こんにちは、京セラコミュニケーションシステム櫻木 (@kccs_nobuaki-sakuragi)です。
最近はGenerative AIが流行りですが、以前からあるGoogle Cloudで提供されているAutoML Visionについて紹介します。
AutoML Visionのサイトを見ると次の様なサービス終了の案内がでています。
AutoML Visionは、VertexAI AutoML(画像)へと名前が変わっていますが、同じ機能+αで機能はVertexAI AutoMLのメニュー内にあります。

2024年1月23日を過ぎるとAutoML Visionは使用できなくなります。以前のAutoML Visionのすべての機能と新機能は、Vertex AIプラットフォームで使用可能です。
名前が新しくなったVertexAI AutoML(旧AutoML Vision)メニューを使いながら、Google Cloudの画像AIをコードを記述せずモデルトレーニングしたい方向けに複数回にわけ記事を書いてみます。
第1回目はこちらになります。
VertexAI AutoML (画像)を使ってみませんか? #googlecloud - Qiita
第2回目はGoogle Cloud内で実施できるAutoMLのデータ準備・評価や予測についてまとめた記事になります。
本記事は、2023年12月15日時点で作成した記事です
本記事の対象者
- 画像AIに興味のある方
- Google Cloudの画像AIを触ってみたい方
- お試しで画像AIは触ってみたいが、サンプルデータが無く、使えない方
- Google CloudのVertexAI AutoML画像で何ができるか知りたい方
- AutoML Visionから、VertexAI AutoMLへ名前が代わり事例を探している方
Google Cloud VertexAI AutoML とは
ドキュメントでは、Vertex AI AutoMLの項目に次のように記載されています。
機械学習(ML)モデルでは、トレーニング データを使用して、トレーニングされていないデータの結果をモデルが推測する方法を確認します。Vertex AI AutoMLを使用すると、提供するトレーニング データに基づいてコード不要のモデルを構築できます。
VertexAI AutoML(以下AutoML)を利用すると最小限のIT技術の知識と操作でモデル作成およびトレーニングを実施する事ができます。
また本記事では、AutoML(画像)分類について説明します。
AutoMLのデータ準備について
画像のサイズと種類について
AutoML(画像)でトレーニングできるデータと予測できるデータのファイル形式とファイルサイズが異なります。ファイル形式やサイズを意識し画像データを収集する必要があります。
とくに見落としがちなのは、予測する画像データが1.5MBの制限がある事です。
