年末
僕自身は年賀状を毎年作成するのを諦めたのですが、アルバイトで家族の分の年賀状を毎年パソコンでつくっています。毎年この時期になるとExcelとワードの差し込み印刷と格闘しながら年賀状を作っているのですが...
Excelのお気持ちが理解できないので、もはやPandasで年賀状の住所録管理と宛名作成したい😅
— Capchii (@Capchii) December 28, 2019
- Excelの関数ワカラーン、せっかく勉強してるしPandasでやらせてほしい。
- 差し込み印刷の柔軟さが微妙、例えば差出人とかも連名で場合分けしたい
...というわけで、Pythonで年賀状作成をしてみることにしました。
やろうとしたこと
- Pandasで住所録データの前処理
- OpenCVではがきの印刷位置指定 (住所とか郵便番号とか)
- Pillowで宛名面・通信面作成
- 印刷 (失敗)
住所録データの前処理
ダミーデータ
まず、実験用にダミーの住所録データを作ります。
https://yamagata.int21h.jp/tool/testdata/
こちらで50人分のアドレスを作り、CSVにしました。
import pandas as pd
df = pd.read_csv("address.csv")
df.columns = ["index", "name", "address"]
 ## 名前と住所の分割
## 名前と住所の分割
次に、今後の連名対応の為、氏名を姓と名に分けます。また、住所をいい感じに段組するために住所を2分割します。具体的には
- 建物・マンション名がない場合→住所の数字以降 (丁目, 番地など) で分割
- 建物・マンション名がある場合→建物・マンション名で分割
という感じで分けていきます
df["sei"]=df["name"].str.split(expand=True)[0]
df["mei"]=df["name"].str.split(expand=True)[1]
import re
def split_address(address):
if " " in address:
pos = int(address.find(" "))
return [address[:pos],address[pos:]]
else:
pos = int(re.search("\d", address).start())
return [address[:pos],address[pos:]]
df["address_1"] = df.address.apply(lambda x: split_address(x)[0])
df["address_2"] = df.address.apply(lambda x: split_address(x)[1])
先にdataframeの列を初期化してれば、二列いっぺんに代入できるらしいですね
郵便番号取得
こちらの郵便番号取得APIを使います。map関数を使うと続々とリクエストを送ってしまいますので、適度にsleepを挟みながら取得していきます。
import json
import requests
import time
def get_postal(address):
pos = int(re.search("\d", address).start())
address = address[:pos]
try:
res = requests.get("http://geoapi.heartrails.com/api/json?method=suggest&matching=prefix&keyword="+address)
