弊社がサービス提供しておりますKCCS APIデータ配信サービス(以下、KCCS-API)では、天気予報、気象予報のデータを取り扱っています。
一方で、気象実績データの取り扱いはないのか、というお問い合わせをいただくことが多いのですが、実績データは取り扱いをしておりません。
今回は、気象データの実績値と予報値の比較をしてみました。
ここでいう「実績値」と「予報値」は下記となります。
| 値の種類 | 取得元 | 取得単位 | 取得形式 |
|---|---|---|---|
| 実績値 | 気象庁のホームページで提供されている過去の気象データ | 日本全国の気象台、測候所、気象観測所、特別地域気象観測所、南極の昭和基地とアメダス観測所単位 | CSV |
| 予報値 | KCCS-APIの過去気象予報データダウンロード機能(※気象庁発表「メソ数値予報モデル」を整形して提供) | 約5kmメッシュ | CSV |
※実績値は、下記気象庁のホームページから取得することが可能です。
目的
気象庁のホームページから取得できる実績値は、予報値のような細かいメッシュ単位での取得ができません。
※参照:https://www.data.jma.go.jp/obd/stats/data/mdrr/man/first.html
そこで、KCCS-APIサービスの「過去気象予報データダウンロード機能」で提供している気象庁発表「メソ数値予報モデル」データの最新の予報値は実績値として近似値にならないのか、というのを検証してみました。メソ数値予報モデルは約5kmメッシュでの予報値が提供されています。
予報値が実績値と近似値になるのであれば、実績値の近似値を細かいメッシュ単位で提供できていることになるのでは!?と考えました。
やり方
-
気象庁の過去の気象データ・ダウンロードHPから3か所の地点のデータをダウンロードする。
- 期間:2021/6、2021/12の2か月分
- 地点:新潟・東京・鹿児島
- データの種類:全天日射量、気温、降水量
-
KCCS-APIサービスの過去気象予報データダウンロード機能を使って、上記の気象観測点の緯度経度のメソ数値予報データをダウンロード。
-
上記1と2のデータを比較する。
注意点
下記の通り、実績値と予報値では、単位及びtimestampの扱いが違うので、データの前処理をする必要があります。
| 項目 | データ(ソース) | timestamp | 単位 | 全天日射量 | 実績値(気象庁) | 前1時間 | MJ/㎡ |
|---|---|---|---|
| 予報値(KCCS-API) | 後1時間 | W/㎡ | |
| 気温 | 実績値(気象庁) | - | ℃ |
| 予報値(KCCS-API) | 瞬時値 | ℃ | |
| 降水量 | 実績値(気象庁) | 前1時間 | mm |
| 予報値(KCCS-API) | 後1時間 | mm |
比較内容
- 1時間単位で比較する。
- 実績値と予報値の比較方法は、決定係数で行う。
コード
サンプルとして、全天日射量を3地点で比較するコードを下記に記載します。
import pandas as pd
import datetime
from sklearn.metrics import r2_score
#実績値を読み込む
jisseki = pd.read_csv('jisseki-data/data_202112.csv')
jisseki['timestamp'] = pd.to_datetime(jisseki['timestamp'])
#実績値の前1時間を後1時間に整形
jisseki['timestamp'] = jisseki['timestamp'] + datetime.timedelta(hours=-1)
#予報値を読み込む
forecast_ = pd.read_csv('jisseki-data/WEATHER_FORCAST_RESULT_202112.csv')
