Apache Kafka(以下、Kafka)を仕事で使うことになりそうなので、自分へのメモも兼ねてさわりをまとめてみます。
Kafkaとは?
Kafkaは分散メッセージングシステムと呼ばれ、一言で表せば、メッセージ(データ)の送り手と受け手の仲介をするシステムです。「ビッグデータ」や「IOT」がトレンドとなっていく中で、Kafkaは2011年にLinkedInからリリースされました。現在はOSSとして開発され、開発コミュニティには米国のConfluent, LinkedIn, Uber, 中国のAlibabaなどが名を連ねています。リリース当初はバージョン0.7.0でしたが、2020年5月現在では2.5が最新バージョンです。
メッセージングシステムとは?
記述が重複しますが、メッセージングシステムは意味が広く、「送り手からデータを一旦受け取り、受け手に対して適切なタイミングでデータを送るシステム」を指します。例えば、Webサイトのログ収集であれば、複数のWebサーバーからログを中継サーバーに送り、中継サーバーがバッチ処理でデータベースなどにログを送るといった構成が考えられ、これもメッセージングシステムということができます。これだけの説明だと、まだぼんやりしてしまうので、pub/subメッセージングモデルを例にして、図を使いながら説明を加えていきます。
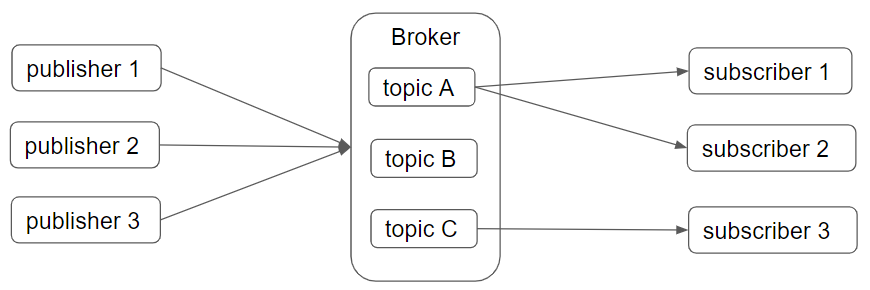
pub/subメッセージングモデルではpublisher(送り手)がbrokerにメッセージを送り、subscriber(受け手)はbrokerからメッセージを受け取ります。publisherがsubscriberに直接メッセージを送るのではなく、常にbrokerを間に挟みます。publisherから送られたメッセージはbroker内のtopicに格納されていきます。topicは複数あり、メッセージの内容に応じて、どのtopicに格納されるべきかをpublisherから指定します。一方で、各subscriberは特定のtopicからのみ選択的にメッセージを受け取ります。このような仕様になっている理由は私たちの日常生活を考えてみても分かります。世の中のサービス・製品は(ある程度ターゲットは決まっているものの)基本的には誰でも利用できるような形で作られていますが、ユーザー側は当然ながら全てを利用するわけではなく、自身の興味・関心に基づいて選択をします。pub/subメッセージングモデルもこれと同様です。
なぜbrokerが仲介をするのか?
