皆様こんにちは。
Kazuyaと言います。
今回は、昨今ではソフトウェアの高速リリースにおいて切り離せなくなった、「DevOps」。
この概念に、AIの力を加えて、運用において避けて通れない、「インシデント」を
より早く識別したり、発生する可能性を診断する方法または、それを解決するための機能を、
Cloud Pak for Watson AIOpsを用いて、実現した際のスピーディな展開をご紹介いたします。
Cloud Pak for Watson AIOpsについての説明ページは、
こちらをご参照ください。
https://www.ibm.com/jp-ja/cloud/cloud-pak-for-watson-aiops
免責事項
- 今回利用する環境は、CloudPak Watson AIOps v3.1の環境です。この手順で説明する手順と、ご利用のバージョンとでは操作手順が異なる場合があります。また、本投稿においては利用するとどのように利用できるようになるのかを取りまとめているため、細かな設定等は割愛しています。
- 本ページでご紹介するユースケースはあくまで一例です。実際の運用時に、この通りにやっていたからといって、全ての問題が解決されるわけではありません。
利用する製品
- Automation Hub
- Event Manager(Netcool Operations Insight)
- Prometheus
- ELK(Kibana)
- Instana
- Grafana
- OCP
- Slack
このデモでわかること
- Watson AIOpsにより、複数の情報ソースをインテリジェントに関連付け、価値の低いアラートではなく実用性のあるアラートを AI用いて凝縮して検出することができ、AIOpsを導入しておくことで、いかに問題発生時に人手を介さずに問題解析と、 その対策を打ちやすくなるかを理解することができます。
AIOpsで監視対象とするアプリ
- Kubernetesで実行される、マイクロサービスアーキテクチャ。
- さまざまなタイプのアプリのプロキシとして機能する、ランダムな見積りを提供するコンテンツ配信アプリ。
- 本アプリはミッションクリティカルに位置付けられており、24/365停止が許されないため、障害の早期検知と万が一発生時も早期対策が必要。
前提:
- 監視対象とするアプリケーションは、インフラストラクチャを含めて既に出来上がった状態とする
- アプリケーションへの障害は、外部ツールを用いて障害をシミュレートする
- AIOpsの設定にて、Slackへ通知するようにしてある。
本題
1.障害の発生〜通知の受信
障害を発生させます。これは外部ツールでも何らかのプログラムバグを用いても構いません。
しばらくすると、設定されている通り、Slackへ通知が届きます。

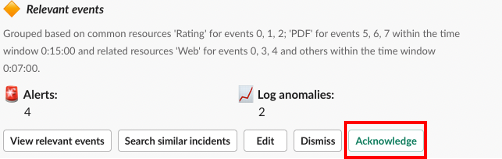
①上記のように、最初は「Rating」に問題があると検知され通知が届きました。
②その後、最終的には、「Rating」に加えて、「Webサービス」にも影響が出ていることが
わかるようになっています。
AIOpsは通知を「ストーリー」と呼ばれるものでフォーマットしてくれます。
イベント、メトリック、アラート、ログを相互に関連付け、根本的な問題の後、影響を受けるサービスのさまざまな通知を、人間が見てわかりやすいようにリアルタイムに表示してくれます。これを、オリジナルの大量のメトリックやログのストリームを見て解析していると考えてみましょう。
・・・膨大な情報量ですよね。。
この上記のような「根本的なこと」の導出と、「それによって受ける影響範囲」というのが、インシデントが発生したときに最初に求められる「調査対象範囲」となってきます。
これが、AIOpsを用いると、設定さえしておけば、最も簡単に整理した形で通知してくれます。これにより、問題がこれから発生するまたは既に発生したことが、即時検知できるのです。
2.問題となるサービスの特定
1で確認できた問題の内容だけでは、一体全体どのサービスが問題を起こしたのかわかりません。
問題は、発生した箇所を特定することが重要です。
早期問題箇所の特定により、問題が他のサービス・コンポーネントに雪崩のように派生していくことを防げます。
Slackと連携したAIOpsの機能では、この解決も支援してくれます。
1で確認したSlack内の、ストーリーの関連イベントセクションを確認します。

わざわざ、他のツールで解析する必要はなく、Slack上からそのまま調べることができます。
上記の関連イベントセクションを見ると、Ratingサービスのメモリ・CPUの大幅な増加であることが大幅に遅くなります。
これだけだと憶測に過ぎないので、詳細を確認するために、さらに関連するイベントを要求します。
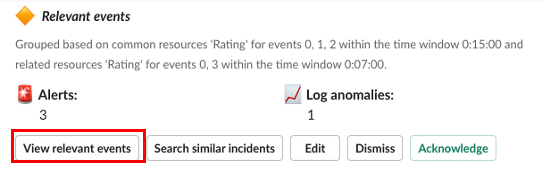
クリックにより、関連するイベントがグループ化されてポップアップ表示されます。

