Microsoftのデータサイエンス初心者向けコース(無料)3日目
データ可視化
対象読者
Pythonとデータサイエンスに興味がある人。コードの意味を確認したい人。
データ
今回も引き続き、米国農務省のデータセットから、様々な種類の蜂蜜の関係を示す興味深いビジュアライゼーションを発見してみましょう。
このデータセットには、約600の項目があり、米国州における蜂蜜の生産量が表示されています。そのため、例えば、1998年から2012年にかけて、ある州で生産された蜂蜜の巣の数、1つの巣あたりの収量、総生産量、在庫、ポンドあたりの価格、価値などを、各州ごとに1行ずつ見ることができるのです。
例えば、ある州の年間生産量と、その州の蜂蜜の価格との関係を可視化するのは興味深いですね。また、1つの巣の蜂蜜の収穫量との関係を可視化することもできます。この年のスパンは、2006年に初めて見られた壊滅的な「CCD」または「コロニー崩壊症候群」をカバーしている(http://npic.orst.edu/envir/ccd.html)ので、研究する上で痛烈なデータセットであると言えます。🐝
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
honey = pd.read_csv('https://raw.githubusercontent.com/microsoft/Data-Science-For-Beginners/main/data/honey.csv')
honey.head()
散布図
蜂蜜の 1 ポンドあたりの価格と、その原産地である米国の州との関係を示す基本的な散布図を作成します。すべての州を表示できるように、y 軸を十分に高くします。
sns.relplot(x="priceperlb", y="state", data=honey, height=15, aspect=.5);
ちなみに、セミコロンをつけることで、jupyter notebook(colab)で標準出力を非表示にできます。
セミコロンつけないと、""のような文字列が表示されます。
色に意味をもたせる
