この記事は アイマストドン内非公式「ジョンベベベント・カレンダー」 Advent Calendar 2017の12日目の記事です by ke_odakyu9000
今日で折り返し!半分!!!アイマス成分入れたかったけど消えちゃった!!!ごめん!!!
前日の方:Nepさん:デレステ創作譜面について
翌日の方:WakuwakuPさん:jsはいいぞ(P名刺について)
まえおき
当方、プログラミングはC++を1年間ぐらいしか触ったことない
かつ
Pythonに関してはこれがはじめて
という人なのでぐっちゃぐっちゃで見にくいかと思いますがご承知おきください・・・
(ここへの投稿も初めてだったり)
備忘録も兼ねているのでかなり長いです。飽きてしまったらぶっ飛ばして適当に読んでください
それと間違いがあればどんどん編集リクエストをください。お願いします。
動機
C++でつくってるのはいいけどGUIって難しいなぁ
→気分転換になにか別の言語を学びたい!→最近有名な言語ってなんだろう
→Pythonこれだ!!!→なにができるの?→なんでもできるっぽい
→じゃぁやりたかったけどやれてなかったTwitterAPIで遊んでみよう!
ということで何にも考えずにPythonに触れました
ちなみにですが僕はもうTwitterもMastodonもStreamじゃないと落ち着かなくなってるのでとりあえずStream取得したい思いが最初から強かった気がします
作ったもの
- TwitterにPOSTする(普通のツイート)
- TwitterのUserStreamを取得する(勝手に流れるTLのアレ)
- 任意のキーワードに一致するツイートをリアルタイム検索する
事前準備
1.Pythonのプログラミング環境を構築する
詳しい方法は公式が日本語のドキュメントを出しているので省略
これがものすごいわかりやすいのでさほど迷わずに構築できました
2.ライブラリのインストール
今回はRequests-OAuthlibをメインに扱っていきます
同GitHubに記載してるとおり
pip install requests requests_oauthlib
をやればインストールは終わり
このライブラリは初心者にはさっぱりなOAuthの基本部分を全部カバーしてくれるのです
便利ですねー
3.Twitterの各種APIキーを取得
取得はざっくりこのへんを見てほしいなーと思います
私が気がつかない間に携帯電話の番号の登録が必須になっているっぽいので一時的に登録して取得するのもありかなと思います(Twitterさんや、Developerにも面倒にさせないでくれ・・・)
取得したAPIは一応権限をすべてにしておくことをお勧めしておきます
今回はそこで取得したAPIキーのうち
・ Consumer Key
・ Consumer Secret
・ Access Token
・ Access Token Secret
この4つ全てを使います
書いてみる
1.POST(投稿)を書く
これが自分で作った初めてのpythonプログラムです
CK = '取得したConsumer Key'
CS = '取得したConsumer Secret'
AT = '取得したAccess Token'
AS = '取得したAccess Token Secret'
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# 初期化
from requests_oauthlib import OAuth1Session #一番初めのやつ
import random #ランダムな数字を生成するのに使うmodule
import API #ひとつ上のやつ
# ランダム数字を生成
x = random.randint(1,100)
print (x)
# Twitterへの投稿
url = "https://api.twitter.com/1.1/statuses/update.json" #APIの投稿専用URL
params = {"status":"test"+str(x)} #投稿内容(test"ランダムな数字")
twitter = OAuth1Session(API.CK, API.CS, API.AT, API.AS) #OAuthへの接続
req = twitter.post(url, params = params) #送る情報
if req.status_code == 200: #もしresponseが200(成功)なら
print ("OK")
else: #違ったら
print ("Error: %d" % req.status_code) #エラーコード
解説(自分が詰まったところとか大事な処理だけ)
# 初期化
from requests_oauthlib import OAuth1Session #一番初めのやつ
import random #ランダムな数字を生成するのに使うmodule
import API #ひとつ上のやつ
各種ライブラリ、もしくは参照ファイルをここで定義します
この場合だと上2つがライブラリ、最後がさっきつくったKEYのまとめたファイルです
基本的にこれらを参照するときは
ライブラリの名前.使うもの
(Ex:API.CS/ random.randint(1,100))
みたいに使います
特に自分で生成したファイルの読み取り方法を見つけるのにちょっと苦労したりしなかったり(基本)
# ランダム数字を生成
x = random.randint(1,100)
print (x)
コメントの通りランダムな数字を生成できます
全てのツイートでtestとすると同一ツイートではじかれないようにするために使ってます、運が悪いと同じのが生成されて失敗しますw
他にもrandint()の部分を変更すればいろいろできます
詳しく知りたい方はここが参考になるかとおもいます
