概要
最近、terraformのカスタムプロバイダを書き始めましたので、その中で困った点や悩んだ点を書いていこうと思います。今回はまず概要まで。
(一応)Terraformとは
HashiCorp社の作っているインフラ等の自動化ツールで、 .tf という拡張子を持つリソース定義ファイルに記載した内容を基に、リソースを順序制御まで含めて一括作成してくれるツールです。
同類のツールには、 OpenStack Heat が挙げられるでしょうか。
Terraformの使い方
こちら に細かく書いてあります。(Terraformに限らず、HashiCorpのプロダクトはドキュメントが豊富でいいですよね)
ただ、やることは非常にシンプルです。
- Terraformをダウンロードしてパスを通す
- tfファイルを書く
- terraform init, terraform applyコマンド発行
これだけです。
tfファイルとは
tfファイルは、サービス上に作られる環境の設計図のようなもので、以下のような構造をしています。こちらも非常にシンプルです。
provider "openstack" {
user_name = "admin"
tenant_name = "admin"
password = "pwd"
auth_url = "http://myauthurl:5000/v2.0"
region = "RegionOne"
}
resource "openstack_compute_instance_v2" "instance_1" {
name = "instance_1"
network {
uuid = "75db0490-ae35-4a9a-87cd-bfcfe4a7a445"
}
}
- providerセクションで、providerに対する設定を書きます。上の例では認証のために必要な情報を書いているイメージです。
- resourceセクションで、作成したいリソースの情報を書きます。
このフォーマットはJSONとは似て非なるもので、 HashiCorp Configuration Lauguage: HCLという構文らしいです。
この例では書きませんが、複数のリソースを作ってお互いを接続するような書き方も当然できる(というよりそっちがメイン)わけなので、便利だなぁと思いますよね。
例えばOpenStack Providerだと こんな 例があります。
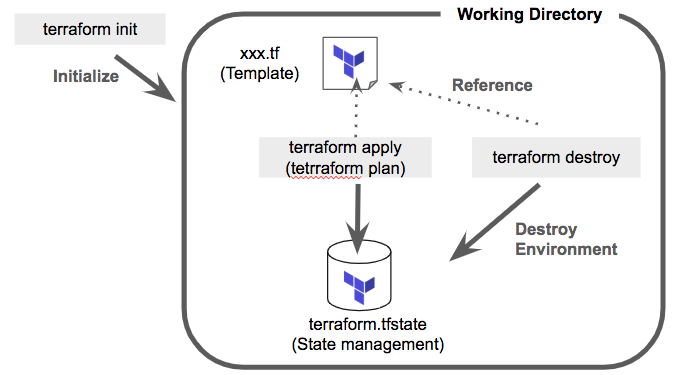
terraform init/apply/destroy
Terraformはディレクトリ単位で環境の状態を管理します。
正確には、ディレクトリ内の terraform.tfstate というファイルで状態が管理されます。
terraform.init をすると、このファイルがまず初期化され、 terraform apply で同フォルダにあるtfファイルに基づき環境が更新され、その更新された情報が terraform.tfstate でも整合性取られて管理されるイメージです。
Terraformの何がいいのか
ちょっと横道にそれますが、自分が開発者目線で見た時に、特に強く感じるTerraformのメリットは以下の通りです。
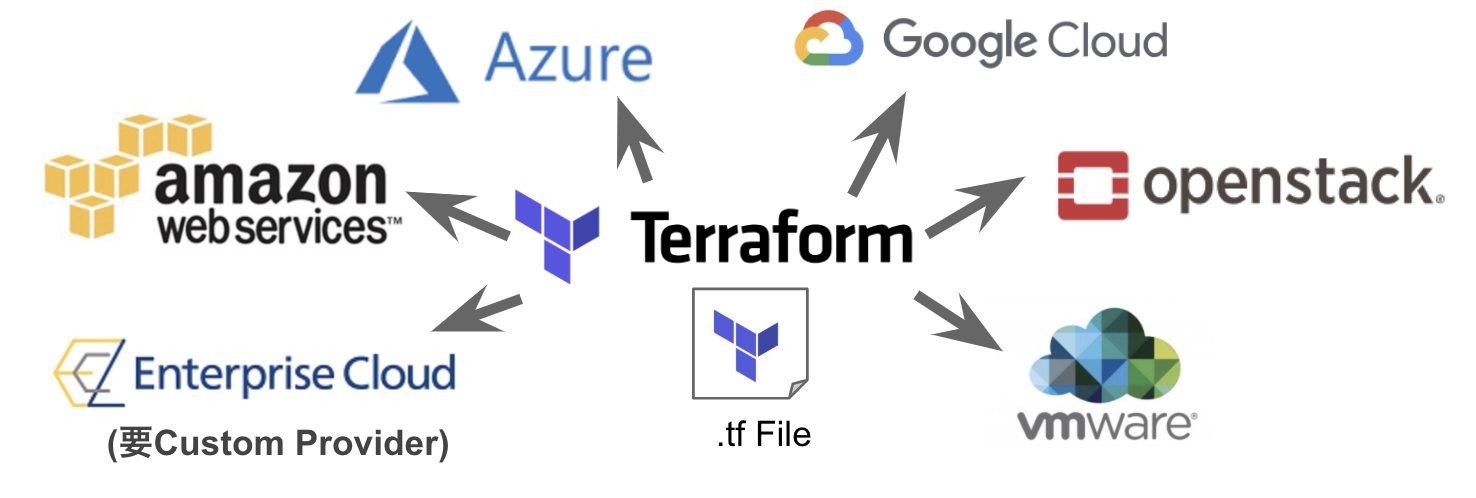
様々なターゲットに対して同一の手法で自動構築ができる
カスタムプロバイダというプラグインが多数存在します。それはもう恐ろしいレベルです。Heatではこうは行きませんし、自社開発とかだととても追随できないレベル。
そういう意味だと
Terraformのプロバイダを持っている=1つのステータス(注目度とか活用度という意味で)
みたいにすら感じてしまいます。
なお参考に対応プロバイダはこちら
これだけの対象に対して一括でオーケストレーションできるというのは素晴らしいことです。
オーケストレーターとしての活用事例も存在する
実際さくらのクラウドではこれを使ってオーケストレーターを開発しています。
機能的にはTerraformにひきずられるでしょうけど、圧倒的省コストで開発完了したのではないでしょうか。こういう考え方は素晴らしいと思いますし、個人的に大好きです。(作るより使えという方針)
リソースマネージャー というらしいです。
