Domoとは?
公式サイトには以下のように書いてあります。
Domoは、あらゆるデータを統合・可視化でき、組織のデータ活用を促進するBIサービスです。急成長企業やスタートアップ、大企業、政府機関など、世界中のお客様がDomoを利用してデータ分析による意思決定を実現しています。
文章の通りなんですが、様々なデータをまとめて可視化するためのツールです。
対象読者
以下の方向けにDataFlowと呼ばれる、データを集計したり値を変更したりする機能の説明をしたいと思います。
- データ分析初心者だがDomoを使用することになった方
- Excelは分かるがBIツールについてはさっぱりな方
(本記事は2022年5月時点の内容です。更新する気はそんなにないです。)
Domoの基本的な考え方
Domoは大きく分けて以下の3つの工程でデータの可視化を行います。
※分からない単語が多くて大変かもしれませんが、分からない単語があれば下記に示す「※用語説明」をご参照ください。
- DataSet(入力データセット)でデータを取り込み、DataFlowでデータを集計し、新しいDataSet(出力データセット)を作成する。
- その後、可視化したいDataSetをAnalyzerで可視化し、「カード」を作成する。
- 最後に「ダッシュボード」に作成した複数の「カード」を見やすく配置する。
本記事ではDataFlowのMagicETLについて説明します。
※用語説明
- DataSet
- 入力データセット
- データの入り口を設定する機能、またはそのデータを指す。
- Google DriveやBoxなどのクラウドサービスにアップロードされたファイルを自動で取り込むことや、セールスフォースのデータを自動で取り込む設定などが可能。
- 出力データセット
- 入力データセットをインプットとして、Domo上で作成したアウトプットのデータセット。
- 入力データセット
- DataFlow
- データを集計する機能。
- データ集計の方法としてSQLを使用するものと、MagicETLを使用するものがある。
- SQL:データの分析を行うことに特化したプログラミング言語
- MagicETL:Domoが用意してくれた、SQLをGUI上で簡単に構築できる機能
- Analyzer
- DataSetを一つ指定し、そのDataSetを可視化する機能。
- Excelでいう、グラフの表示。
- 例えば、列の選択、棒グラフによる表示、円グラフによる表示、ピボットテーブルの作成、などなどが行える。
Excelに慣れた人向けの逆引きまとめ
DataFlowの詳細を記載する前に、せっかちな人向けにExcelでやりたいことをDomoでどう実現できるか一覧化しておきます。
Excelに慣れていない方、せっかちでない方は飛ばしていただいて構いません。
行単位でのIF関数、REPLACE関数、CONCAT関数、TEXT関数などで値をいじりたい
⇒「ユーティリティ - スクリプトを追加」
VLOOKUP関数やXLOOKUP関数などでマッピングを行いたい
⇒「データを結合 - データを結合」
MAXIF関数、COUNTIF関数、SUMIF関数、AVERAGEIF関数などで集計したい
⇒「集計する - グループ化」
データにフィルターをかけたい
⇒「フィルター - 行をフィルター」
(ただし、Analyzerでフィルタリングした方がよい場合が多い。)
データをソートしたい or ROW関数で順位を表示したい
⇒「集計する - ランクとウィンドウ」
ピボットテーブルを作成したい
⇒DataFlowではなく、Analyzerの機能でピボットテーブル化するとよい
(いちおう「ピボット - ピボット」という機能がある)
列を削除したい
⇒「ユーティリティー - 列を選択」
列のデータタイプ変更(日付→文字列など)を行いたい
⇒「ユーティリティー - 列を変更」
MagicETLの各種アイコン説明
DataFlowのMagicETLを以下に全てまとめます。
よく使用するものに★をつけておきます。
- DATASET
- 入力DataSet ★
- 出力DataSet ★
- テキスト
- テキストを置換
- テキストフォーマット
- 列を分割
- 列を結合
- 文字列演算
- 日付と数値
- 日付の演算
- 計算機
- ユーティリティー
- スクリプトを追加 ★
- 値マッパ
- 列の値を設定
- 列を変更 ★
- 列を選択 ★
- 定数を追加 ★
- フィルター
- 行をフィルター ★
- 重複を削除
- データを結合
- データを結合 ★
- 行を追加 ★
- 集計する
- グループ化 ★
- ランクとウィンドウ ★
- ピボット
- アンピボット
- ピボット
- 動的アンピボット
※DATASETに関しては説明を省略します。
ユーティリティー
一番よく使用する機能が多いので最初に「ユーティリティ」カテゴリに分類されるアイコンを説明します。
スクリプトを追加
一番使用する機能と言っても過言ではありません。データのある値に対して任意の計算を行い、新しい値を出力します。
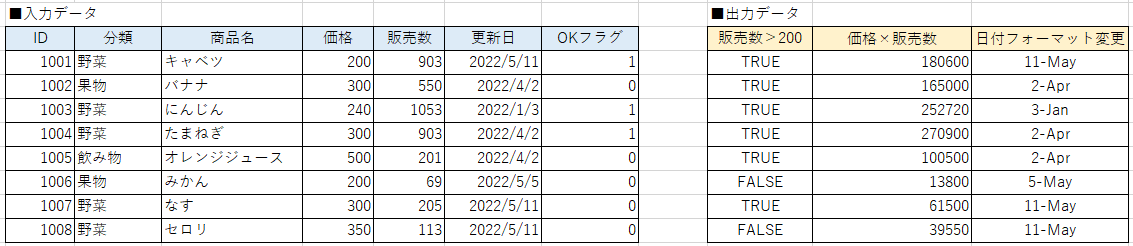
Excelで言うと四則演算、IF文による条件分岐、日付の表示形式変更などが行えます。
注意点としては同じ行のデータの値しか参照することができません。
下記の例でいうと、ID1001の出力データを計算するのにID1002の入力データなどは使用することはできないイメージです。
あくまで行単位での計算機能だと思ってください。(私はその認識ですが間違っていたらコメントください。)
面倒な点として、当然ですがDomo社が関数を定義しているので、行いたい処理のイメージはついているのにも関わらずDomoの関数はどれを使用すればいいかわからない、ということがよくあります。
その場合は下記の公式ドキュメントなどから探すしかありません。
https://domohelp.domo.com/hc/ja/articles/360043429933-Beast-Mode%E9%96%A2%E6%95%B0%E3%83%AA%E3%83%95%E3%82%A1%E3%83%AC%E3%83%B3%E3%82%B9%E3%82%AC%E3%82%A4%E3%83%89
ExcelやSQLの関数名と同じ関数名を定義している場合が多いので、困ったらそれらの関数名で検索するとよいかと思います。
値マッパ
行単位での文字列の置換です。
「ユーティリティ - スクリプトを追加」で同じことができるので、そちらを使用すればよいと思います。
列の値を設定
行単位で、列の値を特定の列の値に塗り替えるものです。
用途があまり思いつきませんし、「ユーティリティ - スクリプトを追加」で同じことができるので、そちらを使用すればよいと思います。
列を変更
値のデータタイプを変更するものです。