今度は、同じデータを蜂蜜色で表示して、価格の推移を年単位で表示してみましょう。これは、「hue」パラメータを追加することで、年ごとの変化を表示することができます。
sns.relplot(x="priceperlb", y="state", hue="year", palette="YlOrBr", data=honey, height=15, aspect=.5);
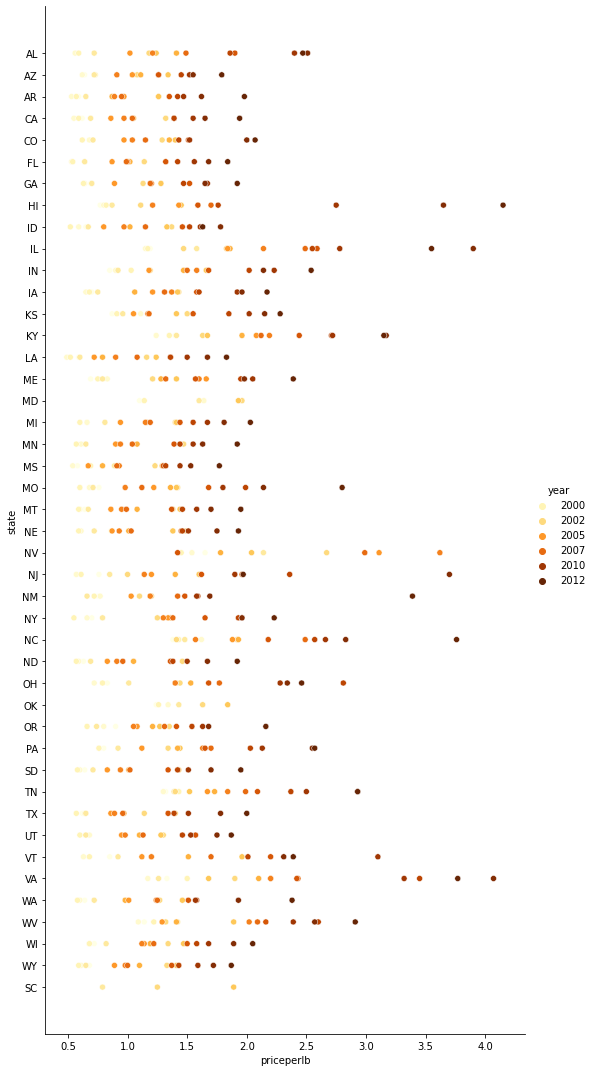
時が経つにつれて、どの州でも1つの巣あたりのはちみつ価格が上がっていっている様子がわかりますね。
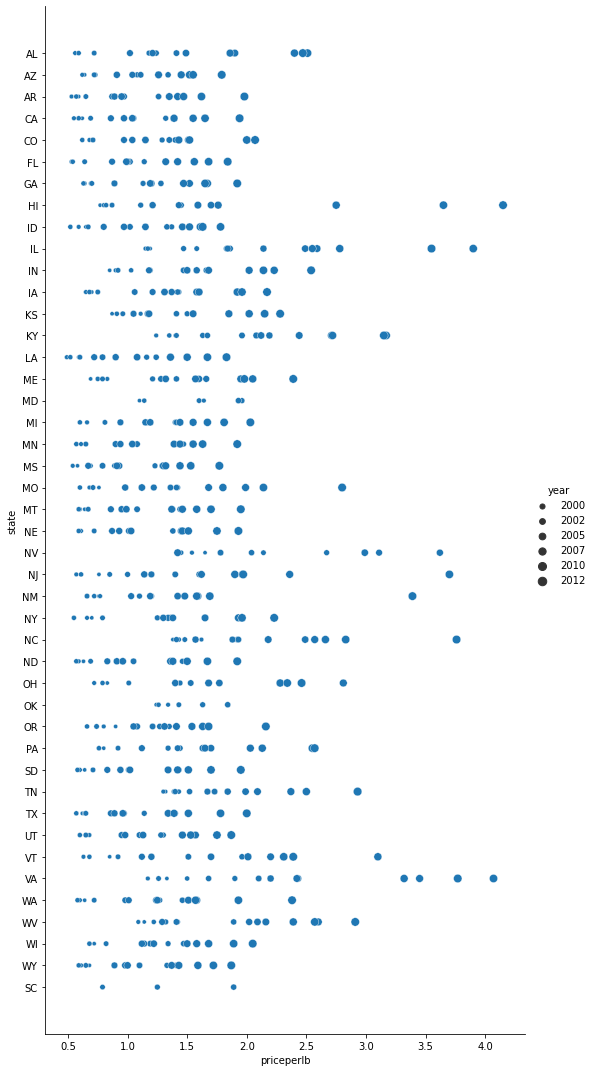
サイズに意味を持たせる
sns.relplot(x="priceperlb", y="state", size="year", data=honey, height=15, aspect=.5);
折れ線グラフ
これは単純に需要と供給の関係なのでしょうか?気候変動やコロニー崩壊などの要因により、年々購入可能な蜂蜜が少なくなり、その結果価格が上昇しているのでしょうか?
このデータセットのいくつかの変数の間の相関関係を発見するために、いくつかの折れ線グラフを調べてみましょう。2003年以外はこれに当てはまるようです。
sns.relplot(x="year", y="priceperlb", kind="line", data=honey);
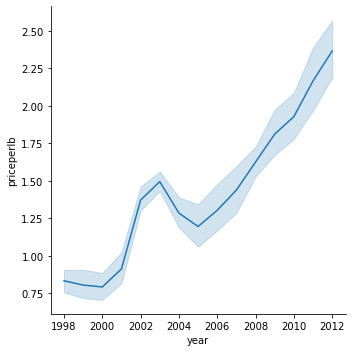
Seabornは1本の線の周りにデータを集約しているので、「各x値における複数の測定値を、平均値と平均値周りの95%信頼区間をプロットして表示」しているのです。 この時間のかかる動作は、ci=Noneを追加することで無効にすることができます。
sns.relplot(x="year", y="priceperlb", kind="line", data=honey, ci=None);
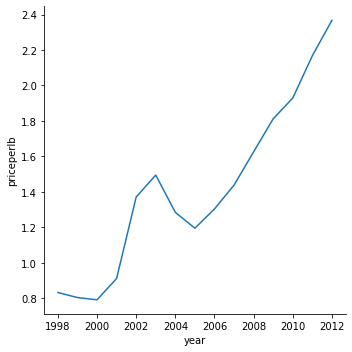
質問です。さて、2003年には、蜂蜜の供給が急増したと見ることもできるでしょうか?総生産量を前年比で見るとどうでしょう?