postal = json.loads(res.text)["response"]["location"][0]["postal"]
time.sleep(1)
return postal
except:
return ""
df["postal"] = df["address"].map(lambda x: get_postal(x))
最終的にこんな感じになります。
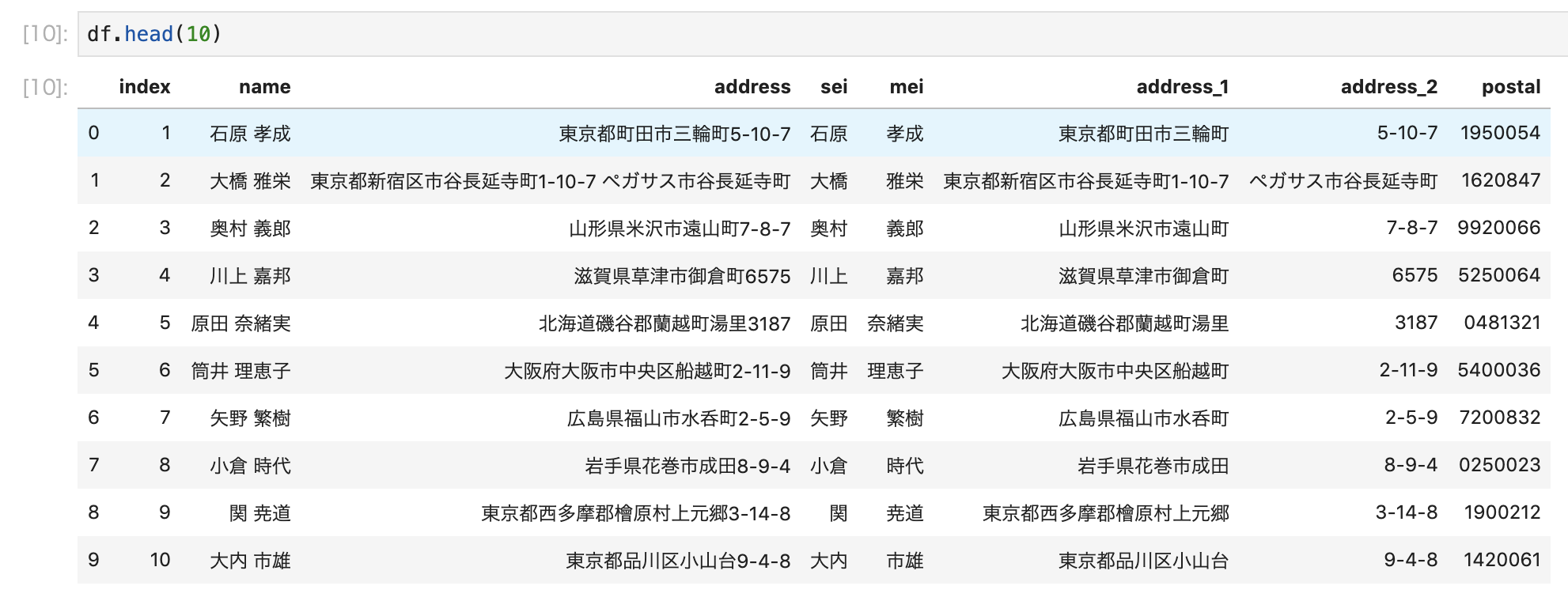
get_postal()は例外が発生した場合、空の郵便番号を返すようになっています。リクエストの送りすぎの可能性もありますが、住所の妥当性チェックもできると思います。
はがきの印刷位置指定
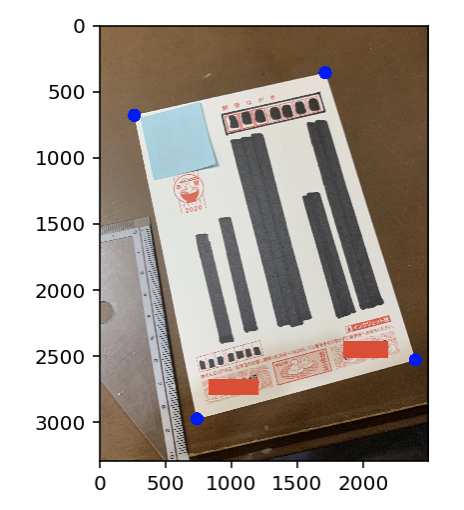
こんな感じにはがきを一枚用意し、住所とかを印刷したい箇所を黒塗りにし、雑に写真を撮ります。

アフィン変換
これをまずアフィン変換による台形補正で、はがきを綺麗に抜き出します。コードはこちらのサイトのコードをほぼそのまま使わせていただきました。
まず輪郭抽出
img = np.array(Image.open("nengajo.jpg"))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(gray,128,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh , cv2.RETR_TREE, cv2.RETR_LIST)
new_img = img.copy()
plt.imshow(cv2.drawContours(new_img, contours, -1, (128,0,0), 30))

次に、一番 (面積の) 大きな輪郭の四隅を抽出します。
menseki=[ ]
for i in range(0, len(contours)):
menseki.append([contours[i],cv2.contourArea(contours[i])])
menseki.sort(key=lambda x: x[1], reverse=True)
epsilon = 0.1*cv2.arcLength(menseki[0][0],True)
approx = cv2.approxPolyDP(menseki[0][0],epsilon,True)
new_img = img.copy()
plt.imshow(cv2.drawContours(new_img, approx, -1,(0, 0, 255),100))
最後に、はがきを真正面から見るようにアフィン変換し、切り抜きます。また、はがきの推奨ピクセルサイズが2362x3496pxということなので、それに合わせます。
approx=approx.tolist()
left = sorted(approx,key=lambda x:x[0]) [:2]
right = sorted(approx,key=lambda x:x[0]) [2:]
left_down= sorted(left,key=lambda x:x[0][1]) [0]
left_up= sorted(left,key=lambda x:x[0][1]) [1]
right_down= sorted(right,key=lambda x:x[0][1]) [0]
right_up= sorted(right,key=lambda x:x[0][1]) [1]
perspective1 = np.float32([left_down,right_down,right_up,left_up])
