はじめに
こんにちは、京セラコミュニケーションシステムでデータサイエンティストとして従事している森田(@kccs_kai-morita)と申します。
Google Cloudのサービスを活用し、ドキュメントファイルをストレージにアップロードすると、その内容の要約がSlackに自動的に通知されるシステムを構築しました。この記事では、その仕組みを詳しく解説します。
この記事の対象者
- GoogleCloudの基本的なサービスの知識がある人
- PaLMの活用方法に興味ある人
つまりどういうことができるの?
以前投稿したこの記事をPDFファイルに変換してCloud Storageにドロップすると、
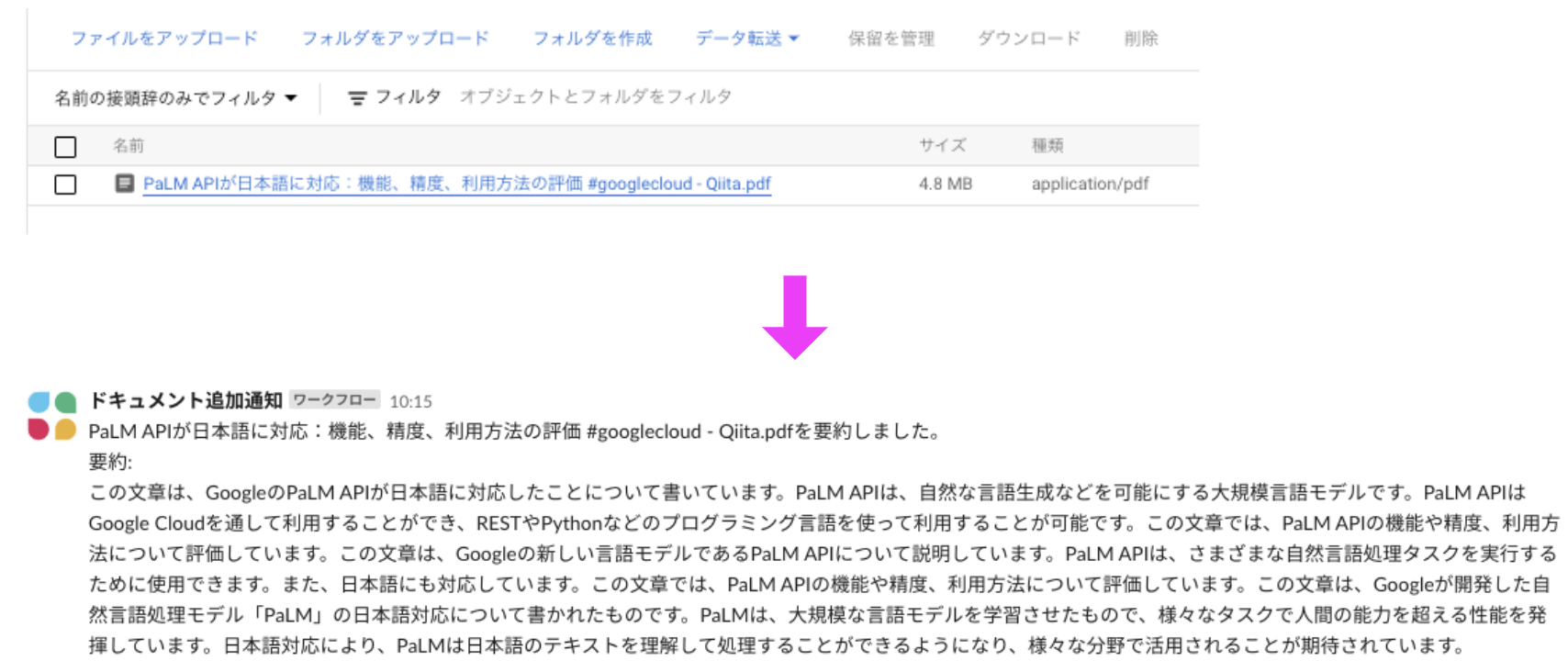 Slackに投稿されたメッセージ
Slackに投稿されたメッセージ
Slackにドロップされたドキュメントの要約が投稿されました!
