はじめに
先日投稿した「Pythonで可愛い子の画像集め(Seleniumでスクレイピング)」に関連して、
今度はFlickrAPIを用いて画像収集したので、記事にしてみました。
今回も、コマンドライン引数次第で集める画像を変えられる作りにしています。
Flickrとは
- 写真動画共有コミュニティサイト(https://www.flickr.com/)
- WebAPIが提供されている(FlickrAPI)
- FlickrAPIの利用には「アカウント登録」「アプリケーション作成」「アクセスキー取得」が必要
やりたいこと
- PythonでWebスクレイピングして画像収集
- Python + FlickrAPIで実装
- コマンドライン引数に収集したい対象を指定したら、FlickrAPIで画像をダウンロード
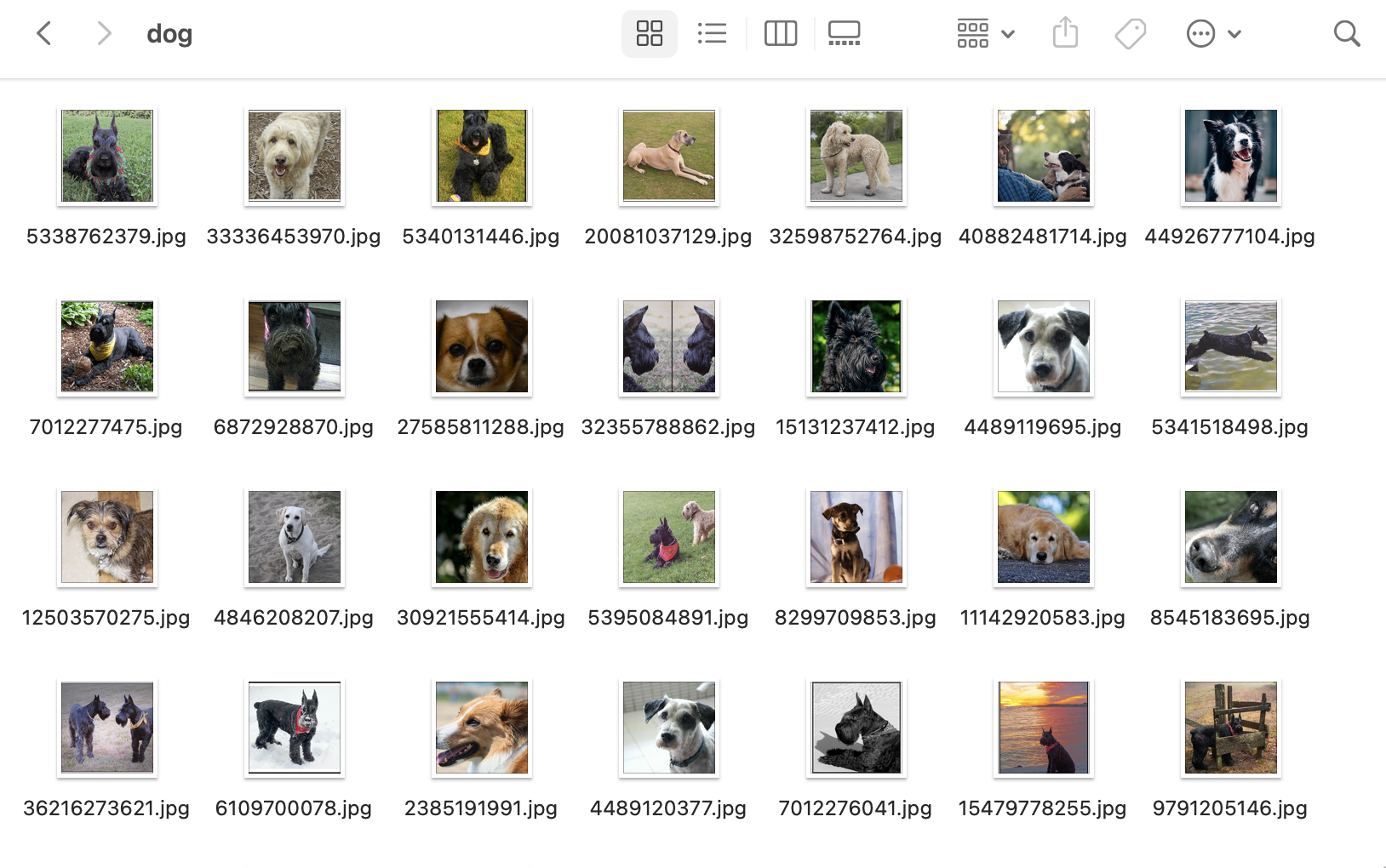
以下のように実行すると、
python XXX.py dog 100
環境
- MacBookPro M1
- Python 3.9.7
- flickrapi 2.4.0
方針
- コマンドライン引数に「収集したい対象」と「ダウンロードする画像数」を指定
- 画像はカレントディレクトリ配下のimages/[収集したい対象]ディレクトリに保存
- 複数回実行すると、前回のものを全削除して、再度ダウンロード
- APIのKeyとSecretはyamlで環境変数にし.gitignoreで管理外へ
注意事項
Webスクレイピングするときの一般的なお話ですが、
- 著作権や利用規約は事前に確認する
- サーバに負荷をかけすぎないよう間隔をあけてアクセスする
- robots.txtも確認しておく
FlickrAPIの準備
1. アカウント登録
FlickrAPIを使うために、Flickr にアカウント登録(サインアップ)する。
2. アプリケーション作成
Flickr Developer Center にアクセスし、アプリケーション登録する。
「Create an App」-「Request an API Key」から「AAPPLY FOR A NON-COMMERCIAL KEY」を選択し、アプリケーション名など入力する。
3. アクセスキー取得
アプリケーション登録すると、「Key」と「Secret」が表示されるので、メモしておく。
FlickrAPIのキホン
1. インストール
pip install flickrapi
2. 使い方
詳しくは Flickr Developer Center 参照。
以下では 画像検索API を使用。
# モジュールのimport
from flickrapi import FlickrAPI
# FlickrAPIのインスタンスを作成
# アクセスキーとシークレットを指定
key = XXXXX # アクセスキー
secret = XXXXX # シークレット
flickr = FlickrAPI(api_key=key, secret=secret, format='parsed-json')
# FlickrAPIで画像検索
response = flickr.photos.search(
text='XXX', # 検索したい文字列
per_page=100, # 画像数(上限500)
media='photos', # 取得するメディアタイプ(今回は画像)
sort='relevance', # ソート順
safe_search=1, # セーフサーチ設定(1でOK)
extras='url_q, licence' # 追加でフェッチしたい情報
)
画像集め(コード)
1. モジュールのインポート
import os
import shutil
import sys
