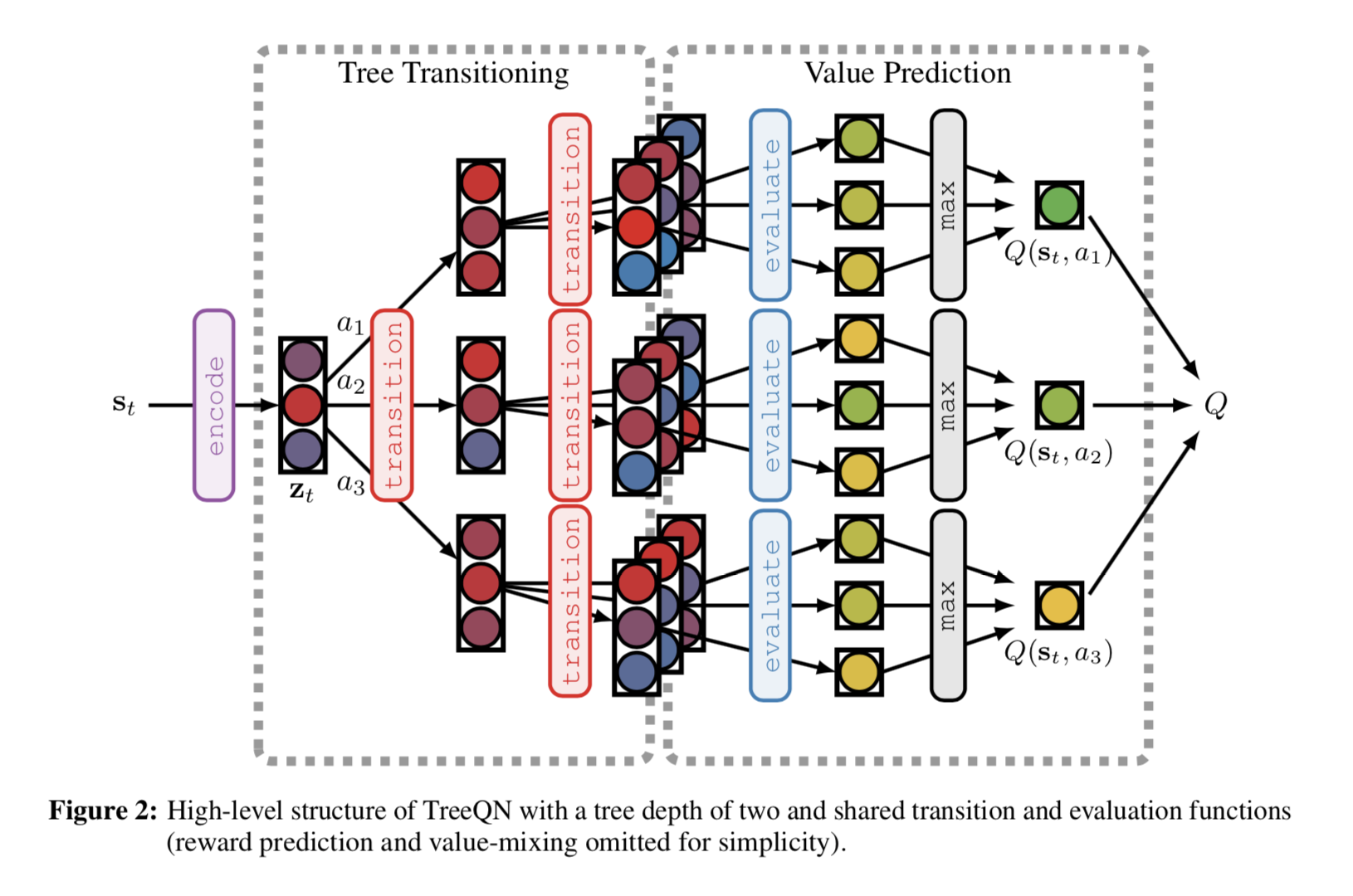
TreeQN
- DQN はいくつかのレイヤー (画像が入力の場合には畳み込み層) の後に全結合層を2つ挟んでQ値を出力する
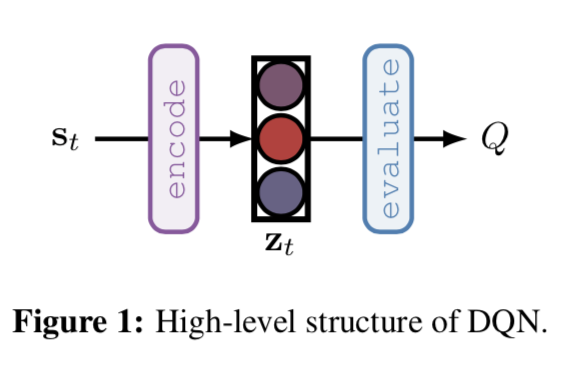
- これを状態のエンコーディングだと考える。TreeQN ではこのエンコードされた状態 $z_t$ に対して再帰的に状態遷移 (これも学習対象) を実施して、Q値のより正確な推測を目論む
- この時、再帰的なモジュールのパラメータは共有されていることに注意
- TreeQN は、状態の埋め込み $z_t$ を与えられて、ある行動 $a_i$ を取ったときの遷移関数と、それに対応する報酬 $\hat{r}_t^{a_i}$ を学習していると言える
- ある深さでの価値 $V(z)$ は価値関数モジュールで予測する
- 予測した価値関数と報酬を組み合わせて、通った木の各パスに対して k-step 収益と TD(λ) 法を組み合わせた木のバックアップをおこなう
 - 特に、 $\lambda=1$ の場合、(3)(4) 式は木のバックアップを通常のベルマン方程式でおこなう方式となる:
- 特に、 $\lambda=1$ の場合、(3)(4) 式は木のバックアップを通常のベルマン方程式でおこなう方式となる:
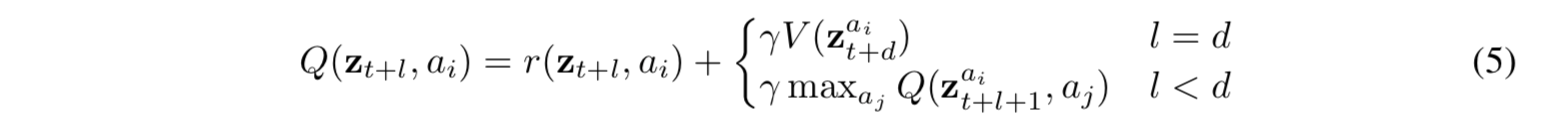
モデルの構成要素
Encoder function (エンコーダ関数)
- DQN でおこなわれているように、観測した状態 $s_t$ を何層かの畳み込み層で $z_t = \text{encode}(s_t)$ に変換する
