この記事はData Visualization Advent Calendar 2015への寄稿です。
はじめに
データ可視化を行うためのツールは選ぶのに困るほど様々なものが出回っています。ExcelやTableauなどのアプリケーションに加え、カスタム可視化を作成するD3などのツールキットなどもオープンソースソフトウェアとして個人で利用可能です。ツールの選択は「これが正解」というものはなく、基本的に自分のスキルセットやデータの種類に応じて使いやすいものを選べば良いと思います。しかしせっかくここはプログラマ向けの場所ですから、コードを書いて行う可視化に的を絞って話を進めます。本稿では、Jupyter Notebook、Beaker Notebookと言うプログラミングによる可視化を行う場合に便利なツールの紹介をします。その中でも特に、自分でJavaScriptコードを書いてカスタム可視化を作る場合にこういった環境を利用するにはどうしたら良いのかという部分を中心に見て行きます。
可視化作業の流れ
様々な可視化の作業の中でも、比較的小規模なデータを扱う場合は、作業は以下のようになると思います。
- データの収集
- 機械可読な状態への加工
- 解析
- 可視化
- 結果の検討
- 必要に応じてさらなる解析と可視化(#4へ戻る)
このようなループで作業を行うことになるはずです。これらのステップをツールの面から見直すと以下のようになります。
| 作業 | ツール |
|---|---|
| データの収集 | 紙、デジカメなどのアナログな手法、実験機器、クローラーなどのプログラム(Web上のデータの場合) |
| 機械可読な状態への加工(クレンジング) | Python/R/Perl/Node.js/awk などのデータ加工スクリプト |
| 解析 | Python/R向けの統計解析パッケージ |
| 可視化 | JavaScriptによる独自の描画コード、Python/Rの可視化ライブラリ |
もちろん一つのプログラミング言語で全てを行うことも可能ですが、特にカスタムな可視化を作成する場合は、クレンジングや解析部分と、実際の描画部分は別々の言語で行う必要がある場合も多いと思います。このように複数の言語やツールを使う必要がある場合、テキストエディタ、ターミナルと結果確認のためのブラウザだけで行っても良いのですが、探索的な可視化作業の場合、各ステップを繰り返す必要もあるために作業の全体像を見渡すのが困難になるという問題があります。
この場合に非常に便利なのは、ノートブック型のアプリケーションです。もともとはMathematicaなどの専門家が使うソフトウェアで実験ノートのデジタル版のような位置付けで作られた概念ですが、コードと人間が読めるドキュメント、可視化結果などを混在させるというのがデータ解析者にとって非常に便利だということで、現在ではサイエンスのみならず、広くデータ解析の現場で利用されています。
代表的なノートブック型アプリケーション
Jupyter Notebook

オープンソースのものでは最も有名なものだと思います。もともとはPython向けの___IPython Notebook___という名前のアプリケーションでしたが、しばらく前に方針転換し、ノートブックアプリケーション部分と、実際のコードを実行するカーネル部分に分割され、現在はPython, R, Juliaをはじめとした40を超えるプログラミング言語をサポートしています。
元々サポートされていた言語であるPythonとの親和性は非常に高く、著名なライブラリであるmatplotlibなどの可視化は特に何もせずともサポートされています。しかし、D3.jsをはじめとした独自の可視化をJavaScriptで開発したい場合はどうでしょう。
Jupyterでカスタムな可視化モジュールを作成する

このスクリーンショットは、このノートブック上で使われているCytocsape.jsの埋め込み可視化モジュールでネットワーク図をレンダリングしたものです。このように、サードパーティーの可視化ライブラリをノートブック内のセルへ埋め込むことは可能です。ただし、その方法はそれほど洗練されてはいないです...
どのように任意の可視化を埋め込むのか?