PaLM2とは
Google Cloudにより提供される生成AI基盤モデルであるPaLM 2はAPIとして利用可能で、自然言語の解析にしたPaLM2 では質問応答やテキストデータの分類といった機能を実現します。これに関しては少し古い内容ですが、以前の記事1で詳細に分析しています。
テキスト用のPaLM2モデルとしては長らく標準的で安定したモデルであるBisonモデルが使用されていましたが、2023年11月末のアップデートで思考連鎖能力が向上してより高度なタスクを処理できるUnicornモデルが導入されました。今回の記事では、この新しいUnicornモデルを使用しつつ前回のモデルとの違いも確認しました。
構成
以下のステップで実現される流れとなります。
- ドキュメントをGoogle Cloud Storageにアップロードする
- ドキュメントのアップロードがトリガーとなり、Cloud Functionsが動作する
- 生成AI PaLM APIを使用して、ドキュメントの要約を作成する
- 作成された要約をSlackチャンネルに通知する
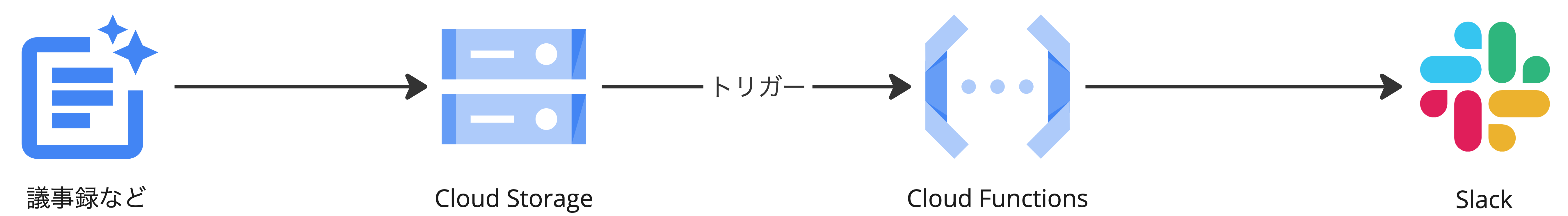 全体構成図
全体構成図
Slack側の設定
Slackでは、事前にワークフローを作成します。
「Webhookから」を選択し、作成されたURLをメモしておきます。このURLにCloud Functionsからリクエストを送ることでSlackへの通知を実現します。
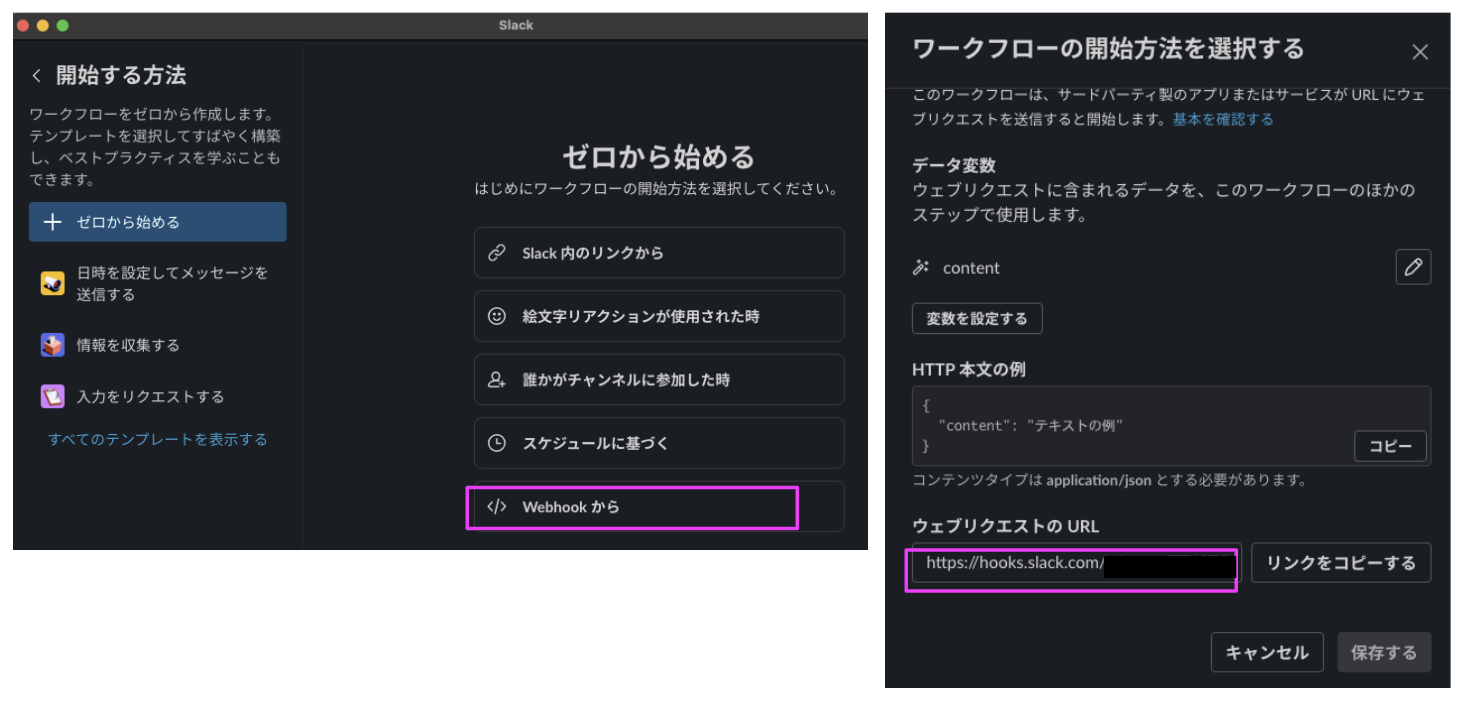 Slack ワークフロービルダー画面
Slack ワークフロービルダー画面
次のステップ設定で、どのチャンネルにメッセージを送信するかを設定します。これで準備は完了です。
CloudFunctionsトリガー設定
Cloud Storageのバケットに新しいファイルが作成されるイベントをトリガーとして、Cloud Functionsが起動するように設定します。
このプロセスでは、APIの有効化とサービスアカウントの権限設定が必要ですが、画面上の指示に従えば簡単に完了します。
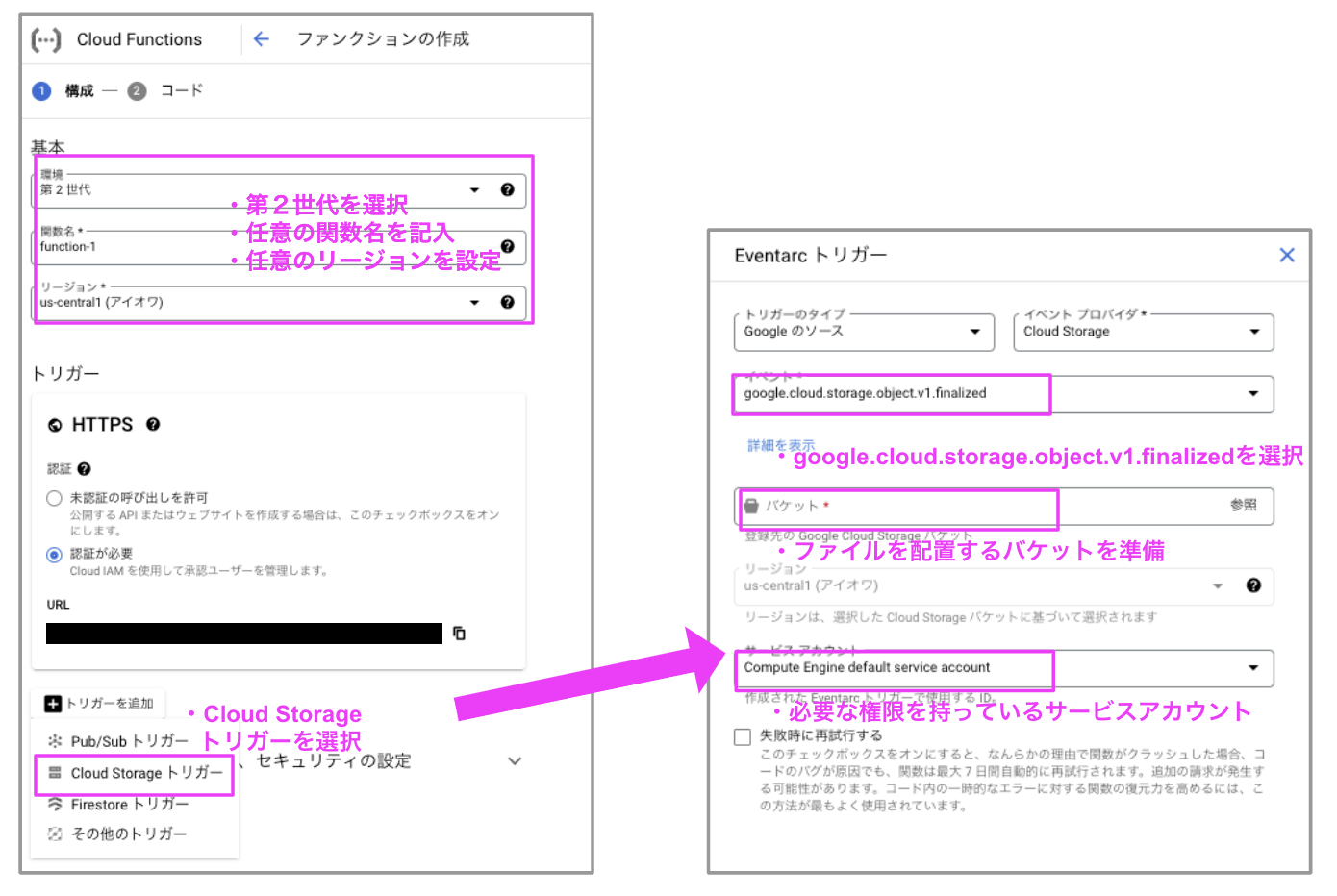 Cloud Functionsトリガー
Cloud Functionsトリガー
Cloud Functionsの実装
Cloud Functionsの実装にはPythonを使用しており、ここではその主要部分を簡潔に説明します。このコードはPython 3.11環境で動作確認済みです。
必要なパッケージは、Google Cloudサービス関連のものとslack-sdkです。
