

深層学習を勉強してみたいと思った
動機は2つあって、単純に深層学習流行ってるからやってみたかった、というのと、今後グラフィックス技術を扱っていく際に深層学習は欠かせないものになりそうだと考えた、というのがありました。
例えば、最近 NVIDIA は深層学習を応用したノイズ軽減技術によってモンテカルロ系レンダラーのレンダリング時間を大幅に削減できるとしています。また、Turing 世代の GPU では深層学習を応用した超解像技術によって高解像度動作時のパフォーマンスを大幅に改善できるとしています。ただ僕には、これらの技術がどれほど効果的なものなのか、また本当に実用的なものなのか、判断することができませんでした。
このような深層学習技術の応用は今後様々な場面で進められていくことと思われますが、そういった技術を評価していくにあたって深層学習の基礎知識を備えておくことが必要になると感じています。
勉強にあたっての戦略
同じように深層学習を勉強してみたいと考えている人は少なくないと思いますが、どのように手をつけたらいいのか分からないまま終わってしまっている人も多いのではないでしょうか。僕自身も、いまいちとっかかりを掴めないままでいる期間が長くありました。
こういう最初の一歩が踏み出せない状況から先へ進むために使う戦略があります。
- 何か low-hanging fruit を探して、それを掴むことを当面の目標として進んでみる。
Low-hanging fruit というのは文字通り低い場所に生っている果実のことで、容易に達成でき、かつ見返りの大きい目標のことを表します。いきなり難しい目標を設定したり、教科書の端から端まで学習しようというのではなく、比較的簡単に達成できそうで、なおかつそれなりの経験が得られそうな目標を設定し、そこまでに必要となる知識だけを掻い摘んで学んでいこう、という戦略です。
僕の場合の low-hanging fruit に当たるのが pix2pix でした。
pix2pix による画像変換
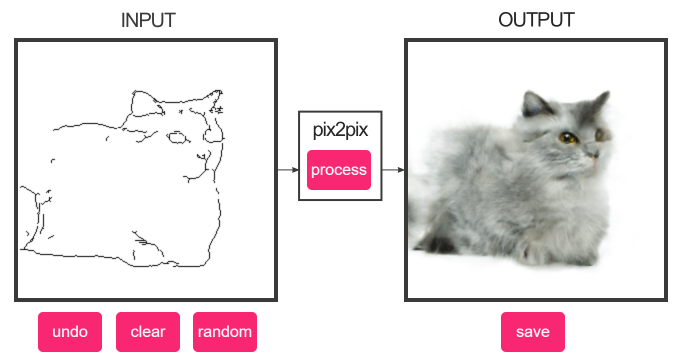
pix2pix は GAN(敵対的生成ネットワーク)を応用した画像変換手法のひとつで、与えられた絵を別の絵に変換するネットワークを構築するというものです。線画の猫をリアルな猫の画像に変換するデモがバズって有名になったので、GAN に興味が無くても見たことのある人は多いと思います。
この pix2pix を応用した実験を Mario Klingemann 氏が行っていて、これに強く興味を引かれました。
Facefeedback II pic.twitter.com/XuFlNWGJ7r
— Mario Klingemann (@quasimondo) November 10, 2017
特に興味深かったのは、この pix2pix を動画の生成に応用するという実験です。連続する2つのフレーム、つまり第 N フレームと 第 N+1 フレームの画像をペアとして pix2pix に学習させることで、任意の画像から次のフレームを予測するモデルが構築できるのではないか……というものです。
I'm training a next-frame-prediction #pix2pix model on some fireworks footage. pic.twitter.com/o0vd7njAai
— Mario Klingemann (@quasimondo) January 2, 2018
pix2pix は動画を扱うようには設計されていないため、フレーム予測モデルとしてはだいぶ不完全です。ただ、その不完全さが生み出す歪みの中に、幾何学的な映像エフェクトとは異なる独特の有機的な味わいがあると感じました。
Mario 氏のツイートを見ると、pix2pix をインタラクティブなフレームレートで動かすことができている、というような情報もありました。これらの情報から、もしかしたら深層学習をリアルタイムな映像表現に使うことができるのかもしれない……という希望が見えてきました。
幸いなことに pix2pix については様々な資料や学習済みモデルが公開されています。これはまさに自分にとっての low-hanging fruits なのではないかと考えるようになりました。
闇雲に実装してみる
pix2pix は、有名な「線画→猫」のデモに使用された学習済みモデルが公開されています(ただし重みデータのみ)。まずは単純にこれを Unity へ移植してみる、というのを当面の目標として設定しました。これには、推論部分の実装を勉強するという目的と同時に、一般的な深層学習用のフレームワーク(TensorFlow 等)を使わず独自設計でチューニングを行った際に、どの程度まで高速化が実現できるか検証する、という目的もありました。
まずは、深層学習について何も分かっていない状況から、闇雲にデモのソースコードを読んで C# で実装し直すということをやってみました。いわゆる写経みたいなものです。件の「線画→猫」のデモは TensorFlow.js という TensorFlow のサブセットのようなもので実装されており、そのコンパクトなソースコードを読解していくことはさほど苦になりませんでした。
My edges2cat implementation seems to work, but actually I'm not sure if this is a correct result. https://t.co/A6rT9mfLAI pic.twitter.com/nmsMBt6hK8
— Keijiro Takahashi (@_kzr) August 13, 2018
こんな感じで徐々に猫が出てくるようになりました。この C# 単純実装では 256x256 の生成で約4分ぐらいかかっています。とてもリアルタイムとは言えません。
とは言え、この時点で既に僕は楽観的な気分になっていました。推論側の実装は非常に単純である――とどのつまり巨大なテンソルの畳み込みを何回も繰り返し行っているに過ぎない、ということが把握できたからです。これなら簡単に GPU compute で高速化できるでしょう。