例えば「日付」データを「テキスト」データに変更するなどといったことが可能です。
また他にも「整数」データを「テキスト」データに変更し、その後「ユーティリティ - スクリプトを追加」で数字の始まりに英単語をつける、というような処理などでも使用されるかと思います。
列を選択
不要な列を削除したり、列名を変更するものです。
よく使用します。

特に「DATASET - 出力DataSet」の前に置くことが多いです。
最終的にDataSetとして出力する前に、不要な列を削除しておくとよいでしょう。
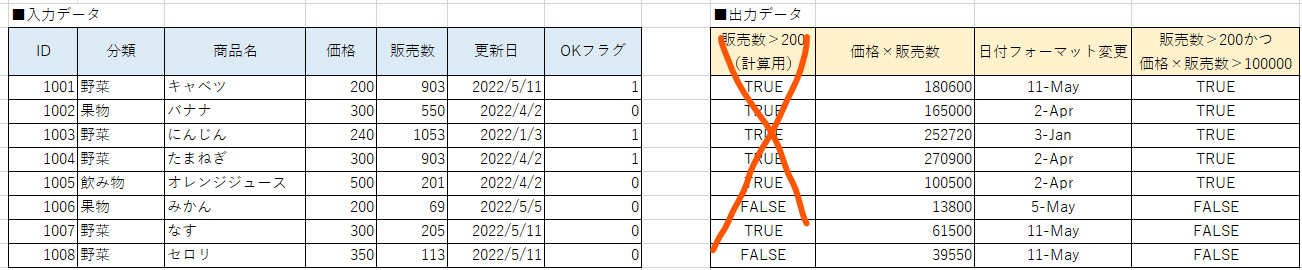
例を挙げるものでもないかと思いますが、念のため例を挙げておきます。
下記の「販売数>200」という列は計算用に作成した列なので、最終的な出力データセットとして不要な場合に削除する必要があります。そのようなときに使用します。
定数を追加
定数だけが代入された新しい列を追加します。

