Part 5 ChemTHEATREデータの地図上へのプロット(前編)
Chap.0 全体の流れ
Part 5では、ChemTHEATREのデータを利用して、計測された化学物質の濃度を地図上にプロットする。いうなれば簡易的なGISである。
前編ではデータ処理~地図上へのプロットを、後編では出力した画像データをつなぎ合わせてアニメーションを作成することを目指す。

Chap.1 ライブラリの読み込み
Cartopyをインストールしてない場合は、予めインストールしておく。
conda install -c conda-forge cartopy
その上で、以下のライブラリを読み込む。
%matplotlib inline
import os
import numpy as np
import pandas as pd
import itertools
import matplotlib.pyplot as plt
from cartopy import crs as ccrs
今回も処理に必要になってくるライブラリーをインポートするところから始める。
1行目は例によって、matplotlibの出力結果を表示するコマンドである。
Part 5では、以下のライブラリを利用することになる。(2行目以降参照)
なお、いずれもAnaconda3(Windows 64bit版)にはすでにインストールされている。
今回は、matplotlibのグラフ上に地図を表示するためにcartopyを利用する。
| ライブラリ | 概要 | 今回の使用目的 | 公式URL |
|---|---|---|---|
| os | 標準ライブラリ | ディレクトリの操作 | https://docs.python.org/ja/3/library/os.html |
| NumPy | 数値計算ライブラリ | 統計処理上の数値計算に利用 | https://www.numpy.org |
| itertools | イテレータ1を生成する 標準ライブラリ |
ループ処理を効率化するのに利用 | https://docs.python.org/ja/3/library/itertools.html |
| pandas | データ分析ライブラリ | データ処理や整形に利用 | https://pandas.pydata.org |
| Matplotlib | グラフ描画ライブラリ | データの可視化に利用 | https://matplotlib.org |
| cartopy | 地図描画ライブラリ | 地図データの可視化に利用 | https://scitools.org.uk/cartopy/docs/latest |
Chap.2 データの読み込み
ライブラリの準備ができたので、次にデータの読み込みを行う。今回は海棲哺乳類のデータを使用するので、ChemTHEATREのSample SearchでSample Typeを「Biotic - Mammals - Marine mammals」として検索する。検索結果から、「Export samples」と「Export measured data」をクリックして、サンプル一覧と測定値一覧のファイルをそれぞれダウンロードする。ファイルを任意のディレクトリに保存し、下記の要領でノートブックから読み込む。
data_file = "measureddata_20191002074038.tsv" #変数に入力する文字列を、各自のmeasureddataのtsvファイル名に変更する
data = pd.read_csv(data_file, delimiter="\t")
data = data.drop(["ProjectID", "ScientificName", "RegisterDate", "UpdateDate"], axis=1) #後でsamplesと結合する際に重複する列の削除
data
| MeasuredID | SampleID | ChemicalID | ChemicalName | ExperimentID | MeasuredValue | AlternativeData | Unit | Remarks | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1026 | SAA000173 | CH0000034 | PCB4+PCB10 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | NaN |
| 1 | 1027 | SAA000173 | CH0000035 | PCB8 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | NaN |
| 2 | 1028 | SAA000173 | CH0000037 | PCB19 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | NaN |
| 3 | 1029 | SAA000173 | CH0000038 | PCB22 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | NaN |
| 4 | 1030 | SAA000173 | CH0000039 | PCB28 | EXA000001 | 32.000 | NaN | ng/g lipid | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7098 | 27705 | SAA002002 | CH0000094 | PCB208 | EXA000001 | 77.249 | NaN | ng/g lipid | NaN |
| 7099 | 27706 | SAA002002 | CH0000088 | PCB194 | EXA000001 | 512.160 | NaN | ng/g lipid | NaN |
| 7100 | 27707 | SAA002002 | CH0000092 | PCB205 | EXA000001 | 3.000 | <3.00E+0 | ng/g lipid | NaN |
| 7101 | 27708 | SAA002002 | CH0000093 | PCB206 | EXA000001 | 81.947 | NaN | ng/g lipid | NaN |
