データベースの正規化についてわかりやすく理解しよう
データベースの正規化とは??
データベースの正規化とは、データの整合性を確保するために必要な手法です。データの重複を削除し、更新や削除に起因する問題を防止することが可能になります。また、必要な情報を効率的に検索できるようになり、パフォーマンスも向上します。
第一正規化から第三正規化まで順に行います。
第一正規化とは?
第一正規化とは、繰り返し項目を排除する(繰り返しの列や、セル結合を排除)ことです。
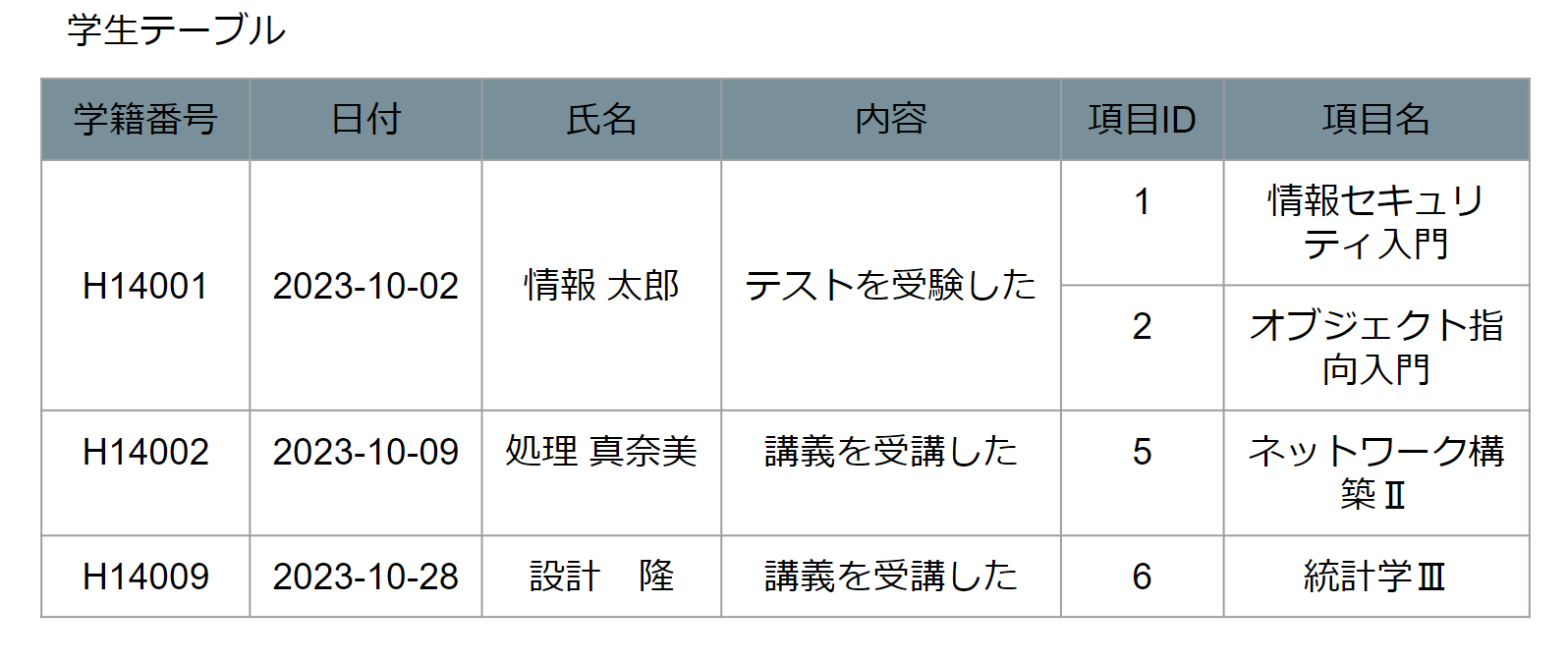
上記テーブルを見ると、学籍番号H14001の情報太郎さんが、2023-10-02日に複数のテストを受験しているため、項目IDと項目名が繰り返していると考えます。
これらの繰り返し項目を切り出すことを第一正規化といいます。
なぜ第一正規化が必要なのか?
