※前回記事にてトラブルシューティング実施にあたって準備しておきたいこと(作業ログの取得方法など)を記載しておりますので、本記事では割愛します。
はじめに
前回の記事の続きとなります。
前回に記事を書いたあと、現場でも意外と基礎を押さえた切り分けができない人が多いのではと思い、よりいろんな方に読んでいただきたくタイトルをかえてみました。
前回の記事では、トラブルシューティングの前に実施しておきたい事や心構えについて記載しました。
今回はそれを受けて実際にトラブルが起きた際の簡易的な切り分け方法についてまとめてみます。
本記事の対象と扱う範囲
前回記事と同様に、初めてエンジニアとして働くことになった方々向けです。
本記事のゴールが「○○できないですのですが、、」といった事象に対して自ら順を追って基本事項を確認し、効率的に質問ができるようになること(先輩社員の負荷を減らすこと笑)を目的としています。
そのため必ずしも自ら解決できるようになることをゴールとはしていません。
ですので、調査時に使えるツールやコマンドの詳細な紹介、パフォーマンス劣化の原因調査やパケット解析といったより詳細なトラブルシューティングについては触れませんのであらかじめご了承ください。
今回取り上げるコマンドもとても基礎的(だけどとても重要)なものにとどめています。
想定するケース
今回は**「○○に接続できない」**とういケースを想定した基本的な切り分け方法を確認していきます。
Webアプリケーションへの接続、または何かしらのツールからサーバ上で稼働するアプリケーションへ接続するような状況を想定しています。
なぜこのケースを選んだかというと、以下の理由からです。
- 1番質問、問い合わせが多いから(現場でも同じ)
- トラブルシューティング時に必要な項目を一通りの確認できるから
なお接続元の端末、接続先のサーバはLinux系のOSを想定しております。
WindowsOSなど他OSの場合も、対応する類似のコマンドがありますので適宜調べてみてください。
もちろんトラブルシューティング時の考え方はOS問わず共通です。
忙しい人のためのチェックフロー
またまた長い記事なってしまったので簡単なチェックフローを作成してみました。
細かい箇所までは網羅できていないので、詳細は次以降を確認してみてください。
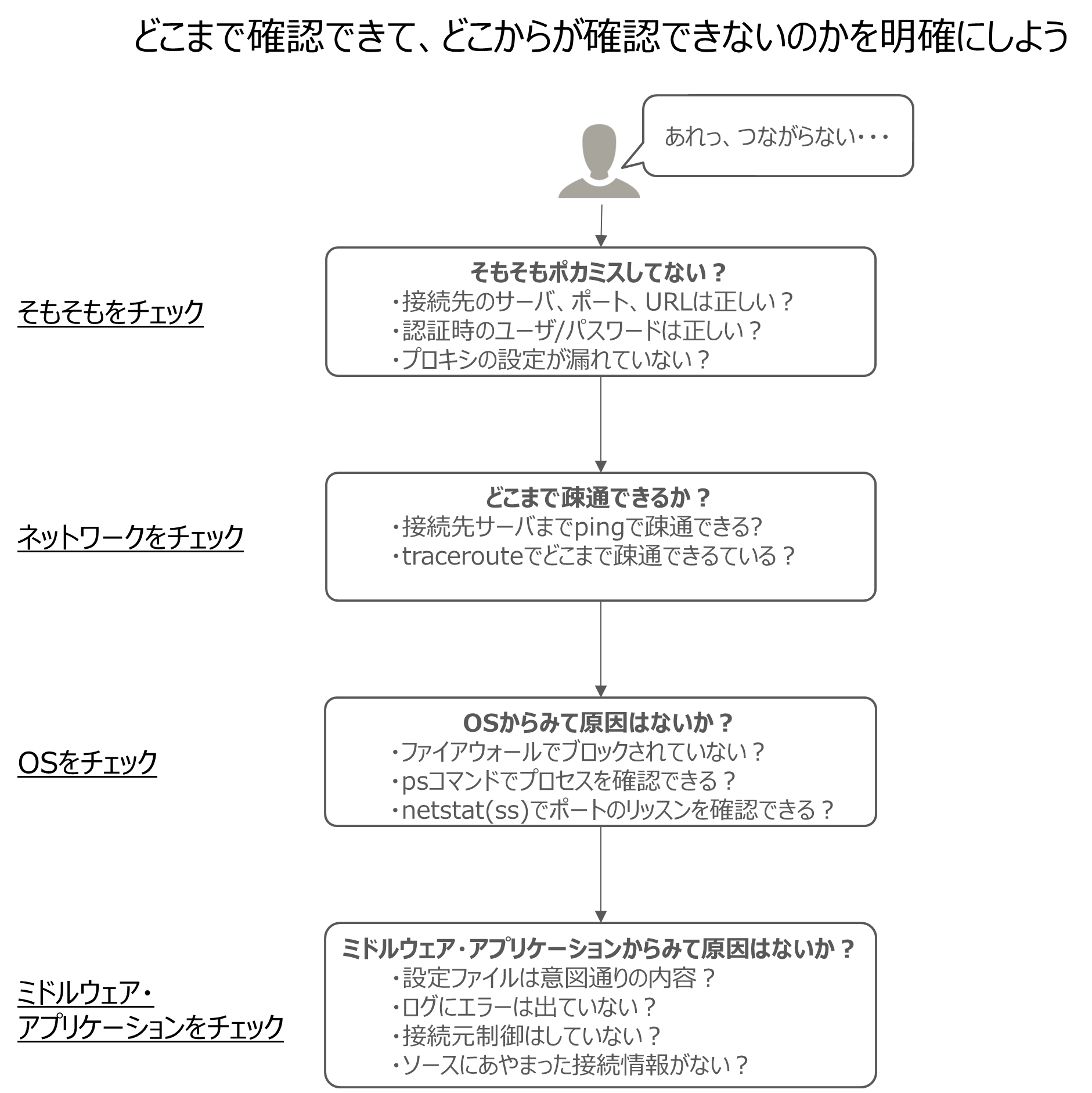
確認していく順番
明らかに原因にあたりがついている場合は別ですが、慣れないうちは処理の流れを意識して順を追って原因調査にあたることをおすすめします。
それでは、確認すべき順番とはどういった順番なのでしょうか?
例えば以下のようなシーンを想定します。
自分の作業用PCのブラウザから、あるサーバ上で稼働するWebアプリケーションの機能を使いたいとします。
この場合、自分のPCからサーバで稼働するアプリケーションへデータが流れていくまでの過程は以下のようになります。
- ブラウザからの操作がネットワークを通じてサーバまで届く
