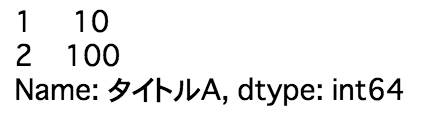CSVファイルの読み込み
data = pd.read_csv("sample.csv", encoding="UTF-8")
data
結果
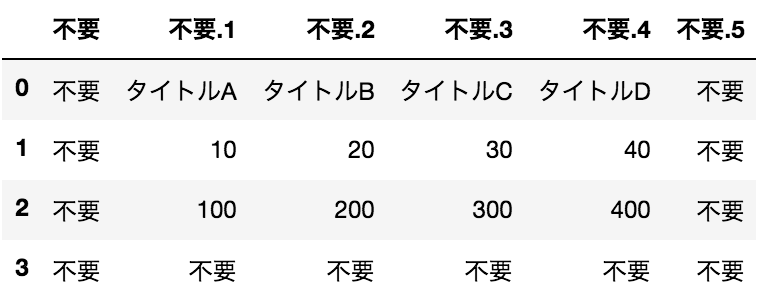
sample.csvの内容
不要,不要,不要,不要,不要,不要
不要,タイトルA,タイトルB,タイトルC,タイトルD,不要
不要,10,20,30,40,不要
不要,100,200,300,400,不要
不要,不要,不要,不要,不要,不要
GoogleスプレッドシートにあったデータをCSVで保存して、解析する際のデータをイメージしてます。
メモとか備考とかが構造化されずに書かれているシートも結構あったりすると思うので。
保存する際に範囲選ぶ事もできると思いますが、今回は練習がてらpandasで整理してみてます。
指定した行の内容をcolumn名に変更する
data.columns = data.iloc[0]
data
結果
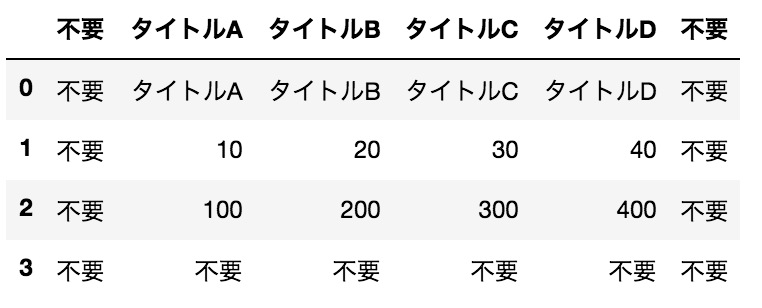
指定した行・列だけ取り出す
data = data.iloc[1:3,1:5]
data
結果

