はじめに
こんにちは、京セラコミュニケーションシステム 川村(@kccs_takahiro-kawamura)です。
前回(LLM時代に必須!?トレーニングジョブを管理するSlurmのセットアップ手順)に引き続き、Slurmについて記載します。
今回は、前回作成した環境で簡単なジョブを実行する手順と注意点を紹介いたします。
本記事は2024年12月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
本記事の対象者
- Slurmでジョブ管理を検討している方
本記事におけるサーバー構成
以下の図のようなサーバー構成を前提に記載します。
また、サーバーのOSはUbuntu 24.04LTSを使用します。
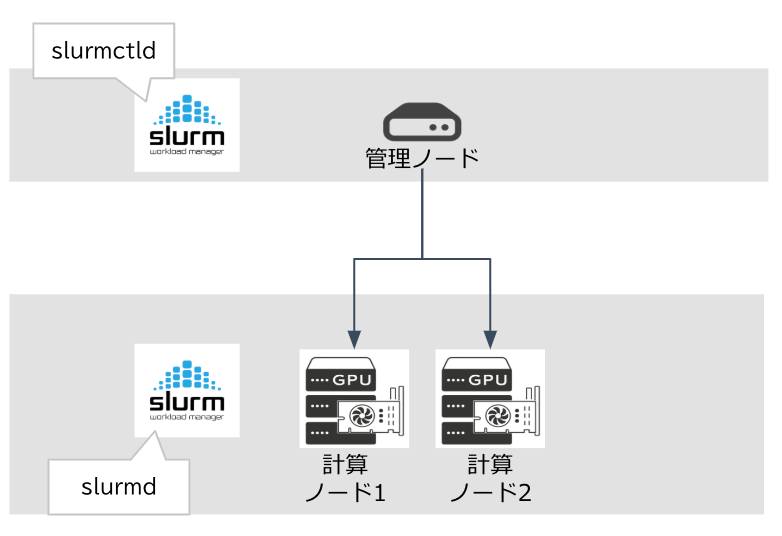
管理ノード
Slurmのクラスターとジョブを管理するサーバーです。
slurmctldが動作します。
計算ノード
Slurmのジョブを実行するサーバーです。
slurmdが動作します。
ジョブの準備
ジョブを実行するためには、ジョブの内容を記載したシェルファイルを用意する必要があります。
今回は下記のようなジョブにしたいと思います。
#!/bin/bash
#SBATCH -J job
#SBATCH -o output/output.txt
#SBATCH -e errors/errors.txt
#SBATCH -p debug
#SBATCH -n 1
python3 job.py
sleep 30
このシェルファイルはジョブを送信する 管理ノード に作成してください。
#SBATCHと書いてある部分はジョブ実行時のオプションです。
-J: ジョブの名前を指定します。
-o: ジョブの標準出力を保存するパスを指定します。
-e: ジョブの標準エラーを保存するパスを指定します。
-p: ジョブを実行するパーティションを指定します。
-n: ジョブの実行に使用するノード数を指定します。
ジョブとしては、job.pyというPythonファイルを実行しています。
こちらは下記のような内容にしたいと思います。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
print(‘hello world’)
このPythonファイルのようなジョブの実態として実行するものは、 計算ノード に作成してください。
これらを合わせて、ジョブの実行結果としては
hello worldと記載されたファイルがoutput/output.txtに
エラーが発生していた場合は、エラー内容が記載されたファイルがerrors/errors.txtに作成されます。
シェルファイルの中に記載したパスが相対パスの場合、
管理ノードでジョブを送信したユーザーと同名のユーザーが計算ノードで必要であり、そのユーザーのホームディレクトリが参照されます。
ジョブの実行
ジョブの実行はsbatchコマンドで行います。
$ sbatch job.sh
これで計算ノードでジョブを実行するように指示が送信されています。
送信されたジョブの状態やどの計算ノードで実行されているか確認する場合はsqueueコマンドを使用します。
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
30 debug job qiita R 0:19 1 slurm-compute-01
ジョブの実行が完了するとsqueueコマンドの結果に表示されなくなります。
まとめ
今回は、簡単なジョブの例を用いてSlurmでジョブを実行するための準備と実行方法について記載しました。
ジョブの実態となるプログラムを毎回計算ノードに配置するのは手間なので、シェルファイルの中でダウンロードしたりするのも1つの手だと思います。
皆さんもこれを機にSlurmでジョブの管理をしてみましょう!
次回の記事もお楽しみに!
おしらせ
弊社X(旧:Twitter)では、Qiita投稿に関する情報や各種セミナー情報をお届けしております。情報収集や学びの場を求める皆さん!ぜひフォローしていただき、最新情報を手に入れてください😄