- 要求を受け取ったサーバは適切なアプリケーションまでそのデータを届ける
- 受け取った要求をもとにアプリケーションで処理を行い応答を返す
原因切り分け時に確認していく順番とはまさにこの処理がながれていく順番と同じです。
アプリケーションに接続できない場合、この一連の処理の途中に何か滞らせる原因があるわけですから、確認もその処理の流れにそって行っていくのは自然な考え方ですよね。
はたまた、もしかするとそもそも接続先を間違っているなど、自分側に原因がある可能性もあります。
先ほどの例をもう少しレイヤを意識してみてみると下のようになります。
- ネットワークを通じて要求がサーバまで届き
(ブラウザからの操作がネットワークを通じてサーバまで届く)
-
OSが適切なアプリケーション(ミドルウェア)に要求を届け
( 要求を受け取ったサーバは適切なアプリケーションまでそのデータを届ける) -
アプリケーション(ミドルウェア)は受け取った要求に従い処理をし応答を返す
(受け取った要求をもとにアプリケーションで処理を行い応答を返す)
よって、トラブルシューティング時にチェックしていくべき内容と順番は以下のように考えることができます。
- そもそもをチェック(そもそもの情報があっているか)
- ネットワークをチェック(ネットワークは正常に利用できるのか)
- OSをチェック(OS上で正常にアプリケーションは起動しているのか)
- ミドルウェア・アプリケーションをチェック(設定は正しくエラーが出ていないか)
この先では、それぞれで何をどのように確認すべきかを整理していきます。
質問の仕方がどう変わるのか
上の順番で原因調査にあたると以下のような質問や問い合わせの仕方ができるはずです。
「○○までは△△して確認ができたのですが、それ以降で□□というエラー(または事象)が発生してしまったのですがどうしてでしょうか。」
これまでの「○○できませんでした」の質問と大きく異なることは、質問を受けた側の調査範囲です。
「○○できませんでした」と質問や問い合わせを受けた人からすると、結局上で説明した順番でどこまでが大丈夫でどこでうまくいかないのかを調べる必要があります。これはとても負荷の高い作業です。
順を追った切り分けを実施して質問をする場合、質問を受けた側はうまくいかなかった箇所からトラブルシューティングにあたれるので、効率的に時間と労力をかけることができます。
こういった切り分け対応をした上での問い合わせができれば、「おっ、この人できるな」ときっと思ってくれるはずですので、ぜひ身に着けておきましょう笑
それでは順を追って具体的な確認内容やその方法についてみてきましょう。
0. 終始徹底したいこと
さきほどの確認順番にはあえて記載しませんでしたが、トラブルシューティング時に終始実施すべき重要な作業があります。
ググることです。
至極当たり前のことなのですが、わからないことがあったら調べる。(ググる)
これは鉄則です。
同様の事象がないか、エラー表示の文字から何かヒントは得られないかをちゃんと自ら調べる癖を徹底してみてください。
