はじめに
本記事は 三重大学 計算研 Advent Calendar 2019 7 日目です。
最近 AtCoder で問題を解いているとき、毎回サンプルを試すのが面倒でまとめてできたらなーと思うことが増えました。調べてみると online-judge-tools や atcoder-tools など他にもいろいろ出てきたのですが、せっかくなので勉強のために自分でも作ってみます。
いきなり上記のようなツールを目指すと難しくてつらくなってしまうので、今回は単純にサンプル出力と実行結果が完全一致しているかのチェックのみです。
ざっくりとした流れは問題ページからサンプルの入出力を取得してローカルに保存 -> 手元での実行結果と比較、という感じです。
BeautifulSoup4, Requests を使います。
※ここで作成するツールはコンテスト中に動きません。ログイン処理を追記すると動くようになります。
ログイン処理については Atcoderで使えるコード自動テストツールを作った を参考にすると良い感じになります。
環境
- Windows 10
- Python 3.7.4
- bash (version 4.4.23)
インストールしておくもの
- Python3
- BeautifulSoup4 (ライブラリ)
- Requests (ライブラリ)
実践
Web ページ情報の取得
とりあえずここでは ABC147 の A 問題のページ情報を取得してみます。
以下では problem_url に問題ページの URL を直接代入していますが、ここを良い感じに指定できると使いやすくできそうです。
import requests
from bs4 import BeautifulSoup
# 問題ページの URL (例)
problem_url = "https://atcoder.jp/contests/abc147/tasks/abc147_a"
# 問題ページの情報を取得
problem_html = requests.get(problem_url)
problem_soup = BeautifulSoup(problem_html.content, "html.parser")
requests.get(URL) は URL のページの HTML を返してくれます。
problem_html にはこの結果が格納されていて、表示してみると生の HTML がぶわっと出てきます。
そこで、BeautifulSoup() に今得られた problem_html を投げることで HTML の情報を扱いやすくできます。
たとえば
print(problem_soup.title)
を実行すると、
<title>A - Blackjack</title>
という出力が得られるようになります。web ページの情報がちゃんと得られていることも分かります。タグを取りたい場合は
print(problem_soup.title.get_text())
とすると以下のように良い感じになります。
A - Blackjack
サンプル入出力のデータを探す
問題ページのサンプルデータを検証モードで開いてみると、どうやら <pre> ~ </pre> で囲まれているようです。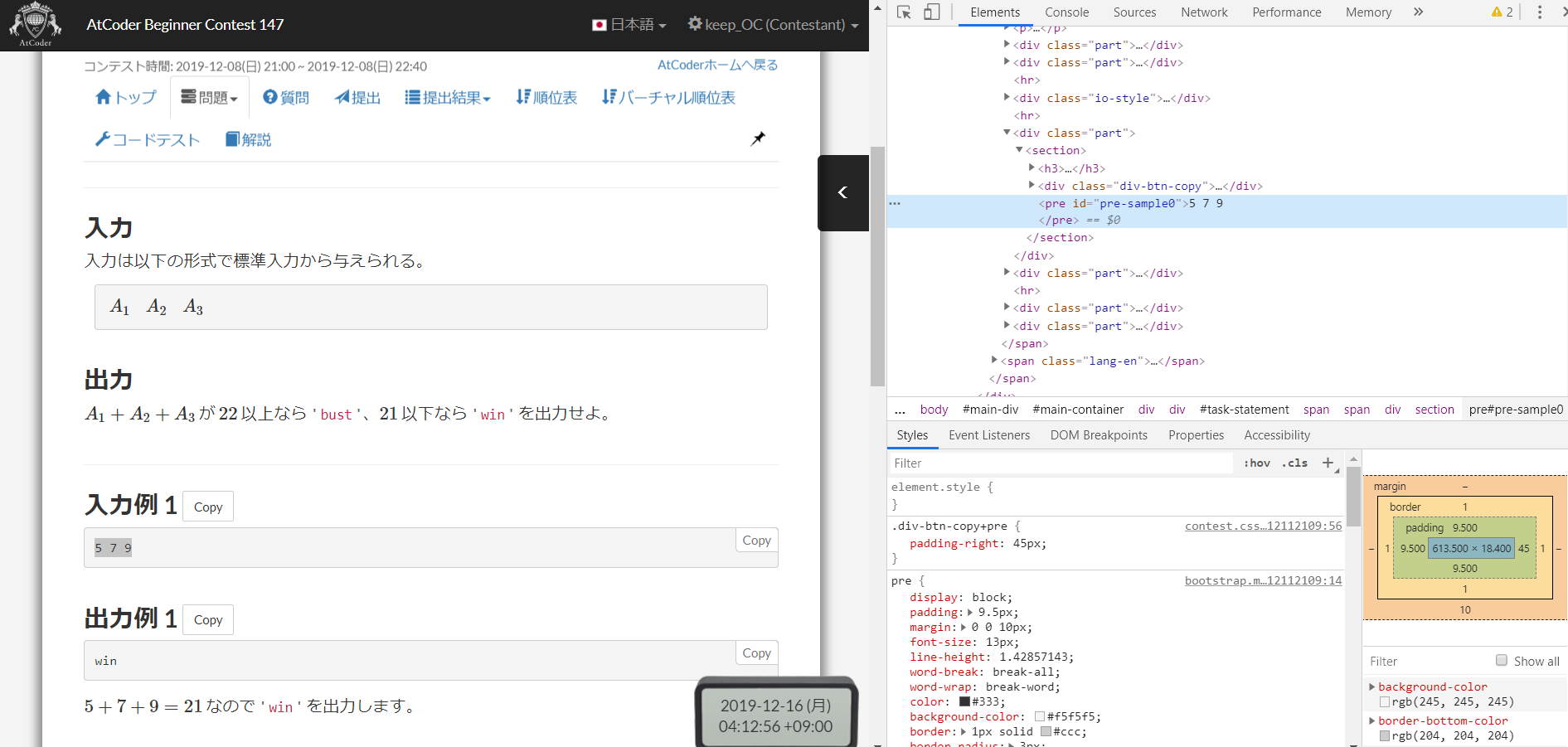
<pre> タグを検索して表示してみます。
for i in problem_soup.find_all("pre"):
print(i.get_text())
以下が出力結果です。
A_1 A_2 A_3
5 7 9
win
13 7 2
bust
A_1 A_2 A_3
5 7 9
win
13 7 2
bust
良い感じにサンプルデータを取得できていそうです。2 回表示されているのは英語ページ分のものみたいです。要素数が偶数個なら半分まで見るとよさそうです(昔の ABC は英語ページがない && 出力説明が <pre> タグで囲われるフィールドでない(ほんと?))。
サンプルデータをファイルに格納する
サンプルデータの場所が分かったのでローカルに保存していきます。今回は今いるフォルダに直接保存することにします。
# サンプルデータを取得
testcase = problem_soup.find_all("pre")
# サンプルの数
# 英語ページのサンプルも取ってきているので省く
n = len(testcase)
if n % 2 == 0:
n = int(n / 2)
# サンプル入出力をファイルに書き込む
for i in range(1, n, 2):