perspective2 = np.float32([[0, 0],[1378, 0],[1378, 2039],[0, 2039]])
psp_matrix = cv2.getPerspectiveTransform(perspective1,perspective2)
img_psp = cv2.warpPerspective(img, psp_matrix,(1378,2039))
plt.imshow(img_psp)
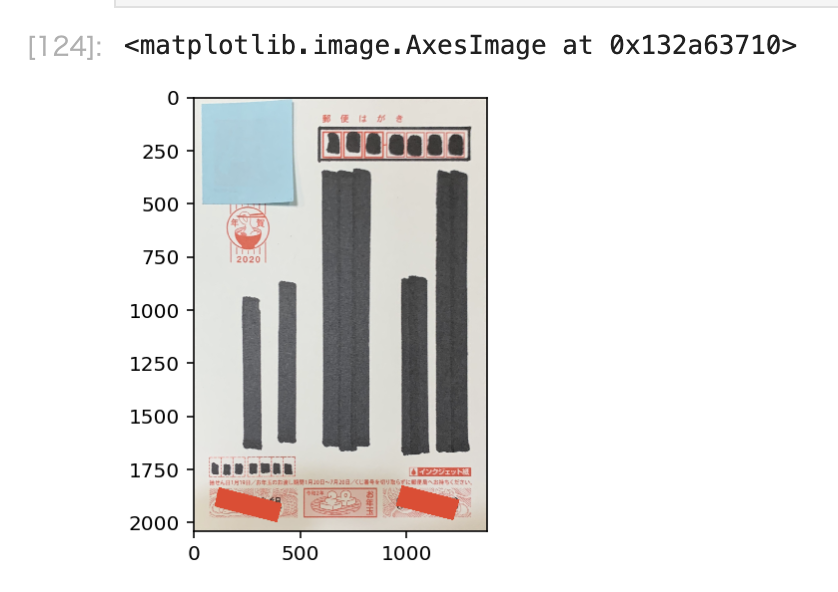
綺麗に抜き出せましたね、すごい!
塗りつぶし領域の抽出
OpenCVのcv2.threshold()により画像の閾値処理をし、塗りつぶした領域をマスクします。cv2.threshold()はグレースケールの画像を投げる事もできますが、HEIGHT×WIDTHの形の、uint8のnumpy行列ならなんでも投げられます。また、自分の経験上、閾値処理はBGRでやるよりもHSVのどれかに注目してやるとうまくいくことが多いです。
今回画像をHSVの3チャンネル画像HEIGHT×WIDTH×3にまず変換します、そのうち、V成分のチャンネルのみを抜き出し、HEIGHT×WIDTHの行列を閾値処理する事で、うまく塗りつぶした部分を抽出することができました。
_, v_img = cv2.threshold(cv2.cvtColor(img_psp,cv2.COLOR_BGR2HSV)[:,:,2], 128, 255, cv2.THRESH_BINARY)
plt.imshow(v_img)

ここで、マスクの輪郭を抽出します。輪郭を抽出する前に、マスク自体のノイズをまずモルフォロジー変換で除去します。また、輪郭の面積が一定以下のものをリスト内包表記でフィルタしています。
_, v_img = cv2.threshold(cv2.cvtColor(img_psp,cv2.COLOR_BGR2HSV)[:,:,2], 128, 255, cv2.THRESH_BINARY)
kernel = np.ones((8, 8),np.uint8)
v_img = cv2.morphologyEx(v_img, cv2.MORPH_CLOSE, kernel)
contours, hierarchy = cv2.findContours(v_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
menseki=[ ]
for i in range(0, len(contours)):
menseki.append([contours[i],cv2.contourArea(contours[i])])
menseki = [m[0] for m in menseki if m[1] > 800]
contours=menseki
cont_vis = cv2.drawContours(v_img, contours, -1, (128,0,0), 30)
for idx, con in enumerate(contours):
cont_vis = cv2.putText(cont_vis, str(idx), (con[2][0][0], con[2][0][1]), cv2.FONT_HERSHEY_PLAIN, 3, (64, 64, 64), 5)
plt.figure(figsize=(15,20))
plt.imshow(cont_vis)
輪郭抽出の結果はこんな感じ
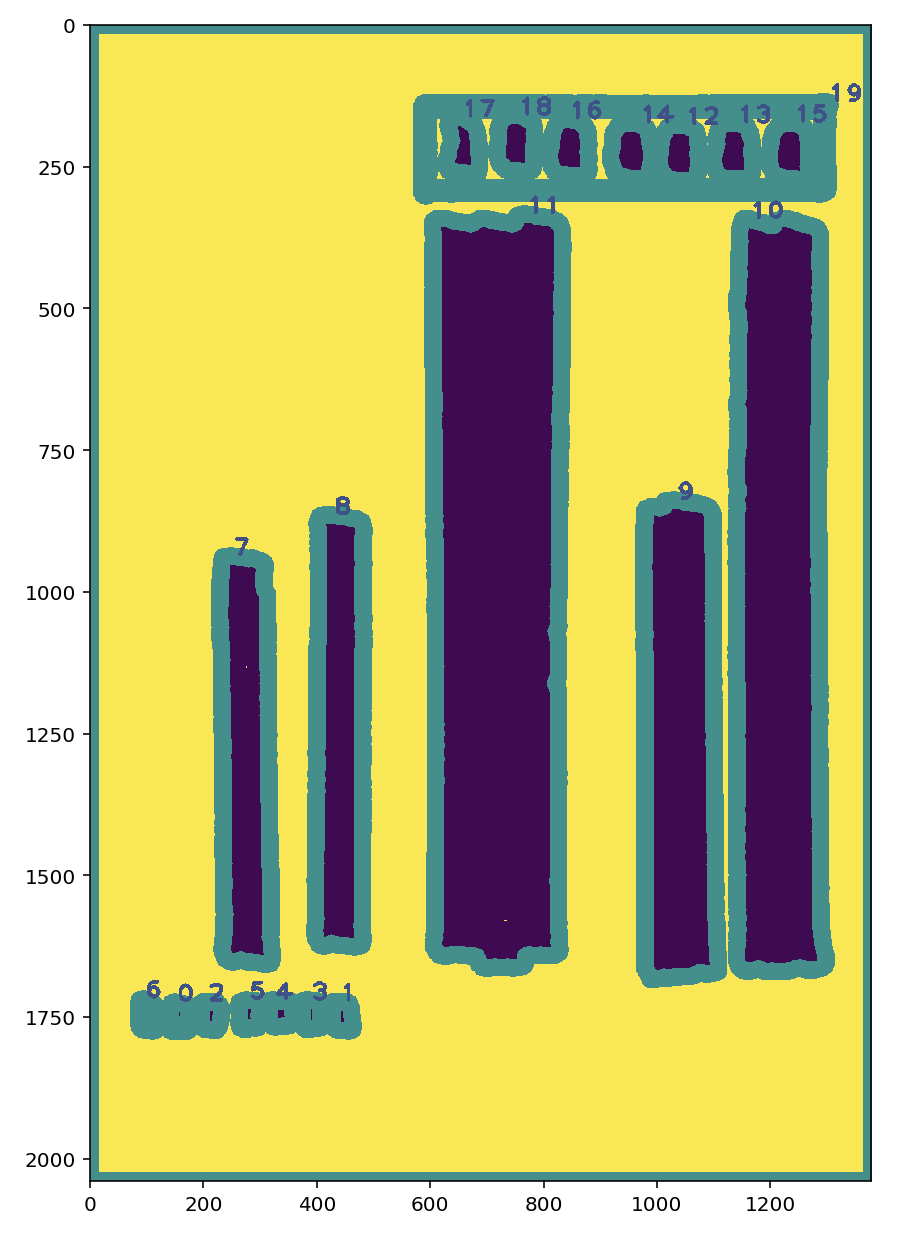
