この記事はLIFULL Advent Calendar 2020 統計・機械学習編の18日目になります(担当の日付を4回ほどずらしてしまい、担当者各位にはご迷惑おかけしました![]() )
)
はじめに
「この商品を購入した人は、他にもこのような商品を購入しています」といったように、ユーザーの履歴から似たような商品をレコメンドする手法を、協調フィルタリングと呼びます。協調フィルタリングは「ユーザーの行動履歴」をキャッシュしてユーザー間もしくはアイテム間の類似度を計算するものですが、評価データの蓄積に乏しい新規のアイテムやユーザーには難しいとされる、いわゆる「cold-start問題」を本質で抱えています。今回はクラスタリングを使った協調フィルタリングで、cold-start問題を改善できるか試してみました。
やったこと
ある新規ユーザーに、商品を一つ見せて評価をもらう→レコメンドアルゴリズムで最も評価の高い別商品一つをオススメする→その商品の評価をもらう→レコメンドアルゴリズムで最も評価の高い別商品を一つオススメする→... という流れを繰り返して、オススメした商品数とその時点での最高評価を調査します。
ここでは二つのレコメンドアルゴリズムを比較実験したいと思います。一つは単純な協調フィルタリング(ここではベースモデルと呼ぶ)、もう一つはクラスタリングを使った協調フィルタリング(ここではクラスタリングモデルと呼ぶ)とします。
ベースモデルは各々のユーザーがアイテムにつけた評価値行列を元におすすめ値を返します。
| Item1 | Item2 | ... | Item_m | |
|---|---|---|---|---|
| User1 | $r_{11}$ | $r_{12}$ | ... | $r_{1m}$ |
| User2 | $r_{21}$ | $r_{22}$ | ... | $r_{2m}$ |
| User3 | $r_{31}$ | $r_{32}$ | ... | $r_{3m}$ |
| ... | ... | ... | ... | ... |
| User_n | $r_{n1}$ | $r_{n2}$ | ... | $r_{nm}$ |
ターゲットユーザーuのターゲットアイテムaに対する予測評価値は
$$r_{ua} = \frac{\sum_{i \in Ir} Sim(i, a) (r_{ui} -\bar{r}_{u})} {\sum Sim(i,a)}
\tag{1}$$
$\bar{r}_{u}$ はターゲットユーザーuがアイテムにつけた評価値の平均、$Sim(i,a)$ はアイテムiとaの類似度(ここではcos類似度を使用)、 $Ir$はターゲットユーザーが評価したアイテム群です。ターゲットユーザーの評価したアイテム数が多いほど(1)で参照できる類似アイテムで加重平均が取れるため、予測評価値の精度が向上するという仕組みです。
クラスタリングモデルは上記(1)式について、クラスタリングによる補正項を加えます。クラスタリングの手法は、ユーザーとアイテムごとにk-means法を用いてクラスタリングし、(1)式に補正項を追加します:
$$\hat{r} {ua} = r_{ua} + \frac{\sum_{t \in Cu, i \in Ca } (r_{ti} -\bar{r}_{t})} {|C{a}|}
\tag{2}$$
ここで、$Cu,Ca$はそれぞれターゲットユーザーu、ターゲットアイテムaが属しているユーザークラスタ、アイテムクラスタであり、$|Ca|$はユーザークラスタ内のユーザー総数です。(2)式が表しているのは、「ターゲットユーザーが評価づけたアイテムだけでは足りないから、それと似た人のユーザー、アイテムに対する評価値も含めてしまおう」という考えです。
100人のターゲットユーザーが全くの新規で評価づけ始める段階において、評価アイテム数とユーザーの最高評価値の平均について、検証しました。クラスタ数は任意ですが、今回は20としています。
データ
MovieLenzのml-100k.zipを展開して使用します。主にu.data(fullなdata)を使います。
コード
import numpy
import pandas
import random
from matplotlib import pyplot as plt
from scipy.spatial import distance
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.cluster import KMeans
class BaseModel:
def __init__(self):
self.name = "BaseModel"
self.master_data = None
self.similarities = None
def train(self, train_data):
train_data.fillna(0, inplace=True)
self.master_data = train_data
sims = cosine_similarity(train_data.transpose())
item_ids = train_data.columns
self.similarities = {
item_id: sim for item_id, sim in zip(
item_ids, sims)}
return self
def recommend(self, target_user_history):
if self.similarities is None:
return "BaseModel not trained."