本を読んでみる
写経によって実践的な経験を得たのちに、改めて書籍を使った勉強を始めることにします。
実践してから本を読む、というのは順序が逆なような気もしますが、個人的にはよく使うアプローチです。最初にいきなり書籍や文献を読み込んでも、そこに記されていることの価値や重要性を理解することができず、学習が散漫になりがちです。そこで逆に、まず無理やり実践を行ってみて、その過程と結果を経験として得てから、その裏にある仕組みについて、書籍にある知識を使って解き明かしていく、という道筋を辿っていきます。
書籍は何冊か読んでみましたが、個人的な目標と合致していて最も参考になったのが次の書籍でした。

PythonとKerasによるディープラーニング、Francois Chollet 著、巣籠悠輔 監訳
AI や深層学習について現実的な視点を提示しつつ、Keras 開発者としての含蓄のある語り口が内容に説得力を与えており、読み進めることに安心感がありました。
これまでのところ、ディープラーニングにおいて本当に成功していると言えるのは、「連続的な幾何学変換を用いて空間Xを空間Yへ写像する能力」だけであることを覚えておいてください。
内容は簡潔でありながら、簡潔過ぎて不足するというようなことがなく(他の入門書籍では「これはさすがに端折り過ぎだなあ」と感じることが度々ありました)、適度な読み応えがあるのも良かったです。
いわゆる教師あり学習と一部の教師なし学習に絞って解説を行っているため、強化学習などに興味がある人にとっては物足りない内容かもしれません。逆に僕は強化学習にはそれほど興味がなかったので、この書籍の内容はうまく合いました。
GPU で高速化する
次は pix2pix の GPU 高速化に着手します。まずは C# の実装を単純に compute 化してみます。これだけで数十倍の高速化が実現できました。さすがは GPU、どうりで深層学習が流行るはずです。
I converted the Pix2Pix C# implementation to GPU compute.
— Keijiro Takahashi (@_kzr) August 23, 2018
Naïve C#: 4 min and 42 sec
Naïve GPU: less than 3 sec
There is still much room for optimization. Getting exciting. pic.twitter.com/BT1UCEI6k1
ここから PIX を使ったプロファイリングを挟みつつチクチクと高速化を施していきます。
It's a bit hard to optimize the transposed convolution kernel. Now it runs at 20 fps on my GTX 1070. I think still there is room for optimization. https://t.co/A6rT9mfLAI pic.twitter.com/F1djMV96ab
— Keijiro Takahashi (@_kzr) August 26, 2018
基本的な高速化手法をいくつか試してみましたが、最も大きな効果を得られたのは memory coalescing を意識したメモリアクセスパターンへの変更です。
簡単に説明すると、NVIDIA 系の GPU ではあるルールに沿ったメモリアクセスを行った場合に、32 スレッド(ないしは 16 スレッド)同時にアクセスが処理されるという仕様があります。メモリアクセスがボトルネックとなっている場合、これを改善するだけで劇的な速度向上が見込めます。
畳み込みニューラルネットワークなどは単なる積和演算の塊なので、まさにこの点が最大の高速化要点となります。スレッドグループ共有メモリを転置用のキャッシュとして利用しつつ、すべてのメモリアクセスで coalescing が発動するよう調整を重ねていきます。
結果として、GeForce GTX 1070 で 26 fps ぐらいの性能が出るようになりました。
Still the optimization on Unity pix2pix is in progress. Now it runs at about 26 fps on GTX 1070. I can draw the thing smoothly. https://t.co/A6rT9mfLAI pic.twitter.com/48snJ4dMOx
— Keijiro Takahashi (@_kzr) August 26, 2018
とりあえずこの状態でインタラクティブデモとして機能するよう体裁を整えておきます。簡単な記録映像も残しておくことにしました。
A demonstration of a real-time pix2pix (image-to-image translation with neural network) implementation with Unity https://t.co/A6rT9mfLAI pic.twitter.com/i7X0m1E896
— Keijiro Takahashi (@_kzr) September 1, 2018
これで推論処理をリアルタイムに動かすという目標は達成できました。当初の目標としていた low-hanging fruits は回収完了というわけです。すっかりモチベーションは得られましたので、この勢いを維持して、次は学習側の仕組みについて勉強していくことにします。
モデルを学習してみる
学習側を勉強するに当たってちょっとしたつまづきがありました。学習のための環境をどのように整備するか迷いがあったのです。大きく分けて二つのアプローチが考えられます。
- 強力な GPU 積んだ PC を組んで Linux をインストールする。
- クラウド上の GPU インスタンスを賃借りする。