ここで、モルフォロジー変換をかけない結果はこんな感じになります。

今回輪郭の誤検知はあまりありませんが、マスクに乗っている細かいノイズが除去されていることがわかります。
あとはこの画像を見ながら、どのデータをどこに配置したいか定義します。
address_conts = {
"to_postal":list(map(cv2.boundingRect, [contours[17],contours[18],contours[16], contours[14], contours[12], contours[13], contours[15]])),
"to_address1":cv2.boundingRect(contours[10]),
"to_address2":cv2.boundingRect(contours[9]),
"to_name":cv2.boundingRect(contours[11]),
"from_address":cv2.boundingRect(contours[8]),
"from_name":cv2.boundingRect(contours[7]),
"from_postal":list(map(cv2.boundingRect, [contours[6],contours[0],contours[2], contours[3], contours[5], contours[4], contours[1]])),
}
cv2.bouundingRect()で輪郭を外接する長方形で囲い、xywh座標 ($(x,y)$は長方形の左上の座標, $(w,h)$は長方形のの縦横の長さ) で保持します。
この結果を見て思ったのですが、cv2.findContours()って画像の下にあるものから輪郭を検出してるんですかね...
印刷面の作成
Pillowで印刷面を作っていきます。
宛名面
先ほどの座標をもとに、文字を縦書きで置いていきます。とりあえず今回は住所録から一件だけ取り出して作ってみます。「Pillow 縦書き」とかでググるとこちらの記事が出てくるのですが、この記事の方のおかげで、Pillowのv6以上ではttb指定で縦書きが可能になっています。あとはraqmの環境構築が必要です。フォントの.otfファイルは今回の実行ディレクトリ (jupyter labを使いました) におきます。
def calc_start_pos(cont):
x = cont[0]
y = cont[1]
return (x, y)
from PIL import Image, ImageDraw, ImageFont
data = df.loc[2]
fnt1 = ImageFont.truetype("GenEiAntique.otf", 80)
fnt2 = ImageFont.truetype("GenEiAntique.otf", 150)
fnt3 = ImageFont.truetype("GenEiAntique.otf", 50)
address = Image.new('RGBA', (v_img.shape[1],v_img.shape[0]), (255,255,255,255))
d = ImageDraw.Draw(address)
d.text(calc_start_pos(address_conts["to_address1"]), data["address_1"].replace("-","|"), font=fnt1, fill=(0,0,0,255), direction="ttb")