RDB(リレーショナルデータベース)ではセルが結合された状態ではテーブルとして管理できません。
なのでRDBで管理できるよう第一正規化を正しく行う必要があります。
さっそく上記学生テーブルを第一正規化していきます
-- 第一正規化 --
手順1 繰り返しの列の部分を別表に切り出す。
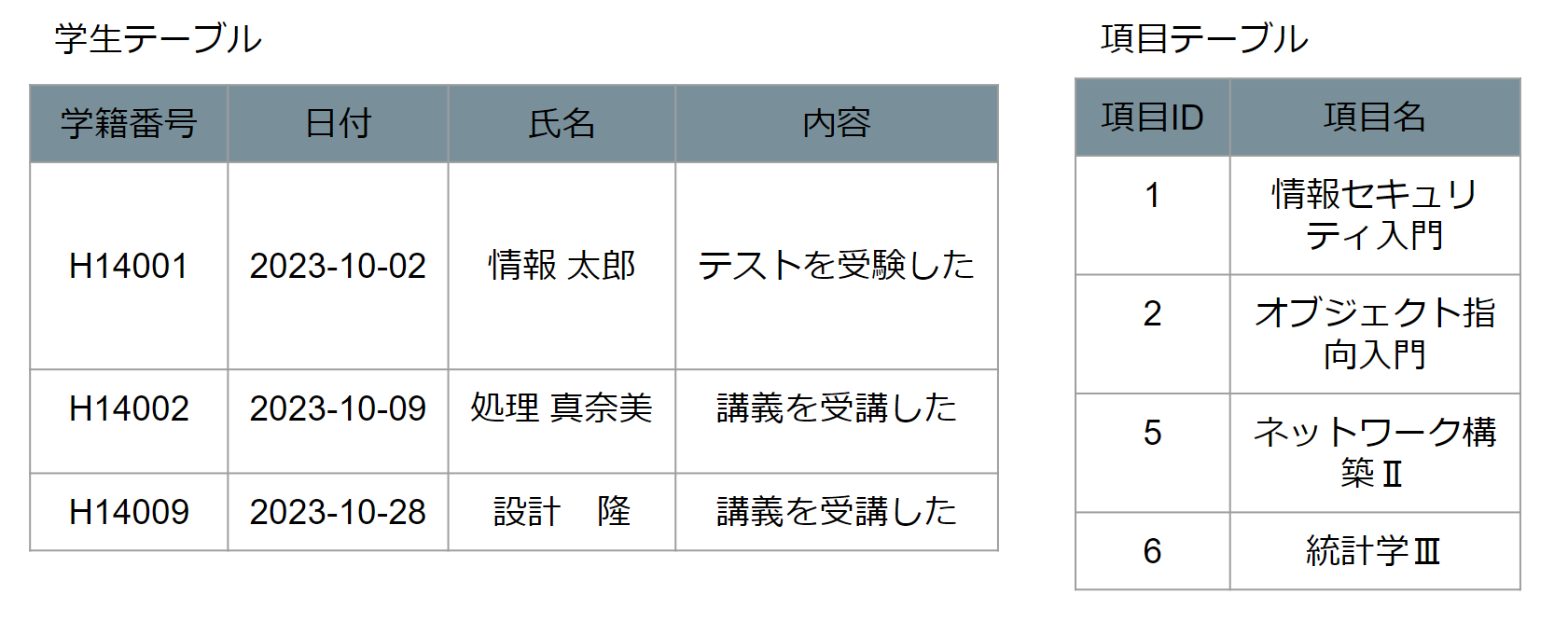
このように繰り返し項目を別表に切り出すことで、学生テーブルに繰り返し項目がなくなりました。
手順2 切り出したテーブの仮の主キーを決める。
このままでは切り出したテーブルに主キーがないため、jOIN句を使って学生とそれに合った項目で結合できないです
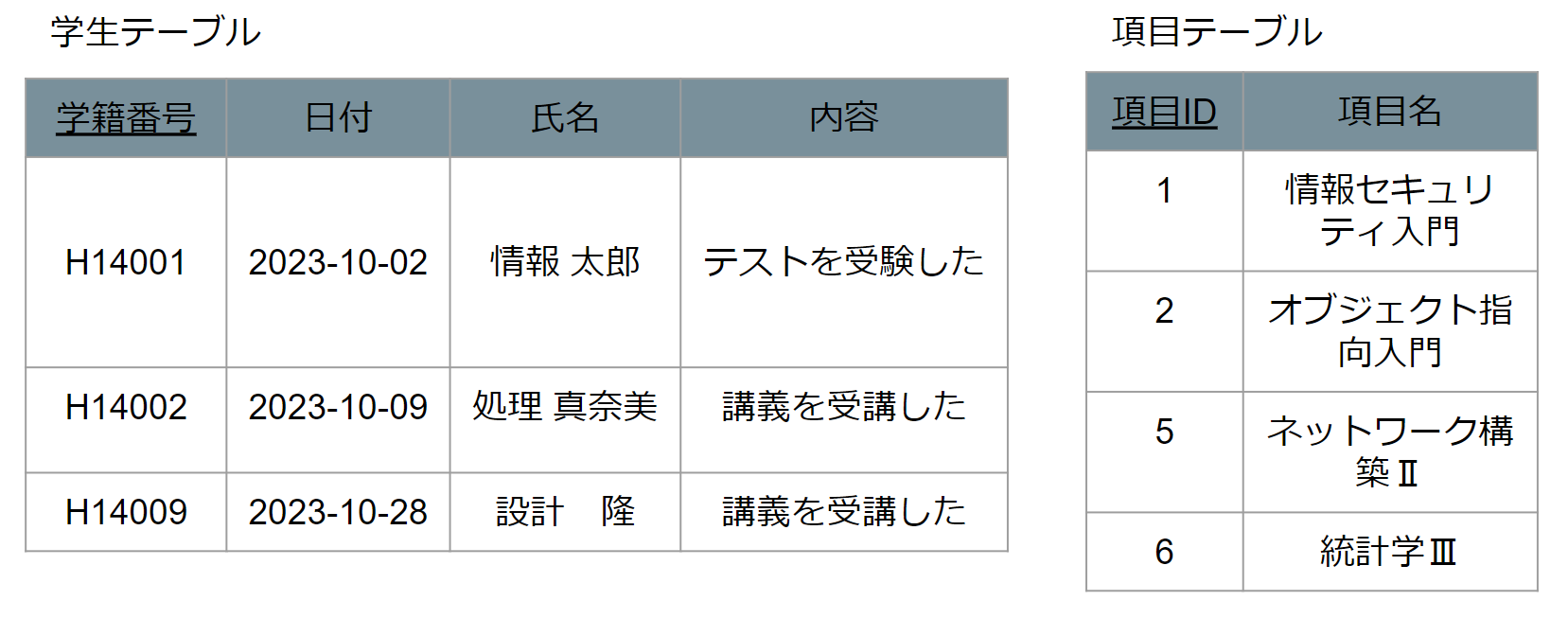
なので項目テーブルに仮の主キーを決めます、一意にレコード(行)を特定できるのは項目IDなのでこれを採用します。学生テーブルについても同じく一意に特定できる学籍番号を主キーにします。
↓ 下線が主キー
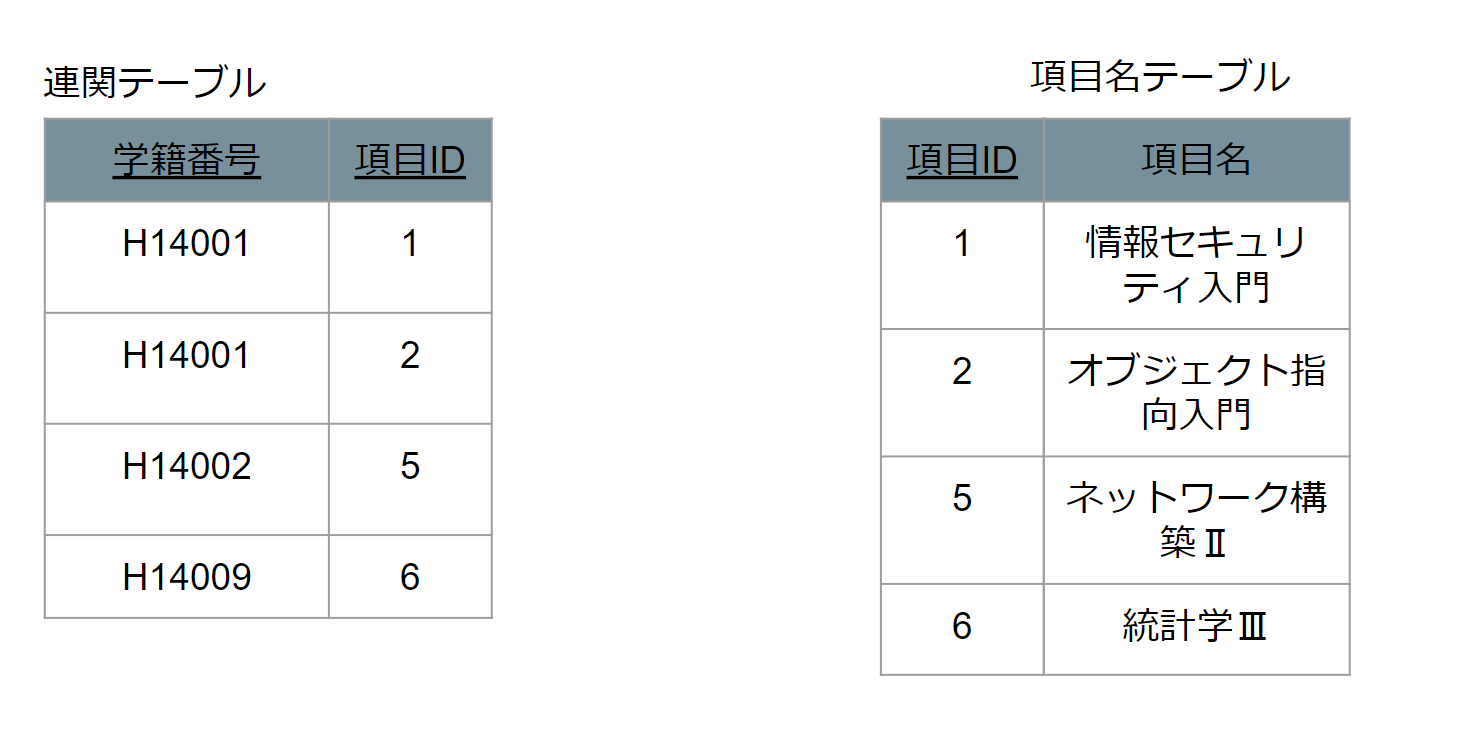
手順3 切り出し元の主キー列をコピーして、複合主キーを作る
JOIN句を使って学生とそれに合った項目で結合できるようにするため、切り出し元テーブルである学生テーブルから主キーをコピーして、項目テーブルの主キーと合わせて複合主キーを作成します。
そうすることで、学籍番号でJOINを行い結合することが可能になります。