その為、予測時に利用する1.5MBの画像ファイルでディスプレイに表示し見分ける事が可能か確認しておく必要があります。
トレーニング/予測で利用できる画像種別と容量について
| 画像ファイル形式 | ファイル容量 | |
|---|---|---|
| トレーニング | JPEG,GIF,PNG,BMP,ICO | 30MB |
| 予測データ | JPEG,GIF,PNG,WEBP,BMP,TIFF,ICO | 1.5MB |
詳細はドキュメント:分類用の画像トレーニングデータを準備するを確認してください。
なお、ファイル形式や、ファイルサイズを気にしなくて良いパターンは、撮像するカメラや条件がさまざまある場合です。
上記に該当する場合は、実際に予測する画像にあわせ、画像も色々なパターンを含め収集する事をオススメします。
たとえば、撮像するカメラやスマートフォンなどを統一する予定の場合は、画像を集めるところからファイル形式やファイルサイズを決めて置くことという形になります。
画像を集める際に気をつけるポイント
AutoMLで簡単にAI・機械学習ができるようになっても、実際にあつかうデータの質が大変重要です。
そこで、AutoML(画像)で学習用画像を画像を集める際に注意するポイントを纏めます。
AIや機械学習はデータの質が大変重要です。ここを間違うとデータを集める所を何度も繰り返す必要がでてきて、最終的に「AIや機械学習って使えないね。」という話になってしまいます。
なぜ、データの質が重要であるかというと、AIや機械学習が判断する特徴量も人が見てぱっと判別する物とほとんど同じだからです。
とくに画像は用意したデータを人がみても短時間で判別できることが重要です。
その為、本来のラベルや意味と異なるデータ(誤ったデータ・ゴミデータ)や、判別ができないデータ(特徴量が見えにくい)などが含まれていると作成したモデルの精度が下がります。
その為、画像を集める・学習する前に次のような事を意識できているかチェックしていただくと良いと思います。
| 気をつけるポイント | 気をつける背景 |
|---|---|
| 現実世界にある物体の写真利用する | AutoML モデルは、現実世界にある物体の写真に対してもっとも効果的に動作します。そのため、トレーニング用のデータは、現実世界で撮影された写真を使用する。 |
| 予測を行うデータに近いデータを使用する | ユースケースに低解像度のぼやけた画像が含まれている場合、トレーニング用のデータも低解像度でぼやけた画像から構成する必要があります。一般に、複数の視点、解像度、背景を持つトレーニング画像を用意することも検討します。 |
| 人間が割り当てることができるラベルを使用する | AutoML モデルは、人間が割り当てることができないラベルを予測することはできません。人が画像を 1~2 秒間見てラベル判定判別できなければ、モデルもトレーニングすることはできません。 |