リソースマネージャー自体のAPIは存在しないみたいですが、GUIをお作りになられているということは、同じ様な仕組みでAPI化もできると思うので、機会があれば自社のコントローラー開発で(TerraformベースコントローラーのAPI化)にでもチャレンジしてみたいです。
コマンドラインツールなので、インフラを建てる必要がない
これはサービス開発者の目線ですが、もし自動化したい→じゃあそのためのコントローラを立てようか・・・みたいな流れになると、当然そのインフラが必要になりますし、コントローラ自体も開発が必要です。
しかしながら、サービス的にもまずフィージビリティがみたいようなフェーズからそんな投資をするのはもったいないよね・・・という時に、作業PCさえあれば使えるオーケストレーターというのは、予算・期間的に魅力です。
Provisioner という イレギュラー部分を最初から想定したもの がある
通常オーケストレーションツールというものは、構築対象がAPIを持っていると考えますが、Terraformの場合、「コマンドで連携する」ための Provisioner というものが最初から想定されています。
例えば、 「ごめん、どうしてもここだけAPI化できなかった」というような部分をごまかすことができるわけですね。
実際に作ってみたことがないのですが、これは直感的に便利だなと思いました。(と信じています)
Golangが覚えられる
これは僕だけの感覚でしょうけど、Goを覚えると、いわゆるCNCF系のものに手出しができるいいきっかけになるかなと思いました。
以上前談でした。
何でカスタムプロバイダを書き始めたのか
さて、筆者の中の人は、ある自社のクラウドサービスの開発に関わっています。(厳密には いました )
で、さらにそのクラウドをIaaS的に利用したサービス開発(一段上のサービス)に昨今関わり始めています。
そうした中で、そのクラウドサービスの環境を自動構築する必要が出てきました。(IaaSとしてという意味)
筆者はそのIaaSとなるクラウドサービスのコントローラやGUIを開発していた人間なのですが、当初は一段上のサービス用にさっさとコントローラを立てようという話も出ました。
が、まだそのフェーズじゃないっしょ・・・という個人的な感覚と、一旦まずは簡易に自動化するのでどうですか?またどうせなら世の中のスタンダードなものを使いたいんですが・・・という思いからTerraformに手を出して、 「あ、プラグイン(Providerという名前は知らなかった)ってこうやれば書けるんだ」 → 「あ、Goなんだ。じゃあ覚えるいい口実にもなるなぁ →作り始めた(いまここ) という感じです。
なお、関わっている(いた?)クラウドサービスの概要は ここ に書かれていますが、おおよそこんなサービスです。
- OpenStackを基盤に据えながらも各種機能を独自追加した感じのクラウド
- 各機能はマイクロサービスモデルを採用。原則APIで降る機能を提供
- 認証はKeystoneベース
なので、OpenStack Custom Providerでいけるのでは・・・と思うのですが、実はOpenStack部分にもそのまま使えない部分とかもあったりしましたし、そもそも独自API部分はどのみち対応してません。
ならそのサービス向けのプロバイダ作ったほうがそもそも楽だよね?という発想をしました。OpenStackのCustom Providerは非常に参考になったのでそれを流用する形で開発を開始しています。
いずれ正式リリースしたらどこかで宣伝する予定です。
カスタムプロバイダを書く前に
書く前にGoの環境は作っておきましょう。AND学習しておきましょう。
TerraformはGolangで書かれています。プラグインもGo必須。
ですのでGoの環境がないとまず開発出来ません。またある程度当該言語スキルが無いと無理です。(当然)
・・・が、僕は完全にGoは初めてです。最初は相当面食らいましたが大分慣れてきました。
Pythonでいうpyenv相当には、gvmが便利です。以前の記事を参照ください。
ちなみに筆者はHeatのResource Pluginは自社向けに結構書いていた人間でして、プロバイダの概念は比較的頭にすっと入ってきました。(がGolangが入ってきません)
カスタムプロバイダを書く上で
カスタムプロバイダを書く上では、いろいろ作法はありますが、基本的な内容は Writing Custom Providers に書いてあります。
主要なところでは以下を作ることになります。
