データベース(DB)は膨大な量のデータを活用しやすい形式で永続的に管理するために使用されます。
Webサービスなどの運用においては、サービスやユーザのデータを適切に管理することは非常に重要となるので、この記事では初心者向けにデータベースの種類やそれぞれの使い分けについて基礎的な事柄をまとめていきます。
データベースの種類
ここではまずその構造に着目して、3種類のデータベースを紹介していきます。もちろん、「データを保存する」という役割はどれも共通ですが、データを保存する際の構造にそれぞれ特徴があるので、その差異を理解しながら読んでいただければと思います。
1. 階層型データベース
階層型データベースは歴史が長く、データの保存に次の図のようなツリー構造を用います。見てのとおり、上位(親)ノードから下位(子)ノードへは1対多数の関係でデータが格納されていき、逆に子ノードから見れば親ノードは一意的に決まります。

長所
階層型データベースの長所はあるデータに到達する際のルートが一意的であるため、検索速度が非常に速いことです。
短所
階層型データベースの短所は子ノードが複数の親ノードに属する状況が発生した場合にデータを重複して登録しなければならないことです。上記の図でいうと、例えば社員Aがプロジェクト1だけでなく、プロジェクト2にも携わっている場合には、プロジェクト2の下に改めて社員Aを追加することになります。これでは社員Aがデータベースに重複して登録されることになり、冗長な構造となってしまいます。
2.ネットワーク型データベース
次の図から分かるように、ネットワーク型データベースの構造は基本的には階層型データベースの構造と似ています。しかしながら、大きく異なるのは「子ノードが複数の親ノードにつながっている」という点です。こうすることで、先に指摘した階層型データベースの短所をクリアしています。子ノードから複数の線が出ていることで網目状構造になるのでネットワーク型と呼ばれています。

長所
ネットワーク型データベースの長所は、繰り返しになりますが、子ノードが複数の親ノードを持てるようになったことです。そうすることで、階層型データベースで問題となった冗長構造を回避できるようになりました。
短所
ネットワーク型データベースの短所はデータ構造が複雑になって把握しづらいことです。子ノードが複数の親ノードを持てるという特徴は冗長性の観点からは長所ですが、階層型データベースに比べて構造が複雑になるという短所も含んでいます。構造が把握できないと、結果的にデータへのアクセスができなくなってしまいます。
3.リレーショナルデータベース(RDB)
RDBのデータ構造は先述の2つとは大きく異なり、列と行からなる表(テーブル)で構成されています。MicrosoftのExcelやGoogleのスプレッドシートをイメージすれば分かりやすいと思います。現在ではこのRDBがデータベースの主流となっています。ちなみに、RDBはあくまでデータベースの種類なので、実際にデータベースを使っていく際には、Oracle Database、Microsoft SQL Server、MySQL、PostgreSQLなどから適切なものを選んで使用します。
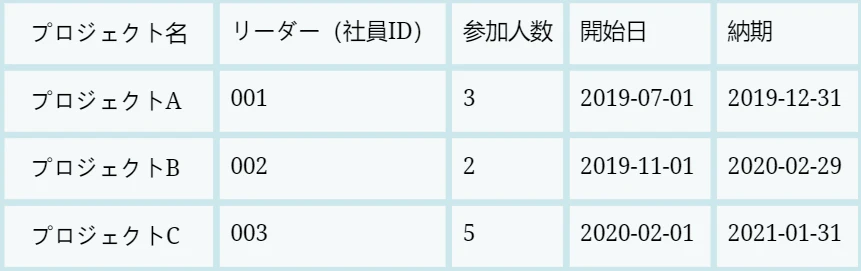
長所
RDBの大きな長所はテーブルを用いることによって複雑なデータであっても分かりやすく扱えるようになったことです。また、親・子という概念がなくなったので、ツリーを辿ってデータの操作を行うのではなく、個々のデータを直接的に操作できるようになりました。後ほど補足しますが、RDBのデータ操作はSQLという言語を使って行われます。
短所
RDBにおいては複数のテーブルを用いることが一般的なので、正しくデータ処理をするためにはこれらのテーブル間で常に整合性を保っておく必要があります。「整合性」という言葉が少し分かりづらいかもしれないので、ここで補足します。例えば、上記のテーブルではリーダーが社員IDで記載されていますが、社員IDだけでは実際にどの社員なのかが分からないので、以下のように社員番号と社員の関係性を示すテーブルを別途用意する必要があります。
| 社員ID | 名前 | 年齢 | 部署 | メールアドレス |
|---|---|---|---|---|