Transition function (遷移関数)
- 各行動 $a_i$ ごとに全結合層を用意し、residual connection を利用して次の時点の状態を予測する
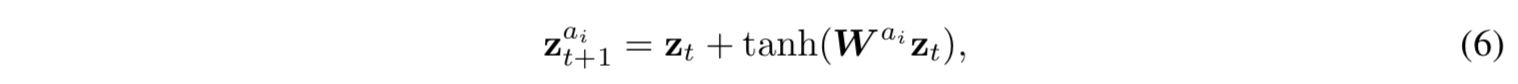 - 全結合層の重み $W$ は $a_i$ ごとに別個に学習することになるが、
- どの状態でも行動 $a_i$ 自体の選択肢は共通 (状態によって取れる行動セットが変わらない[^3])
- 再帰的な構造を採用しているので、木の階層が変わっても $W$ は共通
- 再帰的に適用される遷移関数に、状態空間の意味で一貫性を持たせるため、状態は都度L2ノルムで規格化している:
- 全結合層の重み $W$ は $a_i$ ごとに別個に学習することになるが、
- どの状態でも行動 $a_i$ 自体の選択肢は共通 (状態によって取れる行動セットが変わらない[^3])
- 再帰的な構造を採用しているので、木の階層が変わっても $W$ は共通
- 再帰的に適用される遷移関数に、状態空間の意味で一貫性を持たせるため、状態は都度L2ノルムで規格化している: 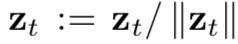
Reward function (報酬関数)
- 各行動 $a_i$ ごとの即時報酬を予測する

 - まずエンコードされた状態と同じ次元に全結合層でマッピングし (ReLU の中身)、その後で ReLU を取ってから、行動の種類数の次元を持つ空間にマッピングする
- $\hat{\boldsymbol{r}}(z_t)$ の第 i 次元が、行動 $a_i$ に対応する即時報酬 $\hat{r}^{a_i}(z_t)$ である
