はじめに
先日の記事では、可視化するグラフとして鉄道路線データを使いましたが、グラフとしてはある意味ちょっと特殊でした。もう少し一般的な作業例を紹介するため、今回はほとんどの方がネットワークと聞いて思い浮かべるであろういわゆるソーシャルネットワークのデータを公開APIから取得し、加工と可視化を行います。
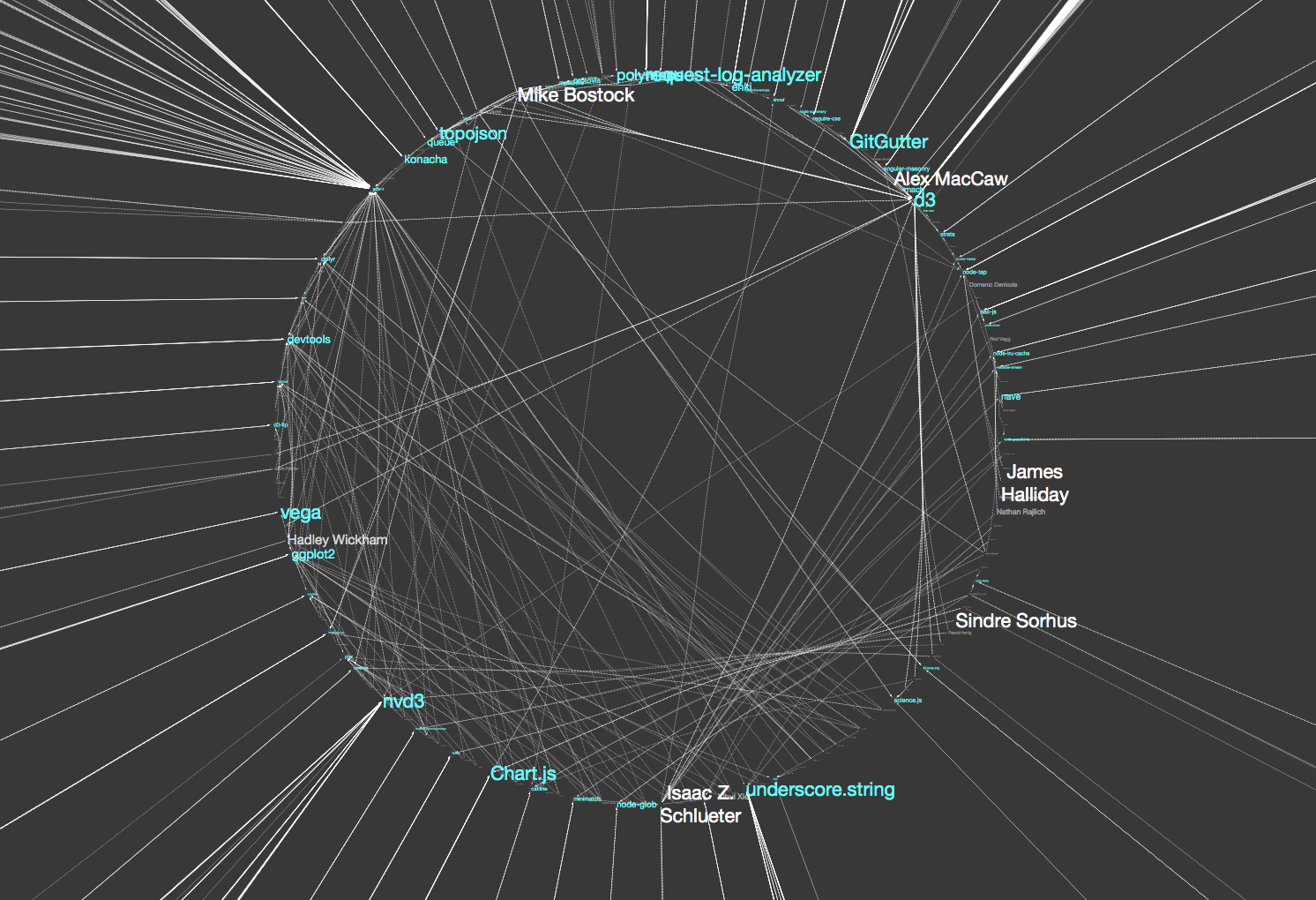
(今回作成したデータの別レイアウト)
ソーシャルネットワークとしてのGitHub
GitHubはソースコードレポジトリサービスですが、同時にプログラマのソーシャルネットワークのような一面を持っています。著名なプロジェクトのコミッター周辺を観察することにより、面白いプロジェクトを発見したり、フォローすべき人が見つかったりすることもあるでしょう。今回は、そのような発見が得られるような可視化を作成するため、実データの例としてGitHubのAPIから取得できる各種データを使用します。
前提知識
このワークフローを理解するのに必要な前提知識は以下の通りです:
- Pythonの基礎
- IPython Notebookの使い方
- NetworkXの基礎 (ノード、エッジ、プロパティの付加方法さえ知っていれば十分です)
- Cytoscapeの基本機能 - 以下の記事が参考になると思います。
使用するツール
- PyGithub v1.25.0
- IPython Notebook v2.1.0
- NetworkX v1.8.1