このとき、AIOpsは、連携しているKibanaにアクセスし、毎分数百から数千は発生しているログエントリデータを手動で並べ替える代わりに、このダイアログ上に、必要な情報を表示してくれます。
この検知には、アプリケーションが正常に稼働している時のログでトレーニングを行なってあり、そのトレーニングされたデータをもとに、現在出力されているログデータが正常時から逸脱しているかどうかを判定して出力してくれます。
ダイアログを下までスクロールすると、通常時と異なっているログが確認できます。

上記のログから見ると、異常と見做されたのは、<TXT>から始まるログが本来出力されないはずのところが、5件発生しているということがわかります。
これにより、AIOpsは、通常時発生しないログがあることを検知してくれています。
つまり、「qotd-rating」サービスがこの問題の根本的な原因となっていることがわかります。
これだけではまだわからない部分が多いので、さらにログの詳細を確認します。
そのために「Show more」をクリックします。

詳細を開くと、テンプレート(異常と判定するに値するルール)に一致したメッセージが5つ存在したことがわかります。

そのログの詳細を「Preview logs」をクリックして確認してみます。

詳細が表示されます。ここでどのサービスに対して、何を行なったらどうなったのかというところまで追えるようになります。

以上で解析までは完了できました。
3.対策方法の取得
上記2までで、何が起こっているかについて、概要は理解できました。
理解ができたら、そこからはいかに早く解決できるのかというところにチームはシフトしていきます。
このとき、1から解決策を考えたり調査すると、対応がどんどん遅れていきます。
それを早期段階で解決に向かわせるために、AIOpsの類似インシデント検索機能を使い、対策案の候補を見つける方法を利用します。
Slackに表示されている、「Search similar incidents」を利用することで、類似するインシデントを探しだし、それに対する対策方法を検索することができます。

クリックすると、検索のためのキーワードが埋め込まれた状態で、ポップアップが表示されるので、今回は問題が起きたのが、「Rating」だったので、キーワードに「rating」と入れて検索してみます。

そうすると、ratingに関連するインシデント事例の検索結果が表示されます。

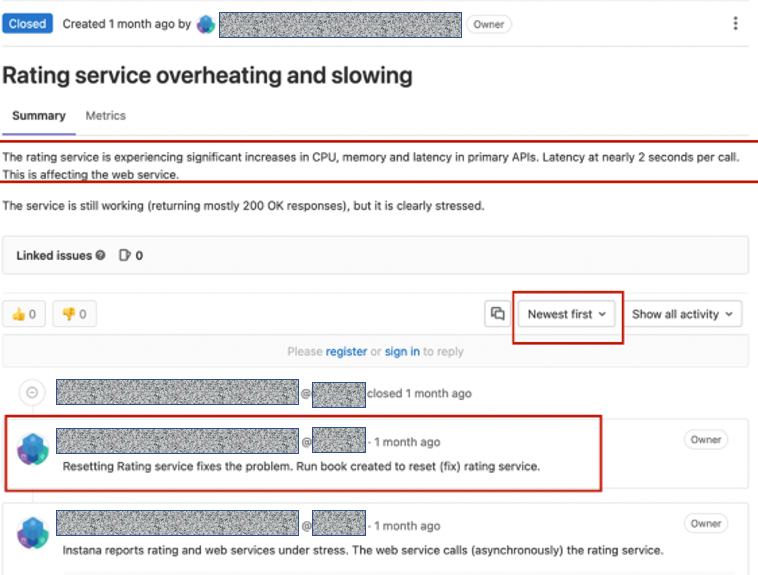
検索結果から、RatingServiceが遅延のかかった理由が記述されます。
その検索結果には、リンク先のRunbookが役に立ったというコメントが見つかりました。
リンク先を開くと、コメントに紐づく情報サイトが表示されます。
これで、解決方法の候補が即時入手できました。
4.問題の修正と対策
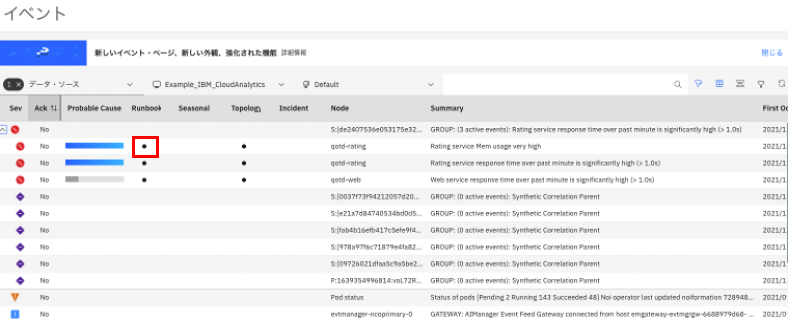
解決方法がわかったら、Watson AIOpsの管理コンポーネントを開き、イベントを確認します。
赤丸のところが、クリティカなイベントになります。