最後に何の数字を生成したのか結果をだすようにprint(object)でやっています
# Twitterへの投稿
url = "https://api.twitter.com/1.1/statuses/update.json" #APIの投稿専用URL
params = {"status":"test"+str(x)} #投稿内容(test"ランダムな数字")
twitter = OAuth1Session(API.CK, API.CS, API.AT, API.AS) #OAuthへの接続
req = twitter.post(url, params = params) #送る情報
if req.status_code == 200: #もしresponseが200(成功)なら
print ("OK")
else: #違ったら
print ("Error: %d" % req.status_code) #エラーコード
ここが肝心要のtwitterへの投稿部
urlは自分のやりたいAPIをここから探し当ててプログラムも変えればやりたいことは基本なんでもできます
あとはREST APIをどうにかこうにかして何か情報を送信するならpost, 受信処理ならgetを使いこなしてがんばる感じです
paramには送りたい情報の中身が入ります
POSTを使うときはparamに何を入れるのかで苦戦したりしなかったりします
"status":"test"+str(x)をエラーの出ないように作るのに苦労しました。textに代入するオブジェクトの型はすべてにおいて一致ないといけないと理解するのにすごく時間がかかりました。(今でも結構頭を使うとところだったりします)
2.UserStreamをGETする
そもそも:UserStreamとはなんだという人向け
Mastodonユーザーならおわかりいただけるとは思いますがmastodonでいう左から2番目の"ホーム"にあたる部分で、フォローしてるユーザーの投稿が自動で流れてくるものです
Twitter公式の説明
The Streaming APIs give developers low latency access to Twitter’s global stream of Tweet data. A proper implementation of a streaming client will be pushed messages indicating Tweets and other events have occurred, without any of the overhead associated with polling a REST endpoint.日本語訳
ストリーミングAPIを使うことで、開発者はTwitterにおけるツイートデータのグローバルストリームに低レイテンシでアクセスすることができます。 適切に実装すれば、RESTエンドポイントへポーリングする時のような負荷をかけずに、ツイートやその他イベントが発生したことを示すメッセージをクライアントへ通知できます。 cf:[Twitter 開発者 ドキュメント日本語訳](http://westplain.sakuraweb.com/translate/twitter/Documentation/Streaming-APIs/Overview.cgi)ということで今回は普通の非公式クライアントのような毎度更新する必要のないTLをみれるようにしてみます
UserStram(GET)を書く
API.pyは上述と同じなので省略
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# Initialize
import sys
reload(sys)
sys.setdefaultencoding('utf-8') # デフォルトの文字コードを変更する.
import requests
from requests_oauthlib import OAuth1Session
import datetime, time
import json
import API
# UserStream
twitter = OAuth1Session(API.CK, API.CS, API.AT, API.AS)
url = "https://userstream.twitter.com/1.1/user.json"
params = {}
RLT = 180 #Rate-Limit time (min)
while(True):
try:
req = twitter.post(url, stream=True, params = params)
#Return
print(req.status_code)
if req.status_code == 200:
if req.encoding is None:
req.encoding = "utf-8"
for js in req.iter_lines(chunk_size=1,decode_unicode=True):
try:
if js :
tweet = json.loads(js)
if tweet.has_key("text"):
#jsonのkeyをそれぞれ変数化
Name = (tweet["user"]["name"])
SC_N = (tweet["user"]["screen_name"])
Text = (tweet["text"])
#print
print ('----\n'+Name+"(@"+SC_N+"):"+'\n'+Text)
continue
else:
continue
except UnicodeEncodeError:
pass
elif req.status_code == 420:
print('Rate Limit: Reload after', RLT, 'Sec.')