ここでは私が@domitoryさんのプロトタイプを元にpipでインストールできるPythonパッケージにまとめたケースを見てみます。
1. スタイルなどを含んだHTMLファイルを用意する
まずは、埋め込める形でのHTMLを用意します。これも正確には完全なHTMLではなく、jinja2のテンプレートとしてJupyter Notebookが解釈できるものにします。今回の場合、以下のタグに対して実際の可視化を挿入することになります。
<div id="{{uuid}}"></div>
2. require.jsを使い、外部のJavaScriptを読み込む
これは現状のJavaScriptの問題でもあるのですが、外部モジュールを綺麗に扱う仕組みがES5までに用意されていないので、IPython NotebookではRequireJSを使って外部のJavaScriptの埋め込みをサポートしています。
if (window['cytoscape'] === undefined) {
// 外部から読み込むJSライブラリの場所
var paths = {
cytoscape: 'http://cytoscape.github.io/cytoscape.js/api/cytoscape.js-latest/cytoscape.min'
};
require.config({
paths: paths
});
require(['cytoscape'], function (cytoscape) {
console.log('Loading Cytoscape.js Module...');
window['cytoscape'] = cytoscape;
var event = document.createEvent("HTMLEvents");
event.initEvent("load_cytoscape", true, false);
window.dispatchEvent(event);
});
}
3. そこへデータを渡すPythonコードを書く
そして最後に、用意したJSやHTMLのテンプレートに対して、Python側からデータを渡すためのコードを書きます。Python側のデータをJavaScriptのコードが解釈できるような形で渡したのちにテンプレートをレンダリングするコードが必要です。
cyjs_widget = template.render(
nodes=json.dumps(nodes),
edges=json.dumps(edges),
background=background,
uuid="cy" + str(uuid.uuid4()),
widget_width=str(width),
widget_height=str(height),
layout=layout_algorithm,
style_json=json.dumps(style)
)
display(HTML(cyjs_widget))
- 実際のコードはこちらにあります
。
このように現状のJupyter Notebookでは、もともと複数言語の混在やカスタム可視化をその場で作るような用途は整備していなかったので、外部JSライブラリを読み込んでセル内で試行錯誤しながら可視化を作って行くという用途よりは、既存の可視化モジュールがあって、それをセル内でも使いたいという場合に向いていると思います。