| 001 | 佐藤 | 35 | 技術○○課 | satoh@example.com |
| 002 | 鈴木 | 28 | 技術××課 | suzuki@example.com |
| 003 | 山田 | 30 | 開発○○課 | yamada@example.com |
| 004 | 高橋 | 37 | 開発××課 | takahashi@example.com |
| ここで、仮に社員ID001の佐藤が何らかの理由で退職し、社員ID004の高橋がプロジェクトAのリーダーを引き継いだとします。この場合には、まず社員がいなくなったことにより、社員のテーブルの更新が発生します。続けてプロジェクトAのリーダーが変わったので、同時にプロジェクトのテーブルも書き換えなければなりません。この連続した更新操作が遅延なく正しく行われていれば、データベースは整合性を保っていると言えます。もし、どちらかの更新しかなされなければ、データベースは不整合を起こしていることになります。このように、RDBを使う際には整合性に注意をする必要があります。 |
補足
ここでは先ほど言葉だけ登場したSQLについて簡単に説明します。SQLはRDBを操作するためのプログラミング言語です。RDBの操作は次の4つが基本となっており、英語の頭文字を取ってCRUD(クラッド)操作と言われます。
| CRUD | 操作 | SQLコマンド |
|---|---|---|
| CREATE | 作成・保存 | INSERT |
| READ | 取得 | SELECT |
| UPDATE | 更新 | UPDATE |
| DELETE | 削除 | DELETE |
| ここでは詳細は割愛しますが、SQLを適切に使うと、例えば先ほどの社員のテーブルで「年齢が30歳以上で技術所属の社員」のような条件検索も簡単に実行することができます。ちなみに、SQLコマンドには国際標準があり、RDBの種類に依らずある程度の一律性は保たれていますが、完全に同じというわけではないので、各々のRDBで使い分けていく必要があります。 |
NoSQL
先ほどの説明で現在主流となっているデータベースはRDBであると述べました。それでは、RDBを使うことによって、世の中にあるあらゆるアプリケーションが問題なく動作しているのでしょうか?残念ながらRDBは万能なデータベースではありません。実際にはRDBでは対処しづらいアプリケーションもあり、RDBの欠点を補うために使用されるのがNoSQL(Not Only SQL)と呼ばれるタイプのデータベースです。ここではNoSQLの特長を述べていきますが、それをより分かりやすくするために、まずはRDBの問題を少し掘り下げていきたいと思います。
RDBの問題
先ほどRDBの短所の説明で「データの整合性を保つように設計しなければならに」と述べましたが、正確に言えば「データの整合性が保てる」ということ自体はRDBを使う上での大きなメリットです。ですが、一方でそのメリットを担保するために犠牲にしなければならない性能があり、それらがRDBの問題ということになります。
1.分散性が低い
サーバーへの負荷軽減やサーバーの障害への対応という観点からすると、データベースサーバーは分散して設置されている方が望ましいです。しかしながら、仮にデータベースサーバーを分散させた場合、例えば複数のサーバーで同時にデータ更新などが発生すると、データの整合性が保てなくなってしまいます。このような理由から(少なくともデータの書き込みについては)データベースサーバーの分散は困難と言えます。
2.拡張性が低い
扱うデータ量が増えてくれば、当然ながらサーバーを拡張していく必要があります。しかしながら、「分散」と同様の理由で(少なくともデータの書き込みについては)データベースサーバーの拡張は難しいのが現状です。
3.処理速度が遅い
RDBではデータの整合性を保つために内部でいろいろな処理を行っているため、短時間で大量のデータを扱う際には速度不足に陥ることがあります。
4.スキーマの変更が難しい
まず、スキーマとはデータの構造のことです。RDBではテーブルを用いることでデータ構造が分かりやすくなりましたが、裏を返すとテーブルのスキーマに当てはまらないデータは入力できないということです。もちろん、スキーマの変更が絶対無理というわけではありませんが、後から変更するには手間がかかります。また、場合によっては入力されてくるデータ構造が一定でないこともあるので、そのようなアプリケーションでRDBを用いることは困難であるといえます。
