こちらは AWS Containers Advent Calendar 2020 の4日目の記事です。
メッセージキューイングサービス「Amazon SQS」をご存知でしょうか。
複数のサービス間連携を疎結合にするために利用されている方も多いのではないでしょうか。
その中で、SQS にキューイングされたメッセージ数に応じて、メッセージを取り出す Worker の数を AutoScaling させたいことってありませんか?
EC2 インスタンスを worker として利用する場合の手順は、ドキュメント に記載があります。
実際のユースケースでは、worker として、AWS Lambda が使われていたり、AWS Fargate が使われていたり、色々なパターンがあるかと思います。
そこで、本記事では、このドキュメントを参考にしながら、Amazon ECS on AWS Fargate を worker として利用した際の、AutoScaling の実装方法について紹介したいと思います。
さっそく構成図
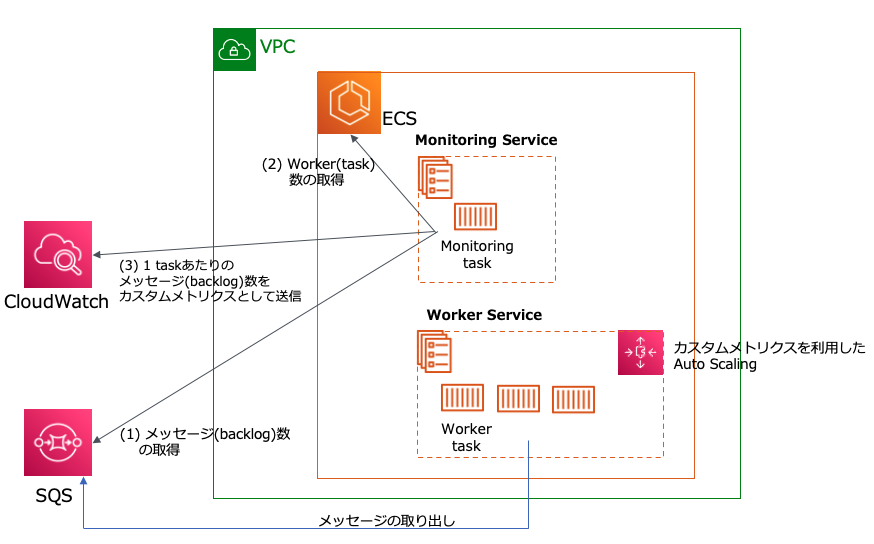
何をしているか?
- ECS 上に 2つのサービスを作成します。
- 1つ目は、Monitoring用(monitoring-service)です。具体的には、SQSのメッセージ数とWorker数から 1workerあたりのメッセージ(backlog)数を計算して、CloudWatchカスタムメトリクスとして登録します。
- 2つ目は、Worker用(worker-serivce)です。SQSからメッセージの取り出しを行います。カスタムメトリクスを指標にした、ターゲットトラッキングポリシーを設定することで、backlog数に応じてtask数のAutoScalingが行われます。
Monitoring Service(monitoring-service) について
こちらはドキュメントでいう「ステップ 1: CloudWatchカスタムメトリクスを作成する」の部分の実装例になります。
- SQS のメッセージ数(ApproximateNumberOfMessages)を取得
- ECS 上の Worker Service(worker-service)で動いているタスク数を取得
- 1タスクあたりのメッセージ(backlog)数を算出し、CloudWatch カスタムメトリクスへ登録
- 上記の動きを1分に一度に行う
(Dockerfile、タスク定義、サービスなどの詳細は割愛しています)
import boto3
import time
session = boto3.Session(region_name="us-east-1")
sqs = session.resource('sqs')
ecs = session.client('ecs')