- Cytoscape 3.1.1
ゴール策定とスケッチ作成
漠然と「GitHubのデータを可視化する」と言っても無数の方法があるので、今回は、以下をテーマに設定します:
「広く使われているデータ可視化ライブラリのコミッターとレポジトリの繋がりを可視化し、フォローすべき興味深いプロジェクトや開発者を探す」
これにはいくつか方法はありますが、以下の仮説に基づいて進めます:
- 著名なライブラリのコミッタは、恐らく個人的にも様々な興味深いプロジェクトをGitHubでホスティングしている可能性が高い
- D3.jsをはじめとする広くデータ可視化コミュニティ使われているライブラリを始点にして、コミッタをリストアップし、彼らの個人レポジトリを調べれば、周辺の面白いプロジェクトが存在するはず
- そして、それらのプロジェクトに複数関わっている人々も多いだろうから、いくつかの適切な始点(seed node)を提供してあれば、自然にレポジトリとユーザーの関係性を表すグラフになる
紙でスケッチを作る
スケッチと言っても大したものは必要ないです。シンプルな図を描きながら実際にそれを作るのに必要な要素を考えます。ここで決めたことは:
- 最初に幾つかの著名ライブラリのプロジェクトIDをseedノードとして渡す
- 2つのエッジのタイプを設定する:
- commit_to - ユーザーからレポジトリに対してコミットしていることを表す
- owns - そのユーザーがレポジトリのオーナーであることを表す