| 7102 | 27709 | SAA002002 | CH0000095 | PCB209 | EXA000001 | 127.064 | NaN | ng/g lipid | NaN |
7103 rows × 9 columns
sample_file = "samples_20191002074035.tsv" #変数に入力する文字列を、各自のsamplesのtsvファイル名に変更する
sample = pd.read_csv(sample_file, delimiter="\t")
sample
| ProjectID | SampleID | SampleType | TaxonomyID | UniqCodeType | UniqCode | SampleName | ScientificName | ... | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | PRA000003 | SAA000173 | ST004 | 34892 | es-BANK | EW00884 | M32582 | Neophocaena phocaenoides | ... |
| 1 | PRA000003 | SAA000174 | ST004 | 34892 | es-BANK | EW00888 | M32588 | Neophocaena phocaenoides | ... |
| 2 | PRA000003 | SAA000175 | ST004 | 34892 | es-BANK | EW00932 | M32580 | Neophocaena phocaenoides | ... |
| 3 | PRA000003 | SAA000176 | ST004 | 34892 | es-BANK | EW00929 | M33556 | Neophocaena phocaenoides | ... |
| 4 | PRA000003 | SAA000177 | ST004 | 34892 | es-BANK | EW00934 | M32548 | Neophocaena phocaenoides | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 197 | PRA000036 | SAA002159 | ST004 | 103596 | es-BANK | EW04779 | 060301-1 | Peponocephala electra | ... |
| 198 | PRA000036 | SAA002160 | ST004 | 103596 | es-BANK | EW00115 | M32625 | Peponocephala electra | ... |
| 199 | PRA000036 | SAA002161 | ST004 | 103596 | es-BANK | EW00122 | M32633 | Peponocephala electra | ... |
| 200 | PRA000036 | SAA002162 | ST004 | 103596 | es-BANK | EW00116 | M32626 | Peponocephala electra | ... |
| 201 | PRA000036 | SAA002163 | ST004 | 103596 | es-BANK | EW00117 | M32627 | Peponocephala electra | ... |
202 rows × 66 columns
Chap.3 データの下処理
Chap.2で読み込んだDataFrameを地図にプロットできるようにした準備する。まず、measureddataとsamplesを結合し、N/Aの列を削除する。
df = pd.merge(data, sample, on="SampleID")
df = df.dropna(how='all', axis=1)
df
| MeasuredID | SampleID | ChemicalID | ChemicalName | ExperimentID | MeasuredValue | AlternativeData | Unit | ... | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1026 | SAA000173 | CH0000034 | PCB4+PCB10 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | ... |
| 1 | 1027 | SAA000173 | CH0000035 | PCB8 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | ... |
| 2 | 1028 | SAA000173 | CH0000037 | PCB19 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | ... |
| 3 | 1029 | SAA000173 | CH0000038 | PCB22 | EXA000001 | 0.010 | <1.00E-2 | ng/g lipid | ... |
| 4 | 1030 | SAA000173 | CH0000039 | PCB28 | EXA000001 | 32.000 | NaN | ng/g lipid | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7098 | 27705 | SAA002002 | CH0000094 | PCB208 | EXA000001 | 77.249 | NaN | ng/g lipid | ... |
| 7099 | 27706 | SAA002002 | CH0000088 | PCB194 | EXA000001 | 512.160 | NaN | ng/g lipid | ... |
| 7100 | 27707 | SAA002002 | CH0000092 | PCB205 | EXA000001 | 3.000 | <3.00E+0 | ng/g lipid | ... |