用途としては、入力データセットAと入力データセットBという2つのデータから1つの出力データセットを作成する場合、AとBを結合する前にどのデータが元々Aのものだったか、Bのものだったか判別するフラグを作成するときなどに使用します。
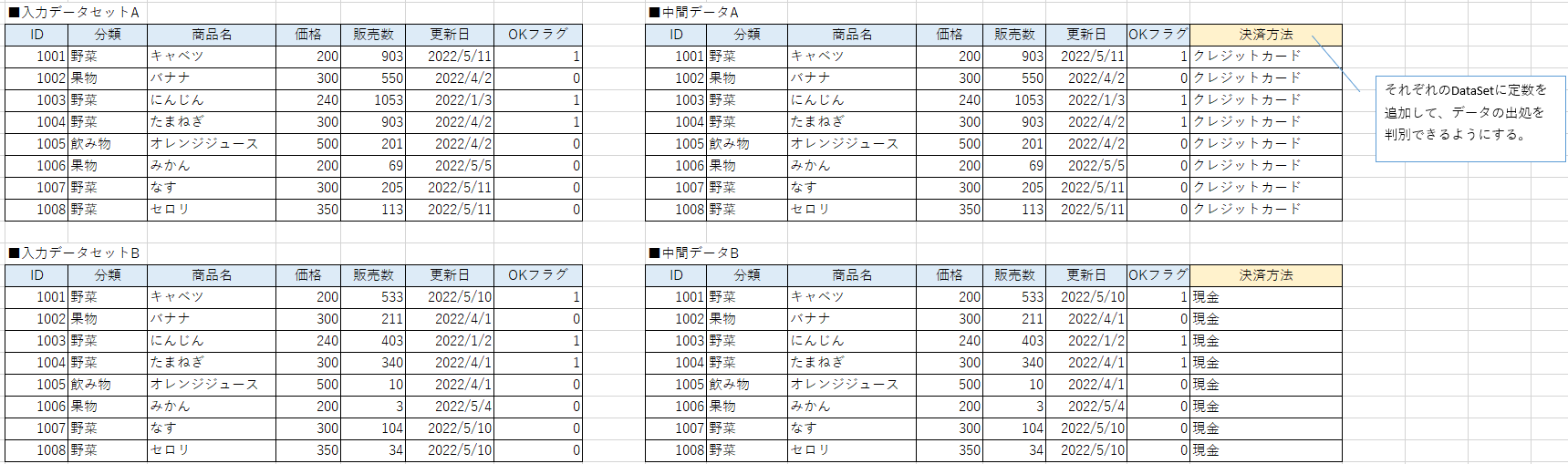
上記の例では「決済方法」という列名を追加し、それぞれのデータセットで異なる定数データを入力しています。
テキスト
下記の5つの機能があります。
ただ全て行単位での変換処理で、どれも「ユーティリティ - スクリプトを追加」で同じことができるので、使う機会はほとんどないかと思います。
- テキストを置換
- テキストフォーマット
- 列を分割
- 列を結合
- 文字列演算
日付と数値
下記2つの機能があります。
こちらに関しても全て行単位での変換処理で、どれも「ユーティリティ - スクリプトを追加」で同じことができるので、「ユーティリティ - スクリプトを追加」を使用すればよいです。
- 日付の演算
- 計算機
フィルター
行をフィルタリングする機能です。
不要な行を削除します。
行をフィルター
条件を定義して行単位のフィルタリングを行います。

Excelでいうところの「データ>フィルター」です。
SQLでいうところのWHERE句です。
前方一致や後方一致、不等号や日付比較などのフィルタリングが可能です。

注意点としては、フィルタリング自体はAnalyzerの方でも可能です。
言い換えれば可視化したときに、その表や図を見ている人が自由にフィルタリングできるように設計したいのであれば、DataFlowではフィルタリングせず、Analyzerの方でフィルタリングできるよう設計するとよいです。
※Analyzerについてはここでは詳細を述べません。そこまで難しいものでもないので、Analyzerの機能をいろいろ自分で試すとわかるかと思います。
重複を削除
指定した列の値が重複しているデータを削除します。