time.sleep(RLT)
else:
print("HTTP ERRORE: %d" % req.status_code)
break
except KeyboardInterrupt:
print("End")
break
except:
print("except Error:", sys.exc_info())
pass
解説
後半while(True):以降の流れをざっくりフローにしてみました
推測も含んでいるので正確とはいえませんが雰囲気をわかってくれればうれしいです
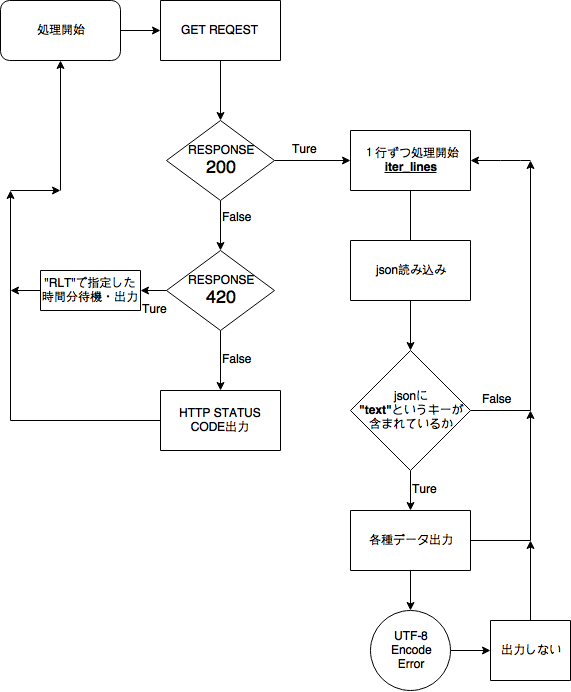
200を受け取った時点で完全に右側のループを永遠に(Ctrl+Cするまで)処理し続けます
この処理の一番大事な部分は
requests.iter_lines()
です。本当は自分で作るべきなのですがrequestsライブラリーでは自動で1行ずつ処理してくれるのでありがたく使わさせて貰います
た だ し
・ 受信するJSONはUnicodeでなければならない
・ データの処理漏れが発生する
という問題つきの処理方法ですがざっくりUserStreamが見れれば満足なのでこのまま公式リファレンスを参考に実装しました(本当はもっとちゃんと処理できるようにしたい)
例外処理とRateLimitについて
except UnicodeEncodeError:
except KeyboardInterrupt:
except:
print("except Error:", sys.exc_info())
でUTF-8の処理エラー、もしくは処理中止を例外処理というよろしくない方法を取っていて改善したいところではあります
Ratelimitの処理
RLT = 180 #Rate-Limit time (min)
elif req.status_code == 420:
print('Rate Limit: Reload after', RLT, 'Sec.')
time.sleep(RLT)
Twitter-StreamAPIにおいてRateLimitの時間がどこにもなく何分待てばいいのかわからないので適当に設定できるようにしてもし420が返されたら指定時間待つ処理をここでしています。
print ('----\n'+Name+"(@"+SC_N+"):"+'\n'+Text)
continue
最後に結果を出力するのですが、
----
ユーザー名(@Twitter_ID):
TEXT
こんな感じのをループするようにしました
で、これの後にcontinueしないと1行目だけ吐き出して終わってしまうことに気がつくのにものすごく時間をとられました。
あとはさまざまな方のソースコードを参考にJSONのkeyの処理の仕方だったり、Python特有のインデントエラーと戦いながらなんとか1週間以内に形をなすことができました
3.ツイートのリアルタイム検索を作る
基本的な部分は先ほど書いたSTREAM.pyとなんら変わらないので変えた部分だけ紹介します
- 初期化に追加
import codecs
sys.stdout = codecs.getwriter("shift_jis")(sys.stdout) # 出力
sys.stdin = codecs.getreader("shift_jis")(sys.stdin) # 入力
後で任意のキーワードを入力できるようにする際にこれがないとエラーの嵐で死にます
- 任意の文字列を入力できるようにする
# 検索ワード登録
print unicode("検索したいワードを入力してください")
print unicode("2つ以上入れる場合は 「,」 で区切って入力してください")
input_word = raw_input(">>> ")
見た目はシンプルなのですがとても曲者なのであとでもう少しだけ詳しく触れます
- URL, 送る情報の変更
url = "https://stream.twitter.com/1.1/statuses/filter.json"
params = {"track": input_word}
URLは検索用のURL、paramsには前で入力した検索ワードを入れてこのワードで検索をかけます
以上を変更してできたコードが以下のとおりです
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# Initialize
import sys
reload(sys)
sys.setdefaultencoding('utf-8') # デフォルトの文字コードを変更する.
import codecs
sys.stdout = codecs.getwriter("shift_jis")(sys.stdout) # 出力
sys.stdin = codecs.getreader("shift_jis")(sys.stdin) # 入力
import requests
from requests_oauthlib import OAuth1Session
import datetime, time
import json
import API
# 検索ワード登録
print unicode("検索したいワードを入力してください")
print unicode("2つ以上入れる場合は 「,」 で区切って入力してください")
input_word = raw_input(">>> ")
# UserStream
twitter = OAuth1Session(API.CK, API.CS, API.AT, API.AS)
url = "https://stream.twitter.com/1.1/statuses/filter.json"
params = {"track": input_word}
RLT = 180 #Rate-Limit time (min)
while(True):
try:
req = twitter.get(url, stream=True, params = params)
#Return
print(req.status_code)
if req.status_code == 200:
if req.encoding is None:
req.encoding = "utf-8"
for js in req.iter_lines(chunk_size=1,decode_unicode=True):
try:
if js :
tweet = json.loads(js)
if tweet.has_key("text"):
#jsonのkeyをそれぞれ変数化
Name = (tweet["user"]["name"])
SC_N = (tweet["user"]["screen_name"])
Text = (tweet["text"])
#print
print ('----\n'+Name+"(@"+SC_N+"):"+'\n'+Text)
continue
else:
continue
except UnicodeEncodeError:
pass
elif req.status_code == 420:
print('Rate Limit: Reload after', RLT, 'Sec.')