最初のうちはググってヒットした情報を見てても、さらにその情報の中に知らない用語が出てきて…といった具合で嫌気がさしてしまうかもしれません。
ただ、今だからこそ分からないことがあっても根気強くさらに調べていく姿勢を身につけてほしいなと考えています。
今はわからなくても、根気強くやってくことである日ぱぁっと世界が開けたように理解できる時がきます。(この感覚を味わうために最初は辛くても頑張ることができるようになります笑)
1. そもそもをチェック
まず確認すべきは、そもそも何か情報に誤りや漏れがないかという観点でのチェックです。
例えば以下の情報は本当に正しいのかを確認してみてください。
- 接続先のURLは間違っていないか
- 接続先サーバのIPアドレス・ホスト名を間違っていないか
- アプリケーションのポート番号を間違っていないか
- 接続時に指定するユーザ/パスワードに誤りがないか
- 社内プロキシの設定がもれていないか
- VPNで接続する際、利用するVPNプロファイルを誤っていないか
社内ネットワークからhttp(s)で接続する場合、社内プロキシはハマるポイントだったりするので、ここの段階で確認してみることをお勧めします。
そもそも誤りがないかの確認を終えたら、ここからがスタートです。
2. ネットワークをチェック
次には、そもそも通信が目的のサーバや機器まで届いているのかを確認することです。
サーバ上で稼働するアプリケーションに接続できないのは、もしかするとネットワーク経路上のどこかで通信が遮断されているからかもしれません。
通信が遮断されてしまっている可能性としては大きく2つあります。
- ネットワーク経路上で障害が起きている
- 意図的に遮断されている
ネットワーク経路上で障害が起きている
通信経路上のネットワーク機器の物理故障や論理障害、LANケーブルの断線などが考えられます。
こういった場合、おそらく周囲の人たちも同様に接続ができない状態に陥っている可能性が高いので、周囲の人の状況なども聞いてみるとよいかもしれません。
意図的に遮断されている
これはセキュリティの観点から意図的に通信が遮断されているケースです。
例えば経路上のネットワーク機器で送信元や通信プロトコルの情報をもとに通信をフィルタリングしているといった場合です。こういった場合、接続時の表示などでわかる場合もありますが、詳細な確認についてはシステム管理者に問い合わせる必要があるかもしれません。
もし問い合わせる場合も、もちろん「1. そもそもをチェック」を終えていることが前提です。
アプリケーションが稼動するサーバ上でファイアウォールが稼動しているといった可能性も考えられますので、その確認方法については「3. OSをチェック」で確認しましょう。
ネットワークのチェックに使えるコマンド
それでは確認に使える必須コマンドを紹介していきたいと思います。
インフラ管理者以外で直接サーバに入って調査できない場合も、最低限確認しておきたい内容なので、ぜひ押さえておいてください。(たったの2つでOKです!)
