はじめに
こんにちは、京セラコミュニケーションシステム 森田 (@kccs_kai-morita)です。
先日Google Cloudにて扱える生成AIことPaLM APIがGAになりましたので、Google Cloudのサービスを組み合わせて特定の文章に質問回答ができるAIシステムをデモ的に作ってみました。
:::note info
本記事は2023年6月ごろに作成しております。
:::
この記事の対象者
- Google Cloudにおける生成AIの活用サービスに興味ある方
- 細かい設定やコードなどサービス個別の情報は別途記事を書く予定です。
プロセスの概要
目標は特定の文章(たとえば社内の文章)に対する質問を投げると、その問い対して回答が得られることです。
これは次の2つのステップで実現します。
- 質問文に関連する文章をデータベースから探索する
- 探索した文章をもとに文章生成AIが質問に対する回答を生成する
PaLMは未調節では一般的な質問にしか答えられず、調節は記事作成時点(2023/6/23)ではプレビュー状態のため、質問を検索して得られた文章を元に質問に対する回答を生成するという方式です。
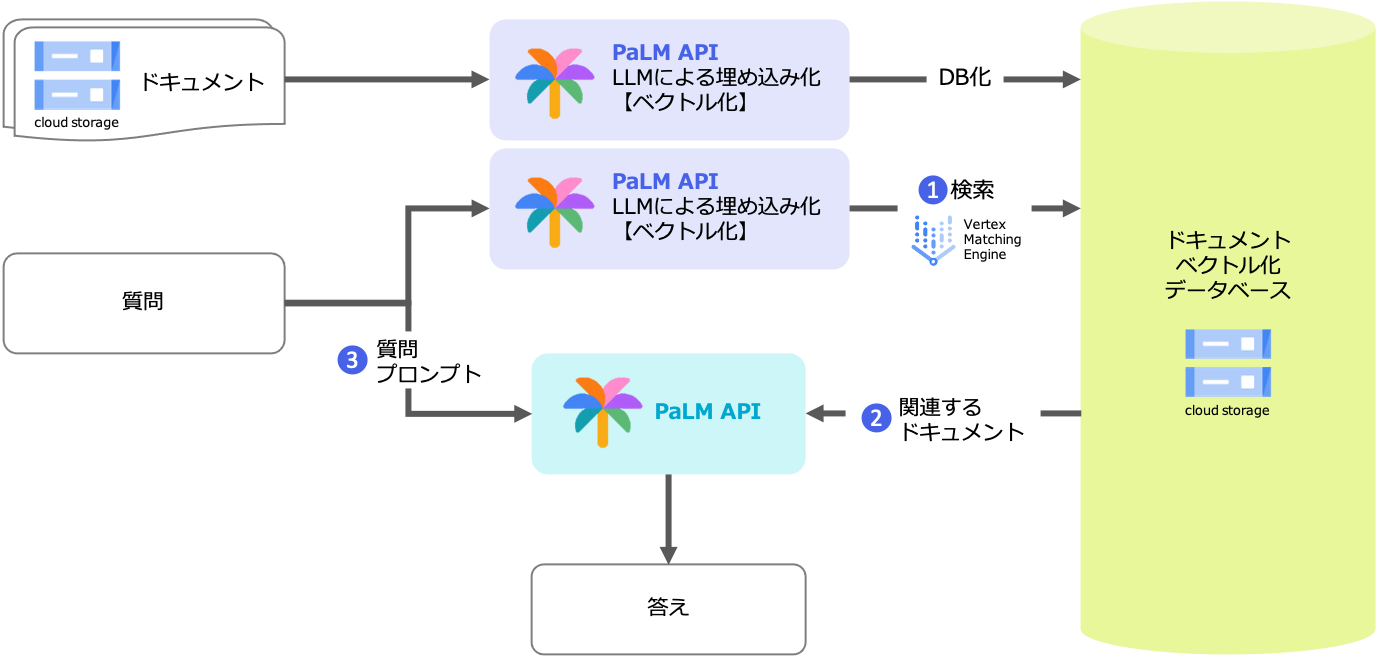
全体図
1. 質問文に関連する文章をデータベースから探索する
文章の探索はセマンティック検索により実現します。
セマンティック検索とは、文章の単なる文字情報に基づく一致度を探すのではなく、文章の意味を把握し、それに基づいて検索結果を提供する技術です。「江戸川コナン」と検索して「工藤新一」がヒットするようなものです(?)。このように文章の深い意味を理解するためには、人間と同様の認識能力が必要、つまりAIが必要となるということですね。
その部分はPaLM APIによりテキスト埋め込みという高密度なベクトル化を行い、そのベクトルがどれくらい類似しているかにより検索を行う仕組みとなります。検索の部分はVertex Matching Engineにより実現します。
VertexMatchingEngineではインデックス(検索先データベース)にはベクトル情報とそれに紐づくIDが設定できますので、IDに文章のファイル名を登録します。
そうすると検索結果に対象の文書が得られるという仕組みです。
[[MatchNeighbor(id='13.txt', distance=0.7408499717712402)]]
ここではidをファイル名としていますが、BigQuery等のデータベースと紐づける方法でも可能です。
2. 探索した文章をもとに文章生成AIが質問に対する回答を生成する
質問をもとに類似した文章をデータベースから検索して、それをベースにPaLM APIに答えてもらいます。
PaLM APIに投げるプロンプトは試行錯誤して以下の形式に落ち着きました。
1. 次のテキストを読んでください。
テキスト:{検索にヒットしたテキスト}
2. このテキストに沿って次の質問に答えてください。
質問:{質問}
また構成図には記載していませんが、記事作成時点(2023/6/23)では英語のみ対応のため、随時Google TranslationAPIにより翻訳しています。
検証してみた
題材
質問対象の文章としては、弊社のQiitaの記事25件としました。
