結論
- 何を作成したか?
機械学習を利用して、ゴッホとカンディンスキーの絵の分類機のWebアプリを作りました。
目次
- 自己紹介
- 本記事の目的
- 機械学習のプログラムでやってみたいこと
- 実装
4-1. 環境
4-2. 結果 - 考察と今後の目標
1. 自己紹介
- 40代男性、 趣味は絵を書くことです。
- 現在の仕事はITのグループもある部でIT関係の協力会社への発注や、予実管理などの管理業務を行なっています。
- 40代になってから書籍を見ながら独学でITやプログラミングを勉強しています。
- 応用情報技術者試験合格。
- 今回は、専門実践教育訓練給付金制度を使って、プロの指導を受けています。
- 病気の後遺症で、左手足が不自由なため右手でタイピングしています。左手は、controlやshiftを押す程度です。
2. 本記事の目的
下記のように、主に自分のためですが、下記を通じて、プログラミングやシステム構築を学び、コミュニティに少しでも貢献できると良いと考えています。
* 専門実践教育訓練給付金制度のコース修了条件がブログ作成のため
* 学んだことを忘れないための備忘録
* 今後の目標の意思表明
3. 機械学習のプログラムでやってみたいこと
-
3-1.背景
私の趣味は絵を書くことです。描いた絵を自分や他人が評価するときに、誰それの絵みたいとか、日本画を描いているのに洋風とか、人は似ているかもしれない誰かの絵というように絵を評価しがちです。
そこで、描いた絵が誰の絵に似ているというようなことを示唆してくれるAIを作りたいと考えています -
3-2.背景より将来的にやってみたいこと
AIにある絵を分類させた時に、その結果がある人が行った絵の分類と似ていれば、そのAIを解析することで、ある人は絵画をどのように鑑賞、評価しようとしているかがわかるのではないかと、想像しました。 -
3-3.背景より本ブログでやったこと
ポスト印象派のゴッホの絵と、抽象絵画の創始者と言われるカンディンスキーの絵を分類できる絵画分類器を作成しました。 -
以下に具体的に記載していきます。
4. 実装
4-1. 環境
- MacBook Pro (Retina, 13-inch, Early 2015)
- MacOS monteray version 12.4
- Google DriveとGoogle Colaboratoryを使用
4-2. 学習用データの収集
- kaggleのデータセットを用いた。
Best Artworks of All Time
https://www.kaggle.com/datasets/ikarus777/best-artworks-of-all-time
このうちのゴッホの絵とカンディンスキーの絵をそれぞれ約90枚づつ使用した。
ゴッホの絵は800枚あったが、カンディンスキーの絵が少なかったため
4-3. プログラムの作成
- VGG16を使って転移学習しました。
- ベタと下記に貼り付けてしまいました。
- ブログを見た方にご指導いただけますと嬉しいです。
import sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib
import cv2
import random
import numpy as np
import matplotlib.cm as cm
from tensorflow.keras.layers import Activation, Conv2D, Dense, Dropout, Flatten, MaxPooling2D, Dropout, Input
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications.vgg16 import VGG16
- グーグルドライブとグーグルコラボを使うと、環境構築の必要がなく、高価な機器を導入することなく、機械学習のプログラムの作成を試すことができました。グーグルドライブとの連携は下のようにすると出来ました。
# ダウンロード先ファイルの参照(google drive用)
import os
from google.colab import drive
drive.mount('./gdrive')
- フォルダーを切って、ゴッホの絵とカンディンスキーの絵のフォルダー内に学習用データを入れておくだけで、ラベリングが出来ました。
# データを取得する
DATADIR = "./gdrive/My Drive/20230101"
#カンディンスキーの絵と、ゴッホの絵
CATEGORIES = ["Gogh_2", "Kandinskiy"]
-