cloudwatch = session.client('cloudwatch')
while True:
# メッセージ(backlog)数を取得
queue = sqs.get_queue_by_name(QueueName="qiita-sqs")
msgs = queue.attributes.get('ApproximateNumberOfMessages')
# workerとして動いているtask数を取得
response = ecs.describe_services(
cluster='QiitaCluster',
services=[
'worker-service'
]
)
tasks = response['services'][0]['runningCount']
# 1taskあたりのblacklog数の算出
if int(tasks) == 0: # taskが動いていない場合
backlog = int(msgs)
else:
backlog = int(msgs) / int(tasks)
# 1taskあたりのblacklog数をカスタムメトリクスとして送信
cloudwatch.put_metric_data(
MetricData=[
{
'MetricName': 'backlogpertask',
'Dimensions': [
{
'Name': 'SQSName',
'Value': "qiita-sqs"
},
],
'Unit': 'Count',
'Value': backlog
},
],
Namespace='SQS/BACKLOG'
)
time.sleep(60)
これで、1タスクあたりのbacklog数が、CloudWatch カスタムメトリクスとして取得できるようになります。
Worker Service(worker-service)について
取り出したメッセージは、実際のワークロードの場合は、何らかの処理をするかと思いますが、この記事では簡素化のため、取り出したメッセージは「何もせず、すぐに削除する」実装になっています。
(Dockerfile、タスク定義、サービスなどの詳細は割愛しています)
import boto3
import time
session = boto3.Session(region_name="us-east-1")
sqs = session.resource('sqs')
while True:
# メッセージを取得
queue = sqs.get_queue_by_name(QueueName="qiita-sqs")
msgs = queue.receive_messages(MaxNumberOfMessages=10)
if msgs:
for msg in msgs:
# 取得次第、消す
msg.delete()