- まずエンコードされた状態と同じ次元に全結合層でマッピングし (ReLU の中身)、その後で ReLU を取ってから、行動の種類数の次元を持つ空間にマッピングする
- $\hat{\boldsymbol{r}}(z_t)$ の第 i 次元が、行動 $a_i$ に対応する即時報酬 $\hat{r}^{a_i}(z_t)$ である
Value function (価値関数)
- 全結合層で価値推定する。結果はスカラ量となる。

訓練
- TreeQN は全体が微分可能なので、離散行動であればどんな深層強化学習のQ関数の代わりにも使える
- 訓練時には、(1) 式で定義したロスとは別に補助ロスとして即時報酬の予測を加える
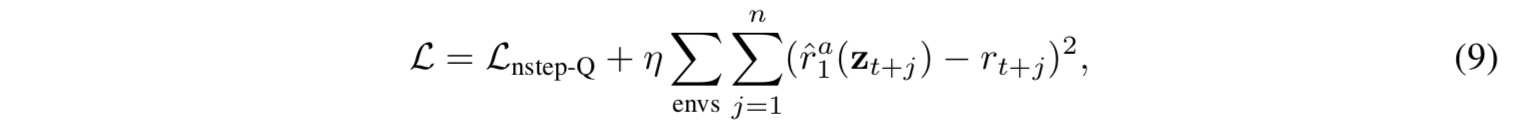 - 今回は、ロスの重みを制御する係数 $\eta=1$ を用いた
- TreeQN では未来への状態の展開をおこなう都合上、未来の時点での即時報酬も使う必要がある ((3) 式を見よ) ため、この補助ロスはその即時報酬の予測精度を高めるという意味がある
- 他にも、例えば状態予測の精度の補助ロス等を使うことも考えられるが、やはり木構造Q関数の更新にどうしても必要となる即時報酬の予測の精度のほうが重要であると考えた
- 今回は、ロスの重みを制御する係数 $\eta=1$ を用いた
- TreeQN では未来への状態の展開をおこなう都合上、未来の時点での即時報酬も使う必要がある ((3) 式を見よ) ため、この補助ロスはその即時報酬の予測精度を高めるという意味がある