補足
データの整合性を保つための処理として「トランザクション」と「バリデーション」を紹介します。トランザクションは複数のテーブルのデータ更新が矛盾なく行われることを担保する機能です。データの更新によって、複数のテーブルの書き換えが必要になった場合に、一部のテーブルの書き換えのみで処理が終わってしまうと不整合になるので、トランザクション処理を行うことによってそのような状況を防止します。万が一、トランザクション処理中に何かしらの不具合が発生した場合にはトランザクション処理の前までデータベースの状態を戻すこと(ロールバック)ができます。もう一方のバリデーションはデータベースに書き込むデータに条件を課すことです。分かりやすい例で言うと、「パスワードは◯◯文字以上」というのもバリデーションの1つです。こうすることによって、データベースに想定外のおかしなデータが書き込まれることを防ぎます。
NoSQLの特徴
一言でいうと、上記のRDBの問題点を補う機能を持っているのがNoSQLです。従って、「分散性と拡張性が高く、スキーマ不定のデータにも対応できて、処理速度が速い」というのがNoSQLの魅力です。このように言うと、NoSQLの方がRDBより優れているように聞こえてしまうかもしれませんが、そうではありません。NoSQLではRDBの問題を解決する代わりに、RDBの大きなメリットであるデータの整合性を諦めています。従って、RDBとNoSQLはどちらか一方が優れている、または劣っているということではなく、アプリケーションによって適切に使い分けていくのが正しいと言えます。
RDBとNoSQLの使い分け
これまでの説明を踏まえて両者の使い分けを一言で表すと、「処理速度はちょっと遅くてもいいから、データの信頼性(整合性)を確実に守りたい」であればRDB、「データの信頼性(整合性)はあまり重要でないから、とにかく大量のデータを高速に処理したい」であればNoSQLということになります。
一般論だけだと少し分かりづらいかもしれないので、(架空の)具体例を挙げてみます。
1.金融機関の取引管理
この事例であれば、データベースとしてRDBとNoSQLのどちらを使うのが適切でしょうか?金融機関の取引管理ということは利用者間のお金の動きを管理することになります。このように金銭が絡むような場面ではデータの不整合は絶対にあってはいけません。例えば、AさんからBさんに10万円振り込んだ時に、Aさんの口座からは10万円減ったが、Bさんの口座には変化がないとなっては大問題です。従って、ここではデータの整合性を保証できるRDBを使うべきだと言えます。
2.人気ECサイトにおける各ユーザの製品閲覧履歴
この場合はどうでしょうか?まず人気ECサイトの製品閲覧履歴ですから金融機関の取引に比べて扱うデータ量が膨大であることが予想されます。そのためデータ処理は高速である方が望ましいと考えられます。また、製品の閲覧履歴ですから金融機関の取引ほどのデータの整合性は要求されないとも考えられます。従って、この場合はデータベースとしてNoSQLを用いる方がよさそうです。
※上記の例は前提条件等非常に曖昧なので、あくまでイメージ程度の参考に留めておいてもらえると幸いです。
近年は扱うデータ量が増加傾向にあるので、RDBでサーバーの性能を向上させていくという手法が通じないケースも多くなってきました。依然としてRDBが主流であることは事実ですが、NoSQLの重要性も今後さらにあがっていくことが予想されています。
NoSQLの構造
ここまでRDBとの比較でNoSQLの特徴について述べてきましたが、その中身は実際にどのような構造になっているのでしょうか?ここではデータ構造に着目してNoSQLの分類を説明していきます。
1.キーバリュー型
キーバリュー型のNoSQLは名前の通りキーとバリューの組み合わせから成るデータ構造を持っています。具体例を表に示します。キーというのデータのIDの役割を果たし、キーを定めると、それに付随するバリュー(データ)も1つに定まります。表の例で言うと、時刻(キー)が定まると、その時の温度(バリュー)が定まります。