import time
import urllib.request
import yaml
from flickrapi import FlickrAPI
2. api_key.yaml(KeyとSecretを記載した設定ファイル)
API_KEY:
key: XXXXX # メモしておいたKey
secret : XXXX # メモしておいたSecret
3. main処理
def main():
# APIKeyとSecretを設定ファイルから取得
key = ''
secret = ''
try:
with open('api_key.yaml', 'r') as f:
data = yaml.load(f, Loader=yaml.SafeLoader)
key = data['API_KEY']['key']
secret = data['API_KEY']['secret']
except FileNotFoundError as e:
print(e)
exit()
# 引数チェック
target = ''
per_page = 0
try:
target = sys.argv[1]
per_page = int(sys.argv[2])
except IndexError:
print('引数に「収集したい対象」と「画像数」を指定してください。')
exit()
except ValueError:
print('引数に「収集したい対象」と「画像数」を指定してください。')
exit()
# 保存先のディレクトリ
save_dir = 'images/' + target
if not os.path.exists(save_dir):
os.makedirs(save_dir)
else:
# すでにディレクトリがあったら全削除して再作成
shutil.rmtree(save_dir)
os.makedirs(save_dir)
# FlickrAPIで画像収集
flickr = FlickrAPI(api_key=key, secret=secret, format='parsed-json')
response = flickr.photos.search(
text=target, # 引数で指定して対象
per_page=per_page, # 引数で指定した画像数
media='photos',
sort='relevance',
safe_search=1,
extras='url_q, licence'
)
# APIレスポンスから画像URLを取得し、画像ダウンロード
wait_time = 1
for image in response['photos']['photo']:
save_file = save_dir + '/' + image['id'] + '.jpg'
if os.path.exists(save_file):
continue
data = urllib.request.urlopen(image['url_q']).read()
with open(save_file, 'wb') as f:
f.write(data)
time.sleep(wait_time)
if __name__ == '__main__':
main()
実行例
python XXX.py dog 100
すると、「images/dog」ディレクトリの配下にダウンロードした画像が保存されました。
まとめ
今回はFlickrAPIを用いて画像収集してみました。
Seleniumに比べてブラウザ操作がなくAPIで画像URLを取得するので比較的速く画像収集できます。
またプリ画像に比べると画像の種類も豊富で、より簡単に速く大量の画像を収集できるかと思います。