ping
疎通確認にはpingコマンドが活用できます。
$ ping <対象サーバ(機器)のホスト名 or IPアドレス>
例えば192.168.1.1というIPアドレスを持つサーバにpingコマンドで疎通を確認してみます。
疎通ができると以下のように対象サーバから応答がかえってきます。
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.133 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.118 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.115 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=64 time=0.117 ms
…
もし疎通ができない場合は以下のように「Destination Host Unreachable」という結果がかえされます。
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
From 192.168.1.1 icmp_seq=1 Destination Host Unreachable
From 192.168.1.1 icmp_seq=2 Destination Host Unreachable
From 192.168.1.1 icmp_seq=3 Destination Host Unreachable
…
接続先のサーバからpingの応答がなかった場合、経路の途中に原因があるか、サーバ自体に原因があるかもしれません。
次のtracerouteで経路の途中に問題があるのかを確認し、その結果をインフラ管理者へ共有しましょう。
traceroute
目的のサーバや機器までどういったネットワーク経路をたどるのかを確認できるのがこのコマンドです。
例えば異なるネットワークにある192.168.2.1までのネットワーク経路を確認してみます。
目的のサーバが別ネットワーク上にあるためゲートウェイを経由して到達していることがわかります。
$ traceroute to 192.168.2.1 (192.168.1.1), 30 hops max, 60 byte packets
1 192.168.1.254 (192.168.1.254) 0.865 ms 0.948 ms 1.034 ms
2 192.168.2.254 (192.168.2.254) 0.412 ms 0.396 ms 0.370 ms
3 192.168.2.1 (192.168.2.1) 1.308 ms 1.295 ms 1.276 ms
もし経路の途中に原因があると以下のように「***」が表示され続けてコマンドが終了します。
$ traceroute to 192.168.2.1 (192.168.1.1), 30 hops max, 60 byte packets
1 192.168.1.254 (192.168.1.254) 0.865 ms 0.948 ms 1.034 ms
2 192.168.2.254 (192.168.2.254) 0.412 ms 0.396 ms 0.370 ms
3 * * *
4 * * *
5 * * *
…
tracerouteが目的のサーバまで到達していない場合は、経路の途中に原因がある可能性が高いので、インフラ管理者にtracerouteの結果を共有し問い合わせてみましょう。
サーバの直前まで辿りついているものの、疎通ができない場合はサーバ側のファイアウォールではじかれている可能性があるので、実機を確認するか同様に担当者に確認してもらいましょう。
ネットワーク上は目的のサーバまで、もしくは直前まで届いていることが確認できたら、次はOSをチェックしましょう。
3. OSをチェック
ここからはサーバ上で確認を進めていきます。
主な確認事項は以下の通りです。
- ファイアウォールでブロックされていないか
- プロセスは正常に起動しているか
- ポートはリッスンしているか
それでは順を追って確認していきましょう。
ファイアウォールでブロックされていないか
セキュリティ上、OSのファイアウォールを稼働させている場合、接続元IPアドレスや接続先ポート番号でアクセスが制限されています。
接続元の端末や、接続したいアプリケーションが利用するポートへの通信が許可されていない可能性があります。(ファイアウォールの許可設定をすることを「穴をあける」といったりします。)
OSのファイアウォールの内容はそれだけで一記事になってしまう量なので、主要なOSディストリビューション毎の参考となるリンクを記載します。
ファイアウォールの設定ではじかれていないかを確認してみましょう。
切り分けのために一時的にOSのファイアウォールを切って接続確認をしてみるという方法もとれますが、問題ないかは必ず確認してください。
RedHat・CentOS
▼仕組みなど全体像を押さえたい
Linux女子部 firewalld徹底入門!