- 「有用なプロジェクトかどうか」を判断するのにStarを付けた人(GitHubの用語では、Stargazer、すなわち「星を見つめる人」)の数を使う
- 当然個人のレポジトリには個人的な用途のために作った書き捨てコードもあるので、閾値としてStar数100以上を設定する
実際に使った図
仮説が正しければ、2番目の図のような直線的な繋がりから、最後の図のような網の目状のグラフになって行くはずです。
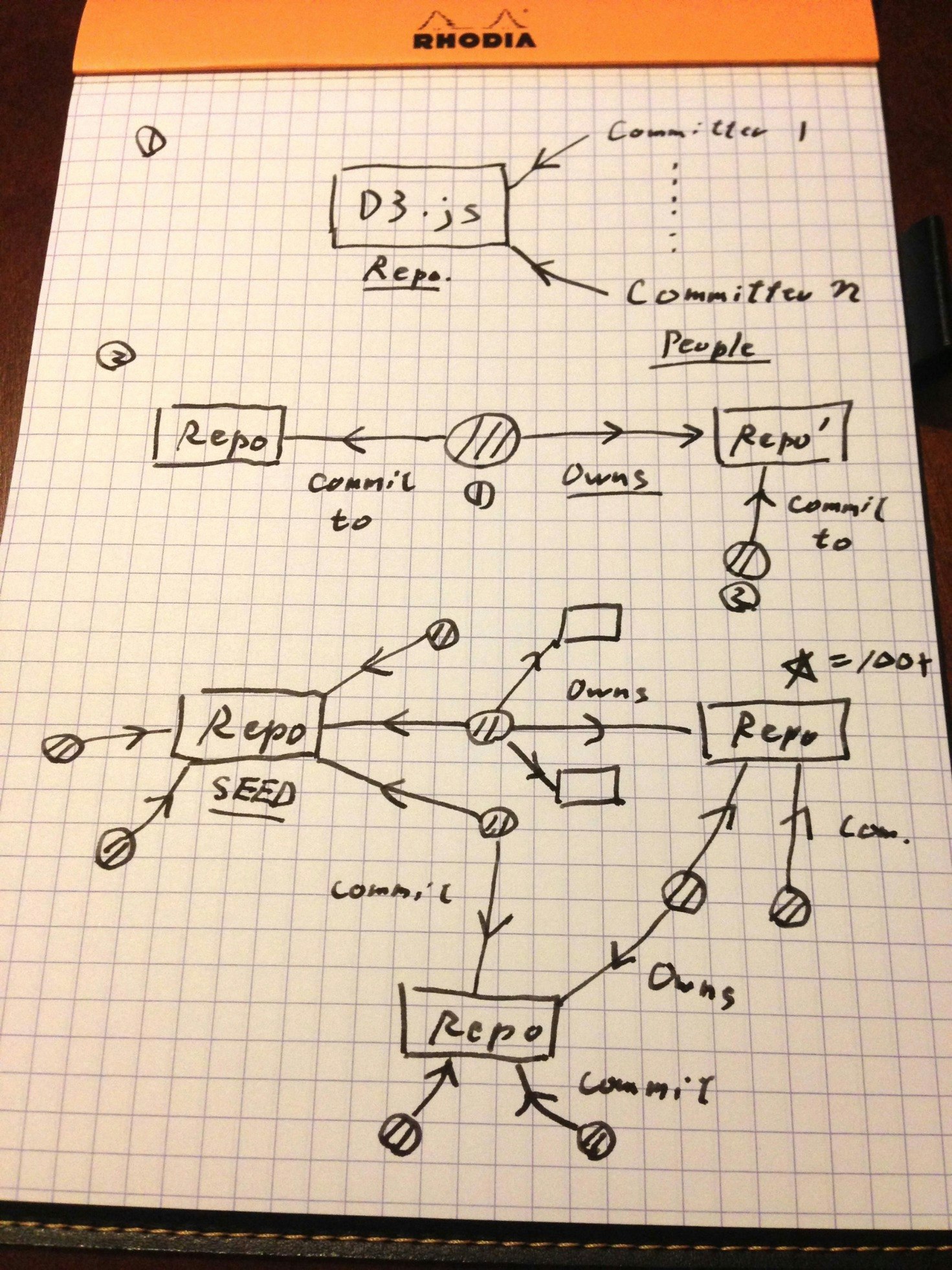
実際の作業
今回もデータの用意にはIPython Notebookを利用します。テストも何もない簡単な作業記録だけですが、一応Gistにアップしておきます:
IPython Notebook内の作業記録の解説
ここではノートの中身を簡単に解説します。
GitHub API
GitHubは、レポジトリやユーザーに関する情報を提供するRESTfulなAPIを提供しています:
もちろんこれを直接叩くことも可能ですが、ここではPython的な書式でこれらにアクセスできるラッパーを使います:
このライブラリを使うことにより、「URLを記述して_requests_などのライブラリを使ってJSONを取得、変換」と言う一連の作業を隠蔽できます。具体的には、このような感じになります
# D3.jsのレポジトリの詳細情報を取得する
repo = client.get_repo('mbostock/d3')