Ratingの根本的な障害を解決するためのRunbookへのリンクが表示されているので、クリックして実行します。
Runbook実行のためのイベント詳細が表示されたら、「運用手順書の実行」をクリックして実行。(このページは日本語設定)

実行ページが表示されたら、「運用手順書の開始」をクリック。

自動ステップの「実行」をクリックして実行します。

以上で対策は完了です。
5.問題解決の確認
問題解決は、Instanaのヘルスメトリックを見ることで確認ができます。
レイテンシーが正常に減少しているか確認してみます。

著しく増加していたレイテンシーが減少したことを確認できました。
問題は早期に解決できました。
6.インシデントのクローズ
最後に、Runbookに対する評価を必ず残すようにします。
これは時間が経過した後に、他のメンバーが同じ問題に直面した時の信頼度につながります。
AIOpsのイベントマネージャータブのRunbookを開き、履歴を開くことで、フィードバックの送信ができます。
問題が正常に解決したのかなど、詳細な情報を入れて完了します。
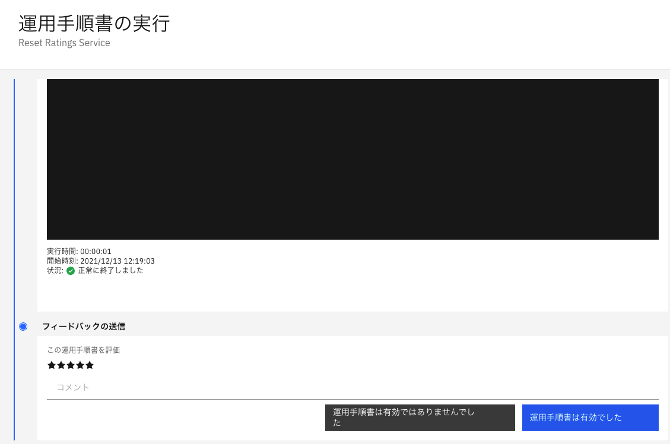
このRunbookは3回、満点の評価がついている状態となりました。

これでインシデントのクローズ準備ができました。
Slackに戻ってクローズしましょう。
先ほど表示されていた解決方法の検索結果のダイアログにて「Add to story」をクリックし、
Ratingに関する詳細を入力します。

最後に、このインシデントが無事クローズされたことがわかるように、インシデントをクローズします。
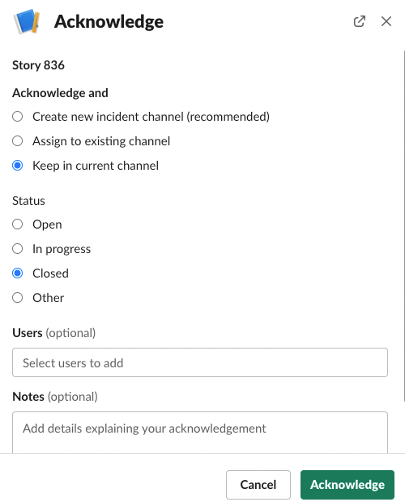
インシデントのクローズには「Acknowledge」をクリックします。
現在のチャンネル情報を保持したことを選択して、クローズステータスにした上で終了します。
おわりに
以上で、トラブルの早期検出・対策候補の探索・対策の実施が完了となりました。
AIを活用することで、本来膨大にかかる問題の根本原因の分析から対策方法の検討といったものが、過去の事例を探って実現することで短時間で実現できるということがわかったのではないでしょうか。
初期の頃はナレッジがたまっておらず、時間がかかるものも、こうやってナレッジをどんどん貯めていき、Runbookにて自動的に対応できるようにしておくことで、ミッションクリティカルなシステムの運用も、ダウンタイムなしまたは最小限に抑えることができる可能性を秘めているという運用に是非取り入れていただきたい製品のご紹介でした。
AIは我々にとって味方です。
活用して初めてその価値が高まります。
存在しているだけで終わらせず、AIだけに頼らず、その活用方法を是非学び、さまざまなシチュエーションで最大限の力を出してもらい、煩雑な人間系の作業を是非減らしていきましょう!