重複の削除を行うとDataSet上で上にあるデータが残ります。
下のExcelの例でいうとIDが若い3つのデータのみが残ります。

Excelでいうところの「データ>重複の削除」です。
SQLでいうところのDISTINCTです。
データを結合
こちらもとてもよく使用する機能です。
異なる二つのDataSetを結合するときに使用します。
データを結合
DataSet AとDataSet Bを横方向(行方向)に結合します。

言葉だけで説明すると難しくなるので例を挙げて説明します。
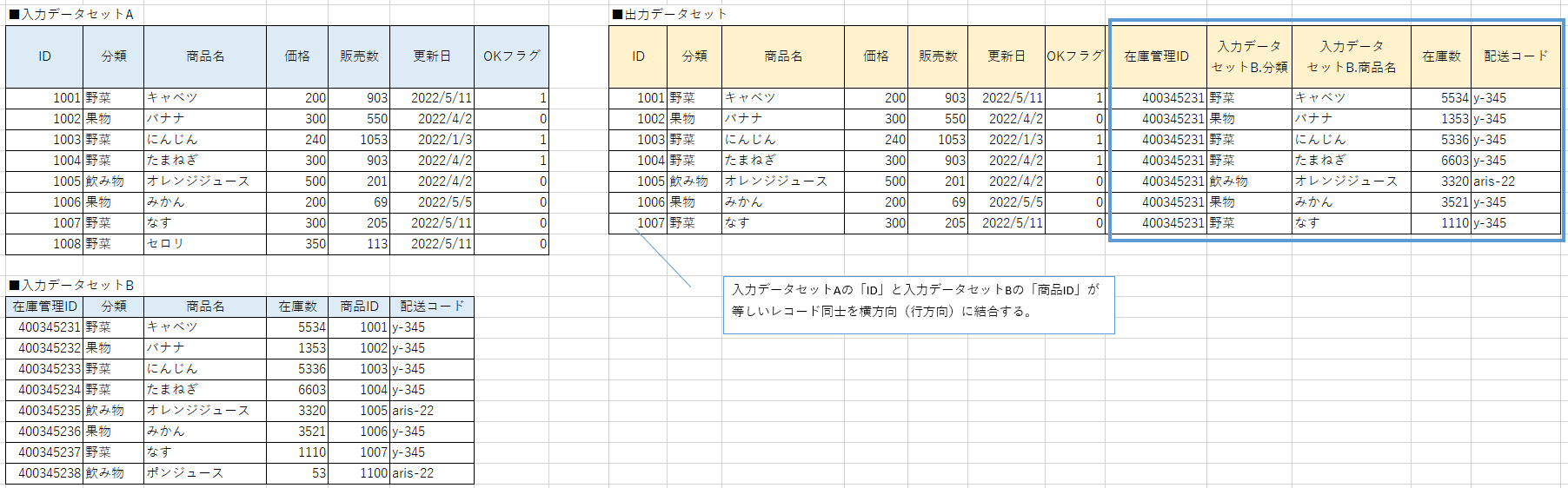
上記の例では入力データセットAの「ID」と入力データセットBの「商品ID」が等しいレコード同士を横方向に結合しています。
この場合の「ID」や「商品ID」を「結合キー」と言います。
(結合キーは複数指定することも可能です。)
結合後、列名が重複する場合、上の例の「入力データセットB.分類」のように「データセット名.列名」という表記に変更されることが一般的です。
結合の方法には以下の4つが存在します。
- 内側(INNER JOIN、またはJOINとも言う)
- 左外側(LEFT OUTER JOIN、またはLEFT JOINとも言う)
- 右外側(RIGHT OUTER JOIN、またはRIGHT JOINとも言う)
- 両方の外側(FULL OUTER JOIN、またはFULL JOINとも言う)
詳細はここでは省略します。
SQLの用語となってしまうのでSQLの解説記事になってしまいますが、詳細を知りたい方は下記の記事などを参照するとよいかと思います。
https://qiita.com/ngron/items/db4947fb0551f21321c0
いちおう、下記にそれぞれの結合の例を示しますのでそちらもご参照ください。
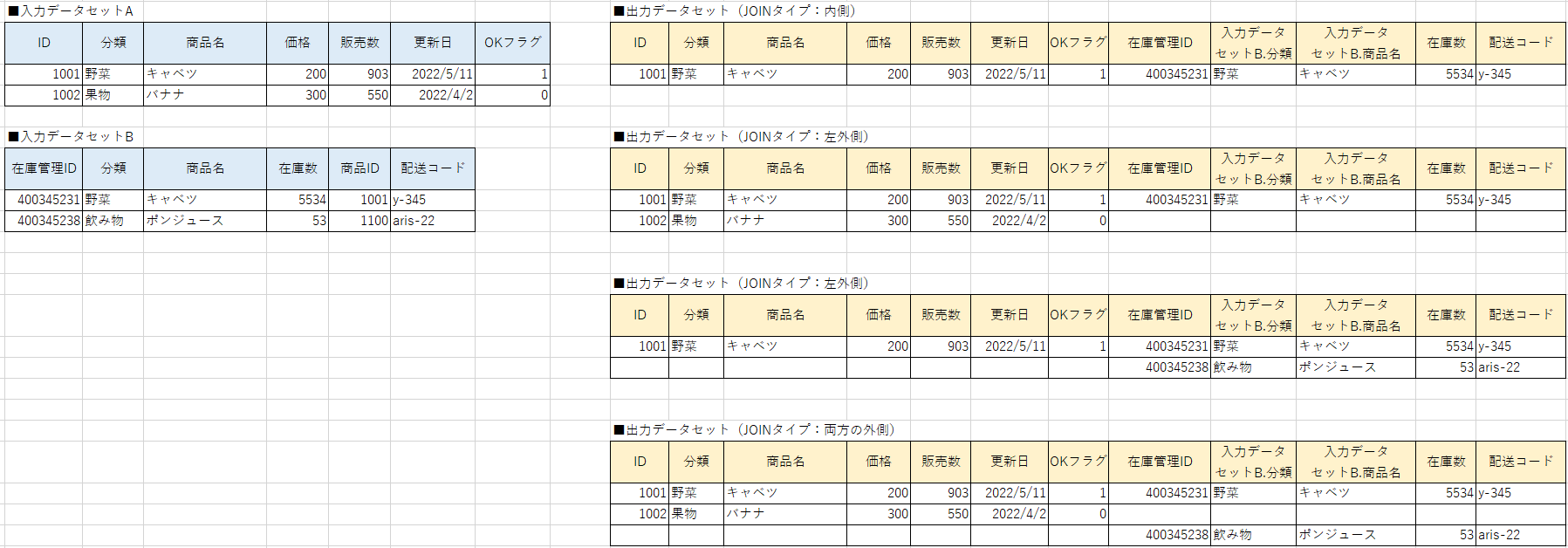
基本的には「内側」の結合を使用すればよいことが多いです。
また、私の個人的なルールかもしれませんが、結合元のデータを「左の表」、結合先のデータを「右の表」に設定することが暗黙の了解です。
ExcelでいうところのVLOOKUP、XLOOKUPでしょうか。。?
行を追加
DataSet AとDataSet Bを縦方向(列方向)に結合します。