# ちゃんと動いているか確認のため、レポジトリの名前を結果から取り出す
repo_name = repo.full_name
APIからのデータ取得
キー無しでのアクセスも出来るのですが、アクセスできる回数の上限が非常に低いです。今回はそれなりの量のデータを取得するので、まずはAPIキーを取得します。
これを使ってクライアントを作成します。と言っても、取得したキーをクライアントに渡すだけです。
TOKEN = 'ここに生成したキーを入れる'
client = Github(TOKEN, per_page=100)
Seedレポジトリの設定
これは基本的に自分の興味に即して変えてもらって構わないのですが、今回はJavaScriptを主な言語とする可視化関連のハッカー周辺をのぞいてみたいと思います。Seedリストは任意のプロジェクトを入れてもらって構いませんが、ここでは定番となったような可視化ライブラリのレポジトリを使いました。
SEEDS = [
'mbostock/d3', # D3.js
'nnnick/Chart.js', # Chart.js
'trifacta/vega', # vega http://trifacta.github.io/vega/
'misoproject/d3.chart', # d3.chart D3で再利用可能なチャートを作るためのライブラリ
'novus/nvd3', # NVD3 D3を利用したチャートライブラリ
'simplegeo/polymaps', # Polymaps 地図関連のライブラリ
'lmccart/p5.js' # p5.js ProcessingのJavaScript版。
]
データの取得
データの取得は、上のseedノードから3ホップ(つまり3つのエッジを通ることによって到達できるノード)で接続されているユーザーまでを取得してグラフを構築します。つまり、
seed node <--(commit_to)-- committer 1 --(owns)--> committer 1's personal Repo <--(commit_to)-- committer 2
この関係を1つずつ抽出していきます。同時に、各レポジトリが持つスター数、開発者に関してはフォロワー数などもノードのプロパティとして取得していきます。これを続けることにより、複数のプロジェクトにコミットしているアクティブな開発者がいれば、彼らを通じて網目状のグラフが作られるはずです。もちろん上の_committer 2_から更に先を検索することも可能ですが、恐らくデータが巨大になりすぎるので、今回はここまでの接続を確認することにします。
実際のグラフデータは、NetworkXで作成したMultiDiGraphに保存します。これにより、方向性を持った複数のエッジも問題なく扱えます。インメモリでデータを処理するのですが、今回程度の大きさならば全く問題無いです。
今回はただひたすらシリアルにデータをGitHubのAPIから読みだしてノードとエッジを1つずつ追加しているだけなので、とても時間がかかります。気長に待ちましょう。