- 他にも、例えば状態予測の精度の補助ロス等を使うことも考えられるが、やはり木構造Q関数の更新にどうしても必要となる即時報酬の予測の精度のほうが重要であると考えた
ATreeC

- TreeQN を actor-critic に拡張する
- TreeQN を、Q関数の予測ではなく方策 $\pi$ の予測にするのは容易 (単純に最後に Softmax を入れれば良い)
- Actor はこの方策を用いれば良い。Critic 用の価値関数は、$z_t$ から別の全結合層を生やしてそれを使う
- Critic 側にも木構造を採用することもできそうだが、将来の課題とする
関連研究
- model-based と model-free を組み合わせようとする動きは大昔から存在する
- 提案法に一番近いのは Value prediction networks (VPNs) だと思われるが、VPN は木構造で行動選択をおこなうものの、訓練時の価値推定に木構造を利用しているわけではない
- 遷移モデルを使った rollout をおこなう Imagination-augmented agents も提案されているが、その遷移モデルは事前に学習したものであり、end-to-end にはなっていない
- TreeQN は木構造を訓練にも予測にも統一された方法で組み込んでいて、シンプルかつ柔軟性が高いことを主張する
実験結果と議論
- Box Pushing という、倉庫番を模した単純なゲームと、 Atari のゲームで実験した
box pushing
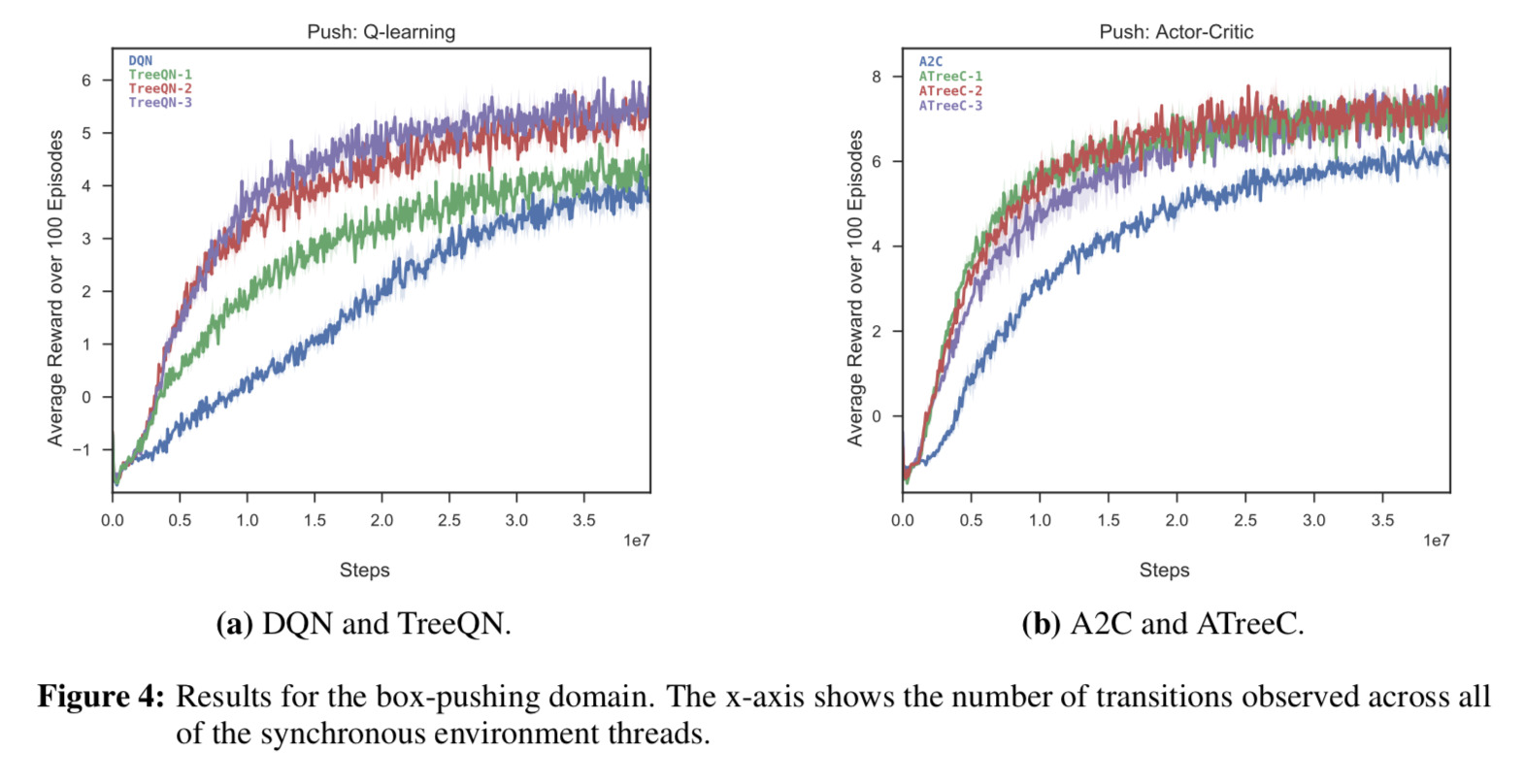
- TreeQN/ATreeC はどちらも DQN/A2C より最終結果が良いし、学習も早かった