実際にJOINを行ってみます
SELECT 学生.学籍番号,日付,氏名,内容,項目ID,項目名
FROM 学生 JOIN 項目 ON 学生.学籍番号 = 項目.学籍番号;
↓実行

しっかりと結合できました。
このようにテーブルでの繰り返し項目を排除して設計することで、更新漏れやパフォーマンスの向上が見込めます。
例えば非正規形の状態で、とある学籍番号のある項目IDの項目名を変更しようとすると、非正規状態の学生テーブルのすべてのレコードに対して処理しなければならないので人為的なミスの更新漏れが発生してしまうかもしれません、正規化を行うことによって、項目テーブルで変更したい学籍番号と項目IDの項目名を変更するだけで学生テーブルをいじる必要がなくなります(人為的ミスの削減)
さらに、学生テーブルを全件変更することなく、項目テーブルを変更すればよいだけなので処理速度パフォーマンスも向上します。
第二正規化に進む前に関数従属について説明します。
関数従属とは
とある列Aの値が決まれば、列Bの値が決まる という状態
この時、列Bは列Aに関数従属しているといえる。
RDBのすべての非キー列は、主キーにきれいに関数従属しているべきである
どういう意味でしょうか、実際に見ていきましょう。

複合主キーである学籍番号と項目IDが決まれば項目名が一意に決まるものは、主キーに対してきれいに関数従属しているといえます。しかし上記の項目テーブルでは、項目IDのみで項目名が一意に決定しています。