| 時刻(Kye) | 温度(Value) |
|---|---|
| 13:00 | 24℃ |
| 14:00 | 26℃ |
| 15:00 | 23℃ |
見て分かるようにRDBに比べてデータ構造がシンプルなので、処理速度はRDBより高速化することが可能です。具体例ではバリューは単一の値でしたが、リストなどにして複数の値を持たせることも可能です。キーバリュー型のデータベースとしてはRedis, Riakなどがあります。
2.ドキュメント型
ドキュメント型のNoSQLで扱うデータ形式はJSONやXMLです。以下にそれぞれのデータ形式の具体例を示しますが、これらはキーバリュー型に比べて複雑なデータを扱うことができます。しかしながら、RDBと異なり、事前にスキーマを定義しておく必要がないので、柔軟なデータの扱いが可能です。ドキュメント型のデータベースとしてはMongoDB、CouchDBなどがあります。
[
{'ID': '001','Name': 'Tanaka', 'Division': 'Sales'}
{'ID': '002','Name': 'Yoshida', 'Division': 'Engineering'}
]
<?xml version='1.0' encoding='utf-8'>
<root>
<employee>
<employ>
<ID>001</ID>
<Name>Tanaka</Name>
<Division>Sales</Division>
</employ>
<employ>
<ID>002</ID>
<Name>Yoshida</Name>
<Division>Engineering</Division>
</employ>
</employee>
</root>
3.カラム指向型
カラム指向型のNoSQLはRDBと同じくデータ構造は表になっています。RDBと異なるのは、そのデータの取り扱い方です。RDBの説明では詳しく言及しませんでしたが、RDBではデータを行単位で扱います。RDBの説明で用いた表を再度使いますが、RDBでは「社員IDが001のデータ」と検索をかけて、「佐藤、35歳、技術○○課、satoh@example.com」というデータが得られるということです。
| 社員ID | 名前 | 年齢 | 部署 | メールアドレス |
|---|---|---|---|---|
| 001 | 佐藤 | 35 | 技術○○課 | satoh@example.com |
| 002 | 鈴木 | 28 | 技術××課 | suzuki@example.com |
| 003 | 山田 | 30 | 開発○○課 | yamada@example.com |
| 004 | 高橋 | 37 | 開発××課 | takahashi@example.com |
これに対してカラム指向型は、名前が示すように、列単位でデータを扱うことを特徴とします。従って、列単位でまとまった処理を行うことが多い場合にはRDBよりも高速に処理ができて有用であるといえます。カラム指向型のデータベースとしてはCassandra、HBaseなどがあります。
4.グラフ型
グラフ型のNoSQLではデータの構造は以下の図のようになっています。このグラフ構造はノード、エッジ、プロパティによって特徴づけられます。
- ノード・・・頂点を意味し、図中の薄灰色の丸がそれに該当する。ラベル(図中のUser)を付与されていることが多い。
- エッジ・・・辺を意味し、図中の矢印がそれに該当する。ノード間の関係性を表すのに用いられる。
- プロパティ・・・ノードやエッジの属性を表す役割を持つ。図ではFollow, Name, Ageなどが該当。

グラフ型データベースの最大の特徴は個々のデータの関係性が明示的に埋め込まれていることです。RDBではデータの管理が複数に渡ることが多く、テーブル間の関連性は規定できますが、テーブルを飛び越えて個々のデータの関連性を直接規定することはできません。そのため、グラフ型データベースはデータの検索がRDBに比べて高速であるというメリットを持っています。具体例の図からも分かるように、SNSのユーザのつながりを表す場合になどに用いると有効です。グラフ型データベースとしてはNeo4jなどがあります。
実際にデータベースはどうやって操作するのか?