- TreeQN より ATreeC のほうが精度が良い。確率的な方策が効いていると思われる
- 提案法はより大きな構造を利用している2ので、状態の表現に対する正則化の効果が得られたことがベースラインよりも学習が早くなる一因だという仮説を考えている
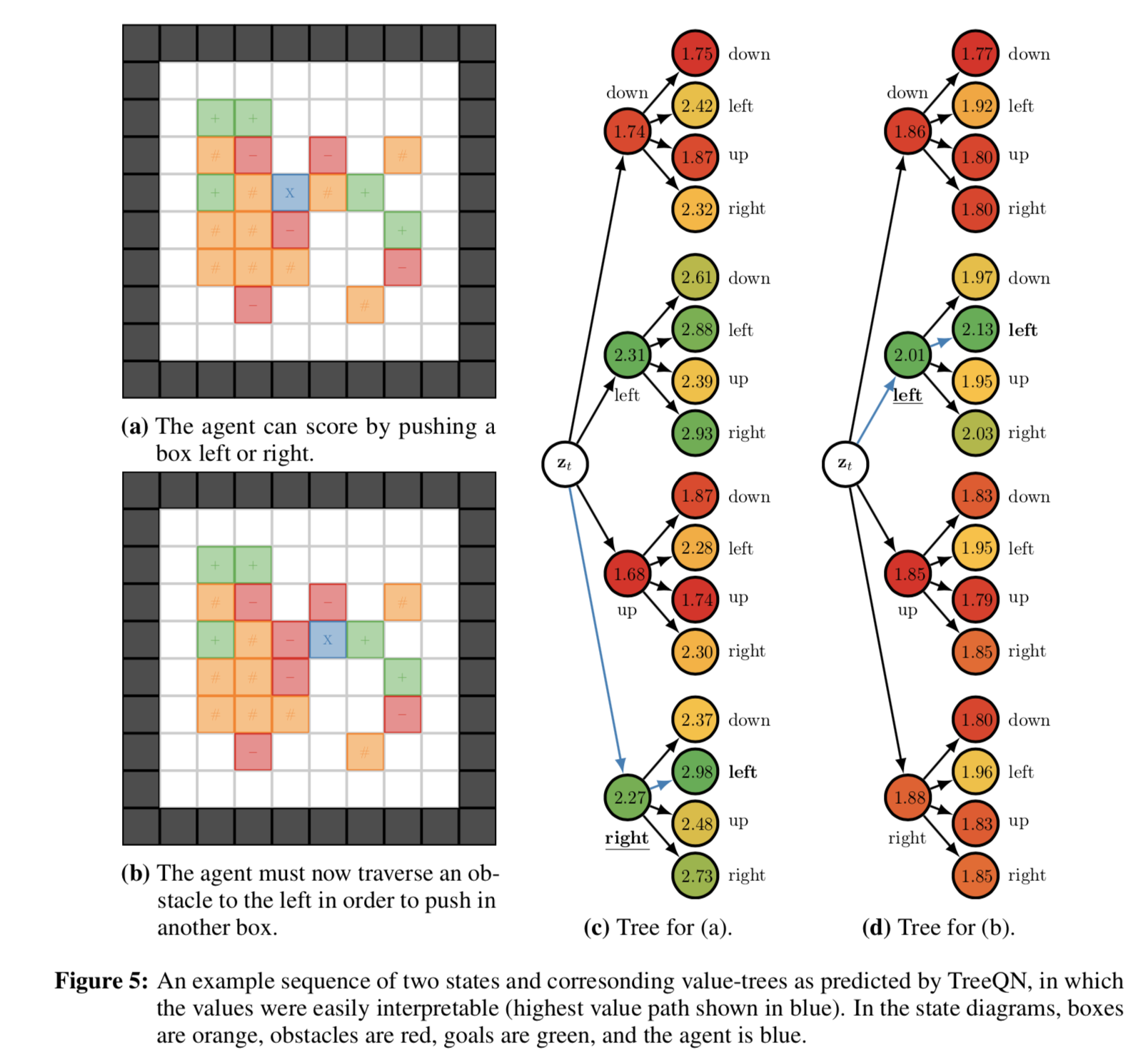
-
(a) エージェント (青色) が右か左に一歩押すと、箱 (橙色) をゴール (緑色) に到達させられる状態
-
(c) (a) での方策評価。right -> left が一番いいと判断している
-
(b) (a) の状態からエージェントが右に一歩動いた状態
-
(d) (b) での方策評価。left -> left が一番いいと判断している
- 赤マスはエージェントが通ると小さな罰則を受ける設定だが、それでもちゃんと left を二回連続実行して箱をゴールに押そうとしている
-
最適な行動列ではないにもかからわず、エージェントが同じ行動を連続して計画することが見られ、実行計画が解釈困難であることが課題である
Atari
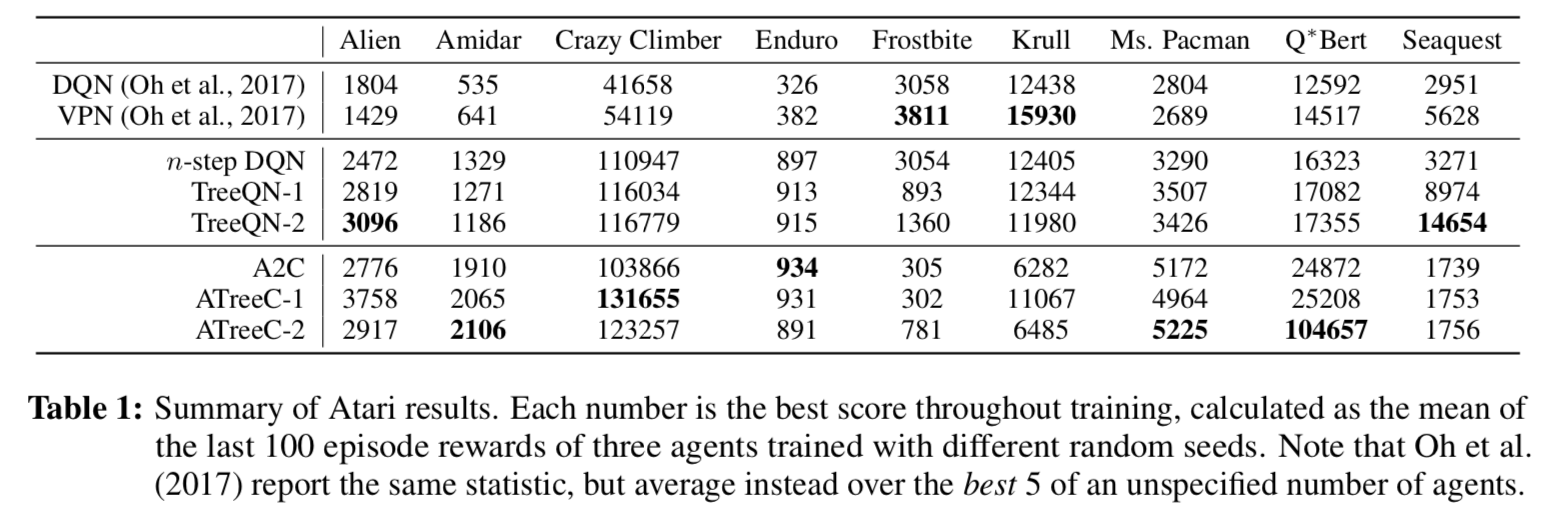
- 学習曲線は図がでかいので元論文の Figure (6) 参照してください
- TreeQN がうまくいっているゲームは、予想通り、先読みが効果的なゲームだった
- 基本的には ATreeC のほうが TreeQN より結果が良い 3
- うまくいかなかった Frostbite と Krull は、サブゲームを段階的にクリアすることで高得点が得られる形式のゲームだった
結論と課題