片方に多くようなデータ数の偏りがあると、判定が不正確になりました。
当初9:1でしたのを1:1に修正しました。 - 画家ごとに、フォルダーを切れば多分類の絵画分類器が作れそうです。
IMG_SIZE = 100
training_data = []
def create_training_data():
for class_num, category in enumerate(CATEGORIES):
path = os.path.join(DATADIR, category)
for image_name in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, image_name),) # 画像読み込み
img_array = cv2.cvtColor(img_array, cv2.COLOR_BGR2RGB) #カラーの修正
img_resize_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # 画像のリサイズ
training_data.append([img_resize_array, class_num]) # 画像データ、ラベル情報を追加
except Exception as e:
pass
create_training_data()
random.shuffle(training_data) # データをシャッフル
X_train = [] # 画像データ
y_train = [] # ラベル情報
# データセット作成
for feature, label in training_data:
X_train.append(feature)
y_train.append(label)
# numpy配列に変換
X_train = np.array(X_train)
y_train = np.array(y_train)
# データセットの確認
for i in range(0, 10):
print("学習データのラベル:", y_train[i])
plt.subplot(5, 5, i+1)
plt.axis('off')
plt.title(label = "Gogh" if y_train[i] == 0 else "Kandinskiy")
plt.imshow(X_train[i], cmap="gray")
#plt.show()
print(type(X_train[0]))
#次元数の確認
print(X_train[0].ndim)
# データの分割
X_train_08 = X_train[:int(len(X_train)*0.8)]
y_train_08 = y_train[:int(len(y_train)*0.8)]
X_test_02 = X_train[int(len(X_train)*0.8):]
y_test_02 = y_train[int(len(y_train)*0.8):]
# 正解ラベルをone-hotの形にする
y_train_08 = to_categorical(y_train_08)
y_test_02 = to_categorical(y_test_02)
#input_tensorの定義
input_tensor = Input(shape=(100, 100, 3))
#ivgg16の設定
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 別のモデル(全結合層)の構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# 学習済みであるvgg16と構築した別のモデル(全結合層)top_modelを連結する。
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みをfor文を用いて固定する。
for layer in model.layers[:19]:
layer.trainable = False
#コンパイル、(最適化関数はsgdで良いか?)
model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"])
#出力
model.summary()
#モデルの学習
history = model.fit(X_train_08, y_train_08, batch_size=32, epochs=30, verbose=1, validation_data=(X_test_02, y_test_02))
#精度の評価
scores = model.evaluate(X_test_02, y_test_02, verbose=1)