Linux女子部 iptables復習編
▼コマンドの使い方を押さえたい
CentOS iptablesによるパケットフィルタ
CentOS7 firewalldの設定方法 - UnixPower on Networking
Ubuntu
▼UFWを使う場合
UFW - Community Help Wiki - Official Ubuntu Documentation
プロセスは正常に起動しているか
ファイアウォールでの設定を終えても事象が解決しない場合は、アプリケーションプロセスの稼動状況を確認してみましょう。
まずはプロセスが正常にあがっているのかをコマンドで以下の確認してみましょう。
ps
psコマンドはOSが管理しているプロセステーブルの情報を表示することができます。
auxオプションをつけることで、全てのプロセス情報の詳細を表示することができます。
(各カラムの意味は「ps aux」コマンドで表示される項目の意味を知りたいをご参照ください)
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 29628 4328 ? Ss 6月16 0:01 /sbin/init
root 2 0.0 0.0 0 0 ? S 6月16 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 6月16 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 6月16 0:00 [kworker/0:0H]
…
下の例は、サーバ上で稼働しているプロセス一覧からsshdプロセスの情報のみを表示させています。
2つ目の「grep -v grep」はgrepコマンド自身のプロセス情報を除外して見やすくするためのものなので、なくても大丈夫です。(なおgrep自身を除外する方法は複数あります)
? ps aux | grep sshd | grep -v grep
root 1341 0.0 0.0 59576 5372 ? Ss 6月16 0:00 /usr/sbin/sshd -D
root 7129 0.0 0.0 103688 6540 ? Ss 6月18 0:00 sshd: mano [priv]
user01 7214 0.0 0.0 104060 5168 ? S 6月18 0:01 sshd: user01@pts/3
root 16383 0.0 0.0 103688 6568 ? Ss 00:35 0:00 sshd: keigo [priv]
user02 16468 0.0 0.0 103824 4868 ? S 00:35 0:00 sshd: user02 @pts/9
psコマンドの表示で特に確認してもらいたいのが以下の箇所になります。
- USER(プロセスの所有ユーザー)
- STAT(プロセスの状態)
アプリケーションプロセスが正しいOSユーザで起動しているかを確認してください。
例えば正しいユーザーで起動していなかったために、必要なファイルやディレクトにアクセスできず必要な処理ができていないということも考えられます。
STATはそのプロセスの稼働状態を表します。ここが特にZ(ゾンビ状態)となっていないかを確認してみてください。
ゾンビ状態とはOSの管理するプロセステーブル上はあたかもプロセスが存在していることになっているのですが、実態のプロセスが存在していない状態です。
該当アプリケーションがゾンビ状態となってしまっていた場合、killコマンドでこのプロセスを強制的に殺して、再度起動処理を行って状態を確認してみてください。
$ kill -9 <該当プロセスID>
そもそもpsコマンドでアプリケーションプロセスが表示されない…
そもそもプロセスが存在していなかった場合、起動にすら失敗している可能性があります。
再度起動処理を実施して、その際のメッセージや該当ログの内容を確認してみましょう。
効率的なログの確認方法は「4. ミドルウェアをチェック」にまとめましたのでそちらも確認してみてください。
ポートはリッスンしているか
プロセスが正常に稼働していることが確認できたら、今度は正常にポートがリッスンしているかを以下のコマンドで確認しましょう。
netstat(systemdの場合はssコマンド)
netstatコマンドで現在そのサーバ上のプロセスが何番ポートで起動しているのかを確認できます。
「anp」オプションをつけることでプロセスIDも表示することができるので、先ほどのpsコマンドで調査対象のアプリケーションプロセスのプロセスIDを特定してgrepで絞り込むことも可能です。(プロセスIDも表示する場合はroot権限で実行する必要があります)
$ sudo netstat -anp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22921 0.0.0.0:* LISTEN 876/rpc.statd
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 842/rpcbind
tcp 0 0 127.0.1.1:53 0.0.0.0:* LISTEN 2429/dnsmasq
tcp 0 0 0.0.0.0:36886 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1341/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 12394/cupsd
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 11413/postgres
…
RedHat/CentOSのバージョン7系などsystemdを利用している場合は以下で同様の情報を確認できる。
$ sudo ss -anp
