Rによる機械学習
(ソフトウェア品質技術者のための)データ分析勉強会で、書籍『Rによる機械学習 (Machine Learning with R)』を使用して機械学習を学ぶ。
https://www.amazon.co.jp/dp/4798145114/
第5章 分割統治 -決定木と分類ルールを使った分類-
疑問点
- 均一性って何?
- 純粋性と同じような意味。
- エントロピーって何?
- 純粋性(インスタンスのサブセットが一つのクラスだけに属する度合い)の測定方法。
- エントロピーは低いほうがいい。
- 最終的に求めたい予測値は目的変数という?
- 目的変数と言ってよい。
- C5.0アルゴリズムではターゲット因子ベクトルともいう
- 学習データに偏りがあっても(yesかnoかを求めるときに学習データがyesのデータばかりでも)、性能は大丈夫?
- 誤りコストというテクニックで補える?
- 機械学習の手法すべて学習データは目的変数のバランスがよいほうがよい。未知のデータは予測できない。
- ブースティング
- 決定木だけで使われる言葉ではなく、機械学習の他の手法でも使われる言葉?
- 複数の決定木を作り、複数の決定木から出てきた結果を重みをつけて多数決するような感じ。各決定木の信頼度をもとに、重みをつけるみたい。
- ホールドアウト検証と交差検証?
- @sampoさんが違いをまとめてくれた。
- https://k-metrics.netlify.com/post/2019-09/cv/
前提知識
データの無作為抽出の方法
データを訓練データとテストデータに分ける。そのときに、無作為抽出が使える。
Rではsample()関数とset.seed()関数が使える。
prop.table()関数でバランスよくデータ抽出できたかが確認できる。
誤り率の算出方法
下のモデルの性能評価結果の「actual default:yesかつpredicted default:no」と「actual default:noかつpredicted default:yes」の割合を足したものを誤り率と言う。以下の場合、0.3=0.2+0.1である。
| predicted default
actual default | no | yes | Row Total |
---------------|-----------|-----------|-----------|
no | 55 | 10 | 65 |
| 0.550 | 0.100 | |
---------------|-----------|-----------|-----------|
yes | 20 | 15 | 35 |
| 0.200 | 0.150 | |
---------------|-----------|-----------|-----------|
Column Total | 75 | 25 | 100 |
---------------|-----------|-----------|-----------|
決定木
書籍通りに実施しれば結果が得られる。
誤りのコストの指定をすると、いい感じの結果が得られるようになる。
起こしたくない判断誤りを防ぐために、誤りのコストの指定をする。
分類ルール
書籍通りに実施しれば結果が得られる。
おまけ
rpartを使ってみやすい決定木をつくる
https://www.marketechlabo.com/r-decision-tree/
https://qiita.com/nkjm/items/e751e49c7d2c619cbeab#決定木でデータを分析する
> install.packages("rpart")
> install.packages("rpart.plot")
> credit <- read.csv("credit.csv")
> credit_train <- credit[-17]
> model_credit <- rpart::rpart(default ~ ., credit)
> rpart.plot::rpart.plot(model_credit, extra = 1, type = 2)
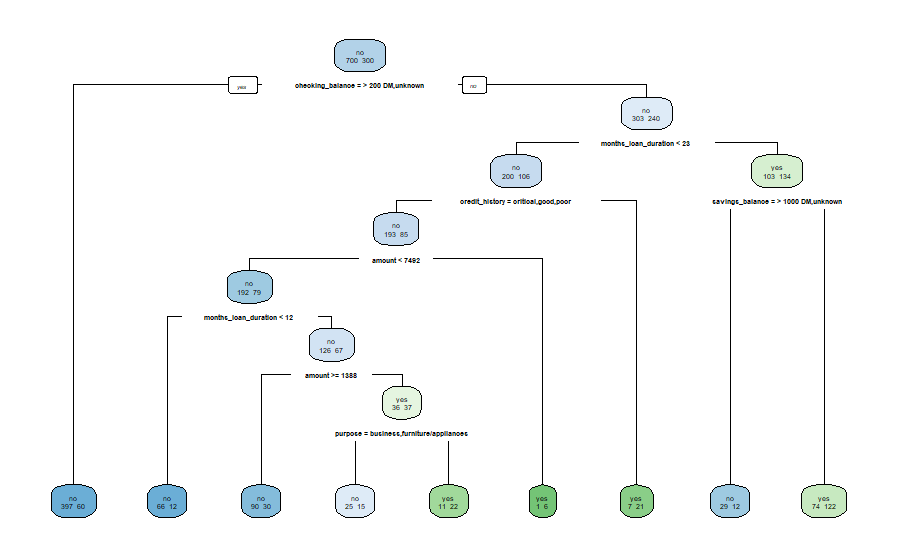
ロジスティック回帰分析を使用すると
説明変数を連続値のデータに変換することで、ロジスティック回帰分析+逐次選択法(ステップワイズ法)を使用し、決定木と同じようなモデルを作成できる可能性もある。
演習時のトラブル
- C50パッケージをロードしたらWarningが出た。Warning出た状態でも、とりあえず動いた。
> library(C50)
Warning: パッケージ 'C50' はバージョン 3.6.1 の R の下で造られました
- R3.6.0以降は乱数生成アルゴリズムが変更され、set.seed()関数をつかっても、sample()関数による無作為抽出の結果は再現しない。なので、本の通りにやっても本とは違う結果が出る(Tree Sizeが変わる)。