publisherからsubscriberにデータを送るのが目的であれば、一見するとbrokerは不要に見えますが、brokerの存在は以下の2つの観点から非常に重要です。
1.publisher/subscriberはbrokerとだけ通信すればよい
仮にbrokerが無かったとすると、publisherは個々のsubscriber全てを把握していなければなりません。逆に、subscriberはデータを送ってくる個々のsubscriberを全て把握していなければなりません。brokerがあるおかで、publisherはsubscriberを意識せずとにかくbrokerにメッセージを送ればよい、subscriberはpublisherを意識せずとにかくbrokerからメッセージを受け取ればよい、となるわけです。
2.メッセージングモデルの変更が容易
前述のメリットと一部重複しますが、brokerだけとの通信を考えればよいということは、例えばpublisher/subscriberの追加や削除を行いやすいということです。brokerがなければ、追加・削除を行う際に全てのpublisher/subscriberを考慮せねばならず、作業の難易度が上がってしまいます。
Kafkaの特長
ここからはKafkaについても説明です。まずは、Kafkaの具体的な構造について述べる前に、全体像を掴めるようKafkaの特長について述べていきます。
1.大量のデータを高速に処理できる
最初に「IOT」や「ビッグデータ」などのトレンドの中でKafkaが開発されたと述べましたが、このような背景を考えれば、大量のデータを高速で処理できることはとても重要です。詳細は後述しますが、Kafkaはpub/subメッセージングモデルと若干異なる構成を取ることやbroker複数台構成を前提としていることからスケールアウトをしやすいものになっています。スケールアウトのしやすさは処理の高速性の向上に直結します。
2.自由なタイミングでのデータ利用が可能
前述の「高速に」というのはリアルタイム処理を指しますが、必ずしもリアルタイム処理ばかりではありません。Kafkaに接続されるconsumer(pub/subメッセージングモデルのsubscriberに該当)は様々で、バッチ処理を行う場合もあります。また、データもすぐに使用するとは限らず、broker内で長期にわたって保存が必要となるケースがありますが、Kafkaではデータをメモリ上だけでなくディスクへ書き込むことで永続的な保存を可能にしています。こうすることによって、データを自由なタイミングで利用することができます。
3.高速性を保ったうえでのデータの送達保証が可能である
データの送達保証というと、1件1件のデータに対するトランザクション処理が分かりやすいかと思いますが、これを実行しながら高速にデータを処理することは非常に難易度が高いです。一方で、当然ながら途中でデータが失われるのも避けるべき事態です。最も厳密なデータ送達保証は「1件のデータを確実に1回ずつ送る」(Exactly at once)ですが、Kafkaでは「(重複してもいいから)少なくとも1回は確実にデータを送る」(At least once)を実現することで、高速性とデータ送達保証のバランスをとっています。
4.データを送受信するためのAPIが充実している
Kafkaに接続されるproducer/consumer(producerはpub/subメッセージングモデルのpublisherに該当)は単一のものではなく、異なるシステムに属している場合も多々あります。このような場合にはpublisher/subscriberとkafkaの間を取り持つ接続用APIが重要になってきます。接続APIの役割を果たすものとして「Kafka Connect」(及びKafka Connect接続するConnectorプラグイン)が提供されています。APIをユーザー側で開発するのは非常に手間がかかるので、豊富なAPIが提供されていることは開発効率の向上に役立ちます。