# なんとなく少しsleepしてみる
time.sleep(0.2)
Worker Service(worker-serivce)のターゲットトラッキングポリシー設定
ECS Service の AutoScaling 設定方法自体は、こちら に記載されています。
しかし、現時点では、マネジメントコンソールでは、カスタムメトリクスを使用したターゲットトラッキングポリシーは設定できないため、本記事では AWS CLI で設定を行います。
TargetValue(1 taskあたりのbacklog目標値)は、実際のワークロードの場合は慎重に決める必要がありますが、ここではドキュメントの設定例と同じ 100 に設定しています。
{
"TargetValue": 100.0,
"CustomizedMetricSpecification": {
"MetricName": "backlogpertask",
"Namespace": "SQS/BACKLOG",
"Dimensions": [
{
"Name": "SQSName",
"Value": "qiita-sqs"
}
],
"Statistic": "Average",
"Unit": "Count"
},
"ScaleOutCooldown": 60,
"ScaleInCooldown": 60
}
aws application-autoscaling put-scaling-policy --service-namespace ecs --scalable-dimension ecs:service:DesiredCount --resource-id service/QiitaCluster/worker-service --policy-name backlog100-target-tracking-scaling-policy --policy-type TargetTrackingScaling --target-tracking-scaling-policy-configuration file://config.json
こちらで、カスタムメトリクスを使用したターゲットトラッキングポリシーが設定できました。
動作確認
SQSにメッセージ投入
- SQS のスタンダードキューとして「qiita-sqs」を作成
- なんらかの方法でSQSへ大量のメッセージを投入(私は単純なシェルスクリプトを書いて、ローカル環境で多重起動しました)
ApproximateNumberOfMessages の確認
この時点では、まだ worker は作成していないため、SQSにメッセージが貯まり続けています。
- ApproximateNumberOfMessagesの値は CloudWatch メトリクスでは確認できないため、ここでは ApproximateNumberOfMessagesVisible のメトリクスを表示しています