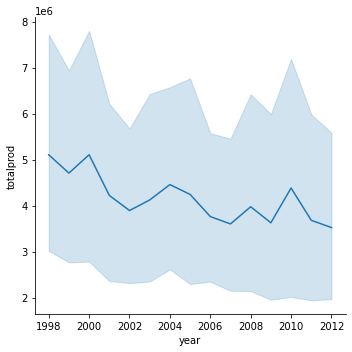
答えはそうでもなさそうです。一般的には、この時期は蜂蜜の生産量が減少していると言われていますが、総生産量を見ると、実はその年だけ増えているようです。
それでは、2003年ごろに蜂蜜の価格が高騰した原因は何だったのでしょうか?
これを発見するために、ファセットグリッドを探索していきます。
ファセットグリッド
ファセットグリッドは、データセットの1つのファセット(この例では、ファセットの数が多くなりすぎないように「年」を選択することができます)を使用します。そして、Seabornはそれらの各ファセットについて、選択したxおよびy座標のプロットを作成し、より簡単に視覚的に比較することができます。このような比較で2003年は際立っているだろうか?
sns.relplot(
data=honey,
x="yieldpercol", y="numcol",
col="year",
col_wrap=3,
kind="line"
);
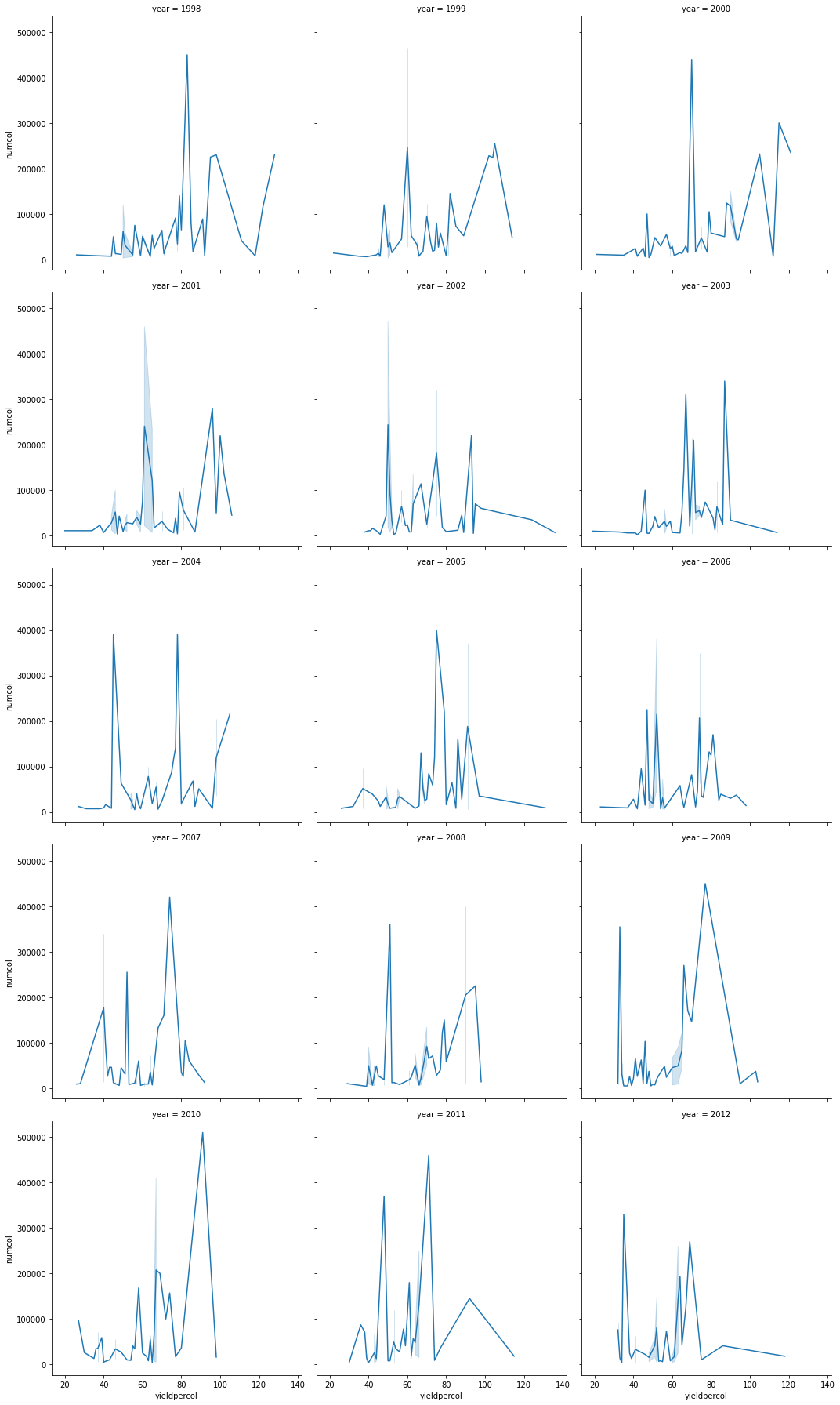
このビジュアライゼーションでは、col_wrapを3に設定した状態で、コロニーあたりの収穫量とコロニー数を前年比で並べて比較することができます。
このデータセットでは、コロニー数とその収穫量に関して、前年比、州別で特に目立つものはない。この2つの変数に相関を見出すには、何か別の方法があるのでしょうか?
Dual Line Plot