print("Test loss:", scores[0])
print("Test accuracy:", scores[1])
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test_02[i])
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
# 画像を一枚受け取り、ゴッホかカンディンスキーかを判定して返す関数
def pred_art(img):
#img = cv2.resize(img, (100, 100))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'Gogh'
else:
return 'Kandinskiy'
#pred_art関数にKandinskiy画像を渡して予測結果が実態に即しているか目視で確認する
path_kandinskiy = os.listdir('./gdrive/My Drive/20230101/Kandinskiy/')
for i in range(5):
img = cv2.imread('./gdrive/My Drive/20230101/Kandinskiy/' + path_kandinskiy[i])
img = cv2.resize(img, (100, 100))
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_art(img))
#acc, val_accのプロット
plt.plot(history.history['accuracy'], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#以下モデルの保存ためのコード
import os
from google.colab import files
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' )
4-4. プログラムの動作結果
Epoch 30/30
5/5 [==============================] - 16s 3s/step - loss: 0.0426 - accuracy: 0.9929 - val_loss: 0.1661 - val_accuracy: 0.9444
2/2 [==============================] - 3s 371ms/step - loss: 0.1661 - accuracy: 0.9444
Test loss: 0.16614863276481628
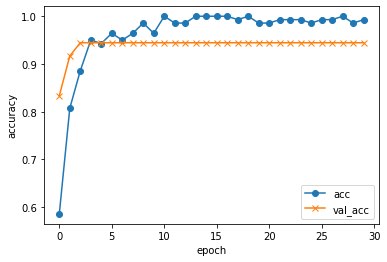
確かに9割程度の正解率になりました。
4-5. Webアプリ化
使用したもの
-
GitHub, Flask, Render
-
Webアプリ化する際のフォルダーの構成
Kaigashikibrtsu_app/
┣ Kaigashikibetsu.py
┣ model.h5
┣ README.md
┣ requirements.txt
┣static/
┗━css
┗━style.css
┣ templates/
┗━index.html
┣ uploads/
┗━gitkeep.txt
-
-
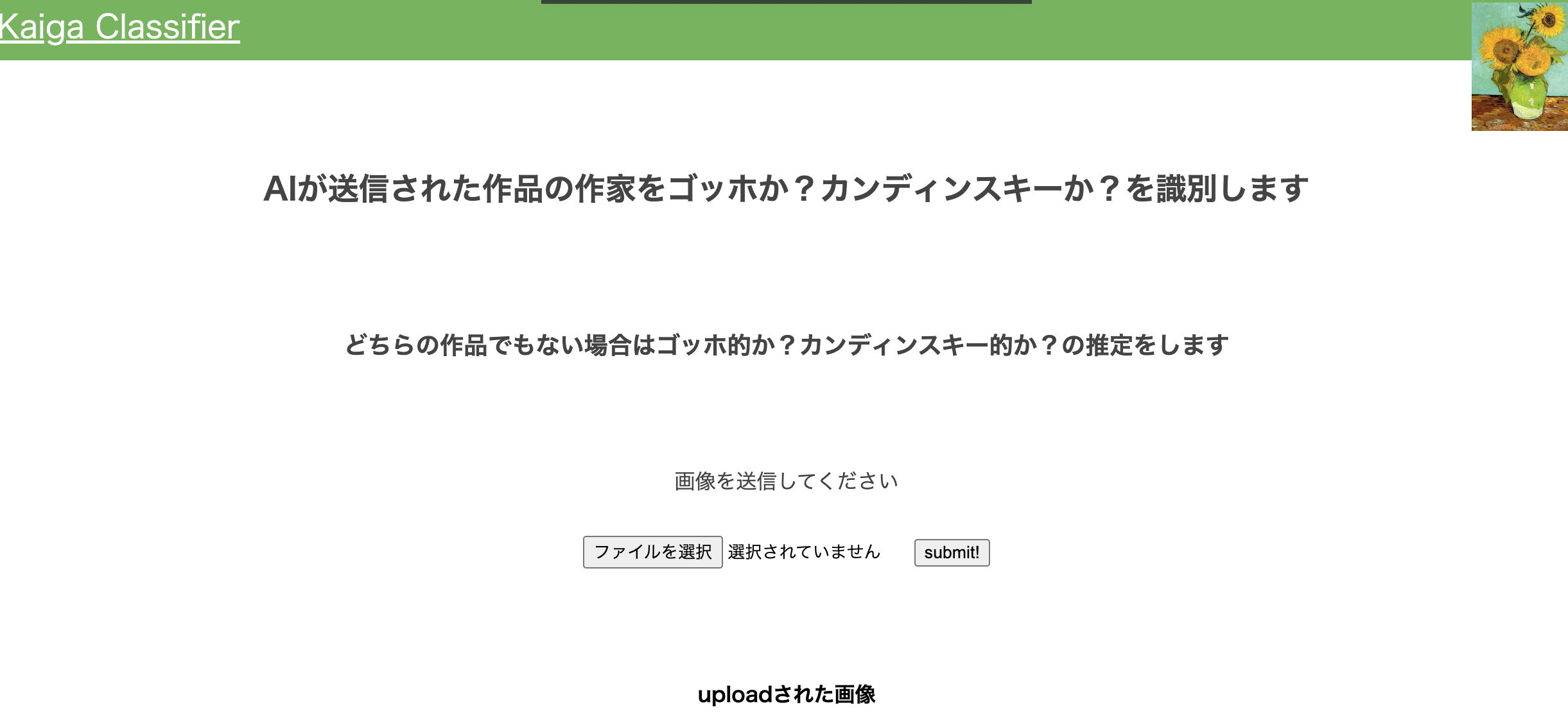
-
判別後

*上の図は正解でしたが10枚に1枚くらいの割合で間違えていました
5.感想と、今後の抱負
5-1. 感想
- 学習用データが、Kaggleにあったので、スクレイピングする必要が無かったので楽でしたが、データを集めることが、機械学習では大変なことがわかりました。
- やりたいことである描いた絵が誰の絵に似ているというようなことを示唆してくれるAIを作りたいと考えていますという目的のためには上記のように9割程度の精度で良いかもしれませんが、コントールである画家の作品の精度は100%に近づけていきたいと考えています。
そのためには訓練データ数を増やすことが取れる手段であり、下記が挙げられます。
- 訓練データの回転、反転等による画像の水増し
- スクレイピング
5-2. 今後の抱負
- ゴッホとカンディンスキーの2分類なので、多分類できるような分類器を作成したいです。
- 学習させるデータの分布等を分析し、プログラムを作成できるようになりたいです。
- 機械学習の原理をより深く理解するようにします。
- 日頃の業務で、プログラマーやSEが多忙な時、お手伝いできたら良いと思っています