| 7101 | 27708 | SAA002002 | CH0000093 | PCB206 | EXA000001 | 81.947 | NaN | ng/g lipid | ... |
| 7102 | 27709 | SAA002002 | CH0000095 | PCB209 | EXA000001 | 127.064 | NaN | ng/g lipid | ... |
7103 rows × 39 columns
次に、必要なデータの抽出を行う。今回取り扱うのは単位が[ng/g lipid]の4種類の化学物質(ΣPCBs, ΣDDTs, ΣCHLs, ΣHCHs)についてのデータである。
data_lipid = df[df["Unit"] == "ng/g lipid"]
data_lipid = data_lipid[(data_lipid["ChemicalName"] == "ΣPCBs") | (data_lipid["ChemicalName"] == "ΣDDTs") |
(data_lipid["ChemicalName"] == "ΣCHLs") | (data_lipid["ChemicalName"] == "ΣHCHs")]
これで必要なデータの抽出は終了した。確認も兼ねて、このデータセットに含まれる生物種と化学物質名の一覧を取得する。
lipid_species = data_lipid["ScientificName"].unique()
lipid_chemicals = data_lipid["ChemicalName"].unique()
lipid_species, lipid_chemicals
(array(['Peponocephala electra', 'Neophocaena phocaenoides',
'Sousa chinensis', 'Stenella coeruleoalba'], dtype=object),
array(['ΣPCBs', 'ΣDDTs', 'ΣCHLs', 'ΣHCHs'], dtype=object))
またここで、後編でも同じデータを利用できるように、DataFrame・data_lipidをCSV形式で出力しておく。CSVの出力はPandasのto_csvメソッドを利用する。
data_lipid.to_csv("data.csv")
Chap.4 地図へのプロット
Sec.4-1 ベースとなる図
続いて、今回のメインである、地図上へのプロットを行う。だが、最初にどのように地図を作成するかを丁寧に確認しておく。
今回のグラフは、地図上に出力することになるので、まず地図の出力を行う。Pythonではcartopyを利用すると、matplotlib上に地図を出力する事ができる。
ax = plt.axes(projection=ccrs.PlateCarree())
ax.coastlines()
plt.show()
次に、地図の上に重ねるグラグの確認をする。今回は緯度・経度の2次元空間内での地点を計測地点としてプロットするので、散布図としてデータを描く。
描画する前に、data_lipidに含まれる生物種ごとにデータを選り分ける。
df_0 = data_lipid[(data_lipid["ChemicalName"] == "ΣPCBs") & (data_lipid["ScientificName"] == lipid_species[0])] #カズハゴンドウのΣPCBs
df_1 = data_lipid[(data_lipid["ChemicalName"] == "ΣPCBs") & (data_lipid["ScientificName"] == lipid_species[1])] #スナメリのΣPCBs
df_2 = data_lipid[(data_lipid["ChemicalName"] == "ΣPCBs") & (data_lipid["ScientificName"] == lipid_species[2])] #シナウスイロイルカのΣPCBs
df_3 = data_lipid[(data_lipid["ChemicalName"] == "ΣPCBs") & (data_lipid["ScientificName"] == lipid_species[3])] #スジイルカのΣPCBs
データがより分けられたら、散布図に起こしてみる。matplotlibのグラフ描画は、上に重ねがけすることができるので、順々に書き加えていくイメージで良い。
fig = plt.figure()
ax = plt.axes()
# CollectionLongitudeFrom, CollectionLatitudeFromから緯度経度情報を抽出
ax.scatter(x = np.array(df_0["CollectionLongitudeFrom"]), y = np.array(df_0["CollectionLatitudeFrom"]), c = "red", alpha=0.5)
ax.scatter(x = np.array(df_1["CollectionLongitudeFrom"]), y = np.array(df_1["CollectionLatitudeFrom"]), c = "blue", alpha=0.5)
ax.scatter(x = np.array(df_2["CollectionLongitudeFrom"]), y = np.array(df_2["CollectionLatitudeFrom"]), c = "yellow", alpha=0.5)
ax.scatter(x = np.array(df_3["CollectionLongitudeFrom"]), y = np.array(df_3["CollectionLatitudeFrom"]), c = "green", alpha=0.5)
plt.show()

Sec.4-2 散布図 + 正距円筒図法
ベースとなる図が描画できたので、今度はそれらを重ね合わせて描画してみる。

fig = plt.figure()
ax = plt.axes(projection=ccrs.PlateCarree())