Seaborn の 'despine' を使って上と下の棘を取り除き、Matplotlib から派生した ax.twinx を使って、2つの線グラフを重ね合わせて、複数線グラフを試してみてください。Twinx は、グラフが x 軸を共有し、2つの y 軸を表示することを可能にします。つまり、コロニーあたりの収穫量とコロニー数を重ねて表示します。
fig, ax = plt.subplots(figsize=(12,6))
lineplot = sns.lineplot(x=honey['year'], y=honey['numcol'], data=honey,
label = 'Number of bee colonies', legend=False)
sns.despine()
plt.ylabel('# colonies')
plt.title('Honey Production Year over Year');
ax2 = ax.twinx()
lineplot2 = sns.lineplot(x=honey['year'], y=honey['yieldpercol'], ax=ax2, color="r",
label ='Yield per colony', legend=False)
sns.despine(right=False)
plt.ylabel('colony yield')
ax.figure.legend();
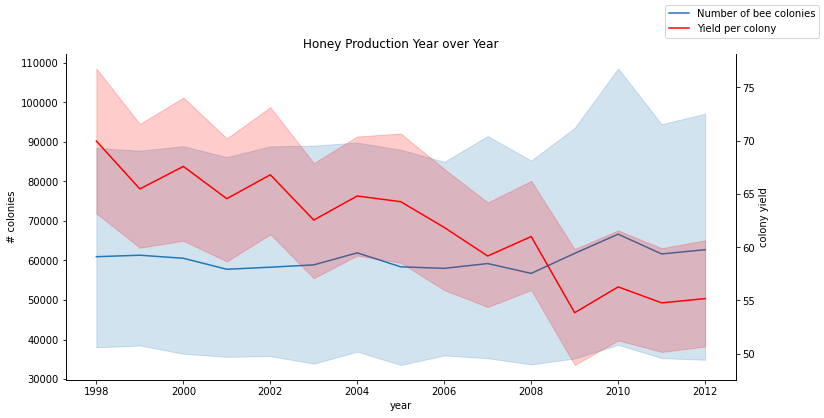
2003年前後は特に目につくことはないが、全体としてコロニー数は減少しているものの、コロニー当たりの収量は減少していてもコロニー数は安定しているということがわかった。よかった大好きなはちみつがまだまだ食べられそう、ということで、少し嬉しい気持ちでこの授業を終えます🍯。