「データを結合」は横方向の結合でしたが、今回は縦方向の結合ですので、直感的に理解しやすいかと思います。
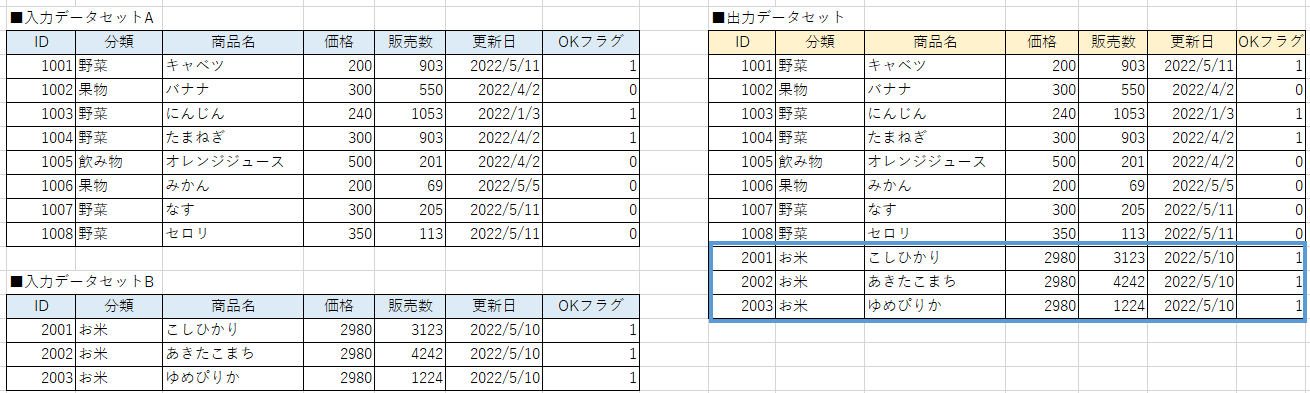
集計する
こちらもとてもよく使用する機能です。
「ユーティリティ - スクリプトを追加」などは行単位でしか計算が行えなかったのですが、「集計する」の機能では異なる行のデータを集計することが可能です。
グループ化
列を一つ指定し、その列の値ごとの合計値や平均値や最大値などを集計するものです。