ax.coastlines()
ax.scatter(x = np.array(df_0["CollectionLongitudeFrom"]), y = np.array(df_0["CollectionLatitudeFrom"]), c = "red", alpha=0.5)
ax.scatter(x = np.array(df_1["CollectionLongitudeFrom"]), y = np.array(df_1["CollectionLatitudeFrom"]), c = "blue", alpha=0.5)
ax.scatter(x = np.array(df_2["CollectionLongitudeFrom"]), y = np.array(df_2["CollectionLatitudeFrom"]), c = "yellow", alpha=0.5)
ax.scatter(x = np.array(df_3["CollectionLongitudeFrom"]), y = np.array(df_3["CollectionLatitudeFrom"]), c = "green", alpha=0.5)
plt.show()

Sec.4-3 Sec.4-2の改良
Sec.4-2で一応出力することができた。しかし、今の状態では地図の範囲が自動で設定されている。これは、データの存在する範囲が全て含まれるように自動処理されているだけなので、取り扱うデータによってその範囲が変わってしまう。ここでは、適当な範囲で地図を固定化する。
matplotlibのset_xlim・set_ylimメソッドを使うことで、それぞれ描画するグラフのX軸方向・Y軸方向の範囲を決めることができる。

fig = plt.figure()
ax = plt.axes(projection=ccrs.PlateCarree())
ax.coastlines()
ax.scatter(x = np.array(df_0["CollectionLongitudeFrom"]), y = np.array(df_0["CollectionLatitudeFrom"]), c = "red", alpha=0.5)
ax.scatter(x = np.array(df_1["CollectionLongitudeFrom"]), y = np.array(df_1["CollectionLatitudeFrom"]), c = "blue", alpha=0.5)
ax.scatter(x = np.array(df_2["CollectionLongitudeFrom"]), y = np.array(df_2["CollectionLatitudeFrom"]), c = "yellow", alpha=0.5)
ax.scatter(x = np.array(df_3["CollectionLongitudeFrom"]), y = np.array(df_3["CollectionLatitudeFrom"]), c = "green", alpha=0.5)
ax.set_xlim(90,180) #描画するX軸(経度)方向の範囲
ax.set_ylim(15, 60) #描画するY軸(緯度)方向の範囲
ax.set_title("ΣPCBs")
plt.show()

Chap.5 1枚にまとめて出力する
Chap.3でわかったとおり、このDataFrameには4種類の化学物質のデータが含まれているので、これらを4つ並べて1枚にまとめた形にして出力してみる。
まず、Chap.4でもやったように、化学物質ごとにデータの選り分けを行うのだが、全部で16通り(生物・化学物質が4種ずつ)の組み合わせがあるので、ここではリストにまとめて、描画する際に順次読み込む形を取る。この際、それぞれの組み合わせ(例えばスナメリのΣPCBs)を生成する必要があるので、Pythonのイテレータ1という機能を利用して、直積2を求めることにする。つまり、化学物質のリスト(lipid_chemicals)と生物種名のリスト(lipid_species)の直積を求めて、16通りの組み合わせパターンすべてを導出する。
df_list = []
for k1, k2 in itertools.product(lipid_chemicals, lipid_species):
df_list.append(data_lipid[(data_lipid["ChemicalName"] == k1) & (data_lipid["ScientificName"] == k2)]) #各組み合わせのデータを抽出
ax = [0]*4
fig = plt.figure(figsize=(16, 9))
for i in range(4):
ax[i] = fig.add_subplot(2, 2, i+1, projection=ccrs.PlateCarree()) #グラフを描く領域を追加
ax[i].coastlines()
ax[i].scatter(x = np.array(df_list[4*i+0]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+0]["CollectionLatitudeFrom"]),
c = "red", alpha=0.5) #カズハゴンドウ
ax[i].scatter(x = np.array(df_list[4*i+1]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+1]["CollectionLatitudeFrom"]),
c = "blue", alpha=0.5) #スナメリ
ax[i].scatter(x = np.array(df_list[4*i+2]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+2]["CollectionLatitudeFrom"]),
c = "yellow", alpha=0.5) #シナウスイロイルカ
ax[i].scatter(x = np.array(df_list[4*i+3]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+3]["CollectionLatitudeFrom"]),
