今回AWSが開催しているちょっぴりDeep Diveに登壇させて頂いたので、そこで話したDR対応としてのマルチリージョン対応内容をQitaでも紹介させていただければと思います。
本記事ではAWS上でDR対策を実施した1例として、どのように検討を進め、何を意識してマルチリージョン対応をしたかをご説明します。
はじめに
- この記事の想定読者
- DR対策が必要か考えている方
- これからDR対策を始めようとしている方
- この記事の用語について
-
DRリージョン
- データやアプリケーションをバックアップおよび復元するため䛾地理的なリージョンまた䛿場所を指す。本記事では大阪リージョンを想定している
-
プライマリリージョン
- サービス䛾主要な運用リージョンや本番運用リージョンを指す。本記事では東京リージョンを想定している。
-
事前検討
現在の災害対策の状況を把握する
DR対策を実施する最初として、災害対策の目的をはっきりさせておく必要があります。
また現時点でサービスとして災害対策がどこまで対応できているかなどを整理して把握します。
その上でサービスとしいてマルチリージョン対応が必要かどうかを検討します。
-
災害対策としてのマルチリージョン対応が必要とされる状況
- 関東への直下型大地震
- AWSのデータセンターが全てのAZで一斉に壊滅的なダメージを受ける
- 復旧までの時間が長期間である
- AWSのリージョン障害
- リージョンサービス(※)などが使用出来なくなる
ex. Amazon DynamoDB、AWS Lambda、Amazon S3、Amazon API Gateway、Amazon SQS etc...
- リージョンサービス(※)などが使用出来なくなる
- 関東への直下型大地震
-
マルチリージョン対応をする前に
マルチリージョン対応を検討する前に対応しておくべき災害対策を実施できているか、それでもサービスをマルチリージョンを対応する目的はどのようなものなのかを明確にしておきます。-
実はマルチAZでも結構障害対策してくれてる
- AWS障害の半数はマルチAZで回避出来る場合が多い
- 過去東京リージョンで発生したAWSの障害を振り返っても完全にリージョンダウンするケースは少なく、マルチAZ対応されていればサービス稼働できていたケースは多かった
- 仮に単一AZ障害が発生しても半日程で復旧されている事が多い
- また、単一AZ障害が発生した場合でも数日間に渡って障害が続くケースは少なく、長くても半日程度で復旧されることが多い
-
Well-Architected フレームワークの基本としてマルチAZが記載されている
- AWS障害の半数はマルチAZで回避出来る場合が多い
-
それでもマルチリージョン対応する目的は何かを考える
- サービス稼働率の維持
- リージョン単位の障害への対策
- マルチリージョンを求めるお客様へ応える
自社サービスでは上記理由から、マルチリージョン対応を実施したが、他にも”数分でもサービスが止まることで甚大な被害が発生するようなサービス”や、”定められたSLAなどでサービス稼働率が常にタイトであるサービス”などは障害発生時に対応できる手段として準備しておく価値があると考えられる。
一方でマルチリージョン対応をすることで対応コストや、インフラ維持コストなどがかかってくる。これらを検討し、その上でマルチリージョン対応をする目的は何か、本当に必要かを考える必要がある。
-
-
現在の災害対策の状況を把握する
災害対策の状況を確認し検討する必要があるものを洗い出す- 災害発生時の対応体制
- 対応要員が一局集中していないか
- 災害発生時の安否確認と連絡手段が確立しているか
- 復旧目標
- 復旧までの最低ライン
- SLA/SLOでDR対策の設計方針が変わってくる
- 復旧までの最低ライン
- 監視体制
- 障害が発生してもアラートの通知などが適切に行えるか
- AWSリソースがリージョンサービスに依存していた場合、災害発生時に通知が飛ばない可能性
- 障害が発生してもアラートの通知などが適切に行えるか
- 災害発生時の対応体制
以下は担当しているサービスの災害対策の状況を洗い出した一例になります。
| 検討項目 | 詳細項目 | 現在の状態 |
|---|---|---|
| 災害時の対応体制 | 対応要員 | - 関東と福岡に要員が存在 - 安否確認システムによるメンバーの安否確認 |
| 復旧目標 | 復旧最低ライン | - SLO 99% (直近1年稼働実績 100%) - 目標復旧時点 1日 (RPO) - 大規模災害時でも SLOの数値が計算される |
| 監視体制 | 災害時のアラート通知 | - リージョンサービスに依存していないアラート通知 |
これらの洗い出しを行なった上で、担当サービスではリージョン災害が長期化した場合に備える目的として、マルチリージョン対応を実施しました。
アーキテクチャ設計
AWSのディザスタリカバリ (DR) のリカバリの戦略では4つのアーキテクチャが提唱されています。

- Backup&Restore
- データリソースのみDRリージョンにバックアップし、それ以外のリソースは障害発生時に構築
- Pilot Light
- データリソースと一部リソースのみDRリージョンに構築し、サービス自体はアイドル状態
- Warm standby
- プライマリリージョンと同様にDRリージョンにリソースを構築するが、アプリケーションリソースの最小限にとどめる
- Multi-site-active/active!