現在、Jupyterプロジェクトは様々なスポンサーから大型のグラントを獲得して、規模を拡張している最中ですので、この辺りの拡張の仕組みはおそらく今後整備されていくと思われます。
Beaker Notebook

Polyglotなデータ解析環境向けのノートブック
Jupyter/IPython Notebookは非常に強力なツールなのですが、現状では一つのノートブックに複数の言語を混在させたり、多言語間でデータをやり取りする方法がありません。また、任意のHTMLに対して容易にJSを実行できるような仕組みがないため、用意された可視化モジュール(matplotlibやBokehなど)以外の独自のものを利用する場合には上記のような作業が必要になります。こういった問題を解決する仕組みを持ったノートブック型アプリケーションにBeakerがあります。
Jupyterとの違い
Jupyterとの最も大きな違いは、Jupyterがノートブックごとに接続するカーネルを限定してノートブックあたり一つの言語という形で管理しているのに対し、Beakerではこれがセルごとの管理になるという点です。したがって、以下のような作業が同一ノートブック上で可能になります:
- Pythonによるスクレイピング用コードや各種ウェブAPIへのクライアントを実行してデータ収集
- さらにそれらをPandasなどを使い整理
- その結果をRのセルで統計解析
- HTMLセルでデザインを決定
- 最後はそれらをカスタムのD3.jsベースの描画コードでHTMLセル内で可視化
具体的には、beakerという共通のオブジェクトを使って、セル間でデータをやり取りできるような仕組みが標準で用意されているということです。例えば、Pythonで代入した値を、
beaker.mydata = "My sample data"
R言語でアクセスしたり
beaker::get('mydata')
JavaScriptで使うといったことが簡単に行えます。
var myJsData = beaker.mydata + " updated by JS";
これを利用して、PythonのPandasでCSVを読み込み、Dictionaryオブジェクトに変換、それをbeakerオブジェクト経由でそのままJavaScriptセルへ渡して描画に利用する、といったことが標準機能だけで行えます。
以下はPythonでデータを準備して、埋め込んだHTMLセル内にCytoscape.jsを使ったJavaScriptのコードで描画を行った例です:
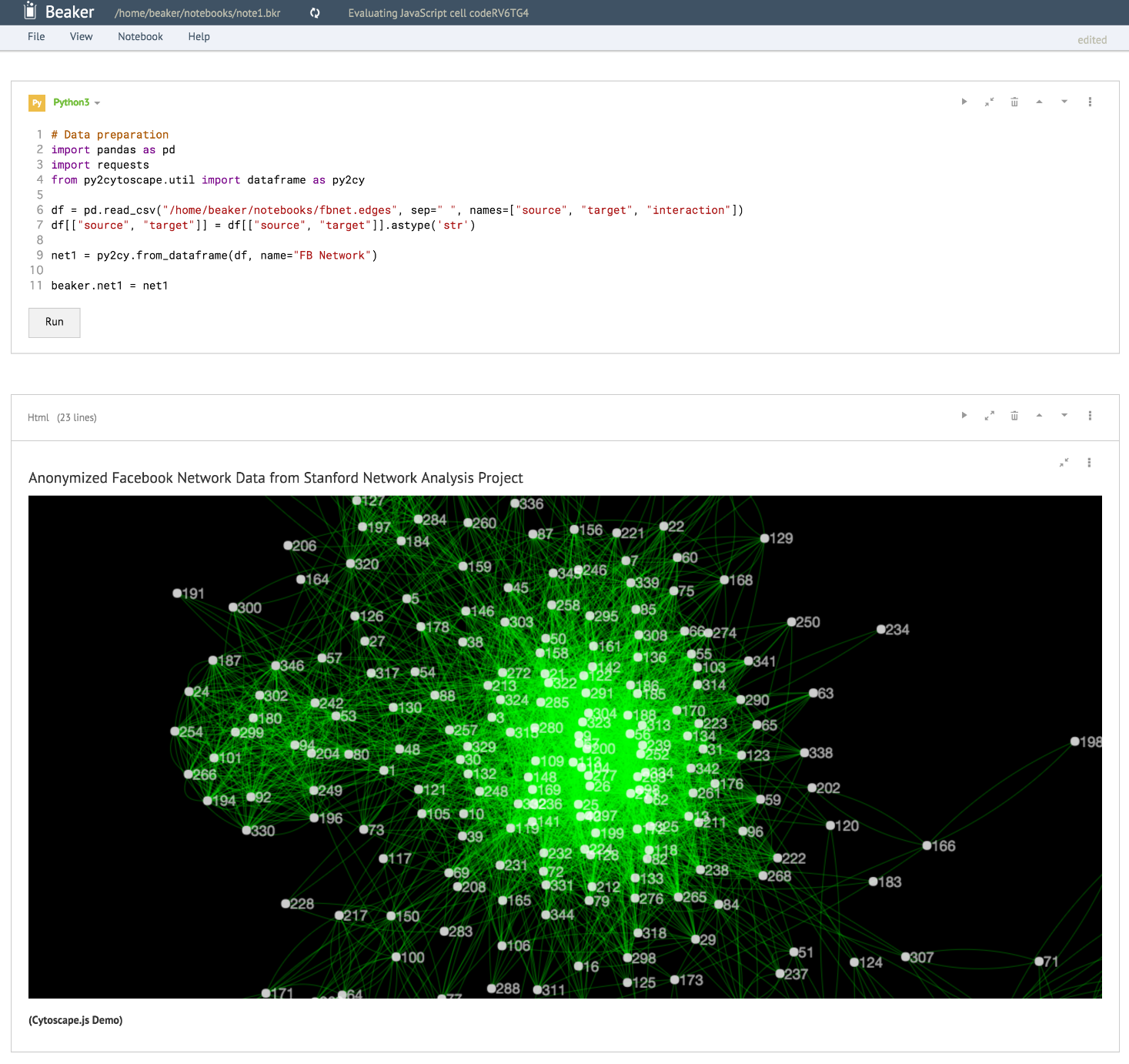
このように、__データの加工部分はPython、統計量算出はRでやりたいが、メインはD3.jsを使ったそのデータの描画__といった場合にこのアプリケーションはお薦めです。全ての工程を一つのノートブック内で行えるからです。
まとめ
今回はJupyterへのカスタムモジュール埋め込みとBeaker Notebookを紹介しましたが、後編では、Beakerでの実際の作業を見て行きます。