生産設備の稼働データを外部から取ってみよう(ネットワーク編)
京セラコミュニケーションシステムの大山です。
前回、生産設備の稼働データを外部から取ってみよう[ローカル編]で点灯と点滅を京セラIoTゲートウェイKC4-C-100A(以降、KC4と称します)で1/0認識させました。今回はLTE通信でSORACOM経由でGoogleCloudPlatform(以降、GCPと称します)に稼働データを送信してみたいと思います。
この記事の対象者
設備稼働データを取りたいけど設備の中から線を引き出すのはちょっといやだな・・・という方
設備稼働データ取りたいけどPLCのプログラムはいじりたくないよ・・・という方
メンテナンスの停止ができない生産設備をお持ちの方
デジタル化担当になったが何から始めていいか分からない方
積層信号灯から設備稼働データをとるまでの経路
今回から実際に積層信号灯から光センサーを使用して点灯/消灯/点滅のステータスをデジタルデータ化してみたいと思います。
まずは大まかなデータの流れについては以下となります。

今回は上図の赤線で囲っている部分光センサでとらえた積層信号灯の点灯/消灯の情報をSORACOM経由でGCPのBigQueryに送るところまで作ってみます。
KC4のブロックプログラム
前回記事で作成したブロックプログラムのディスプレイ表示部分をデータ取得、JSON形式の文字列変換、HTTPReqestにブロックを置き直したのが以下となります。

流れとしては
1秒ごとにGPI/GPIO端子の状態を見に行き元の状態と比較を行い変化があれば
①時刻を取得
②変化したセンサーを特定してセンサーに合わせた色を取得
③マップ変数に時刻・色・端子の状態を格納
④文字変数にマップ変数をJSON形式の文字列でセット
⑤HTTPRequest
として信号灯の変化点に合わせて送信の動作を行います。
※HTTPRequestのブロックについては通信プロトコル編① と KC4のサンプルレシピを参考に作成してます。
CloudFunctions
CloudFunctionsが今回GCP側の窓口となるのでSORACOM Beamで設定した内容と合わせる必要があります。
関数の作成ボタンを押して関数の作成に入ります。
関数名は任意の関数名を入力リージョンは任意のリージョンを選択(今回はasia-northeast1(東京)を選択)他はデフォルト設定です。

上記基本設定をすると
https://リージョン名-プロジェクト名.cloudfunctions.net/関数名でトリガーとなるURLが生成されます。
こちらのURLがSORACOM Beam設定の際の転送先となります。
このトリガーによってKC4からの送信されたJSONデータをPub/Subに送る関数を実行させます。
続いて関数の内容としては以下です。
from google.cloud import pubsub_v1
from flask import Response
import json
def main(req):
try:
# json取得
request_json = req.get_json()
# ヘッダー認証情報取得
header_auth = ''
if '任意のヘッダー名' in req.headers:
header_auth = req.headers['任意のヘッダー名']
print(header_auth)
# 認証情報
auth_string = "任意の値"
if header_auth != auth_string:
return Response(response=json.dumps({'message': 'Unauthorized'}), status=401)
# jsonの中身
print(request_json)
# プロジェクトID
PROJECT_ID = "任意のプロジェクトID"
client = pubsub_v1.PublisherClient()
# トピックID
topic_id = "任意のトピックID"
# Pathの設定
topic_path = client.topic_path(PROJECT_ID, topic_id)
print(topic_path)
message = request_json
# ↓↓↓メッセージの名前はKC4ブロックコードのマップ変数のkey名と合わせる
device_code = message['device_code']
timestamp = message['timestamp']
color = message['colorST_send']
ls1 = message['ls1_send']
ls2 = message['ls2_send']
ls3 = message['ls3_send']
pubsub_message = {'device_code': device_code, 'inserted_at': 'AUTO', 'values': [{'timestamp': timestamp, 'color': color, 'ls1': ls1, 'ls2': ls2, 'ls3': ls3,}]}
# エンコード
data_str = json.dumps(pubsub_message)
print("JSON-encoded message:\n{data_str}")
data = data_str.encode("utf-8")
# プッシュする
client.publish(topic_path, data)
return "Success!"
except Exception as e:
print('Exception Error' + e)
return
JSONデータ取得後ヘッダー情報を比較し問題なければPublisherが受け取れる形にエンコードしてPUSH送信する内容となります。
今回はお試しということでソースコード内に決め打ちのパスワードを書いてますが本来はパスワードとなる値をソースコード内にベタ書きするのはNGです。ハッシュ化してパスワード管理する等、考慮が必要となります。
Cloud Dataflow
テンプレートからジョブを作成ボタンを押して任意のジョブ名を入力、リージョンは"asia-northeast1(東京)"を選択してます。
Dataflowテンプレートは"Pub/Sub Subscription to BigQuery"を選択
Pub/Sub input subscriptionはprojects/プロジェクトID/subscriptions/任意の名前を設定
BigQuery output tableは任意のテーブルを設定
※BigQueryで設定するプロジェクト名、データセット名、テーブル名と合わせる必要があります。
一時的な場所はgs://任意の名前/temp/で設定