#項目を和名から英名に変更する
forecast_ = forecast_.rename(columns={'日時': 'timestamp', '日射量(W/m^2)': 'isolation', '場所名': 'station'})
forecast_ = forecast_[['station','timestamp' ,'isolation']]
#予報値の整形、地点ごとにカラムを作る
forecast_tokyo = forecast_[forecast_['station'] == 'tokyo'].reset_index(drop=True)
forecast_tokyo = forecast_tokyo.rename(columns={'isolation': 'forecast_tokyo'})
forecast_tokyo = forecast_tokyo[['timestamp' ,'forecast_tokyo']]
forecast_nigata = forecast_[forecast_['station'] == 'nigata'].reset_index(drop=True)
forecast_nigata = forecast_nigata.rename(columns={'isolation': 'forecast_nigata'})
forecast_nigata = forecast_nigata[['timestamp' ,'forecast_nigata']]
forecast_kagoshima = forecast_[forecast_['station'] == 'kagoshima'].reset_index(drop=True)
forecast_kagoshima = forecast_kagoshima.rename(columns={'isolation': 'forecast_kagoshima'})
forecast_kagoshima = forecast_kagoshima[['timestamp' ,'forecast_kagoshima']]
forecast = pd.merge(forecast_tokyo, forecast_nigata, on='timestamp', how='inner')
forecast = pd.merge(forecast, forecast_kagoshima, on='timestamp', how='inner')
jisseki = jisseki.rename(columns={'nigata-isolation': 'jisseki_nigata', 'tokyo-isolation': 'jisseki_tokyo', 'kagoshima-isolation': 'jisseki_kagoshima'})
#実績値の単位をW/m2に変更
jisseki['jisseki_nigata'] = jisseki['jisseki_nigata']*1000000/3600
jisseki['jisseki_tokyo'] = jisseki['jisseki_tokyo']*1000000/3600
jisseki['jisseki_kagoshima'] = jisseki['jisseki_kagoshima']*1000000/3600
jisseki['timestamp'] = jisseki['timestamp'].dt.strftime('%Y-%m-%d %H:%M:%S')
#timestampをキーとして、予報と実績値をマージする
total = pd.merge(forecast, jisseki, on='timestamp', how='inner')