| ラベルごとに十分な数の画像を使用する | ラベルごとに約 1,000 個のトレーニング画像をオススメします。ラベルあたりの最小数は 10 です。複数のラベルを使用してモデルをトレーニングする場合は、各ラベル毎に多くのサンプルが必要になります。複数ラベルを使う場合のスコアは、解釈が難しくなります。 |
| ラベルのバランスを考慮する | モデルは、もっとも一般的なラベルの画像数が、もっとも一般的でないラベルの画像数よりも最大で 100 倍存在する場合に最適に動作します。非常に低い頻度のラベルは削除することをオススメします。 |
| None_of_the_above ラベルを使用する | None_of_the_above ラベルと、定義されたラベルのいずれとも一致しない画像を含めることを検討してください。たとえば、花のデータセットの場合、ラベルが付けられた品種以外の花の画像を含め、それらに None_of_the_above のラベルを付けます。 |
私達が製造業の外観検査で利用する場合は、基本的にトレーニングデータと予測データは同じファイル形式、データ容量も同じにしています。
理由は、検査画像は基本的に画像を撮像した条件やカメラが同じである為です。
None_of_the_aboveはモデル作成したけどあまり精度がでない時など、画像分類するには他の物に比べ少ない画像を1つにまとめると精度が上がる場合がありました。
外観検査では白黒つけにく画像や1年に数回しかでない不良画像などもあり、そういった場合にNone_of_the_aboveを使っていました。
データの分割について
一般的な機械学習のフローではトレーニング前にデータを、トレーニング・検証・テスト用分割する必要があります。分割する仕組みをPythonなどで作っておくと手間ではありませんが、初心者であったり、サクッと精度を観たいという人には手間がかかるのが現状です。
Google CloudのAutoMLでは自動的に学習・評価・テストの画像に分割される為、学習データの分割方法や画像に関する知識がなくてもトレーニングに進む事ができこの部分が簡略化されます。
もちろん手動で分割する事もできますので、モデルを精度向上(反復修正)をする場合などは一般的な機械学習のフローと同じ手順で進められます。
AutoMLのモデルの評価と予測の特徴について
AutoMLの評価と予測がGoogle Cloud上で実施できるのが特徴です。
専門知識がなくてもトレーニングとモデル作成、評価までできます。画像を準備すれば、画像モデルをすぐに評価までする事ができるのが特徴です。
AutoMLを利用すると、データを準備し、トレーニングをする。その後、実際のデータについて詳しい専門家にヒアリングしモデル精度を上げる事に注力する事ができます。