Pub/Sub
サブスクリプションを作成ボタンを押して登録名とトピックの名前を入力し他はデフォルト設定でCREATEボタンで作成します。
登録名はprojects/プロジェクトID/subscriptions/任意の名前
※登録名はCloud DataflowのPub/Sub input subscriptionと合わせます。
トピックの名前はprojects/プロジェクトID/topics/トピックID
※CloudFunctionsのソース内のPROJECT_IDとtopic_idに合わせます。

BigQuery
プロジェクト名右横の「︙」縦三点リーダーを押してデータセット作成画面にて任意のデータセットIDとデータのロケーション(東京リージョン)を設定しデータセットを作成します。

データセット作成後プロジェクト名左横の▼を押してノードを展開すると作成したデータセットID名が現れます。同様に「︙」を押してテーブル作成画面に移ります。送信先のテーブルに任意のテーブル名を入力します。他はデフォルトです。
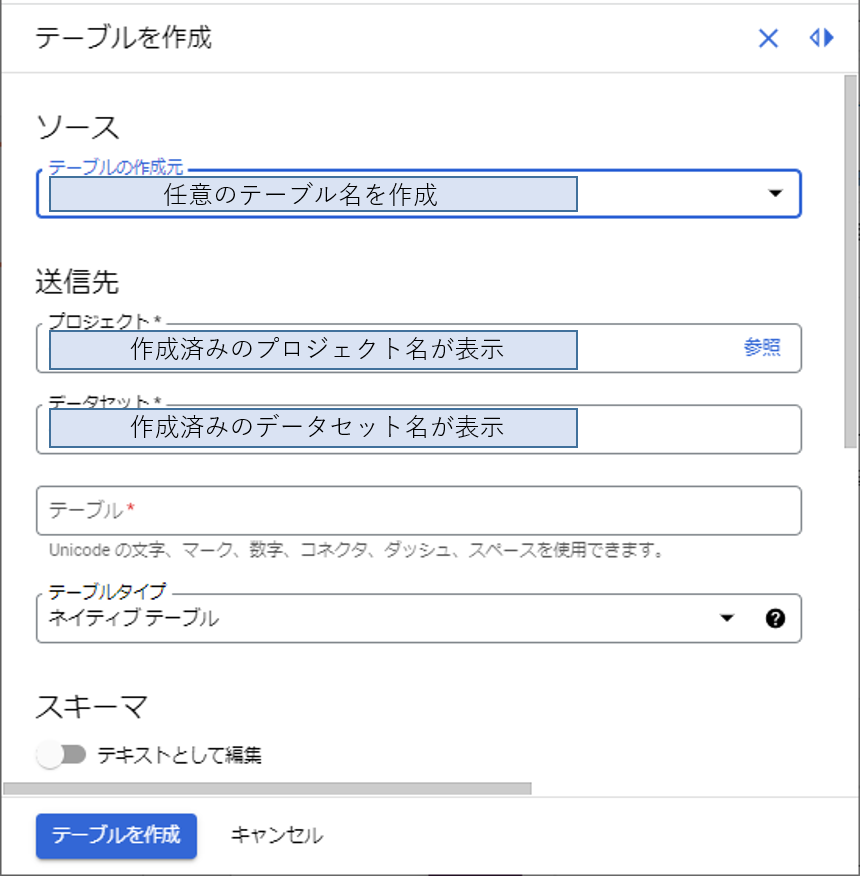
次にスキーマの設定ですが、CloudFunctionsのソースコードに記述した名称に合わせてフィールド名を入力します。タイプは送られてくるデータがどういった型のデータかによって設定します。KC4からは文字と数値と時間が送信されるので文字はSTRING、数値はNUMERIC、時間はTIMESTAMPで設定しています。