total = total[['timestamp', 'forecast_nigata', 'jisseki_nigata', 'forecast_tokyo', 'jisseki_tokyo', 'forecast_kagoshima' , 'jisseki_kagoshima']]
total = total.dropna().reset_index(drop=True)
#地点新潟の決定係数を算出
forecast_nigata = total['forecast_nigata'].to_list()
jisseki_nigata = total['jisseki_nigata'].to_list()
r2 = r2_score(forecast_nigata, jisseki_nigata)
print(r2)
#地点東京の決定係数を算出
forecast_tokyo = total['forecast_tokyo'].to_list()
jisseki_tokyo = total['jisseki_tokyo'].to_list()
r2 = r2_score(forecast_tokyo, jisseki_tokyo)
print(r2)
#地点鹿児島の決定係数を算出
forecast_kagoshima = total['forecast_kagoshima'].to_list()
jisseki_kagoshima = total['jisseki_kagoshima'].to_list()
r2 = r2_score(forecast_kagoshima, jisseki_kagoshima)
print(r2)
結果
まずは1時間ごとで決定係数を出してみました。
| 対象月 | 項目 | 地点 | ||
|---|---|---|---|---|
| 新潟 | 東京 | 鹿児島 | ||
| 2021年6月 | 全天日射量 | 0.89 | 0.88 | 0.84 |
| 気温 | 0.43 | 0.83 | -0.44 | |
| 降水量 | -0.24 | -5.65 | -2.14 | |
| 2021年12月 | 全天日射量 | 0.83 | 0.97 | 0.94 |
| 気温 | 0.78 | 0.91 | 0.75 | |
| 降水量 | 0.05 | 0.75 | -0.46 | |
全天日射量はかなり良い精度ですが、降水量は全体的に精度が悪い結果となってしまいました。
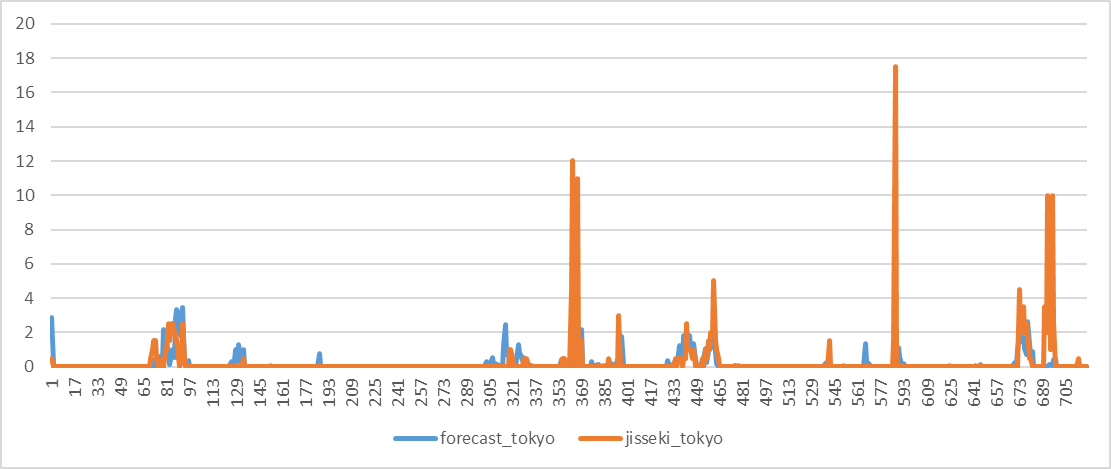
特に精度が出なかった2021年6月の東京をグラフにしてみました。(予測:青、実績:オレンジ)
なんとなく波形は合ってそうですが、波形の大きさが違います。
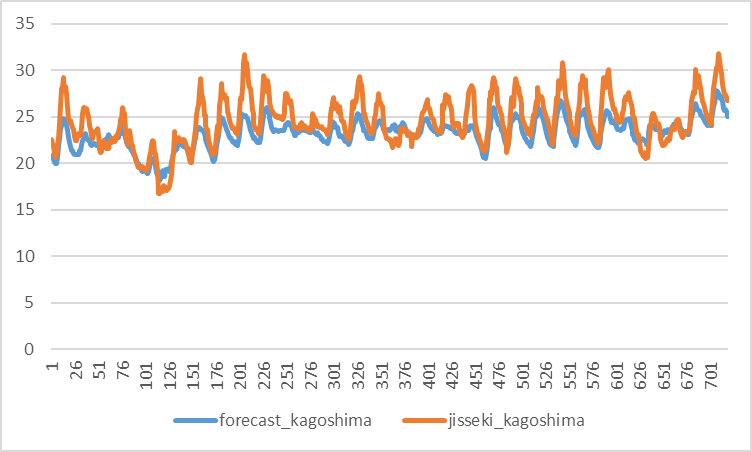
2021年6月の鹿児島の気温についても精度が悪かったので、グラフにしてみました。(予測:青、実績:オレンジ)
こちらもなんとなく波形は合ってそうですが、波形の大きさが違います。
まとめ
以上の検証で下記がわかりました。
これらの特徴を考慮することで、実績値の近似値として、KCCS-APIから取得できる予報値(メソ数値予報値)を利用できるのではないか、と思います。
継続して、他の地点や季節による特徴を見ていきたいと思います。
- 全天日射量は予報値(メソ数値予報モデル)と実績が近しい値である。ただ、値に違いはあるため、例えば明日の日射量予報値から明日の太陽光発電量を予測するようなモデルを作成する際には、過去の日射量実績値と太陽光発電量実績値でモデルを作成するのではなく、過去の日射量予報値と太陽光発電量実績値でモデルを作成した方が良いと考えられる。
- 気温・降水量については、予報値(メソ数値予報モデル)と実績が全ての地点で数値が近しいということはないが、波形は合っている。雨が降ったか降ってないか、というのは一致するが、降雨量は正しく予報が難しいと考えられる。