Kafkaの構成
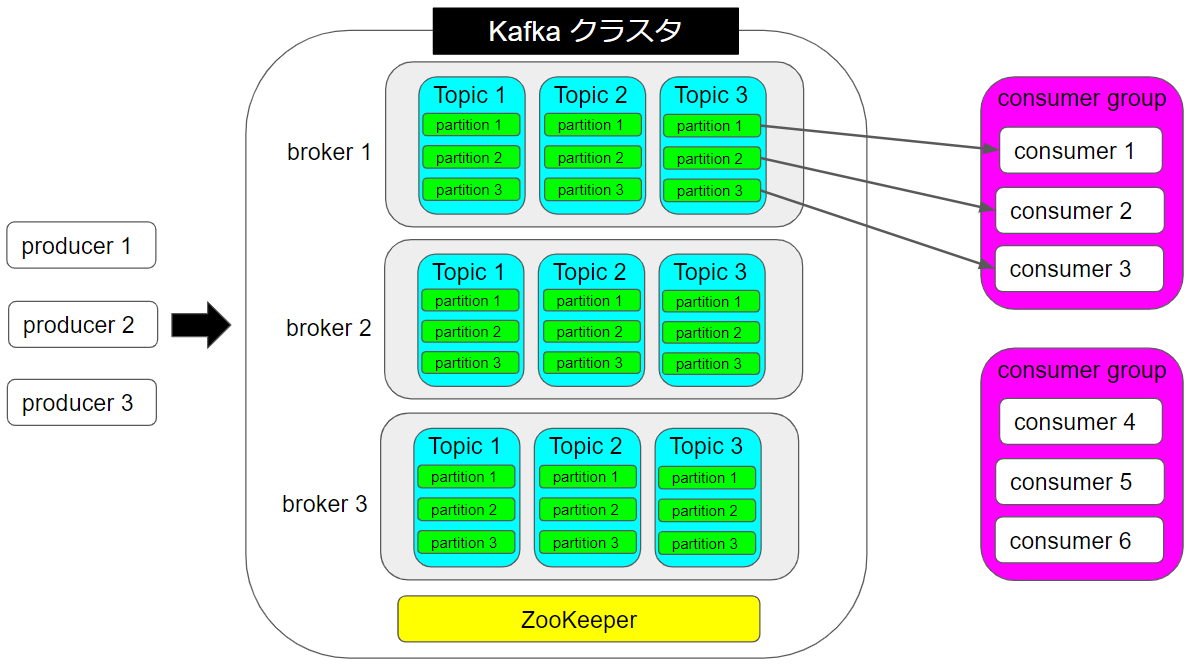
ここまででKafkaの大枠の特長を述べたので、ここからKafkaの具体的な構成について見ていきます。Kafkaの構成は以下のような図で表すことができます。図中の用語について順次説明をしていきます。
message
図には登場しませんが、個々のデータのことをmessageと言います。messageはkeyとvalueから構成されます。
producer
pub/subメッセージングモデルのpublisherに該当し、brokerへのmessageの送信を行います。実際にKafkaと連携するにはAPIを利用して通信用のアプリケーションを作る、またはproducer機能を持つossを使う必要があります。
consumer
pub/subメッセージングモデルのsubscriberに該当し、brokerからmessageの受信をします。Kafkaの送信リクエストはPULL型なので、consumerからbrokerに対してリクエストを送ることでbrokerからmessageが届きます。特長にも書きましたが、Kafkaではデータをディスクに書き込んで永続的に保存しているため、consumerは任意のタイミングでリクエストを送ることが可能です。producerと同様に、Kafkaと連携するためにはAPIを利用して通信用のアプリケーションを作る、またはconsumer機能を持つossを使う必要があります。
broker
producer/consumerからのリクエストに応じてmessageの受信/送信を行います。高速処理を可能にするために、図にあるように複数台の構成を取ることが一般的です。受信したmessageをディスクへ書き込む作業も行います。
topic
broker内のmessageの保管領域を意味し、同分類のmessageは同じtopicに保存される仕組みです。各producerは特定のtopicに対してmessageを送信し、各consumerは特定のtopicからmessageを受信します。
partition
図に示したようにtopicの中に収められたmessageはさらにpartitionと呼ばれる単位に分割されていきます。これは後程説明するconsumer groupとの関連で重要になります。messageがどのpartitionに収められるかは送信時にmessageのkeyから指定することができます。
consumer group
consumer側では複数のconsumerが組み合わさってconsumer groupを形成します。同じconsumer groupに属するconsumerは同じtopicからmessageを受信します。一方、送信元のpartitionはconsumerごとに異なります。このようにすることで、Kafkaではmessageの分散処理を可能にしています。ここが前述のpub/subメッセージングモデルとの違いで、pub/subメッセージングモデルでは「各subscriberは特定のtopicからメッセージを受信する」となっていたものの、特定のtopicからメッセージを受け取るsubscriberはどれも同じメッセージを受け取っていました。
zookeeper
topic, partitionなどmessageの分散処理に関わる情報を保存・管理するためのツールです。図では1つしかありませんが、複数利用する場合が一般的です。
Kafkaクラスタ
zookeeperとbrokerから成るmessageの中継システムをKafkaクラスタと呼びます。
最後に
記事が長くなってきましたので、今回はとりあえずここまでとしたいと思います。余力ができたら、Kafkaにおけるmessageの送達保証、Offset、レプリケーションなどについても記事を書いてみたいと思います。初学者ですので内容に不備がある可能性もあるため、誤りはご指摘いただけると幸いです。