- プライマリリージョンと同様のリソースをDRリージョンに構築
今回紹介するサービスの事例としてはPilot Lightアーキテクチャを参考に対応を進めた
私が担当するサービスでは提唱されている4つのDRアーキテクチャの中から、Pilot Lightアーキテクチャを参考にマルチリージョン対応を進めました。理由としては下記があります。
- コスト
- サービス構成上インスタンス、Application Load Balancer、Nat Gatewayなど常時待機場合コストがかかる構成であった
- 発生頻度と対応時間
- AWSリージョン障害発生頻度、障害発生から復旧まで時間と、移行コストを検討。 移行判断を考慮した場合、 ある程度時間がかかる可能性
- 通常デプロイ時メンテナンス性
- 構成上Warm Standby, active/active構成が不可
- Pilot Light構成場合でもマルチリージョン間で差分を意識して変更やデプロイをしなけれならない構成避けるようにした
Pilot Lightでマルチリージョン対応をする為に
Pilot Lightでマルチリージョンを進めるにあたり、下記を留意して対応を進めました。
- IaC化
- サービス構築時作業の8割程度が元々IaC化されており、今回のDR化で必要な永続層のレプリケート対応や、DRリージョン構築時のパラメータ化のIaC対応が別途必要になった
- 切り替え時にアプリケーション層を構築
- DRリージョン移行時には毎回0からデプロイ機構を構築し、 ネットワークとアプリケーション層の構築を実施する構成とした
- 永続層のレプリケート
- サービスで利用している永続層を洗い出し、 DRリージョンへのデータレプリケートやバックアップの実施
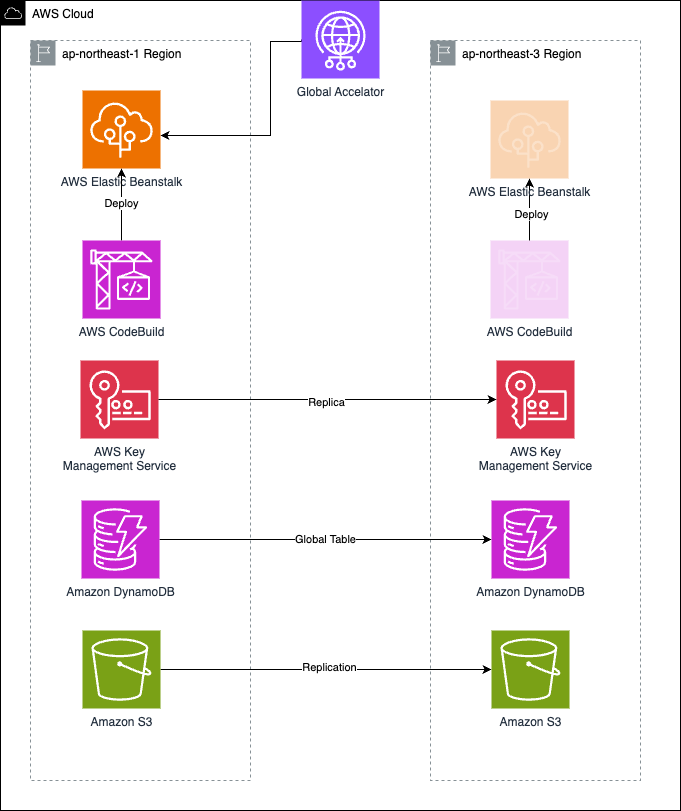
アーキテクチャ設計 - 永続層設計
マルチリージョン対応を進める上で
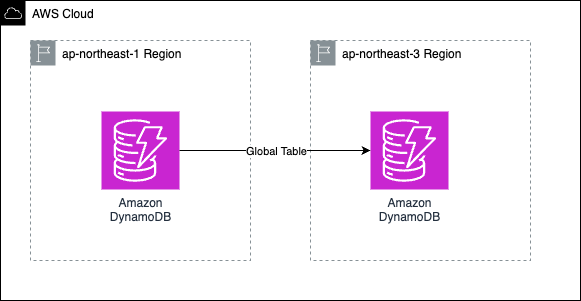
- Amazon DynamoDB
- グローバルテーブルを設定しDRリージョンにプライマリリージョンのデータを同期させる
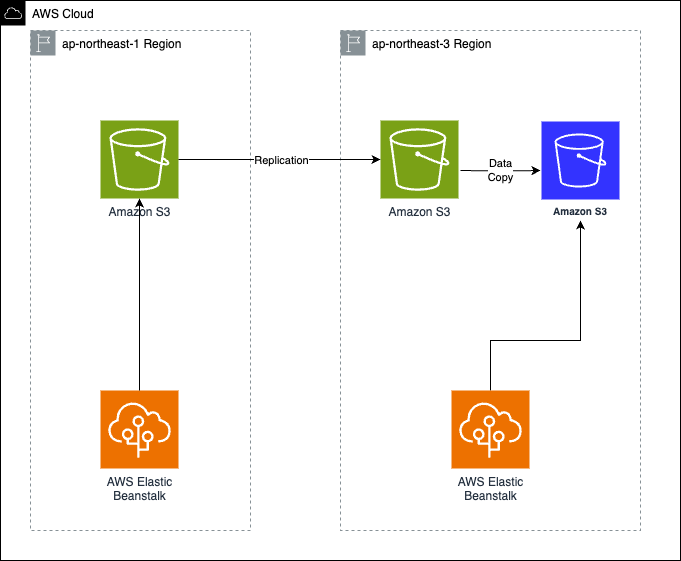
- Amazon S3
