はじめに
今はもはやScratchで活動してないkazuta246(ScratchのUsernameはkazuta123)と申します。
なんか急に記事を書きたくなったので、過去作の一つであるPDTEについて詳しく紹介していきたいと思いますが、1つの記事ですべて紹介しようとすると長くなってしまうのでいくつかのパートに分けて紹介しようと思います。
Part1はPDTEとは何か、そして描画前の処理までを説明します。
PDTE?何それ?
PDTEってのは私の作品の一つPen Dot Text Engine(この記事ではPDTEと略すよ。)の略のこと。
簡潔に言うとそれは8Bitフォント風のペンテキという認識で構わない。
実際に文字を描画してみるとこんな風になる。

ここをクリックするとPDTEにアクセスできるからよかったら見てってね(露骨な宣伝)
まずペンテキって何?
ペンテキとはPen Text Engineの略(この記事ではペンテキと略すよ。)であり、Scratchの"ペン"という機能で文字を書くシステムのようなもののこと。ペンというと制限が結構厳しそうと思う人もいるかもしれないが、割と自由度が高く、Scratchでは様々なペンテキが転がってるので調べてみるのも面白いかもしれない。
前置きが長くなってしまったが早速本題に入ろう。
裏側を紹介していくよ
1.文字のデータ化
まずペンテキを作るにおいて必要なことは、文字をデータ化すること。
言い換えれば、文字の書き方を指示しなければならないのだ。当然、文字の書き方を指定していない状態ではペンテキは動かせない。
PDTEでは、7*7のそれぞれのマス目を塗るか塗らないかの組み合わせで文字を表現しているのだが、塗らない場合を0、塗る場合を1として49マスそれぞれをデータ化としている。
具体的な方法は、一番左上のマスが1文字目に対応し、その右隣のマスが2文字目に対応して・・・一番右下のマスが49文字目に対応するという方法だが、これは言葉での説明が難しいので画像を使って説明することとする。
Aという文字は、PDTEにおいて次の画像のように表示される。

これに枠線をつけて、何文字目がどのマスに対応しているかを示した画像が次の画像である。
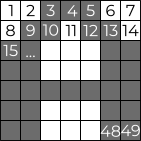
1とかかれている左上のマスは色を塗らないマスなので、Aを表すデータの1文字目は0となる。その右隣も塗られていないので2文字目も0となる。さらにその右隣は色が塗られているので3文字目は1。こうしてデータを作ると、Aの文字データは
0011100011011011000111100011111111111000111100011
となる。
これを繰り返し、使用可能にしたい全ての文字データを作って、データ化は完了だ。データはリストにまとめて保存しておく。
2.文字幅の計算
文字と文字の間隔は整っていた方が見栄えがいい。
そのためには、それぞれの文字の幅を計算しなければならないのだが、この処理は文字データを分析して最初の処理の一部として行っている。
例えば小文字のaの場合、

画像を見ればわかる通り、左から1列目から6列目までを使用しているので、この文字の幅は6となる。
一番右になる列が何列目か、と一番左になる列が何列目か、をコードから読み取り、どれくらいの幅になるのかを割り出している。
文字幅のデータを文字自体のデータとは別のリストに保存して、この処理は完了。
3.データの圧縮
バージョンアップで、コードを圧縮して描画方法も改良することで、動作速度の向上に成功したが、コードの圧縮は文字幅を計算した後に行う。理由は簡単、文字の幅を計算するには圧縮前のコードのほうが楽だからである。
圧縮方法は、0と1のコードを「行ごとに何マス白→黒→白→黒→...が連続しているか」に変換している。
具体的な方法はまたAのコードを例にして解説する。
まず一番上の行を見てほしい。
左から白が2マス、黒が3マス、白が2マスと連続しているので、圧縮後の最初の3文字は232となる。
そしてそれに続く上から2行目を表す部分は12121となる。
3行目はちょっと難しい。一番左が黒なのである。こんなときは「最初に白が0マス」と考えて、0を先に入れる。つまり3行目のデータは0232となる。
これを最後まで行うと、圧縮後のAのデータは、
23212121023202320702320232
となる。
圧縮後のデータで、圧縮前のデータを置き換えてこの処理も完了。
4.文字とデータを対応させるには?
便宜上、PDTEを実行する定義の引数の1つに入力したい文を入力することでそれを実行できるようにする必要があるが、そうするためには文字とその文字を表すデータを対応させなければならない。
しかし、それはあまり難しい話ではない。次のやり方で、対応させることができる。
1.最初の処理で、使う文字をすべて変数に書き出す。

2.変数に入力した文字の順番と同じになるように、それぞれの文字に対応する文字データをすべてリストに追加する。

変数の1文字目である、小文字のaに対応するデータが、dataリストの1番目の要素、つまり
0000000000000001111101100110110011011011100110110に対応し、2文字目であるbはdataリストのその次の要素である
1100000110000011111001100110110011011001101111100に対応し、さらに3文字目であるcはdataリストの3番目の要素...という風に対応している。
終わりに
初めて記事を作成してみたが、感じたことは一つ、
**日本語で説明するの難しすぎね?**ということである。
頭の中ではわかっていても、それを説明するとなるとかなり難しかったが、同時にこの記事を書いていて楽しかったとも感じた。
さて、ここまででようやく最初の処理部分が終了したところである。Part2ではいよいよ描画する方向に入っていくので記事が完成するまでお楽しみに。