この状態を部分関数従属していると表現します。
かみ砕くと、学籍番号と項目IDのセットで複合主キーなのですが、複合主キーの一部である項目ID単体で主キーになってしまっている状態が複合主キーの一部に対して部分関数従属しているといえます。
これを第二正規化によって、複合主キー全体に関数従属させていきます。
第二正規化の条件
上記を踏まえて第二正規化の条件とは、どの非キー属性も主キーの真部分集合に対して関数従属しない
部分集合、真部分集合の説明はこちらをご覧ください。
具体例で学ぶ数学 -部分集合
大雑把に言うと、ある集合(複合主キー)に対して、部分集合は、一部だけ取り出してきたものです(つまり複合主キーの一部)。その際「1つも取り出さない」「全部取り出す(複合主キー全体)」も認めます(複合主キー全体も、複合主キーの一部も複合主キーの部分集合)。
それに対して、真部分集合は、3つ全部取り出すことを認めない(つまり、複合主キーの一部を取り出すことになる)なので、複合主キーの真部分集合に対して関数従属しないというのは、複合主キーの一部の列に対して関数従属してはならないということになります。
これを踏まえて第二正規化を行っていきます。
-- 第二正規化 --
第二正規化前

この時に項目テーブルを見ると、複数の学生は複数の項目名テーブルを扱うことがわかります。
例) 一人の学生[例えば学籍番号H14001]は複数の項目IDを持っている(複数の項目名に関連している)