- model-free の手法にうまく遷移モデルを組み込んだ TreeQN/ATreeC という新しいアーキテクチャを提案した
- 将来の課題は:
- より深い木での効率的な最適化
- 遷移関数がより解釈可能な実行計画を生み出すような工夫
- 賢い探索を取り入れる
- 非決定的な環境における、確率的な遷移関数への拡張
感想
- ATreeC って名前が A3C のオマージュになっててすてき
- めっちゃ重そう
- 経験再生しなくても大丈夫なのかな?
- ATreeC は actor-critic というよりも Dueling DQN っぽい気がする
- actor-critic と dueling Q って同じことなのか??
- レビューで言われている通り、微分可能な木構造を実現するようなアーキテクチャは必ずしもTreeQNだけではないし、提案された TreeQN のアーキテクチャが、今やろうとしていることに必要十分ではない、ように思う。が、一番最初の手法提案の論文としては、変に凝っているよりはわかりやすいアーキテクチャだし読みやすい論文だし、個人的には好感度高い
- というか最初から Rainbow みたいなの出て来たら全員挫折してしまうと思う
参考資料
- [1710.11417] TreeQN and ATreeC: Differentiable Tree Planning for Deep Reinforcement Learning
- TreeQN and ATreeC: Differentiable Tree-Structured Models for Deep Reinforcement Learning | OpenReview