# 例
# testcase[1] -> Sample1 の入力
# testcase[2] -> Sample1 の出力
case_num = int((i + 1) / 2)
# i == 1 なら in1.txt に Sample1 の 入力を保存
in_path = "in" + str(case_num) + ".txt"
f_in = open(in_path, "w")
f_in.write(testcase[i].get_text())
f_in.close()
# 出力例も同様
out_path = "out" + str(case_num) + ".txt"
f_out = open(out_path, "w")
f_out.write(testcase[i + 1].get_text())
f_out.close()
手元での実行結果をファイルに保存する
サンプルの入力データを保存できたので、次はこれを使って手元のプログラムを実行、結果をファイルに保存していきます。
import subprocess
# 実行して結果をファイルに格納
for i in range(1, n, 2):
case_num = int((i + 1) / 2)
# 標準入力を in?.txt, 標準出力を res?.txt に設定してプログラムを実行
in_path = "in" + str(case_num) + ".txt"
res_path = "res" + str(case_num) + ".txt"
subprocess.run("./tmp", stdin=open(in_path, "r"), stdout=open(res_path, "w"))
実行ファイルの実行は subprocess.run() を使います。これを用いると普段ターミナルで叩くコマンドを Python プログラム中から呼ぶことができます。
ここでは ./tmp が実行ファイルになっています。TLE 対策はしていません…
出力が合っているかチェック
手元にサンプル出力と実行結果が揃ったので、これらが完全一致しているかチェックしていきます。
filecmp というライブラリがあって良い感じだと思ったんですが、改行まわりでうまくいきませんでした。なので今回はファイルの中身を文字列として抽出し、改行文字を除去したものを比較していきます。
# サンプル出力と実行結果が合ってるか確認
is_correct = True
for i in range(1, n, 2):
case_num = int((i + 1) / 2)
out_path = "out" + str(case_num) + ".txt"
f_out = open(out_path, "r")
out_str = "".join(f_out.read().splitlines())
f_out.close()
res_path = "res" + str(case_num) + ".txt"
f_res = open(res_path, "r")
res_str = "".join(f_res.read().splitlines())
f_res.close()
if out_str != res_str:
is_correct = False
print("Sample " + str(case_num) + " WA...")
else:
print("Sample " + str(case_num) + " AC!")
if is_correct:
print("Sample OK!")
else:
print("Wrong Answer exist.")
"".join(f.read().splitlines()) でファイルの中身を文字列にして、改行文字を消すことができます。
f.read() はファイルの読み込み、splitlines() で改行で文字列を分割したリスト生成、"".join(文字列のリスト) でリストの文字列を "" を挟みながら連結という感じです。
とりあえずはこれでチェック終了です。
おわりに
この記事では主にスクレイピングとファイル保存、その中身の比較について記述しました。ここからコンテスト URL を入力で受け付けたり、コンパイルもまとめてできるようにするとそれっぽいツールになると思います。
また、サンプルが全部合ってたら自動でコードを提出できるともっと便利になると思います。スクレイピング前にログイン処理を書いてなんやかんやするとできるみたいです(よくわかってない)。
ここまで読んでいただきありがとうございました。