つまり複数の学生は複数の項目名に関連し、複数の項目名は複数の学生に関連している多対多の関係であることがわかります。
これら多対多の関係を一対多の関係に変換します、連関テーブルにすることによって多対多の関係を適切に管理します。
手順1 複合主キーの一部に関数従属する列(部分関数従属している列)を切り出す

手順2 部分関数従属していた列をコピーする
項目テーブルが連関テーブルになっています。
この時には、複数の学生は複数の項目名に関連し、複数の項目名は複数の学生に関連している多対多の関係であったのが、連関テーブルで多対多の関係を管理し、関連付けられたデータを追跡します
第三正規化とは?
第三正規化とは、非キー列は主キーに直接関数従属すべきである。よって主キーに関数従属する列にさらに関数従属する列は存在してはならない(推移的関数を許さない)
推移的関数、、新しい言葉がでてきました。テーブルに新しく列を追加してわかりやすく見ていきます。

上記は前の学生テーブルにクラス、クラス担任列が追加されたテーブルです。これを第三正規化するとどうなるでしょう。
まず主キーである学籍番号に関数従属している列クラスは、綺麗に関数従属しています(一つの学籍番号を持つ学生は一つのクラスに属するため)
しかしその綺麗に関数従属しているクラス列にさらに関数従属している列、クラス担任があります。