AutoMLで作成したモデル評価について
モデル評価指標とは、テストセットに対するモデルのパフォーマンスを定量的に測定する指標です。
評価指標をどのように解釈し、使用するかは、ビジネスニーズや、どのような問題を解決するかによって異なります。
たとえば、偽陽性の許容範囲が偽陰性の許容範囲よりも低い場合もあれば、その逆の場合もあります。このような質問に対する答えは、どの指標を重視するかによって変わります。
AutoML(画像:分類)では、適合率、再現率、信頼度しきい値など、さまざまな評価指標が提供されます。
また、トレーニング後、作成したモデルの評価がGoogle Cloudのコンソールから見る事ができます。
とくに混同行列を見ると、ラベル毎の精度状況がひと目でわかります。

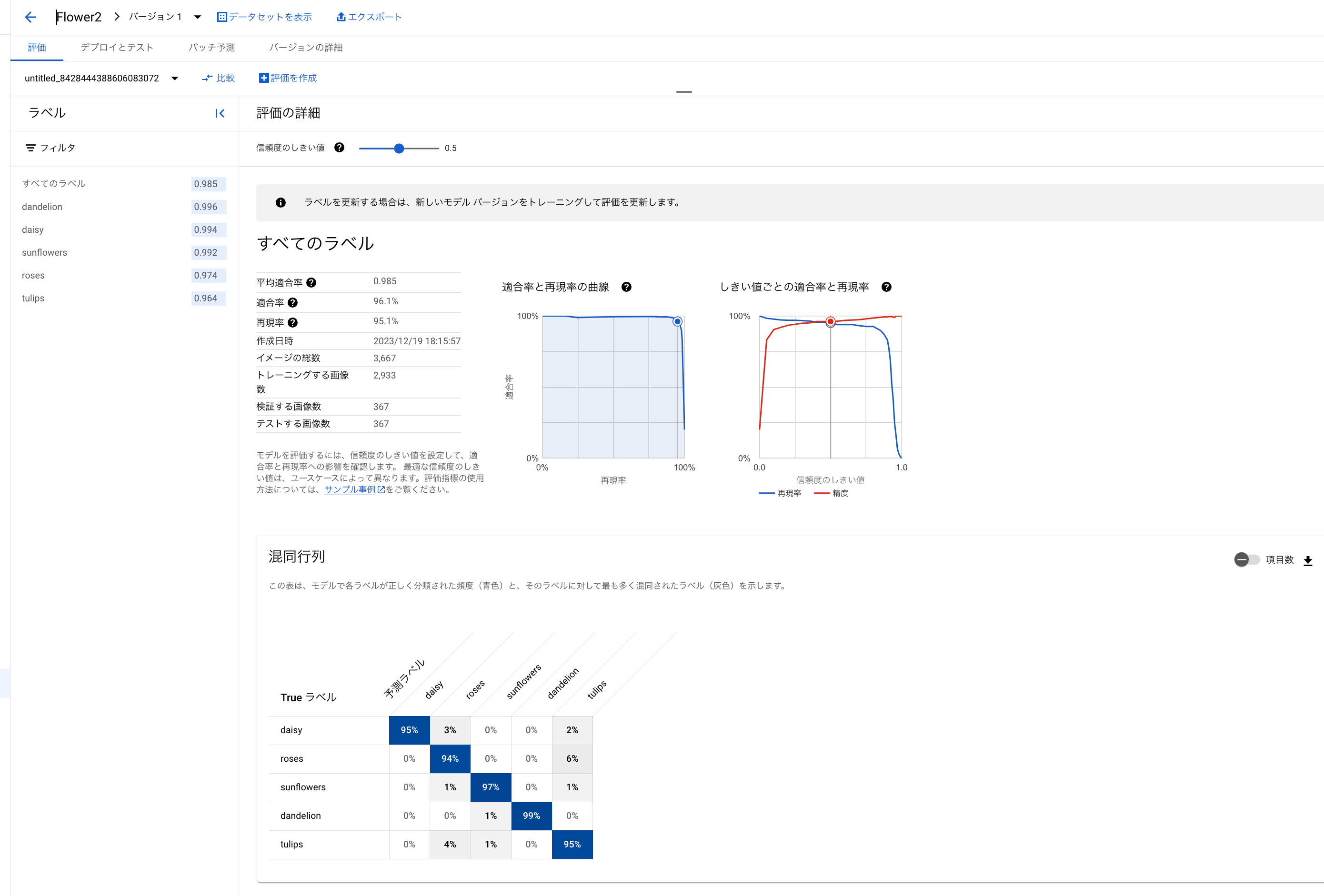
代表的な評価指標は、以下のとおりで、Google Console上でもみる事ができます。。
| 評価指標 | 定義 | 例 |
|---|---|---|
| 適合率 | モデルによって生成された分類予測のうち正しい分類であった割合。 | モデルが猫と犬を分類するタスクで、適合率が 90% の場合、モデルは猫と犬の画像を正しく分類する割合が 90% であることを示します。 |
| 再現率 | このクラスの予測のうち、モデルが正しく予測した割合。 | モデルが猫と犬を分類するタスクで、再現率が 80% の場合、モデルは猫の画像を正しく分類する割合が 80% であることを示します。 |
| 混同行列 | モデルによる予測のうち正しい予測の頻度を示します。 | 混同行列は、行が実際のクラスであり、列が予測されたクラスを示します。正しい予測は、行と列が同じセルに存在します。 |
これらの指標は、モデルのパフォーマンスを評価する際に、さまざまな観点から考慮する必要があります。
より詳しく知りたい場合は、 Googleが無償で提供しているMachine Learning 基礎コース
分類 | Machine Learning | Google for Developersなどが参考になるかと思います。
また、混同行列の項目数のボタンをスライドすると割合で表示されていた物が画像枚数で表示できます。ラベル毎に画像枚数が違う場合は、この赤枠のボタンをスライドすることで、枚数単位で精度の良し悪しを判断する事ができます。左のDaisyをTulipsに誤っている所は2%と表示されていますが、枚数にすると1枚間違っている事がわかります。




精度を上げていく課程をGoogleCloudでは、モデルの反復修正という言葉をつかっています。
モデルの反復修正について詳しく知りたい場合はドキュメントのモデルの反復修正を確認してください。
AutoMLで作成したモデル予測について
Google Cloud内で作成し評価が終わった学習モデルは、Google Cloud内でオンライン予測とバッチ予測を行えます。