- S3もDRリージョンにデータをレプリケーションさせる。 該当箇所は既存のS3バケットの作り直しを避ける為、
レプリケーションバケットを経由する方式にした。
- S3もDRリージョンにデータをレプリケーションさせる。 該当箇所は既存のS3バケットの作り直しを避ける為、
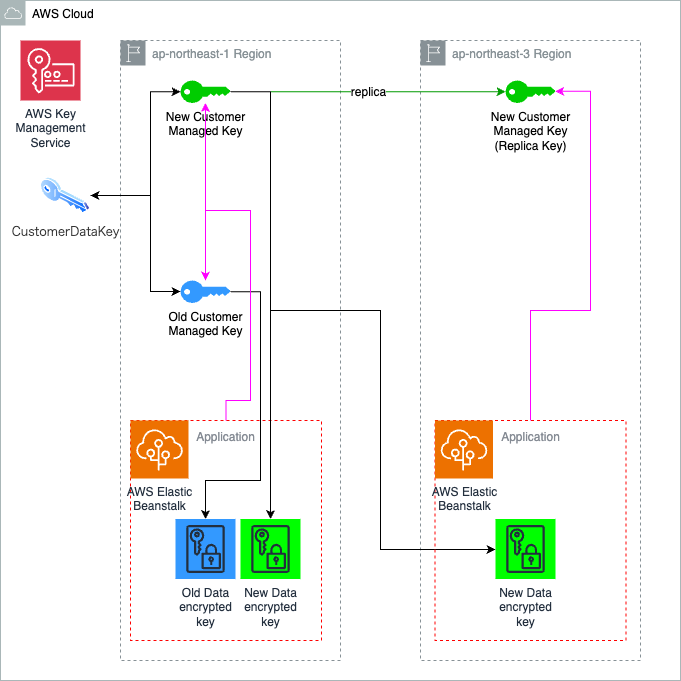
- AWS Key Management Service (AWS KMS)
- マルチリージョン対応前に使用していたAWS KMSのキーは2015年に作成されたキーの為、マルチリージョンキーに対応していなかった。 その為一度キーを作成し直し、データキーを移行した
運用設計
-
いつDRリージョンに移すか(FailOver)
- 条件:どのような状態だった場合にDRリージョンへの移行を実施するかの条件を決めておく
-
いつプライマリリージョンに戻すか(FailBack)
- 条件:災害復旧時のプライマリリージョンへの復帰条件を決めておく
FailOver条件
- 構築開始条件:障害発生から6時間以上プライマリリージョンでサービス利用出来ない障害(※)が継続しており、復旧の目処が立っていない場合
- 移行条件 :障害発生から12時間以上プライマリリージョンでサービス利用出来ない障害(※)が継続しており、復旧の目処が立っていない場合
(※ )ユーザーが障害によってサービスを利用した業務が実施出来ないこと
ex. APIの接続や、管理画面へのアクセスが出来ない等
(構築・移行時共に) AWSサポートに連絡し、 AWS側で復旧の目処が立っていないことを確認する
FailBack条件
- 移行条件 :DRリージョン移行後、プライマリリージョンが完全復旧した翌営業日以降に
プライマリリージョンへの移行作業を実施
AWSサポートに連絡し、 AWS側で復旧が確認できていることを確認する
運用設計
- 緊急時対応計画ガイド
- 緊急時の対応計画を規定する
- 災害発生時にはDRリージョンへの移行、インシデント連絡など、都度判断をして行動をしなければならない
- 災害時に判断基準となるガイドブックを用意しておく事で、災害の混乱時に誤った判断リスクの軽減や、知識の俗人化などを防ぐ事が出来る

緊急時対応計画ガイド
手順緊急時対応ガイドでの手順
| # | ステップ | 概要 |