- Provider
- Resource
- Acceptanceテスト
- Import/Data(これがよく分かっていない)
Provider
今作っているProviderは、基本OpenStackのそれを参考にしているわけですあ、以下のような形で実装しています。
まずmain.goで以下のように返し・・・
package main
import (
"github.com/hashicorp/terraform/plugin"
"github.com/nttcom/terraform-provider-ecl/ecl"
)
func main() {
plugin.Serve(&plugin.ServeOpts{
ProviderFunc: ecl.Provider})
}
eclパッケージにProviderというfuncを定義して、それが実体を返す。
func Provider() terraform.ResourceProvider {
return &schema.Provider{
Schema: map[string]*schema.Schema{
"auth_url": &schema.Schema{
Type: schema.TypeString,
Optional: true,
DefaultFunc: schema.EnvDefaultFunc("OS_AUTH_URL", ""),
Description: descriptions["auth_url"],
},
"region": &schema.Schema{
Type: schema.TypeString,
Optional: true,
Description: descriptions["region"],
DefaultFunc: schema.EnvDefaultFunc("OS_REGION_NAME", ""),
},
(snip)
},
DataSourcesMap: map[string]*schema.Resource{
"openstack_compute_flavor_v2": dataSourceComputeFlavorV2(),
"openstack_compute_keypair_v2": dataSourceComputeKeypairV2(),
(snip)
"openstack_networking_router_v2": dataSourceNetworkingRouterV2(),
},
ResourcesMap: map[string]*schema.Resource{
"ecl_compute_keypair_v2": resourceEclKeypairV2(),
"ecl_compute_instance_v2": resourceComputeInstanceV2(),
"ecl_compute_volume_v2": resourceComputeVolumeV2(),
"ecl_compute_volume_attach_v2": resourceComputeVolumeAttachV2(),
"ecl_network_common_function_gateway_v2": resourceNetworkCommonFunctionGatewayV2(),
(snip)
},
ConfigureFunc: configureProvider,
}
}
その中でも、
Schema
ここで定義した内容については、tfファイルのproviderセクションで定義してあげることになります。
基本的には認証系の情報を持っているイメージなのだと思います。
DataSourcesMap
これは後述しますがよく分かっていません。これから実装しながら読み進めていこうかなと思います。特にテストに関係しているのかなと推測してますが・・・。
ResourcesMap
ここでは、tfファイルにおけるリソース定義文言と、実際のリソース定義関数の紐付けをしています。
例えば、 ecl_compute_keypair_v2 とtfファイルに書いた場合、resourceEclKeypairV2の定義に従ってリソースが作成されますよ・・・という意味ですね。
Resource
次に、↑の ResourcesMapの先で呼び出されるリソース定義関数を書く必要があります。
例えば Keypair ですとこんな感じですね。