イメージとしては指定した列でレコードを縦方向(列方向)に圧縮するものです。
下記の例では同じ更新日ごとの価格の平均値と販売数の合計値を集計しています。
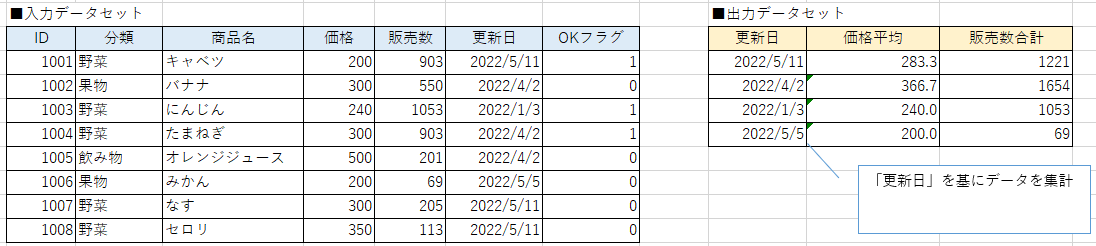
グループ化の手順としては以下のとおりです。
- 集計の基準となる列を指定する。(上記のキャプチャの例では「更新日」)
- 集計する列名を指定する。(上記の例では「価格平均」と「販売数合計」)
- 集計する方法を設定する。(上記の例では平均値と合計値を指定)
注意点としては、今までの「ユーティリティ - スクリプトを追加」や「データを結合 - データを結合」とは異なり入力のデータセットの列が全てリセットされます。
上の例でいうと、入力データセットには「ID」、「分類」、「商品名」などの列が存在していましたが、パラメータとして設定しない限り、出力データセットから列として削除されます。
言い換えれば、集計する際の基準となる列と、集計値の列しかアウトプットとして出力されません。
Excelでいうと、SUMIF、MAXIF、AVERAGEIF、COUNTIFなどの関数がこの機能に当たります。
SQLでいうところのGROUP BY句です。
ランクとウィンドウ
データのソートとソート順を新しく列として追加するものです。
(実際は他にも「ウィンドウ」という機能がありますが、「ランク」の用途で使用することがほとんどなので、今回は「ウィンドウ」の説明を省略します。)

ソート、および出力できる列は以下の種類があります。
※Domo側で表示している分類とは少し異なりますが、こちらの方が理解が早いかと思います。
- ランキング
- ランク
- DenseRank
- 行番号を挿入
- 行番号
- その他
- (今回は説明を省略)
よく使用するのは「ランク」と「DenseRank」と「行番号」です。
「ランク」と「DenseRank」は下記のキャプチャを見るのが最も理解が早いかと思います。
Excelでいうところのソート機能でしょうか。
SQLでいうところのSORT BY句です。

「ランク」と「DenseRank」の違いは同順位がいた場合に順位を詰めるか、詰めないかの違いでしかありません。
「行番号」はただ行の番号を新規の列として出力するものです。
ExcelでいうところのROW関数です。
SQLは、、ROW_NUMBER関数というものがあるそうですね、知らなかったです。
ピボット
ピボットについてはExcelのピボットテーブルを知っていると理解がとても早いです。
もし読者の方がデータ分析計の部署にいらっしゃるのであれば、Excelのピボットテーブルもよく使う機能だと思うので、これを機に先にExcelの方を調べておくとよいかと思います。
ピボット
「集計する - グループ化」が行単位での集計だったのに対し、行単位だけでなく列単位で集計するものです。