|---|---|---|
| 1 | 安全確保 | 自身含めた安全確保を行い定められた安否報告を行う |
| 2 | インフラ状況把握 | 作業端末とインターネットが利用できるか確認する ※利用できない場合は、災害対策本部に指示を仰ぐ |
| 3 | チーム担当者状況確認 | チームとしての業務が可能か確認及び報告をする |
| 4 | 本番環境状況把握 | 作業可能な人員を把握した上で、各種監視ツール等を用い 本番環境の状況を把握する アベイラビリティゾーンの利用可否を確認する 東京リージョン自体が利用不可の場合は、RedBookを参照 |
| 5 | 状況共有 | 把握した状況を、サービス関係者へ報告する その後、Newsサイトを通じ状況を周知する |
| 6 | 本番環境の復旧 | FailOver条件に該当する場合、手順書に従いDRリージョンへの構築作業を実施し、移行する FailBack条件を満たした場合、手順書に従いプライマリリージョンへの移行作業を実施する |
| 7 | 運用基盤の復旧 | 監視の復旧、運用基盤の復旧 復旧後環境に対する下記作業可否の確認 オートリカバリー、適用(migration、war)、DBバックアップ、CloudWatchでのログモニタリング |
災害訓練
BCPテストの実施
- 大規模災害想定のBCPテスト
- 大規模災害を想定した年1回のBCPテストを実施
- DR対応や、移行時の規定を決めていても災害時にどのように動くべきかを訓練しておく必要がある
- BCPテストを実施することで課題点も見えてくる
参照
-
well-Architected for Startups -信頼性の柱- 導入編
https://aws.amazon.com/jp/blogs/news/disaster-recovery-dr-architecture-on-aws-part-1-strategies-for-recovery-in-the-cloud/ -
AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略
https://aws.amazon.com/jp/blogs/startup/techblog-well-architected-reliability-1/#02