パケット解析してますか?
ネットワークトラフィックを解析している人はlibpcapライブラリを使ったことがある、あるいはlibpcapを直接使うことがなくともtcpdumpなどでキャプチャしたPCAP形式のファイルを扱ったことがあるかと思います。
多くのトラフィック解析ツールがPCAP形式に対応しているため、この形式でデータを保持しておけば、後々様々なツールで利用できるという安心感があります。一般的な解析ならば既存のツールで十分でしょう。
しかし、高度な解析をしようとすると、PCAPデータやそこに含まれるパケットの内部構造などを細かく見ていきたくなります。PCAP形式のデータはパケットが羅列されたバイナリデータとほぼ同じなので、前処理プログラムを用いて必要な部分を取り出したり、加工したりしなければなりません。
最近はネットワークも高速化しており、ほんの数分のキャプチャでも場合によっては数十GBのデータになることすらあります。解析内容にもよりますが、すでに手法が確立されたものでない限り、データをいろいろな側面から様々な手法で繰り返し解析していくことになるでしょう。小さなデータなら問題ありませんが、データ量が増えるにつれ前処理にかかる時間も無視できなくなってきます。
本稿では大きなPCAP形式のファイルを高速に処理するためのソフトウェア「SLICECAP」を紹介します。
分割して処理せよ
大きなデータに取り組む時の常套手段は並列処理です。まず、元のデータを小さなデータに分割し、それぞれの小さなデータを複数のスレッドやプロセス、場合によっては複数のサーバに分散させて並列処理します。
PCAP形式のファイルについても同じように取り組みたいのですが、ここで問題が発生します。
PCAP形式のデータはパケットストリームを記録するためのものなので、パケット単位でのインデックス情報が存在しません。あるPCAPファイルに何個のパケットが含まれているのか、先頭から1000個目のパケットはファイル上で何バイト目から始まるのか、といった情報は、PCAPファイルを先頭から順番に調べていかなければなりません。たくさんのパケットが記録されているPCAPファイルを分割するとき、この処理に大きな負荷がかかります。
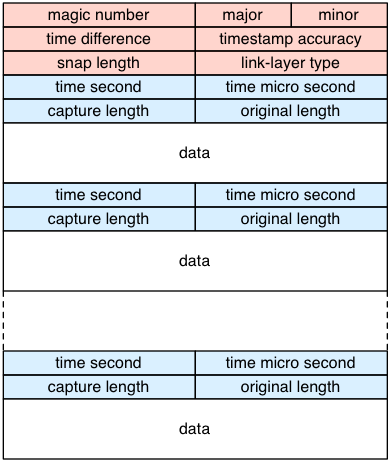
以下にPCAP形式を簡単に示します。赤いヘッダ部はグローバルヘッダと呼ばれ、PCAPデータ全体の情報が収められています。パケットヘッダと呼ばれる青いヘッダ部とその後に続く白いブロックがひとつのパケットを表しており、パケットヘッダ部に個々のパケット特有の情報が収められています。
目的を思いだそう
さて、目的はPCAP形式のファイルを小さなサイズに分割することでした。複数のデータに分割して並列処理できればよいので、必ずしも分割後のデータに含まれるパケットの数が揃っていたりする必要はありません。SLICECAPはユーザが指定した分割数とPCAPファイル全体のサイズから、分割後のデータサイズを計算し、「いい感じに」パケットの区切りを探して分割します。
パケット境界の発見に利用するのは、各パケットヘッダ部に記録されているタイムスタンプ情報です。パケットは連続的に記録されているので、各パケットのタイムスタンプの値も似た値になっていると仮定できます。まず分割のために適当な位置にファイルポインタを移動し、そこから1バイトずつポインタを進めながら、似た値のタイムスタンプが記録されている位置までポインタを進めます。その後、パケットヘッダの他のフィールドが異常な値にならないかを検証し、「それっぽい」と判断すればそこで分割確定です。
分割されたデータは、グローバルヘッダを追加してPCAP形式に再構築され、プロセス間通信の仕組みで子プロセスに渡されます。分割されたPCAPデータが別々のプロセスで処理されるため、コア数に応じて処理性能が向上します。
使ってみよう
例としてPCAPファイルを10個の小さなPCAPファイルに分割する例を示します。
slicecap -r source.pcap -n 10 -- "cat - > dest-{SLICE_ID}.pcap"
実際の解析では、catよりももう少し役に立つフィルタプログラムを指定することになるでしょう。
次に示す図は、並列プロセス数を増やしながらp2cコマンドを用いてヘッダ情報をCSVに変換した時の処理時間を計測したものです。
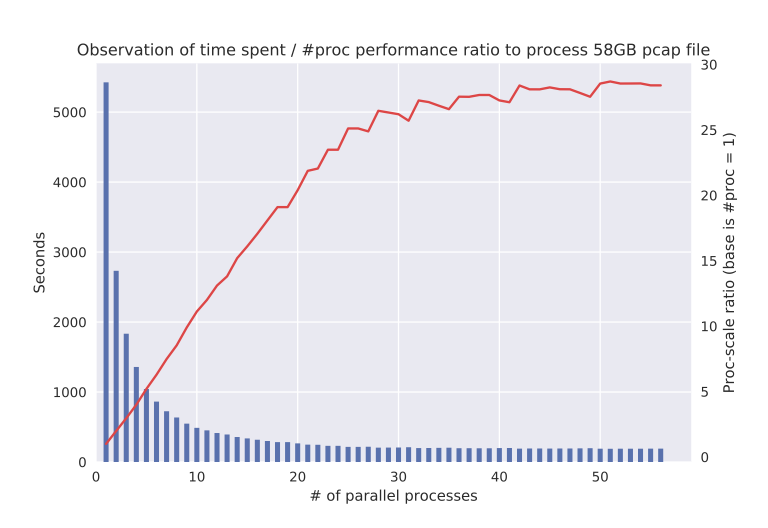
計測に用いたPCにはIntel Xeon E2697 v3 (14 core)が2個と256GBのメモリが搭載されています。58GBのPCAPファイルを解析し、IP/TCP/UDPヘッダを抜き出してCSV形式で出力する処理を実行しました。並列プロセス数を増やしていくごとに処理時間が短縮しているのがわかります。簡単な整数演算のみで完結してしまうためか、ハイパースレッディングの効果はあまり見られませんでした。処理内容によってはもう少し向上する可能性もあるでしょう。
入手先
SLICECAPはPyPiレポジトリに登録されています。pipコマンドでインストールしてください。ソースコードは https://github.com/keiichishima/slicecap/ で公開しています。バグレポ、プルリク歓迎です。