functions-framework==3.*
google-cloud-storage==2.8.0
google-cloud-aiplatform==1.33.1
PyPDF2==3.0.1
langchain==0.0.312
slack-sdk==3.23.0
トリガーを設定するだけではファイルの情報は読み取れないため、PyPDFを用いてPDFファイルを読み取ります。ここをOCRや他のファイル読み取る仕組みに変えることでPDF以外の形式に対応可能です。
from io import BytesIO
from google.cloud import storage
from PyPDF2 import PdfReader
def get_pdf_from_gcs(bucket_name,file_name):
gcs_client = storage.Client()
bucket = gcs_client.get_bucket(bucket_name)
blob = bucket.blob(file_name)
buffer = BytesIO()
blob.download_to_file(buffer)
buffer.seek(0)
reader = PdfReader(buffer)
text = ''
for page in reader.pages:
text += page.extract_text() + "\n"
return text
PaLM APIに送信するプロンプトを設定します。ここではLangChainを用いて実装していますが、Google Cloud SDKを使用しても同様に実装可能です。現在は汎用性の高い簡潔なプロンプトを採用していますが、特定の用途(たとえば議事録)に合わせてプロンプトを調整することで、さらに精度の高い結果が得られます。他にも、音声テキストの誤字や脱字のチェックもできそうですね。
第二のプロンプトは、後ほど説明するトークンの制限に対処するために使用されます。これは、すでに要約されたテキストを集約し、さらに要約することを目的としています。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
text_bison = VertexAI(
model_name='text-unicorn@001',
max_output_tokens=512,
temperature=0.2
)
prompt_summary = PromptTemplate(
input_variables=['content'],
template=""" この文章の要約を作成してください。
文章: {content}