汎用フォーマットへの書き出し
この処理が終われば、単なるNetworkXのグラフオブジェクトですから、様々な加工が可能になります。今回は特にグラフ自体の統計処理は行わず、生のデータをそのまま可視化してみますので、このグラフデータを Cytoscapeで読み込める形に書き出します。これもいろいろな方法があるのですが、GraphMLと言う汎用のXMLフォーマットが一番扱いやすいので、GraphMLとして書き出します。NetworkXには書き出しのための関数があるので、それを使います。
nx.write_graphml(g, 'github_universe.graphml')
可視化
Cytoscapeでの読み込み
ひとまずデータが完成したので、これを Cytoscapeに読み込ませます。GraphMLはデフォルトでサポートされていますので、__File → Import → Network → File...__で先に書きだしたファイルを指定すれば、自動的に読み込まれます。
可視化の方針
グラフの可視化は以下の方針で行います:
スタイルの作成
- ノードラベルの大きさは、ユーザーに関してはフォロワー数を、レポジトリに関してはスター数+ウォッチ数を使う。この値が大きいほどラベルのフォントは大きくなる (Continuous Mapping)
- 同様のマッピングを、ノードの大きさ、文字の透明度にも利用する
- ノードのタイプに基づいて色を変え、ユーザーノードとレポジトリを区別できるようにする(Discrete Mapping)
レイアウト
- 恐らくハブが幾つか存在するタイプのネットワークになっているので、レイアウトには力学シミュレーション系のものを使う
- グラフの特性上、一つのノードに対して大量のエッジが存在する物が多いので、__Edge Bundling__を用いてエッジをまとめて見やすくする
マッピングの詳細は、繰り返しになるのでここでは書きませんが、私の過去の記事や、マニュアルを参考にして下さい。今回はじめて利用する__Edge Bundling__とは、大量のエッジが一部のノード(ハブと呼ばれます)に集中しているようなデータの場合、複数のエッジを束ねて、描画結果を見やすくする機能です。__Layout → Bundle Edges → All nodes and edges__を選択し、オプションは全てデフォルトで実行すれば、ほとんどの場合うまく行きます。
これらのマッピングを施し、レイアウトを適用した結果は、以下の様な感じになります:
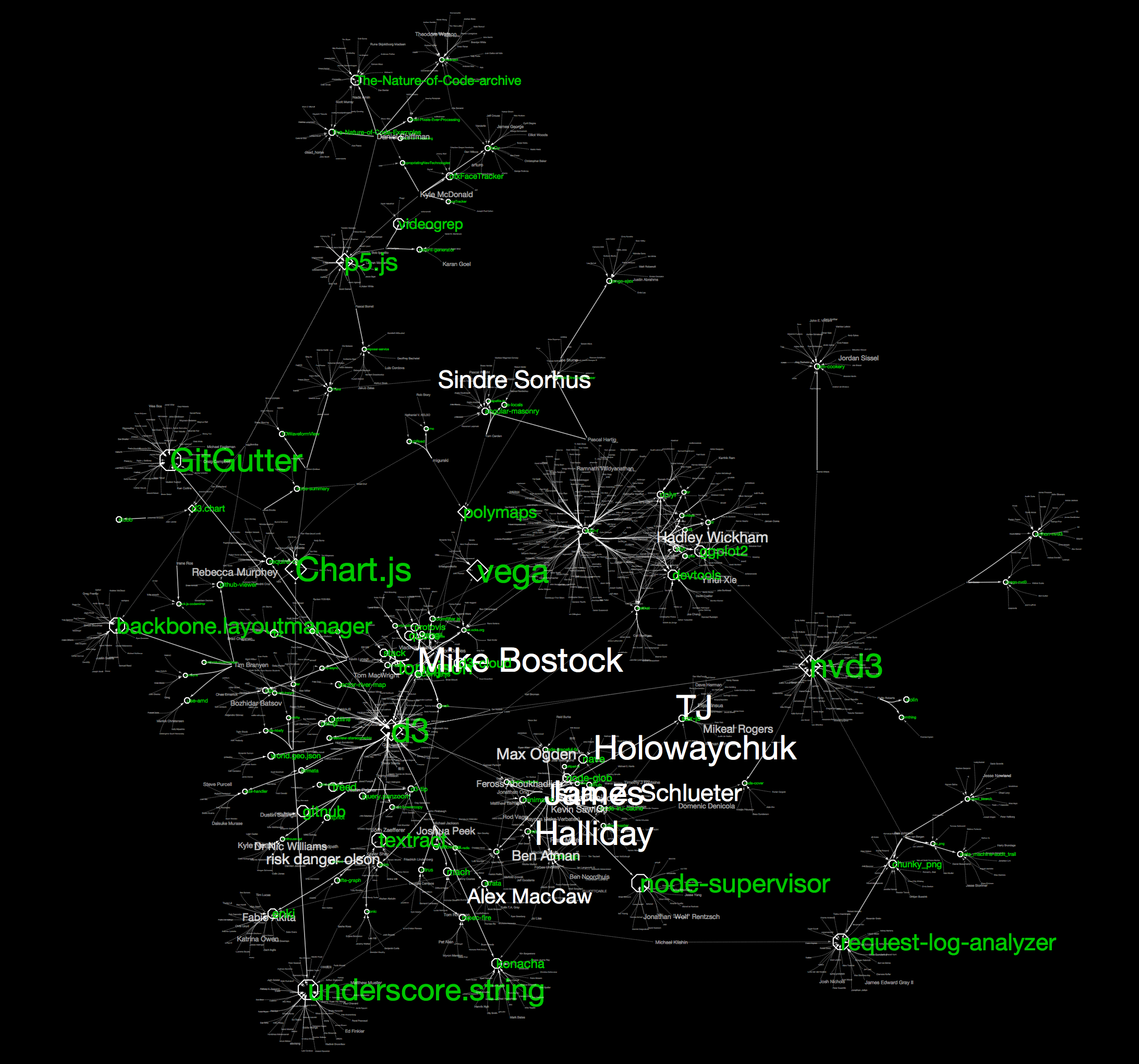
(ハイレゾ版)
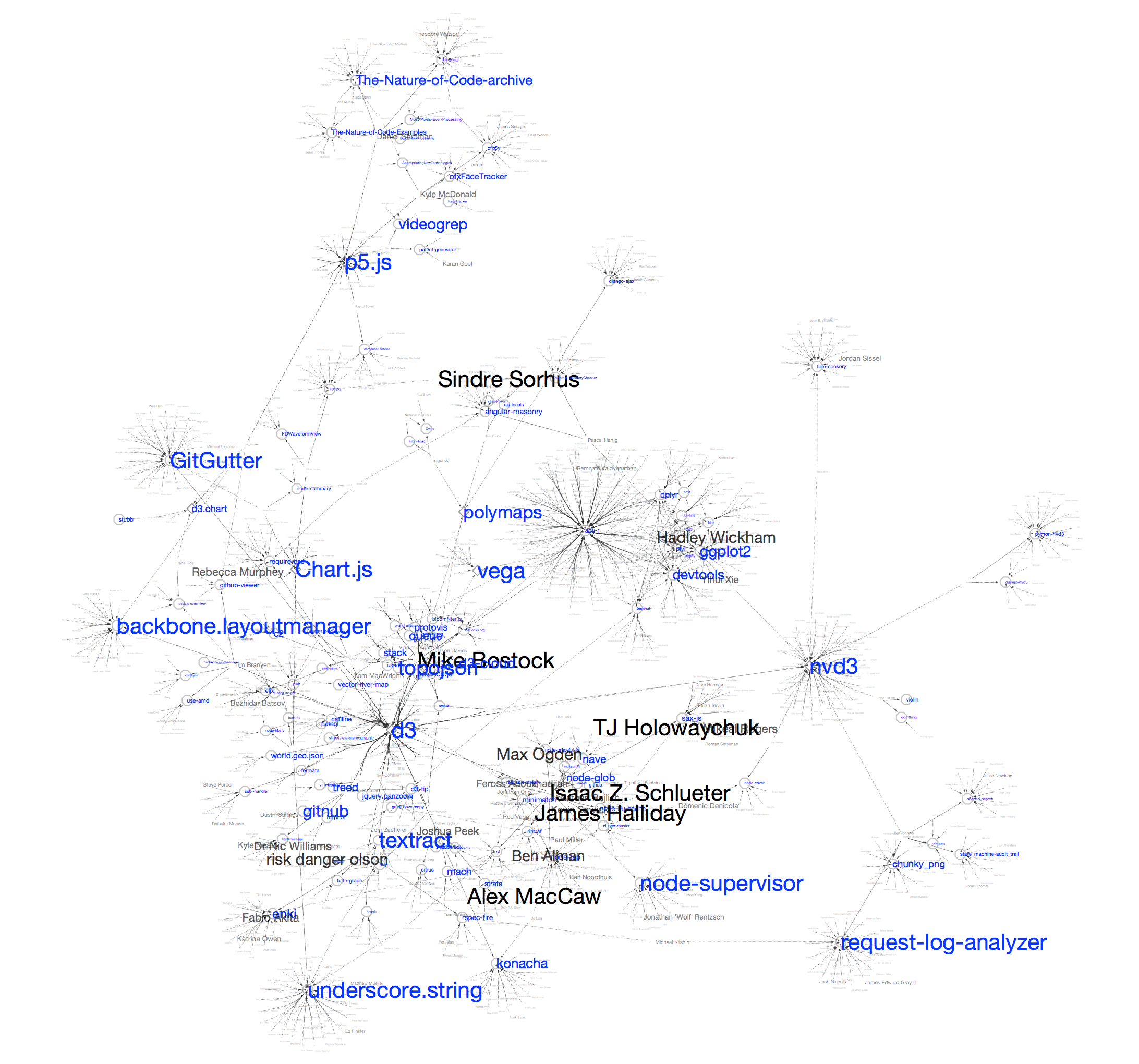
(ハイレゾ版)