time.sleep(RLT)
else:
print("HTTP ERRORE: %d" % req.status_code)
break
except KeyboardInterrupt:
print("End")
break
except:
print("except Error:", sys.exc_info())
pass
解説というか**"文字コード"**について
ここまで3つ(実際にはこれ以外にもいくつか)書いてきましたがどれでも頭を悩ませるのが"文字コード"です
はっきりいってこれの処理をどうするのかに一番時間を使ってました
私自身よくわかってないので一番詳しいこちらのサイトを見て貰うほうがよっぽどためになりますし私自身参考にさせていただきました。
特にこれ
print unicode("検索したいワードを入力してください")
print unicode("2つ以上入れる場合は 「,」 で区切って入力してください")
input_word = raw_input(">>> ")
Windows環境のコマンドプロントではどうもデフォルトではShift_jisで文字を扱っているらしく文字コードを変換してやらないと日本語のすべてが文字化けします。(自分で環境を変えている人を除き)
でも出力は明記するだけでどうにかなるでいいんです。
問題は入力。普通にUnicodeで指定すると一文字ずつUnicodeのencodeでエラーだらけになるんです。
そこで回避する方法が
import codecs
sys.stdout = codecs.getwriter("shift_jis")(sys.stdout) # 出力
sys.stdin = codecs.getreader("shift_jis")(sys.stdin) # 入力
これです。荒業ですがコマンドラインで入力に対して処理が必要ならこれで処理しないとエラーの嵐に襲われます(マジでエラーログの嵐です、ループ処理している故)
これについてはこちらのサイトにあったものを使わさせていただきました。ありがとうございます・・・
たぶんこれからもutf-8には頭を悩ませることになりそうです・・・
正直なところ
なんか動作が不安定というかほしい動作をしてくれなくていて
おそらくの原因がstreamAPIの仕様のものじゃないかなぁと思ってたり
キーワードで検索した際にハッシュタグはきちんと拾うのですが文章中のワードは拾ってくれないっぽいんです・・・
これはまた考えてどうにかしたいかなぁと思います(いっそのこと諦めて普通のsreachにしてしまうか)
初めてpythonに触ってみた感想とかまとめとか
Pythonってものすごく手軽
っていうのが一番思ったことです
型がなんだとか文字コードがなんだとかいろいろありましたがすごい楽しかったです
今回はrequestsしか使いませんでしたがさまざまなライブラリがあり、機械学習、サーバープログラミングなどなどなんでも簡単にできるんんだなぁと思いました。先人方に感謝ですね
また、pythonさんものすごく処理が早いことも強みだなと思いました
思った以上にPythonいろんなことができて面白いので今後も何か作っていきたいなぁとか思ってたりします
ここまで長々としてしまいましたがご覧いただきありがとうございました
参考文献
- PythonでTwitter Streaming APIを叩いた話 - nasa9084
- Twitter Streaming APIで取得した内容をJSON形式で書き出す - snofra
- Python で Twitter API にアクセス - yubais
アイマストドン内非公式「ジョンベベベント・カレンダー」 Advent Calendar 2017:
明日はWakuwakuPさん:jsはいいぞ(P名刺について)
以下おまけ、さほど面白くもないので見たい人だけどうぞ
ベベントカレンダー 前日のNepさん:デレステ創作譜面についてをみて:
音ゲーは好きですが自分で譜面作るってやったことないなぁと、これ製作者側の思いとかも感じられたりするのでしょうかね・・・楽しそうではあります
今後やりたいこと:
・PythonでGUIをつくりたい(これもライブラリがあるらしい)
・上に書いたStream検索をどうにか有用性のあるものにしたい
・Twitterの膨大なデータで機械学習やってみたい
最後のStream検索使えないとか言いながらなんで書いたの:
えっとですね、元はアイマス関連のアドベントカレンダーなのでアイマス関連ワードを自由に拾って例えばライブ後の感想をあつめてみたりしたかったんですけど時間と技術的に無理でした
2018/3/3追記
なんかTwitterさんUserStream廃止するとか言ってますね
ここに書いたの意味ないじゃないですか!!!!!(憤怒)