nl UNCONN 0 0 15:-4163 *
nl UNCONN 0 0 16:0 *
nl UNCONN 0 0 16:1292 *
nl UNCONN 0 0 18:0 *
u_str LISTEN 0 128 /tmp/.X11-unix/X0 941 * 0 users:(("Xorg",pid=1516,fd=3))
u_str LISTEN 0 128 /var/run/avahi-daemon/socket 14596 * 0 users:(("avahi-daemon",pid=724,fd=10))
u_str LISTEN 0 128 /tmp/ssh-i3fnhMckky/agent.7214 69071 * 0 users:(("sshd",pid=7214,fd=11))
u_str LISTEN 0 30 /sys/fs/cgroup/cgmanager/sock 1302 * 0 users:(("cgmanager",pid=350,fd=3))
u_str LISTEN 0 30 /var/run/dbus/system_bus_socket 11544 * 0 users:(("dbus-daemon",pid=578,fd=4))
psコマンドで接続したいアプリケーションのPIDを確認し、netstat(ss)コマンドで想定したポート番号でリッスンしているのかを確認してみましょう。
ここまでで特に問題がない場合は次の「4. ミドルウェア・アプリケーションをチェック」に移り、より詳細な原因調査を行っていきます。
4. ミドルウェア・アプリケーションをチェック
いよいよ最後の確認ポイントです。(ここまできたらもう原因特定まで自分でやれよというツッコミは置いておいて)
ミドルウェア・アプリケーションは千差万別で確認が必要な箇所はそれぞれ変わってきます。
ですのでここでは共通する確認ポイントやその方法についてまとめます。
押さえておいてほしいポイントは以下です。
- 設定ファイルを再度確認する
- ログファイルを追う
それでは順番に確認していきましょう。
設定ファイルを再度確認する
実は結構多い原因としてミドルウェアの設定ファイルや、アプリケーションが固有で利用する設定ファイルの誤りや漏れというものがあげられます。
利用するミドルウェア毎に設定方法は異なりますが、主に以下の設定値を確認してみてください。
- リッスンポートが意図したポート番号になっているか
- ディレクトリのパスの指定に誤りがないか(そのディレクトリがOS上で存在し適切なオーナー、パーミッションが存在しているか)
- 他サーバと協調して動くようなソフトウェアの場合、他サーバの情報に誤りがないか
- 必要な環境変数が正しく設定されているか
- ミドルウェアの設定で接続元を制御していないか
- アプリケーションのコード内に誤った接続情報がハードコーディングされていないか
ログファイルを追う
ログの確認はトラブルシューティング時の基本となります。
ソフトウェア固有の原因の場合は最終的にログを追いながらつぶさにあたりをつけていくことになります。
ログの確認の仕方なのですが、まずは以下のような確認をしていくことになります。
- 過去のログからメッセージを追う
- リアルタイムにログを追いながら挙動を確認する
過去のログからメッセージを追うというのは、既存のログファイルからおかしなログが出力されていないかを確認することです。
次の、リアルタイムにログからアプリケーションの状態を確認するために以下のコマンドを活用してみてください。
tail
tailコマンドに「-f」オプションを利用することで、リアルタイムにログを確認することができます。
例えばWebアプリケーションの場合、ログをtailで確認しながらブラウザからアクセスしてログに出力される情報を追って原因を追究するということもできます。
ターミナルを複数開いて、片方でログをリアルタイムにtailしておきながら、もう片方のターミナルで操作して挙動を確認するということも行ったりします。
下はapacheのアクセスログ(監視ツールMuninへのアクセス)をリアルタイムに表示させています。
アクセスがあるたびに一行ずつ最新に更新されていきます。
$ tail -f /var/log/apache2/access.log
192.168.1.1 - munin [18/Jun/2015:18:46:14 +0900] "GET /munin/localdomain/localhost.localdomain/munin_stats-day.png HTTP/1.1" 200 15290 "http://192.168.1.1/munin/munin-day.html" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36"
192.168.1.1 - munin [18/Jun/2015:18:46:17 +0900] "GET /munin/network-day.html HTTP/1.1" 200 1669 "http://192.168.1.1/munin/processes-day.html" "Mozilla/5.0 (Windows NT 6.1)
まとめ
私も社会人になってから初めてサーバに触れ、何かちょっとした問題でも慌てふためいていたことを覚えています。
私も当初は「○○できないのですが」とよく先輩社員へ質問をしに行くたびに、申し訳ない気持ちでいっぱいでした。(当時は何が分からないのかすら分からない状態でした)
そうした中、必死に先輩の確認手順をひたらすら隣でみて、みな自然とデータの流れ、レイヤ・スタックを意識して確認していることに気づけました。
早くこのことに気付けたら、どれだけ多くの時間を効率の悪い調査に使わずに済んだことかと今でも後悔していています。
こうした思いから、この記事がこれから現場で活躍が期待されるみなさんの力に少しでもなれたらとても嬉しいです。