ここまで各々のデータベースの特徴や構造について説明してきました。これらもとても重要なことですが、私たちがアプリ開発などを行うには、データベースにデータを保存する、データベースからデータを読み込むなどの操作ができなければ話は始まりません。ここではデータベースのデータをいかに操作するのかについて説明をしていきたいと思います。
1.ORM
先ほど「RDBのデータはSQLという言語を使って操作する」と述べました。確かにこれは間違いではありません。例えば、社員(Employee)テーブルに「年齢25歳、技術xx課所属、メールアドレスyoshida@example.com、社員ID005の吉田」という社員を追加する場合には以下のようにSQLを書けば追加することができます。
INSERT INTO Employee (ID, name, age, division, mail) VALUES ("005", "yoshida", 25, "技術xx課", "yoshida@example.com");
しかし、実際にアプリ開発などを行う場面を考えると、これでは不都合があることが分かります。SQLはあくまでRDBのデータを操作するための言語であって、私たちがアプリを開発する(ログイン機能を実装するなど)際に使う言語ではありません。Webアプリ開発であれば、例えばphp及びフレームワークのLaravelなどを使うため、データベースとのやりとりをする時だけSQLという言語を持ち出してくるのは不便で手間がかかります。そこで、**「SQL言語を明示的に使うことなくデータベースの操作を可能にする機能」**がORMです。
ORMはObject Relational Mapperの略です。RelationalはRelational Database、つまりRDBのことです。Objectはオブジェクト指向のオブジェクトのことで、Mapperは「関連付け」のような意味で捉えるのがよいでしょう。オブジェクトを持ち出すと何が嬉しいかというと、例えばphpのようなオブジェクト指向の言語であればオブジェクトをそのまま扱うことができるので、データベースの操作に改めてSQLを持ち出す必要がないということです。例えば、php/Laravelの場合であれば、先ほどSQLで示したデータの追加は以下のようになります。
$employee = new Employee
$employee->ID="005"
$employee->name="yoshida"
$employee->age=25
$employee->devision="技術xx課"
$employee->mail="yoshida@example.com"
$employee->save()
$employeeというインスタンスを生成する、ID, nameなどのプロパティに値を入れる、saveというメソッドで保存するなど、データベースに関する操作をしつつも、結果的にやっていることは通常のオブジェクトの扱いと変わりありません。
補足
誤解を招かないように補足しますが、ORMはSQLを使っていないわけではありません。SQLはEmployeeの親クラスのModelに書かれており、データベースの操作は根本的にはSQLで行なっています。
2.ODM
ODMはObject Document Mapperの略です。ORMのRelationalがDocumentに変わりました。つまり、ODMが対象とするのはRDBではなく、ドキュメント型のNoSQLということになります。ただし、ODMもオブジェクトを介してデータベースを操作するという点では同じです。
ここで着目したいのはORM, ODMを使えば、データベースがRDBであれNoSQLであれ、開発者はオブジェクトだけを扱って入ればよいということです。すなわち、ORM, ODMは異なる種類のデータベースを違いをあまり意識することなく混在させられるというメリットも生み出します。
以上、データベースの基礎的な内容についてまとめてみました。内容の誤り等がありましたらご指摘をいただければ幸いです。