d.text(calc_start_pos(address_conts["to_address2"]), data["address_2"].replace("-","|"), font=fnt1, fill=(0,0,0,255), direction="ttb")
d.text(calc_start_pos(address_conts["to_name"]), data["name"] + " 様", font=fnt2, fill=(0,0,0,255), direction="ttb")
d.text(calc_start_pos(address_conts["from_address"]), "東京都新宿区歌舞伎町127-0-1".replace("-","|"), font=fnt3, fill=(0,0,0,255), direction="ttb")
d.text(calc_start_pos(address_conts["from_name"]), "某山某太郎", font=fnt1, fill=(0,0,0,255), direction="ttb")
for num, rect in zip(data["postal"], address_conts["to_postal"]):
d.text(calc_start_pos(rect), num, font=fnt1, fill=(0,0,0,255), direction="ttb")
for num, rect in zip("1600021", address_conts["from_postal"]):
d.text(calc_start_pos(rect), num, font=fnt1, fill=(0,0,0,255), direction="ttb")
calc_start_pos()で文字を書き始める位置を計算しようと思ったのですが、先ほど抽出した矩形の左上座標をそのまま指定すればうまく配置できました。
こんな感じで描いた宛名面を、先ほどのはがきに載せてみます。あらかじめ黒く塗り潰したところはマスクを使い、はがきの色っぽく塗り戻しています。
address_array = np.array(address)
final_image = np.zeros_like(img_psp)
letter_image = img_psp.copy()
for i in range(3):
letter_image[:,:,i] = np.where(
v_img < 129,
222,
img_psp[:,:,i]
)
for i in range(3):
final_image[:,:,i] = np.where(
address_array[:,:,i] ==0,
address_array[:,:,i],
letter_image[:,:,i]
)
plt.figure(figsize=(7,10))
plt.imshow(final_image)

細かい調整はまだできそうですが、そこそこいい感じになりましたね。np.where()はマスクを元にあれこれ処理するときに便利です。
裏面
いい感じにOpenCVで書きます。
ura = np.zeros_like(final_image)+255
pts = np.array([[400,500],[1100,500],[750,1500]], np.int32)
pts = pts.reshape((-1,1,2))
ura = cv2.fillPoly(ura,[pts],(128,128,128))
ura = cv2.circle(ura,(400,500), 200, (72, 72, 72), -1)