こちらに関しては公式ドキュメントがわかりやすいのでそちらを見た方がよいです。
https://domohelp.domo.com/hc/ja/articles/360044951294-%E6%96%B0%E3%81%97%E3%81%84Magic-ETL%E3%82%BF%E3%82%A4%E3%83%AB-%E3%83%94%E3%83%9C%E3%83%83%E3%83%88
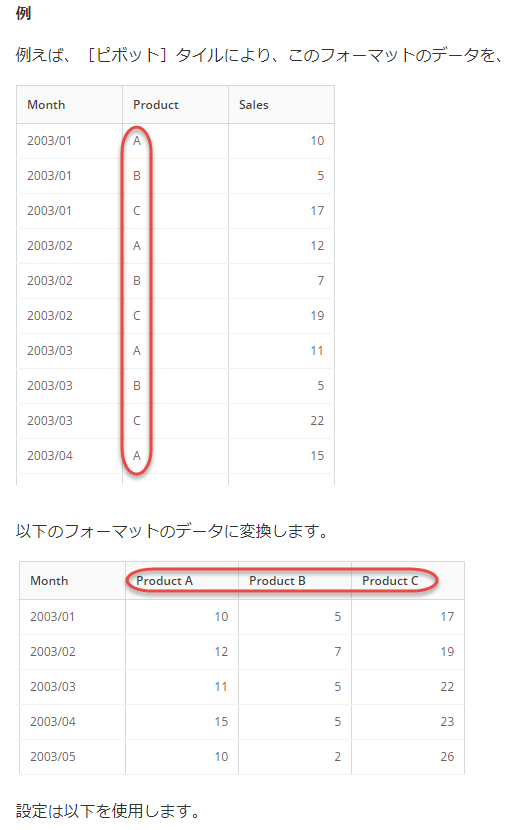
注意点としては、必ずしもDataFlow上でピポットテーブルの形式にする必要はない、ということです。
というのも、Analyzerの機能でピボットテーブルに変換する機能が存在し、そちらの方が直感的にピボットテーブルを作成しやすいので、多くの場合はそちらを利用すればよいかと思います。
なのでピボットテーブル化するようなことがもしあれば、一度踏みとどまってAnalyzerの方の機能を十分に試してから、DataFlowの最終化を行うかとよいと思います。
いちおうAnalyzerの方のドキュメントを下記に示しておきます。
https://domohelp.domo.com/hc/ja/articles/360043429473-%E3%83%94%E3%83%9C%E3%83%83%E3%83%88%E3%83%86%E3%83%BC%E3%83%96%E3%83%AB
アンピボット
ピボットされた表をピポットされていない状態に戻すものです。

こちらも公式ドキュメントを参照するのが最も理解が早いかと思います。
動的アンピボット
上記の「アンピボット」が静的なテーブルを対象に実施されるのに対して、動的なテーブルのピボット解除したいときに使用するのがこちらです。
(わかりにくくてすみません、下記に詳細を示します。)

アンピボットとの違いは以下の通りです。
アンピボット:ピボットを解除する列を指定する
動的アンピボット:ピボットを解除しない列を指定し、それ以外の列を全てピボット解除の対象とする
なので動的に列が増えるテーブルに対しては、動的アンピボットを使用するとよいです。
ただ、そのような事例は頻繁に起こることではないと思いますので、頭の片隅にいれておけばよいかと思います。
さいごに
今回はDomoのDataFlow MagicETLについて説明しました。
SQLを使用せずに直感的にSQLライクなデータ分析ができる!という謳い文句でMagicETLという機能が公開されていますが、私がさわってみた感じ、SQLの知識は少し必要かと思います。
もともとExcelの関数に慣れている方であれば、SQLの知識が不要かもしれませんが、結局そういう人ってSQLの知識もっていますよね。。
逆に言えば、SQLも慣れていない・データ分析自体も初めて、という方が触れる分にはSQLの勉強になってとてもよいかと思います。
また、SQLに慣れた人でもMagicETLの方が直感的に理解しやすい&他の人に説明しやすいかと思うので、もっと玄人向けに設計してもいいのになぁと思いました。
特にJOINの条件がイコールしかないので、他の行のデータを参照するして集計することができなかったりします。
まあ、その場合はSQL書けって話なのかもしれませんが。
以上です。