一度Cytoscape上に可視化を作成してしまえば、ズーム、検索、スケーリング、サブグラフ作成などが自由に行えますので、いろいろ試して下さい。興味のあるプロジェクトを始点にズームインして周りを眺めると、アクティブな開発者(今回はフォロワーの数が多い人ほど大きなラベルで表示されています)や、関連するプロジェクトが見えると思います。セッションファイルもアップしておきますので、実際にCytoscape上で見ていただくと詳細まで分かりやすいと思います。
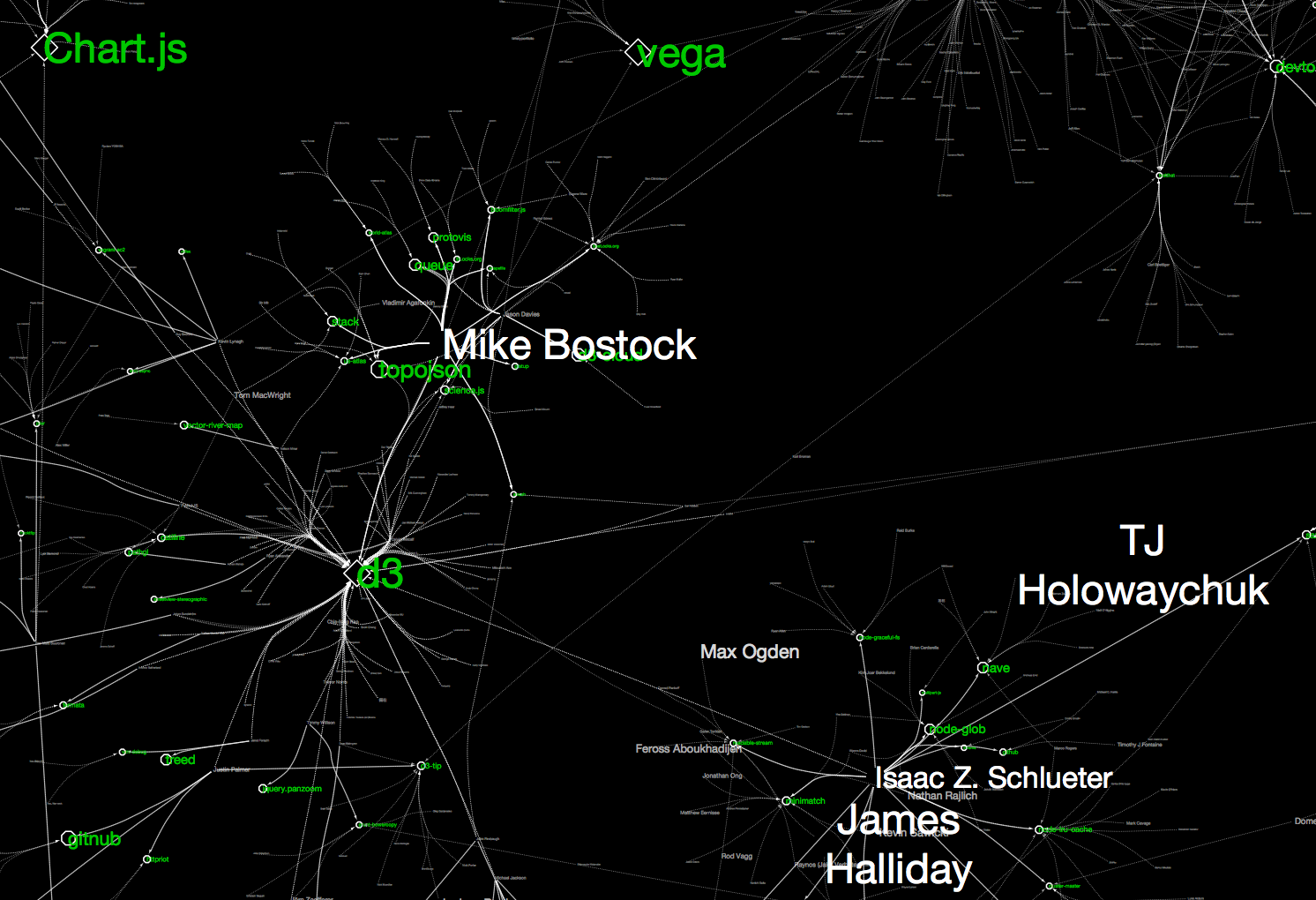
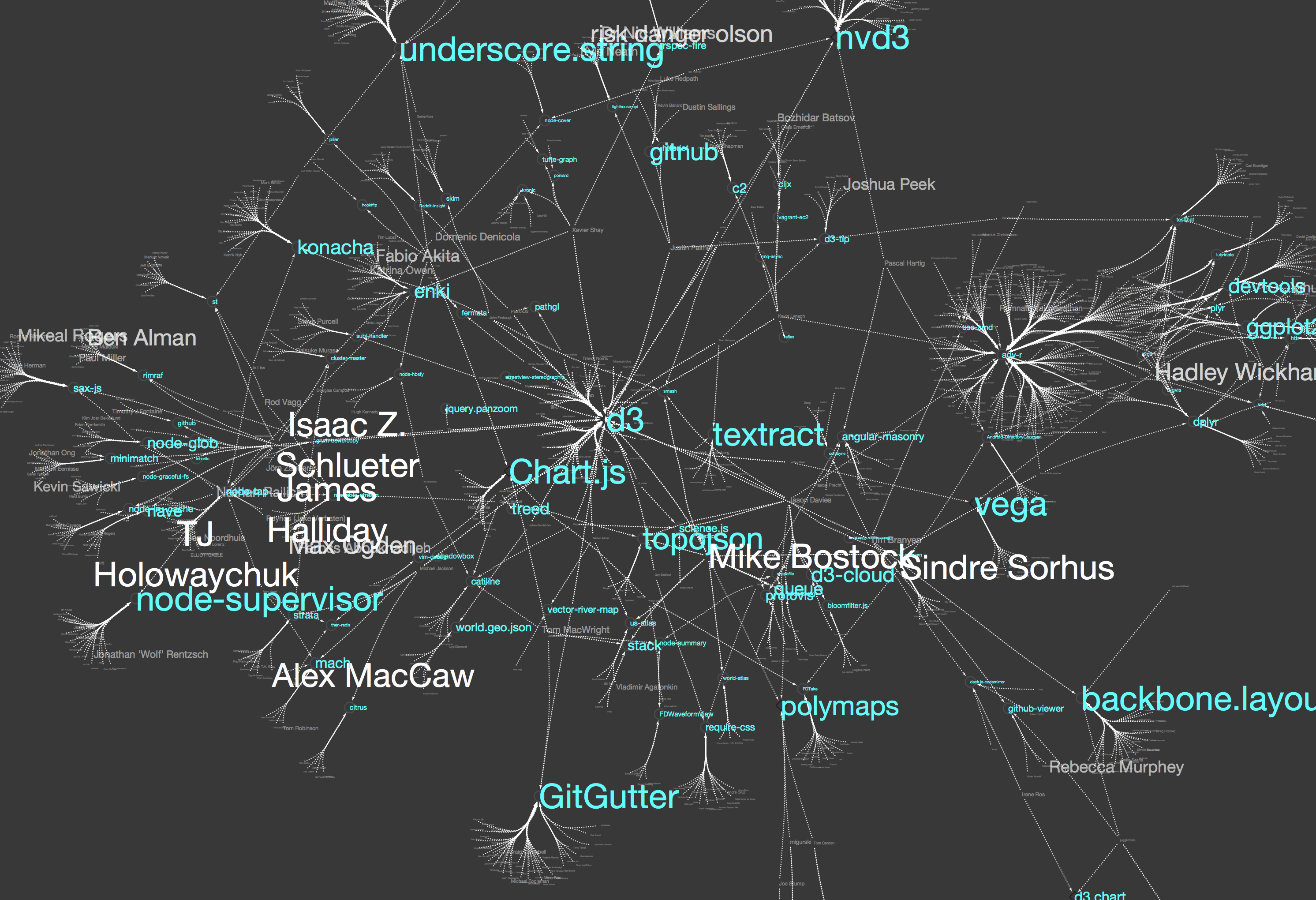
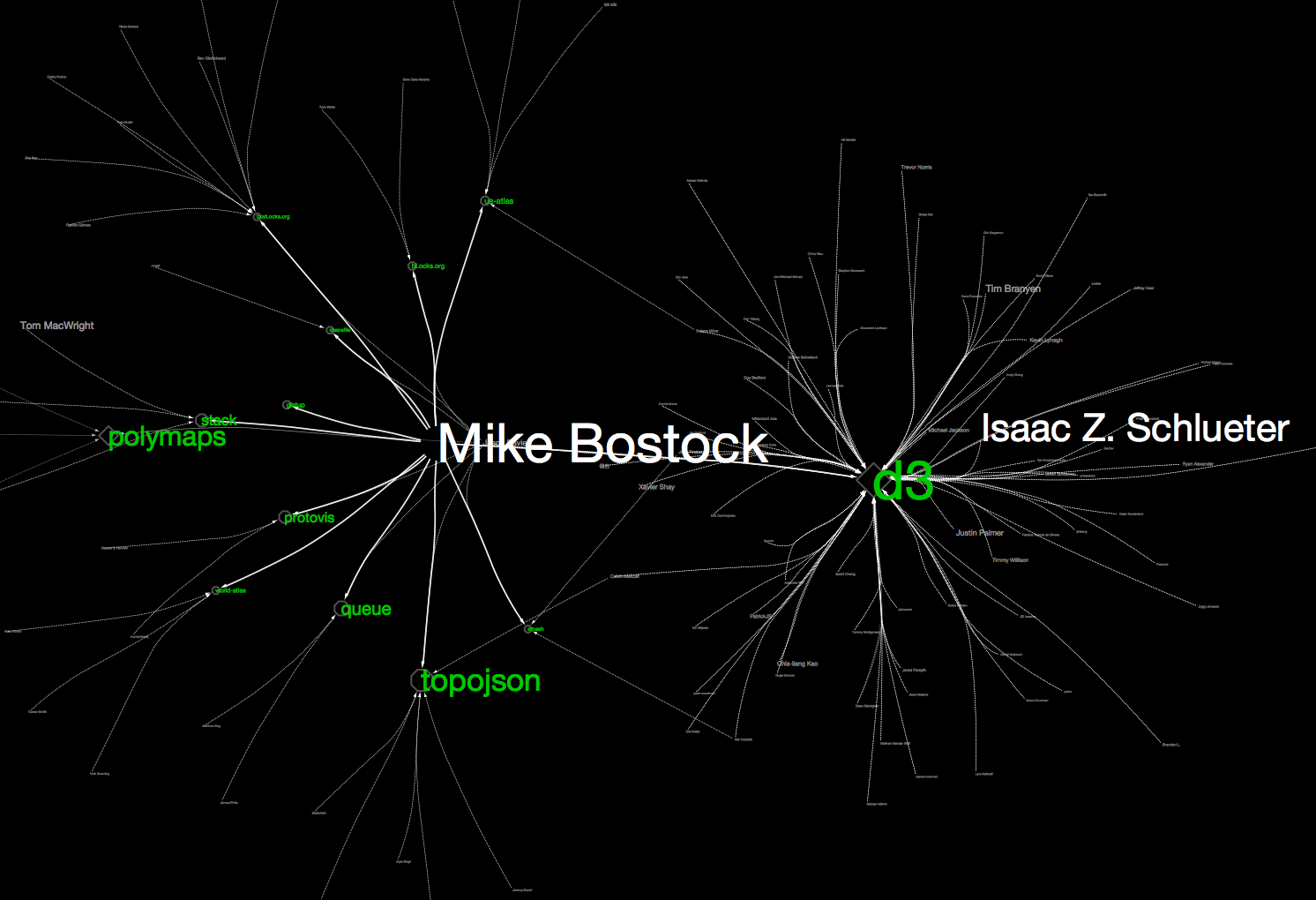
もちろん、Visual Style, IPython Notebookのコードともに再利用可能ですから、SEEDのリストを皆さんの興味のある分野に変更することにより、同じような可視化が違う分野について作成できます。
おわりに
今回は、「ネットワークらしいネットワーク」がどのように見えるのかを解説するために、データ元としてGitHubを利用しましたが、これもほんの一例です。TwitterやFacebookなども同様のAPIを持っているので、ソーシャルネットワークの解析と可視化に興味のある方は、データ生成部分をそれらのサービス向けに置き換えることにより、このワークフローが再利用できると思います。実際に解析を行う場合には、NetworkXの各種統計解析機能や、さらなる外部データの付与など色々なことが考えられますが、その辺りは実際に手を動かして、様々なデータセットを試してみてください。