この記事は株式会社ナレッジコミュニケーションが運営するAmazon AI by ナレコム Advent Calendar 2019の17日目にあたる記事になります。

はじめに
AWS re:Invent 2019にてAmazon EC2 Inf1インスタンスが発表されました!
Amazon EC2 Inf1インスタンスは、AWSが設計、開発、をしたハイパフォーマンス機械学習推論チップであるAWS Inferentiaチップを16 基まで利用でき、推論チップを最新のカスタム第2世代インテル® Xeon®スケーラブルプロセッサおよび最大100Gbpsのネットワークと組み合わせることにより、ハイスループットの推論を可能にしました。
簡単にまとめると、AWSで機械学習の推論を実行するのに最適化されたインスタンスです。
AWS Inferentiaチップとは

AWS がカスタマイズした、高パフォーマンスの機械学習推奨チップ
- 高性能
AWS Inferentiaの各チップは低電力で最大128TOPS(1秒間に数兆回の操作)のパフォーマンスをサポートしています。また、AWS InferentiaはFP16、BF16、およびINT8データ型をサポートしています。さらにAWS Inferentiaは32ビットのトレーニング済みモデルを取得しており、BFloat16を使用して 16 ビットモデルの速度での実行が可能です。
-
低レイテンシー
AWS Inferentiaは、大規模なオンチップメモリを特徴としています。このため、大規模なモデルのキャッシュが可能となり、チップ外に保存する必要はありません。この結果、AWS InferentiaのプロセッシングコアであるNeuronコアがモデルへ高速でアクセスでき、チップのオフチップメモリ帯域幅によって制限されないため、推論レイテンシーの低下に大きく貢献します。 -
使いやすさ
AWS Inferentiaには、AWS Neuronソフトウェア開発キット(SDK)が付属しています。これで、複雑なニューラルネットモデルが利用可能となり、AWS InferentiaベースのEC2 Inf1インスタンスを使って実行する一般的なフレームワークで作成およびトレーニングすることができます。Neuronはコンパイラ、ランタイム、プロファイリングツールで構成され、TensorFlow、Pytorch、MXNetなどの一般的な機械学習フレームワークにも統合済みです。このため、EC2 Inf1インスタンスの最適なパフォーマンスが実現します。
Amazon EC2 Inf1インスタンス仕様
以下、Amazon EC2アップデート – 高性能で費用対効果の高い推論のための AWS Inferentia チップを搭載した Inf1 インスタンスで公開されている仕様になります。
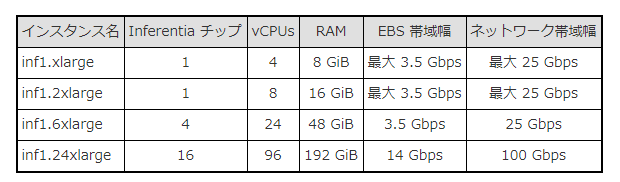
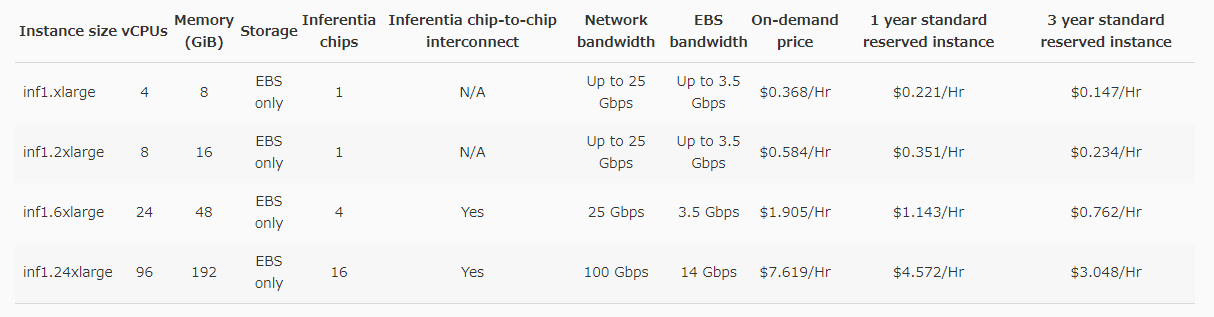
Amazon EC2 Inf1インスタンス価格
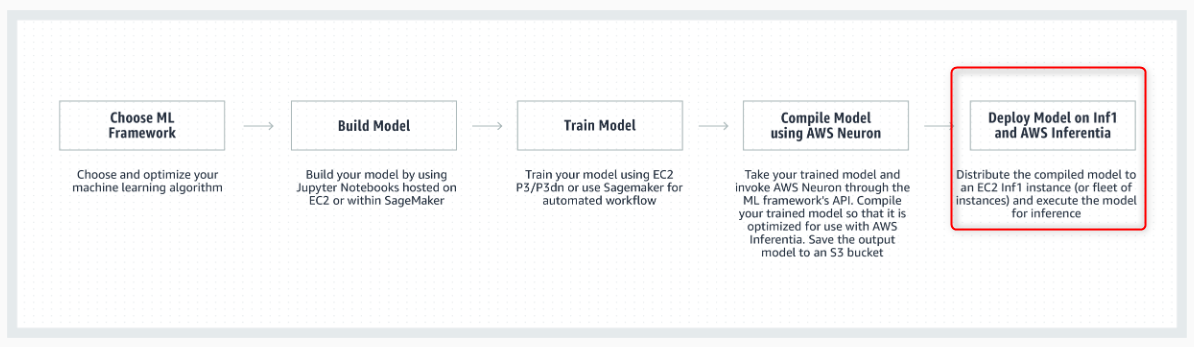
Amazon SageMakerで間もなくAmazon EC2 Inf1インスタンスをサポート
Amazon SageMakerで作成したモデルがAmazon EC2 Inf1インスタンスのAuto Scalingクラスターで複数のアベイラビリティーゾーンに分散してデプロイされ、高いパフォーマンスと可用性が発揮されます。
おわりに
2019/12/17現在、バージニア北部リージョンでEC2インスタンスとしては利用可能です。
Amazon SageMakerで使用可能になったタイミングで改めてご紹介したいと思います。