func resourceEclKeypairV2() *schema.Resource {
return &schema.Resource{
Create: resourceEclKeypairV2Create,
Read: resourceEclKeypairV2Read,
Delete: resourceEclKeypairV2Delete,
Importer: &schema.ResourceImporter{
State: schema.ImportStatePassthrough,
},
Schema: map[string]*schema.Schema{
"region": &schema.Schema{
Type: schema.TypeString,
Optional: true,
Computed: true,
ForceNew: true,
},
"name": &schema.Schema{
Type: schema.TypeString,
Required: true,
ForceNew: true,
},
"public_key": &schema.Schema{
Type: schema.TypeString,
Optional: true,
Computed: true,
ForceNew: true,
},
"private_key": &schema.Schema{
Type: schema.TypeString,
Computed: true,
},
"fingerprint": &schema.Schema{
Type: schema.TypeString,
Computed: true,
},
"value_specs": &schema.Schema{
Type: schema.TypeMap,
Optional: true,
ForceNew: true,
},
},
}
}
(この後ろにCRUD用関数が続く・・・)
上の方に
Create: resourceEclKeypairV2Create,
Read: resourceEclKeypairV2Read,
Delete: resourceEclKeypairV2Delete,
という部分がありますが、これがCRUDのそれぞれの時に呼ばれる関数です。
OpenStack Heatとかですと、handle_createとか、check_create_completeとかに該当する処理を、上のような形で定義していくイメージでしょうか。
また Schema にパラメータを定義していきます。 OpenStack Heat だと Property, Attributeの区別が明確でしたが、そこは一緒に定義していくイメージのようですね。
(OpenStack HeatのAttributeは、Property(Computed = true)に近いイメージですね)
Acceptanceテスト
Terraformの公式サイトを見ると、TestとAccテスト(Acceptanceテスト)は違うものとして定義されており、かつ、Accテストは課金されちゃうから注意ね!って書かれてます。
実際AccテストはAPIを発行してリソースを実際にCRUDします。いわゆるシステムテスト・結合テストのイメージですね。
で、皆さんこれをメインに実装されている。
じゃあ通常のテストってなによ?ということなんですが・・・。
Terraform界の通常のテスト=ユーティリティ系関数とかのunittest
という考えでほぼ間違ってないかなと思います。
Heatなんかだと、API実行部をモックしてリソースクラスの挙動を確認するためのunittestがあって、これが非常にリファクタに役立つのでそういう物を作れるかな・・・と思っていろいろ考えていたのですが、結論としては一旦諦めました。
ちなみにmakeファイル内では、Accテストの場合だけ環境変数がセットされ、それに連動してAccテストが動くかどうかが分岐する・・・みたいなことをやってます。
普通にRequest/Responseをモックしたunittest書きたいなぁ・・・。
いいアイデア無いのだろうか。
Import/Data
ここは正直まだ書いたことがないのでよく分かりません。実装が進んできたらまたここの部分を別記事で書こうかなと思います。
今回の最後に
今後進むにつれていろいろ出てくると思うので、都度アプデしていきます。
またProviderは初心者なので、良いサイトあれば教えてください。