"""
)
prompt_summary_summary = PromptTemplate(
input_variables=['content'],
template=""" 次の文章はあるドキュメントをページ単位で生成AIにより要約されたものです。この文章をまとめてください。
文章: {content}
"""
)
chain_chunck_summary = LLMChain(llm=text_bison, prompt=prompt_summary)
chain_chunck_summary_summary = LLMChain(llm=text_bison, prompt=prompt_summary_summary)
今回の要約対象はPDFファイルの文章全体となるため、APIにすべてインプットするとデフォルトでは1024トークンの入力トークン制限に引っかかります。そこで、LangChainによりチャンクにわけてトークン制限に引っかからないように工夫しました。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = JapaneseCharacterTextSplitterForSurvey(
chunk_size = 900,
chunk_overlap = 5,
length_function = len,
)
response_list = []
response_from_llm = ''
page_text = text_splitter.split_text(file_text)
if len(page_text) > 1:
print('チャンク単位で要約します')
# ページ単位、チャンク単位で要約
for text in page_text:
response = chain_chunck_summary(text)['text']
response_list.append(response)
#応答の統合
response_text = ''.join(response_list)
response_list_all = text_splitter.split_text(response_text)
for text in response_list_all:
response = chain_chunck_summary(text)['text']
response_from_llm += response
print(response_from_llm)
else:
print('全ページ一括で要約します')
response_from_llm = chain_chunck_summary_summary(file_text)['text']