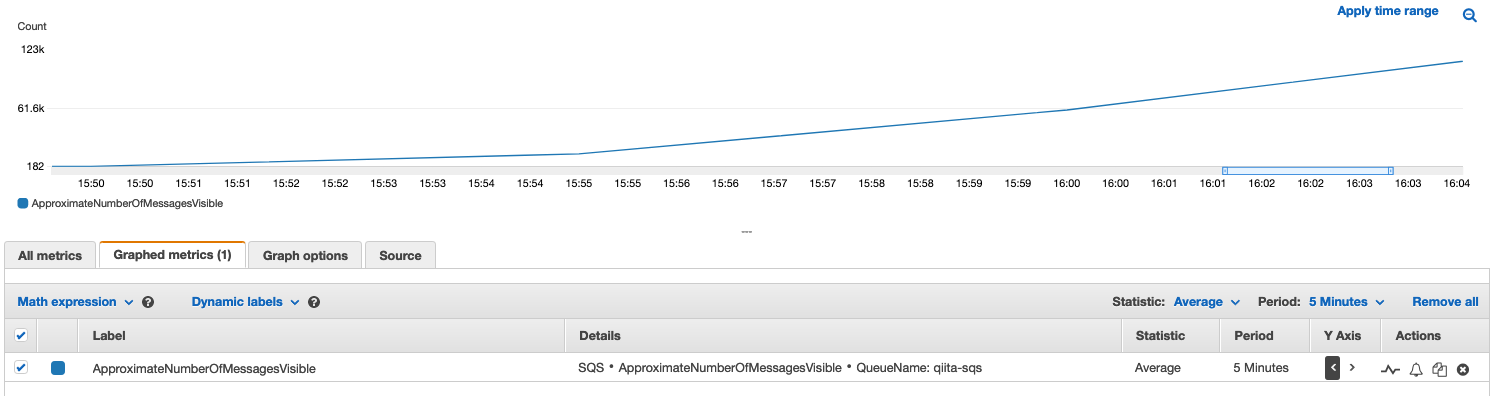
monitoring-serviceの作成とカスタムメトリクスの確認
1 taskあたりのbacklog数を算出し、カスタムメトリクスとして登録するための service を作成しました。
この時点では、まだ worker は作成していないため、1 taskあたりのbacklog数 = SQS内のメッセージ数 となり、値が増え続けていることがわかります。
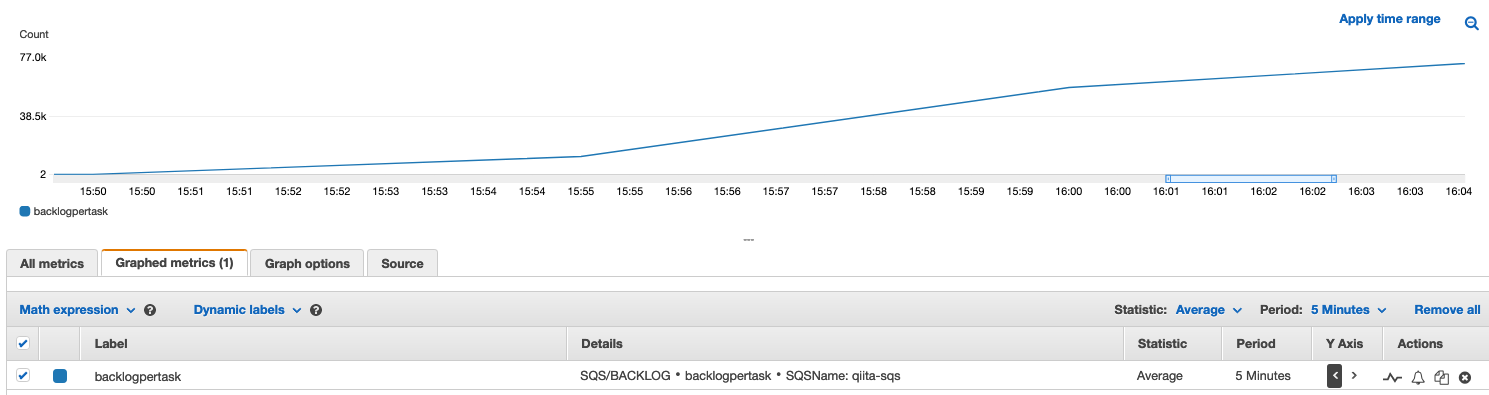
worker-serviceの作成
実際に SQSからメッセージを取り出す、worker service を作成しました。
作成後に、カスタムメトリクスを使用したターゲットトラッキングポリシーを設定しています。(サービス作成時は 1 task のみ起動, Max 10 taskまでスケーリング)

前述のカスタムメトリクス(1taskあたりのbacklog数)は 100 を遥かに超えているので、AutoScalingが発動して、
task数が増え、その結果、カスタムメトリクス(1taskあたりのbacklog数)の値が減少していくはずです。
task数の推移
CloudWatch Container Insights のメトリクスで 起動しているタスク数を確認することができます。 task数は想定通り、初期値の1 から徐々に増えて、最大値に設定した 10 task まで増えていることが分かります。
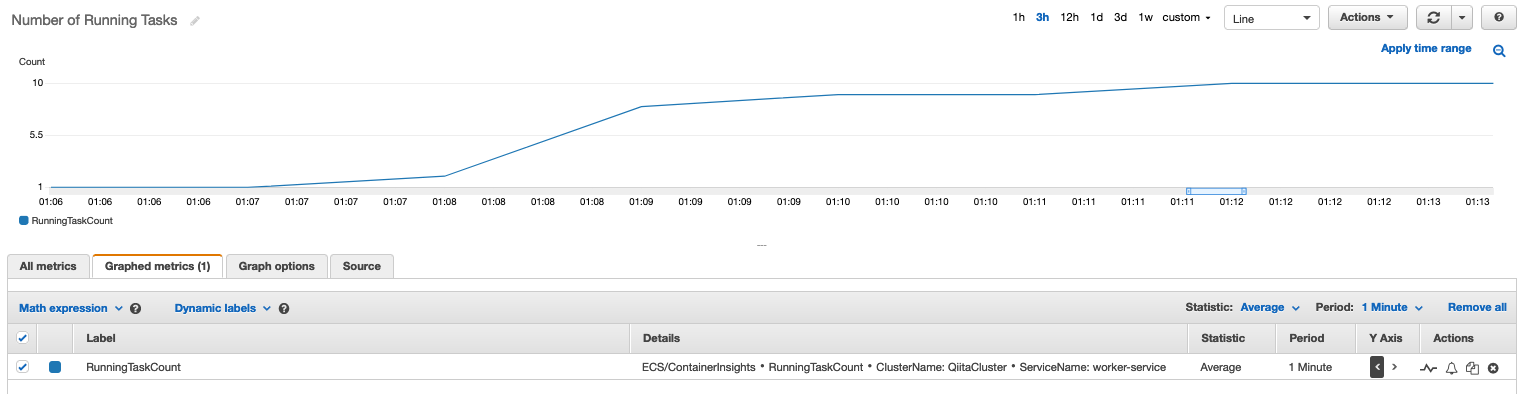
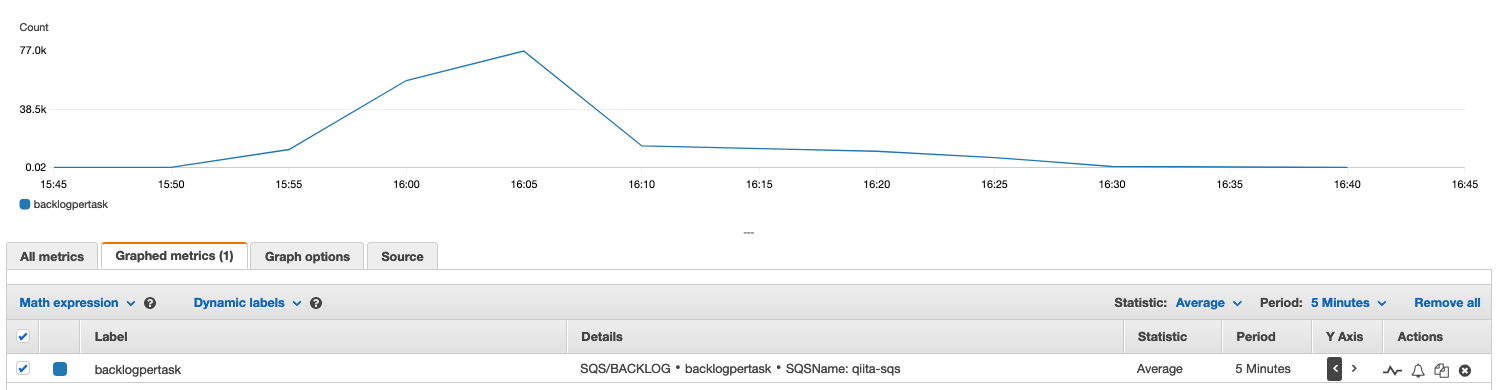
カスタムメトリクスの推移
いまは、workerの数が増え、どんどん SQS からメッセージを取り出している状態なので、カスタムメトリクス(1taskあたりのbacklog数)も減っていることが分かります。
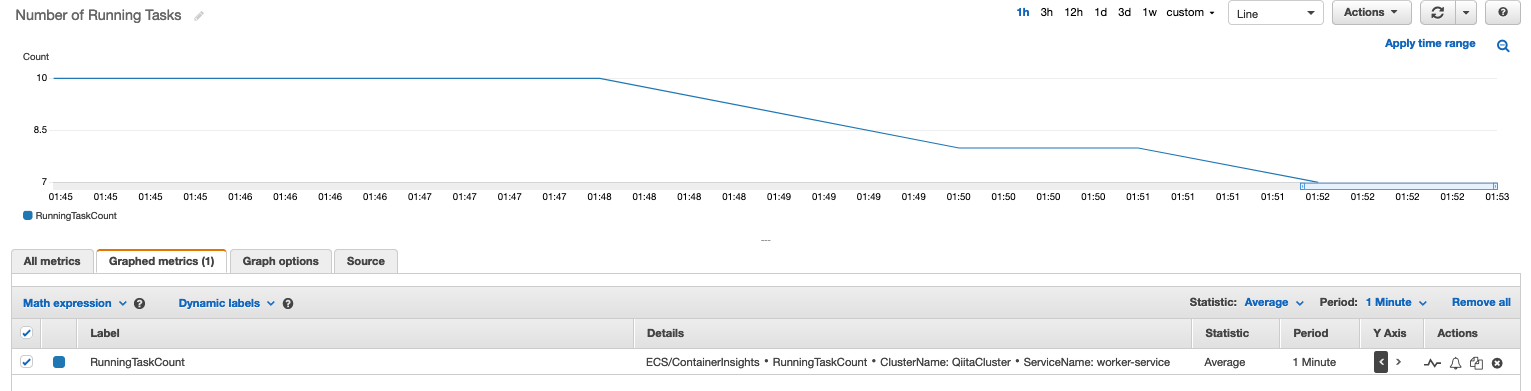
task数のスケールイン
カスタムメトリクスの値がターゲットである100以下になっているため、暫くするとtask数のスケールインが発生します。
(まだスケールインの途中でのスクショですが、task数が 10 -> 7 に減っています)
まとめ
本記事では、AWSのドキュメントを参考にしながら、Amazon ECS on AWS Fargate を SQS の worker として利用した際の、AutoScaling の実装パターンの1例について紹介しました。
AutoScalingの実装方法に悩まれている方、もしくは、これから設定しようとされている方のお役にたてば幸いです。