新しい PC を組むことはやぶさかではありませんが、**PC 組むのが楽しすぎて、環境整備が済んだ瞬間に得られる達成感で終わってしまうのではないか?**という心配がありました。よく分からんという人もいるかもしれませんが、ガジェット購入やクラウドファンディング出資の趣味を持っている人ならなんとなく分かるのではないかと思います。ポチる瞬間が楽しさの最大値で、実際にモノを手にすると面倒くさいなこれ……と感じてしまうアレです。
そこでクラウドを使う方向で AWS などをチマチマと試していたのですが、そのうちに Google が Colaboratory というサービスを実験的に始めているということを知り、そこですべてが変わりました。
結論を言ってしまうと、Colaboratory は他の選択肢をすべて駆逐するほどに優れたものです。ぶっちゃけ、深層学習の勉強をしたいと思ったら Colaboratory 一択、他の選択肢は考えなくていいです。安い(無料)、速い、使いやすい、と、メリットしかありません。 Google Cloud 側にある有料サービスよりずっと使いやすいのだから意味不明ですが、Google ではよくあることでしょう。そのうちにサービス終了してしまうかもしれません(これも Google ではよくあることです)ので、今のうちに使い倒しておくのが吉です。
I made a complete set of Colaboratory Notebooks that can be used to train pix2pix models. You can instantly run them on a GPU instance for free -- no need to build a Linux machine to train them.https://t.co/liipIYIm8g pic.twitter.com/TOzpjvrdFD
— Keijiro Takahashi (@_kzr) September 22, 2018
セットアップ済みの機械学習環境が使い放題な状態となり、勉強の障壁はほぼ無くなりました。ゴリゴリとスクリプトを組んで pix2pix モデルの学習を試していきます。学習用データのスクレイピングやプリプロセスも、すべて Colaboratory と Google Drive の上で行っていきます。
Re-trained the edges-to-dogs model with head photos. It's fun to playing around with. https://t.co/A6rT9mfLAI pic.twitter.com/lkfbnV5bK8
— Keijiro Takahashi (@_kzr) September 27, 2018
edges2irasutoya - a pix2pix model trained with illustrations from https://t.co/rEUbWkhHqE pic.twitter.com/4PEaNqZFiU
— Keijiro Takahashi (@_kzr) September 28, 2018
様々な可能性を試してみましたが、最終的にはやはりフレーム予測モデルを使ったフィードバックアニメーションが VJ 的には面白そうだという結論に辿り着きます。有料・無料含めて様々な動画素材を入手し学習させてみました。
This one also worked well. It seems good at imitating water surface animation. pic.twitter.com/qEdT7LQ3Ht
— Keijiro Takahashi (@_kzr) October 9, 2018
これを最終的に Ngx というソフトウェアパッケージとして体裁を整えて、実際のライブイベントで VJ に使用しました。
Building a VJ system with pix2pix feedback animation (next-frame prediction models). It runs at about 26 fps on GTX 1070. #unity3d https://t.co/77nbIrSlEj pic.twitter.com/u9IQFObgJF
— Keijiro Takahashi (@_kzr) October 10, 2018
機械学習VJ #chane19 pic.twitter.com/keYh7Lj5QV
— chaosgroove (@chaosgroove) October 13, 2018
まとめ
今回、深層学習の勉強を行ったことで様々な知見を得ることができました。特に映像表現への応用については、その可能性と限界について以前よりも具体的な認識を持つことができるようになったと思います(いまだ浅いものではありますが)。GAN を使用した画像生成は新しい新しい表現の可能性を提示してくれますが、そこから生み出される表現の質と幅の間にはトレードオフの関係が存在していると感じました。質を上げようとすればするほど幅は狭まり、元のデータセットの中にある表現の枠内へと収斂してしまうという問題です。
それはさておき、普遍的に共有することのできる重要な知見が一点だけあります。それは Colaboratory はヤバいということです。ここまでに記した勉強の方法や深層学習に対する認識は僕個人に依存するものであり、それを無理に勧めることはありませんが、Colaboratory のヤバさだけは否定しようのない普遍的な事実として伝えられます。
Colaboratory は機械学習を勉強するに当たって生じうる面倒さをすべて解消してくれます。あー機械学習やってみたいなあ……と思った5分後には MNIST 手書き認識とか動かしてははーんとか言うことができます。僕も最初に Colaboratory を知ることができていたら、もうちょっと違う過程を辿ることになっていたかもしれません。
以上