欲しい内容だけになりました。
要約統計量を色々出す(失敗)
data.describe()
結果
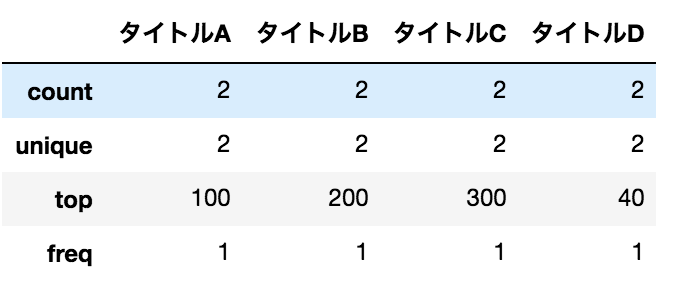
平均等が出ると思ったのですが、出ないです。
これは値の型が数値型になっていないためです。
値の型を変える
data = data.astype('int')
data
結果
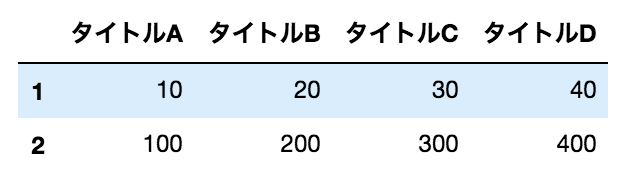
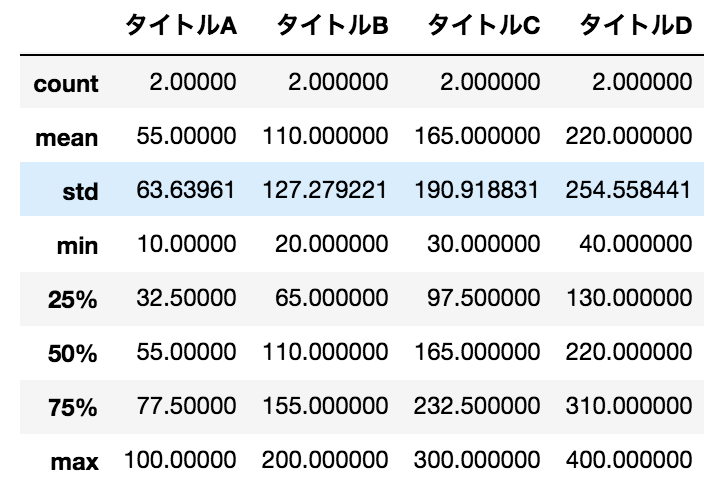
要約統計量を色々出す(成功)
data.describe()
結果
相関係数を出す
data.corr()
結果
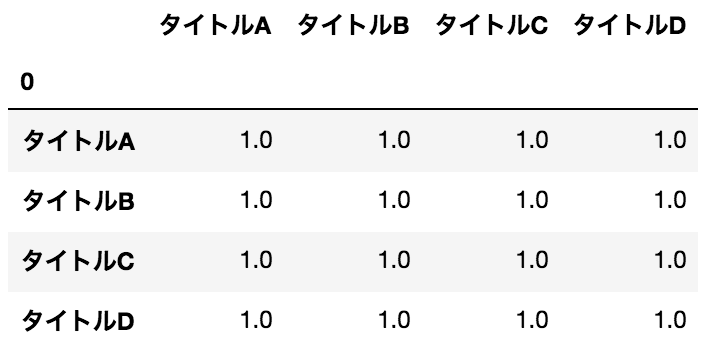
備考
左上の0ってのが何なのかわかっていません
他にも色々
data.sum() #合計
data.skew() #歪度
data.kurt() #尖度
data.var() #分散
data.cov() #共分散行列
備考
- 共分散についてはこちらがわかりやすかったです http://mathtrain.jp/covariance
- 共分散行列についてはこちらがわかりやすかったです http://mathtrain.jp/covariance
箱ひげ図を表示する
%matplotlib inline # ページ中に表示するのに必要
data.plot(kind='box')
結果
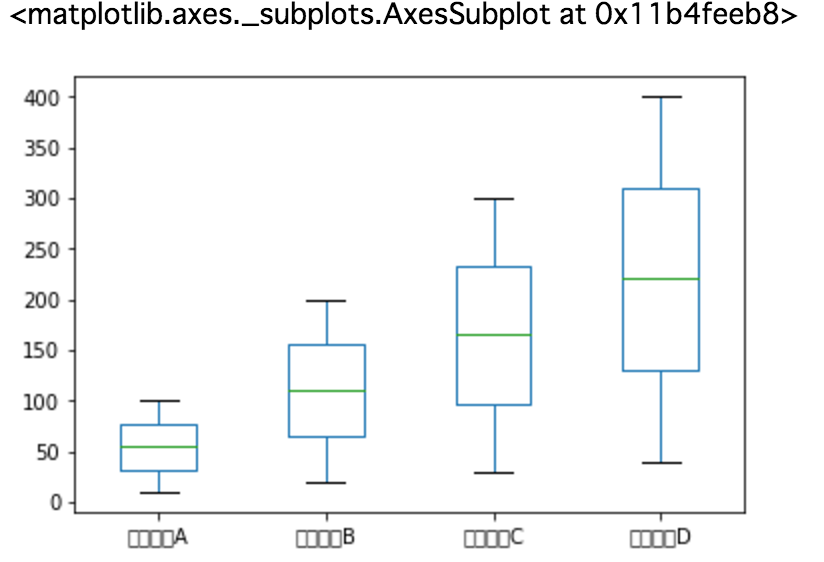
備考
日本語のラベルが表示されてないですが、日本語は
matplotlib.rcParams['font.family'] = 'M+ 1c' # 指定可能なフォント
のように指定する事で表示する事ができます。
指定可能なフォントは
import matplotlib.font_manager as fm
fm.findSystemFonts()
で調べられます。
http://qiita.com/hagino3000/items/1b54acc01483ccd0ac72
を参考にしました。
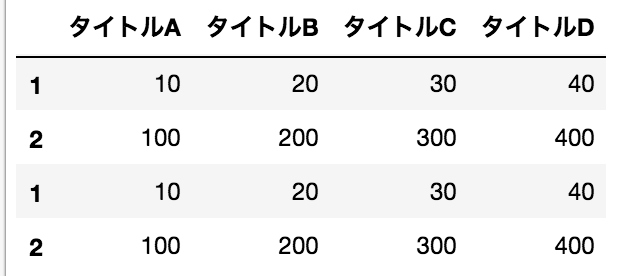
DataFrameの結合(行方向)
pd.concat([data,data])
結果
DataFrameの結合(列方向)
pd.concat([data,data], axis=1)
結果

全ての値を変更
data.pipe(lambda df: df / 2)
結果

値で並び替え
data['タイトルA'].sort_values(ascending = True)
結果