ura = cv2.circle(ura,(1100,500), 200, (72, 72, 72), -1)
ura = cv2.circle(ura,(750,1500), 50, (72, 72, 72), -1)
ura = cv2.circle(ura,(750,1500), 50, (72, 72, 72), -1)
ura = cv2.circle(ura,(670,900), 50, (72, 72, 72), -1)
ura = cv2.circle(ura,(850,900), 50, (72, 72, 72), -1)
ura = cv2.line(ura,(750,1500),(900,1400),(72, 72, 72),20)
ura = cv2.line(ura,(750,1500),(900,1500),(72, 72, 72),20)
ura = cv2.line(ura,(750,1500),(900,1600),(72, 72, 72),20)
ura = cv2.line(ura,(750,1500),(600,1400),(72, 72, 72),20)
ura = cv2.line(ura,(750,1500),(600,1500),(72, 72, 72),20)
ura = cv2.line(ura,(750,1500),(600,1600),(72, 72, 72),20)
ura = cv2.putText(ura, "A Happy New Year!!", (50, 1800), cv2.FONT_HERSHEY_PLAIN, 8, (64, 64, 64), 10)
ura = cv2.putText(ura, "2020", (450, 2000), cv2.FONT_HERSHEY_PLAIN, 13, (64, 64, 64), 20)
plt.figure(figsize=(10,15))
plt.imshow(ura)
🐭

印刷
コマンドラインのlprコマンドから印刷を試みます。指定できるオプションはlpoptions -p [プリンタ名] -lでコマンドラインから確認できます。あとはご使用のプリンターの公式サイトを見れば、いい感じに印刷できるはず...?
import subprocess
from PIL import Image
from io import BytesIO
buf = BytesIO()
Image.fromarray(ura).save(buf, 'PNG')
# print out
p = subprocess.Popen('lpr -P Canon_TS5100_series -o media=Postcard -o InputSlot=rear -o MediaType=any'.split(), stdin=subprocess.PIPE)
p.communicate(buf.getvalue())
p.stdin.close()
buf.close()
おもて面も同様に指定すれば、いい感じに印刷できるはずです。
結果
↓裏面、いい感じ

↓おもて面、二回印刷してフチなしとフチありを試したのですがいうまくいかず...

印刷までこぎつけたのですが、サイズが合わない悔しい結果になってしまいました。アフィン変換したときに小さく切り出してしまい、誤差が生じている可能性や、プリンタ側で拡大縮小している可能性があります... (フチなしの時とフチありの時のちょうど中間に印刷できれば、ちょうどよくなるはず?)
まとめ
印刷がうまくできませんでした。どなたか知見をお持ちでしたら教えていただきたく思います。ExcelとWord万々歳。良いお年を!