c = "green", alpha=0.5) #スジイルカ
ax[i].set_xlim(90,180)
ax[i].set_ylim(15, 60)
ax[i].set_title(lipid_chemicals[i])
plt.show()

これでは計測地点が反映されるだけなので、測定値も地図上にプロットしてみる。各散布点の半径に反映してみる。散布図を描くscatterメソッドのsパラメータにMeasuredValue列のデータを代入するだけで良い。
fig = plt.figure(figsize=(16, 9))
for i in range(4):
ax[i] = fig.add_subplot(2, 2, i+1, projection=ccrs.PlateCarree())
ax[i].coastlines()
ax[i].scatter(x = np.array(df_list[4*i+0]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+0]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+0]["MeasuredValue"]), c = "red", alpha=0.5)
ax[i].scatter(x = np.array(df_list[4*i+1]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+1]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+1]["MeasuredValue"]), c = "blue", alpha=0.5)
ax[i].scatter(x = np.array(df_list[4*i+2]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+2]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+2]["MeasuredValue"]), c = "yellow", alpha=0.5)
ax[i].scatter(x = np.array(df_list[4*i+3]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+3]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+3]["MeasuredValue"]), c = "green", alpha=0.5)
ax[i].set_xlim(90,180)
ax[i].set_ylim(15, 60)
plt.title(lipid_chemicals[i])
plt.show()
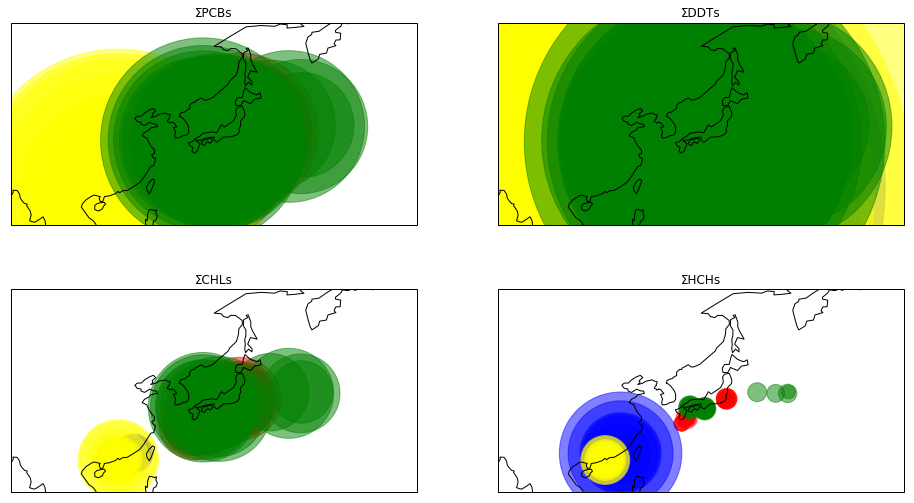
MeasuredValueの値をそのまま散布点の半径に代入すると、特にΣDDTsのグラフの円が大きくなって、全てが重なってしまうので半径を小さくするように調整する。ここでは、一律10分の1の大きさにする。
fig = plt.figure(figsize=(16, 9))
rate = [10,10,10,10] #縮尺を示す変数
for i in range(4):
ax[i] = fig.add_subplot(2, 2, i+1, projection=ccrs.PlateCarree())
ax[i].coastlines()
ax[i].scatter(x = np.array(df_list[4*i+0]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+0]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+0]["MeasuredValue"])/rate[i], c = "red", alpha=0.3)
ax[i].scatter(x = np.array(df_list[4*i+1]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+1]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+1]["MeasuredValue"])/rate[i], c = "blue", alpha=0.3)
ax[i].scatter(x = np.array(df_list[4*i+2]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+2]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+2]["MeasuredValue"])/rate[i], c = "yellow", alpha=0.3)
ax[i].scatter(x = np.array(df_list[4*i+3]["CollectionLongitudeFrom"]), y = np.array(df_list[4*i+3]["CollectionLatitudeFrom"]), s=np.array(df_list[4*i+3]["MeasuredValue"])/rate[i], c = "green", alpha=0.3)
ax[i].set_xlim(90,180)
ax[i].set_ylim(15, 60)
plt.title(lipid_chemicals[i])
plt.show()
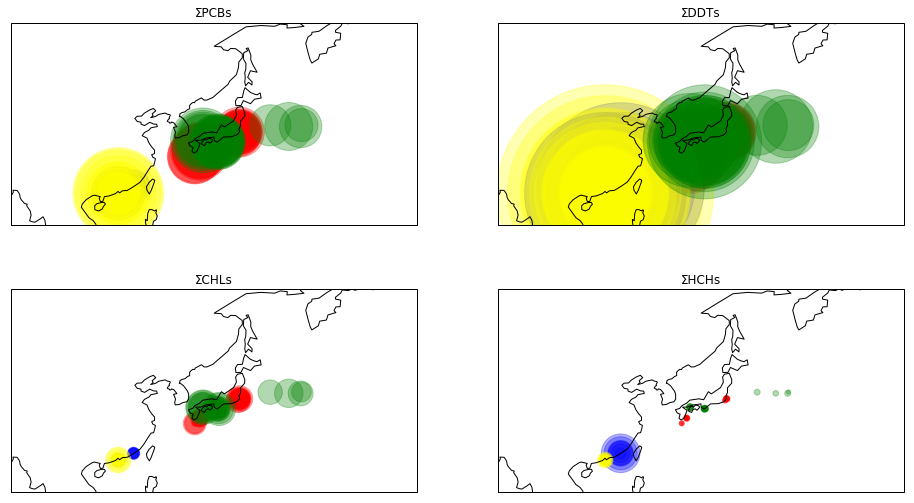
これで、地図上に計測結果をプロットするところまではできた。しかし、すべてのデータが重なって表示されるので非常に見にくい図となっており、この図では時系列的な変化もわからない。後編では、それらの問題を解消するためにアニメーションにする。
脚注
1イテレータとは、リストなどのデータの集合する型で次の要素にアクセスすることを繰り返す仕組みのこと。
2直積とは、下図のように各集合から要素を1つずつ取り出して組にして、新たな集合を作ること。デカルト積とも。