質問は「Vertex AI Workbenchについての記事を書いたのは誰ですか?」と聞きます。
ちなみに構築や検証はVertex Matching Engineと同じVPC上に構築したVertex AI Workbenchで行いました。
検証結果
細かいVertex Matching Engineの構築方法や埋め込み部分のコードは割愛します。VPC周りの設定に苦戦しました・・・。
# 質問
question_ja = "Vertex AI Workbenchについての記事を書いたのは誰ですか?"
question = translate(question_ja, dest='en', src='ja')
# VertexMatchingEngineでベクトル類似度検索をする
embedding = embeddings = emb_model.get_embeddings([question])
res_vme = index_endpoint.match(
deployed_index_id='palm_blog',
queries=[embedding[0].values]
)
# マッチしたファイルをGCSから検索する
match = re.search("id='(.*?)'", str(res_vme))
if match:
filename = match.group(1)
bucket_name = 'バケット名'
folder = 'documents'
source_blob_name = folder + '/' + filename
text = download_blob(bucket_name, source_blob_name)
# 英訳してPaLM APIにプロンプトを送る
text_en = translate(text, dest='en', src='ja')
prompt=f"""
1.Read the context the following context.
context : {text_en}
2.Based on the context, answer the question referred to {question}
"""
response = model.predict(prompt)
res_ja = translate(str(response), dest='ja', src='en')
res_ja
応答結果
'Vertex AI Workbench に関する記事は、京セラコミュニケーションシステムの森田 (@kccs_kai-morita) が執筆しました。'
弊社の記事でVertex AI Workbenchについて書いている記事はこの記事のみですので、成功しました!
おわりに
日本語未対応であることや、Vertex Matching Engineの費用が課題となりますが、このアーキテクチャはさまざまな応用が可能だと考えています。探索対象の文章として社内文章やウェブサイトの記事を活用したり、PaLM API Chat(2023/6/23時点ではプレビュー)を用いて応答を生成することにより社内チャットボットのできあがりです。
また後日Vertex Matching EngineやPaLM APIの細かい仕様の検証やコストについての記事も作成する予定です。