if not target_user_history:
random_id = random.choice(self.master_data.columns)
return random_id
score_averaged = numpy.array(
[score for _, score in target_user_history]).mean()
scored_ids = []
tmp_df = pandas.DataFrame(columns=self.master_data.columns)
for scored_item_id, score in target_user_history:
tmp_df[scored_item_id] = [score]
scored_ids.append(scored_item_id)
scores = tmp_df.fillna(0).values
pred_scores = {}
for item_id in self.master_data.columns:
if item_id not in scored_ids:
pred_scores[item_id] = (
self.similarities[item_id] * scores).sum() / self.similarities[item_id].sum()
recommend_item_id = max(pred_scores, key=pred_scores.get)
return recommend_item_id
class ClusteringModel:
def __init__(self):
self.name = "ClusteringModel"
self.master_data = None
self.similarities = None
self.item_cluster_centers = None
self.user_cluster_centers = None
self.kmeans_model = KMeans(
n_clusters=n_clusters,
init="k-means++")
def train(self, train_data):
train_data.fillna(0, inplace=True)
self.master_data = train_data
sims = cosine_similarity(train_data.transpose())
item_ids = train_data.columns
self.similarities = {
item_id: sim for item_id, sim in zip(
item_ids, sims)}
self.kmeans_model.fit(train_data)
self.user_cluster_centers = self.kmeans_model.cluster_centers_
self.master_data["label"] = self.kmeans_model.labels_
self.kmeans_model.fit(train_data.transpose())
self.item_cluster_centers = self.kmeans_model.cluster_centers_
self.master_data.loc["label"] = self.kmeans_model.labels_ + [100]
return self
def recommend(self, target_user_history):
if self.similarities is None and self.cluster_ids is None:
return "ClusteringModel not trained."
if not target_user_history:
random_id = random.choice(self.master_data.columns)
return random_id
score_averaged = numpy.array(
[score for _, score in target_user_history]).mean()
scored_ids = []
tmp_df = pandas.DataFrame(columns=self.master_data.columns)
for scored_item_id, score in target_user_history:
tmp_df[scored_item_id] = [score]
scored_ids.append(scored_item_id)
scores = tmp_df.fillna(0).values
for center in self.user_cluster_centers:
d = self._distance(tmp_df.fillna(0), center)
distance_list.append(pandas.Series(d))
df_distances = pandas.concat(distance_list, axis=1)
user_cluster_id = df_distances.idxmin(axis=1)
same_user_data = self.master_data[self.master_data["label"]
== user_cluster_id]
pred_scores = {}
for item_id in self.master_data.columns:
if item_id not in scored_ids:
pred_scores[item_id] = (
(self.similarities[item_id] *
(scores - score_averaged)).sum() /
self.similarities[item_id].sum()) + (
((same_user_data - same_user_data.mean()).sum())
/ len(same_user_data)
)
recommend_item_id = max(pred_scores, key=pred_scores.get)
return recommend_item_id
def _distance(self, df, centers):
def _d(x):
return distance.euclidean(x.values, centers)
dist = df.apply(_d, axis=1)
return dist.values
def main():
data = numpy.loadtxt("bukken_search/data/u.data",
delimiter="\t",
usecols=(0, 1, 2),
skiprows=1)
user_ids = list(set([row[0] for row in data]))
movie_ids = list(set([row[1] for row in data]))
df = pandas.DataFrame(index=user_ids, columns=movie_ids)
for row in data:
df[row[1]].loc[row[0]] = row[2]
train_data = df.loc[101:]
test_data = df.loc[:100]
models = [BaseModel(), ClusteringModel()]
for model in models:
model.train(train_data)
history_list = []
history = []
for _, row in test_data.iterrows():
itr = 0
while itr < 20:
id_ = model.recommend(history)
history.append((id_, row[id_]))
if not numpy.isnan(row[id_]):
itr += 1
history_list.append(history)
plot_figures(history_list, model.name)
def plot_figures(history_list, model_name):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
x = numpy.linspace(0, 100, recommend_iteration)
user_scores = []
for history in log_list:
scores_tmp = [score for _, score in history]
scores = []
for i, _ in enumerate(scores_tmp):
scores.append(max(scores_tmp[0:i + 1]))
user_scores.append(scores)
y = numpy.array(user_scores).mean(axis=0)
ax.plot(x, y, linestyle='solid', linewidth=3.0)
ax.set_xlabel('n_iteration')
ax.set_ylabel('score')
ax.set_xlim(0, 100)
ax.set_ylim(0, 1)
ax.legend()
ax.grid(True)
fig.savefig("{}.png".format(model_name))
if __name__ == "__main__":
main()
結果
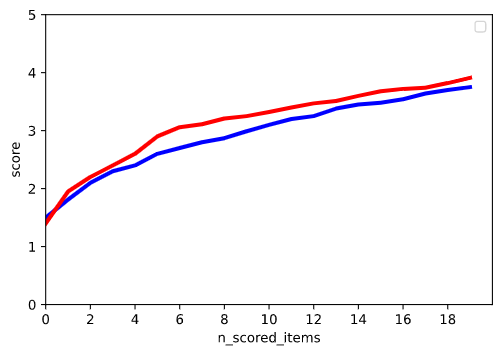
青: ベースモデル、赤: クラスタリングモデル
最初のスコア上昇率はクラスタリングモデルの方が大きくみられ、cold-startの改善の余地が見られたと思います。あとはクラスタリングの精度、クラスタ数などを調整するなどが次の改善作業かなと思います。
*コードバグが見つかったので修正するまで一旦限定公開にしておきます。
参考
https://www.ai-gakkai.or.jp/jsai2012/webprogram/2012/pdf/244.pdf
こちらの手法を参考にさせていただきました。