作成したモデルをオンライン、バッチですぐに試すことができます。
オンライン予測とバッチ予測の違いは、 「いつ、どのように予測を行うか」 が使い分けをします。
使い方は、モデル作成後にも選択できる為、当初はオンライを考えてたが、夜間にチェックしてもいいかもとバッチ予測へ変更したり、オンラインとバッチモデルを併用するなどする事もできます。
オンライン予測とバッチ予測の使い分けについてです。
オンライン予測 は、リアルタイムに予測を行います。アプリケーションの入力に応じて、すぐに予測結果を返す必要がある場合に使用します。たとえば、ユーザーの行動を分析して、次のオススメ商品を表示するなどの場合に使用されます。
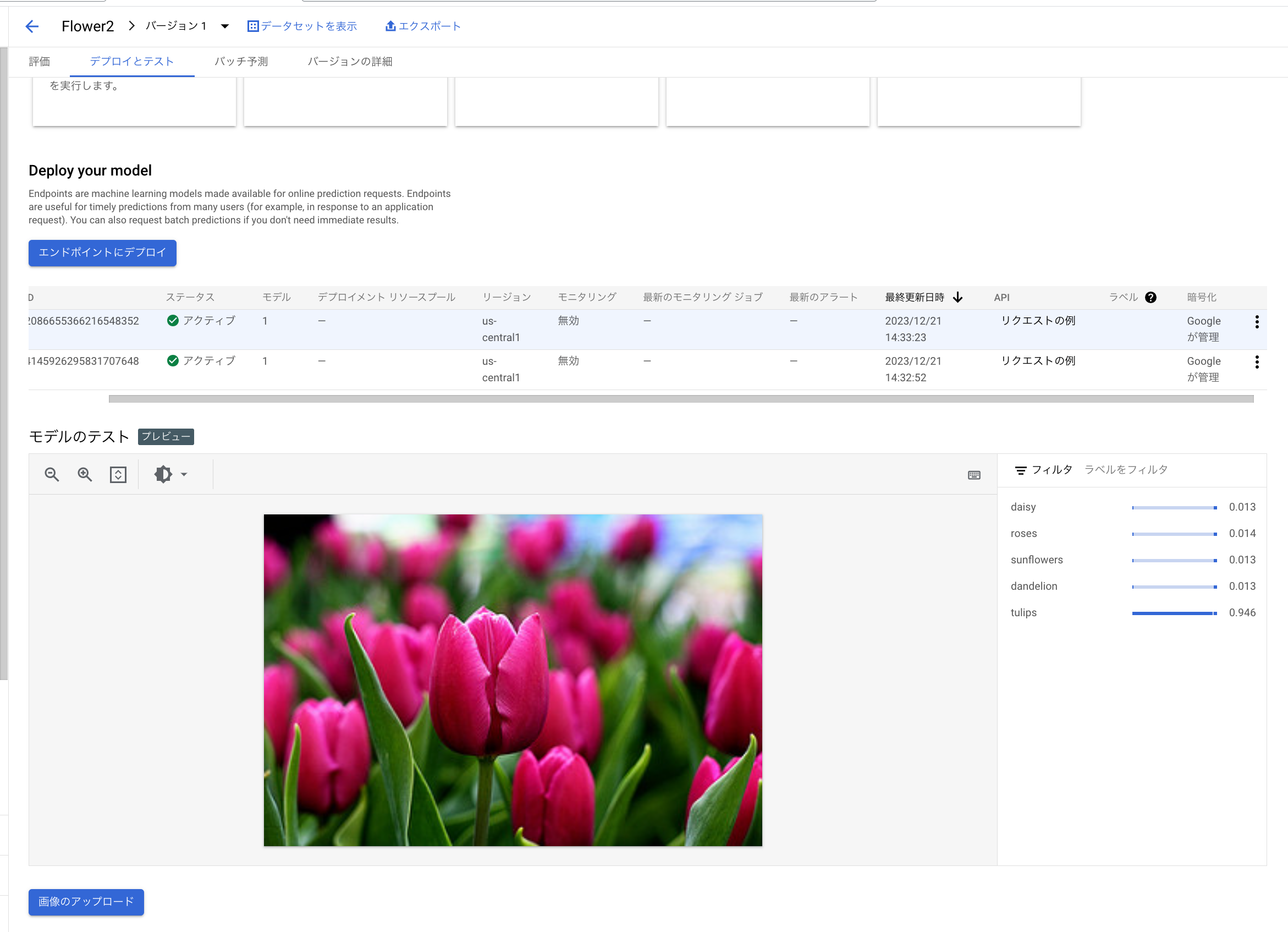
本来はプログラムを作成しオンライン予測をする事が多いですが、Google CloudのConsoleからも実施できますので初心者でも簡単に使うことができます。
オンライン予測をGoogle Cloud Consoleから実施した例

バッチ予測は、一度に大量のデータを処理して予測を行います。すぐに予測結果を返す必要がなく、大量のデータを処理する必要がある場合に使用します。たとえば、画像認識で、画像データの中から特定の物体を検出するなどの場合に使用されます。
オンライン予測とバッチ予測の使い分け
| 項目 | オンライン予測 | バッチ予測 |
|---|---|---|
| リクエスト | 同期 | 非同期 |
| モデルの配置 | エンドポイントにデプロイする | モデルソースから直接リクエストする |
| データ処理 | 1 つのデータに対して予測を行う | 複数のデータに対して同時に予測を行う |
| 使用例 | リアルタイムで予測を行う必要がある場合 | 大量のデータを一括で処理する場合 |
| 具体的な利用シーン | * ユーザーの行動を分析して、次のオススメ商品を表示する * リアルタイムで顧客の問い合わせに応答する * 不正アクセスを検知する |
* 画像認識で、画像データの中から特定の物体を検出する * 顧客の購買履歴から、将来の購買予測を行う * 商品の在庫を予測する |
最後に
本記事ではGoogle CloudのVertexAI AutoML(画像)のデータ準備・評価・予測についてまとめました。
次回以降は、実際の操作について記事したいと思います。
本記事は2023年12月15日に作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
おしらせ
弊社X(旧:Twitter)では、Qiita投稿に関する情報や各種セミナー情報をお届けしております。情報収集や学びの場を求める皆さん!ぜひフォローしていただき、最新情報を手に入れてください![]()