print(response_from_llm)
事前にメモしたwebhook URLに対して、要約された内容を送信する設定をします。
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
response_to_slack = f'{file_name}を要約しました。\n要約:\n{response_from_llm}'
url = '### ワークフローのwebhook URL ###'
req_header = {
'Content-Type': 'application/json',
}
req_data = json.dumps({
'content':f'{response_to_slack}'
})
req = urllib.request.Request(url, data=req_data.encode(), method='POST', headers=req_header)
with urllib.request.urlopen(req) as response:
body = json.loads(response.read())
headers = response.getheaders()
status = response.getcode()
投稿結果を確認する
正常にデプロイされると、設定したバケットにPDFファイルを置くだけで対象のSlackチャンネルなどに送信できます。
ついでにPaLM 2のモデルごとの投稿結果の違いを見てみました。
この記事の要約セクションの画像は、Bisonモデルを使用した結果となります。新しいモデルのUnicornモデルの結果を見てみましょう。
 Unicornモデルによる投稿
Unicornモデルによる投稿
Unicornモデルの結果は、より詳細で包括的であり、多くの情報を提供しているように思われます。とくにAPIの具体的な利用例や詳細な機能に関する情報が含まれています。一方、Bisonモデルの要約は比較的簡潔であり、日本語対応に関する基本的な情報を提供していますが、詳細な利用例や機能についてはあまり触れていません。
Unicornモデルのほうが利用料は高価ですが、より効果的な生成ができそうですね。
両モデルの詳細な比較は今後の記事にする予定です。
おわりに
プロンプトを変えるだけでドキュメントの分析としていろいろ応用できると思います。また、この記事2のようにGoogle DriveとCloud Functionsは連携できるので、Driveへファイル配置するとSlackに生成AIで分析結果を送信とできそうです。