最後にパーティションとクラスタの設定ですがパーティションは"取り込み時間により分割"と"フィールドにより分割"から選べます。フィールドはスキーマ設定の時のタイプがDATE、DATETIME、TIMESTAMP、INTEGERの型の中から選択します。DATE、DATETIME、TIMESTAMPは年月日時間単位、今回使用しておりませんがINTEGERは開始、終了、間隔の項目が出るので整数の範囲で分割されるものと思います。
今回は取り込み時間により分割で1日ごとを選んでいます。
お試しでデータ量が多くないのが分かっているのでパーティショニングフィルタの”データのクエリでWHERE句を必須にする”のチェックを外してますが、
誤って範囲指定していないクエリを実行して大量のデータを要求して分析の利用料金が上がる事を防ぐために基本はチェックを入れておいた方がいいです。
BigQueryの利用料金について詳しくは以下の記事を参照ください。
BigQueryの料金体系をサクッと解説

詳細オプションはデフォルトのままでテーブル作成ボタンを押して設定完了です。
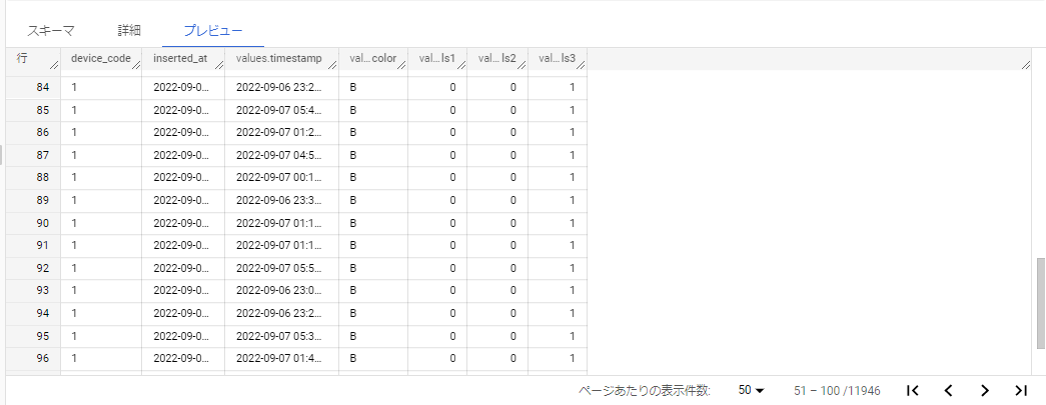
作成したテーブルをクリックしてスキーマタブを見ると以下のような感じになります。

SORACOM Beamの設定
GCPにデータを送信する際SORACOMのSIMを使用します。詳しくはKC4側の設定についてはKC4のSIM設定を、SORACOM側の設定についてはSORACOMの利用を始めるを参照ください。
最後にSORACOM Beamの設定ですがGCPのCloudFunctionで設定したトリガーURLを転送先、ソースコードの任意のヘッダー名・任意の値をそれぞれの欄に入力します。

KC4から送信を行うと以下のようにBigQueryにデータが入ります。
まとめ
各モジュール間で名前を合わせる必要がありこの部分で少しややこしく感じましたがそれさえクリアすればGCP初心者の私でもクラウドサーバにデータを送ることができました。
ということであと少し続きますが、次回はBigQueryに送ったデータをクエリで抽出してLooker Studio(旧DataPortal)に表示させるところを作ってみたいと思います。
※記事に掲載しているスクリーンショットは2022年12月時点となります。