これは主キーの学籍番号に関数従属している列クラスに、さらに関数従属している列クラス担任がある状態(推移的関数従属状態)といえます。

この推移的関数従属を排除するのが第三正規化になります。
手順1 推移的関数従属している列を切り出す

手順2 直接関数従属していた列をコピーして、切り出したテーブルの主キーにする
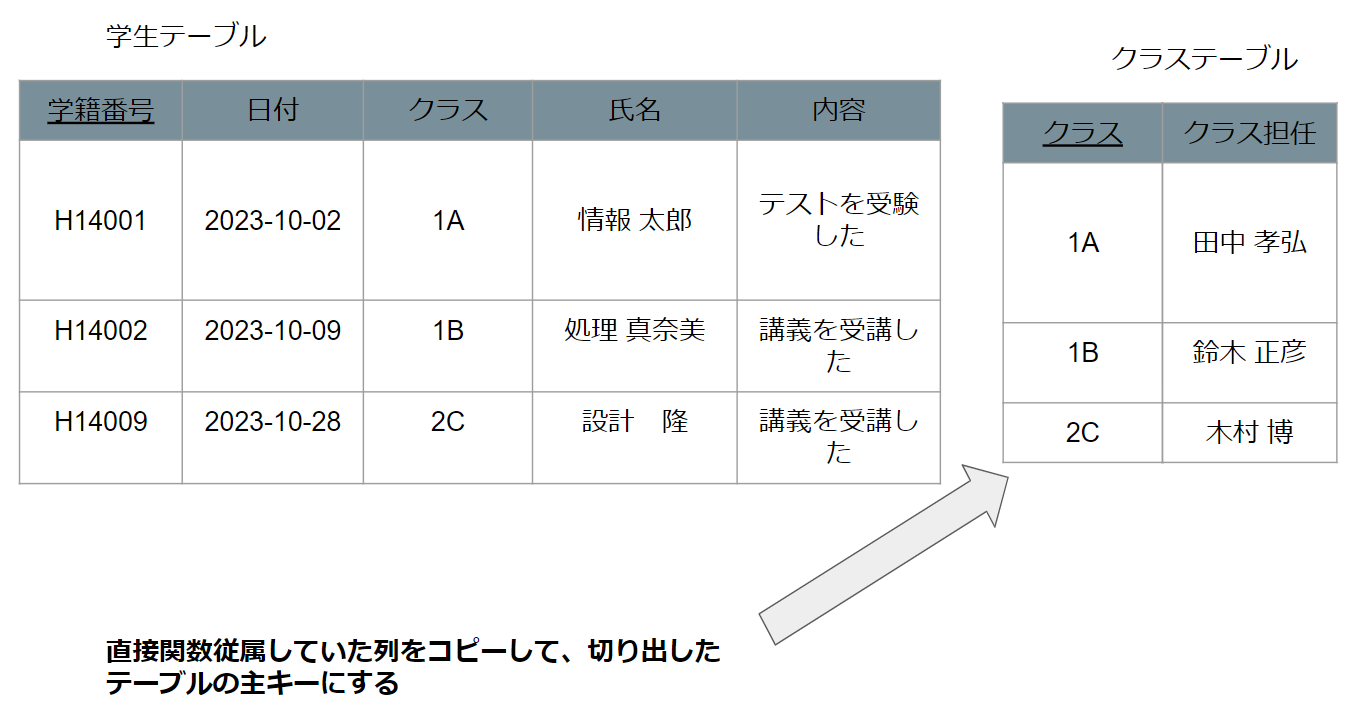
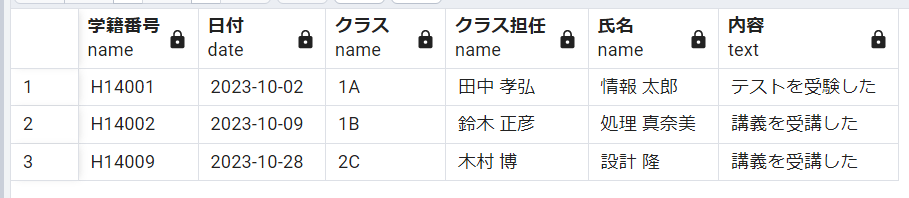
第三正規化を終えた上記のテーブルを見てみると、推移的関数従属がなくなってることがわかります。
これが第三正規化です。
JOINを行い、学生テーブルとクラステーブルを結合すると、学生ごとのクラス担任を得ることができます。
SELECT 学籍番号,日付,学生.クラス,クラス担任,氏名,内容
FROM 学生
JOIN クラス ON 学生.クラス = クラス.クラス;
↓実行
正規化で排除するもの
第一正規化 繰り返し項目
第二正規化 複合主キーの一部への関数従属(部分関数従属)
第三正規化 間接的な関数従属(推移的関数従属)
まとめ
以上がシステム設計で求められる正規化(第一正規化~第三正規化)になります。
大量のデータを扱うときは特に正規化を行うとパフォーマンス画大幅に改善するので、大切な知識になりますね。
併せて概念設計→論理設計→物理設計も理解しときたいところです。
データベース設計の基本
ちなみに正規化は論理設計工程で行います。