前編はこちら
さてここでは前編の論文を元に RIG の中身及び推察されることを記述する。
RIG の処理概要
まずは処理詳細に入るまでに、ユーザーの入力と出力に注目してみよう。RIG の処理フローは論文のとおり以下の図の真ん中のフローである。
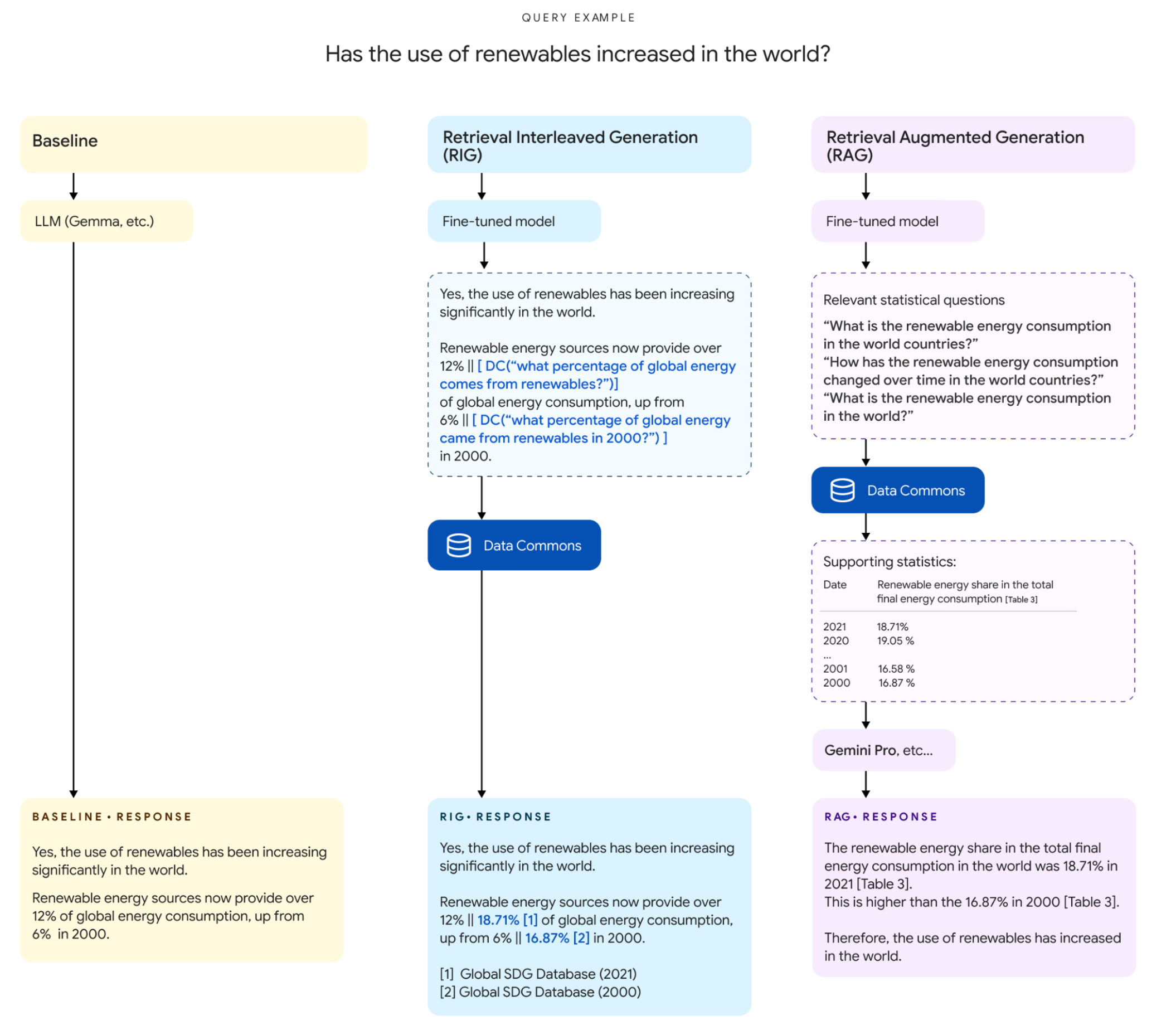
(Data Commons と LLM のインターフェースより転載)
ユーザーのクエリが、
Has the use of renewables increased in the world?
(筆者訳: 世界で再生可能エネルギーの使用は増えていますか?)
である。
そのクエリが Fine-tune されたモデルを通じると以下のように変換される。
Yes, the use of renewables has been increasing significantly in theworld.
Renewable energy sources now provide over 12% || [DC("what percentage of global energy comes from renwables?")] of global energy consumption,
up from 6% || [DC("what percentage of global energy came from renewables in 2000?")] in 2000.
(筆者訳:
再生可能エネルギーの供給は現在、世界のエネルギー消費量の 12% 以上 || [DC("再生可能エネルギーが世界のエネルギー供給に占める割合はどのくらいですか?")] を占め、
2000年 の 6% || [DC("2000年に世界のエネルギーのどの割合が再生可能エネルギーからだったのか?")] から増加しています。
)
(注 : 読みやすさを優先して改行を追加しています)
回答の原型と、そして回答に使用する数値の部分に自然言語のクエリを挿入した形で出力されました。
そして DataCommons を通すことで、最終的に以下の回答を出力します。
Yes, the use of renewables has been increasing significantly in the world.
renewable energy sources now provide over 12% || 18.71%[1] of global energy consumption, up from 6% || 16.87%[2] in 2000.
[1] Global SDG Database(2021)
[2] Global SDG Database(2000)
(筆者訳:
はい、再生可能エネルギーの利用は世界で大幅に増加しています。
再生可能エネルギー源は現在、世界のエネルギー消費の 12% 以上 || 18.71%[1] を占めるまでになり、2000 年の6% || 16.87%[2] から増加しています。
[1] Global SDG Database(2021)
[2] Global SDG Database(2000)
)
先ほど自然言語のクエリに実数及び引用が入りました。
筆者の推測:
このように自然言語のクエリを介してデータソースを参照する仕組みのようです。
RAG 同様にデータソースは参照するものの、生成した後にデータを挿入するのが RIG、
データを参照した後に生成するのが RAG なのでしょうか。
また、RIG の I 、つまり Interleaved はどこに相当するのか、
おそらく、自然言語クエリが複数入るのでそこを一つずつ置き換えていく部分が
Interleaved に該当する予感です。
ではその処理の中身を除いてみましょう。
処理詳細
原文の Retrieve Ingerleaved Generation(RIG) 節に詳細があります。
RIG はパイプラインで 3 つのコンポーネントでそれがシリアルに動くようです。
1つ目が Fine-Tuning したモデル、2 つ目が自然言語クエリを構造化データクエリへ変換、最後に Data Commons からデータを取得して回答にマージする処理です。
Fine Tuning したモデル
まずこのモデルで出力させたい狙いを考えます。
一般的に質問に対して生成 AI で回答させると、統計値を含む回答を生成します。
例)
Q: 2024 年の日本の人口は?
A: およそ 1 億 2 千万人です
ここで回答の 「1 億 2000 万人」 を LLM 生成統計値 (LLM-SV, LLM-generated Statical Value) とします。
LLM-SV は生成 AI が確率に基づいて出力する以上、ハルシネーションを含む可能性があります。
また、ある時点でハルシネーションじゃなかったとしても、時系列で正解が変化も当然あります。
(これから日本の人口は減っていく見込みですし)
そこで、外部のデータソースに頼る(論文中だと Data Commons)ことを考えます。
外部のデータソースで最も関連性の高い値を特定し、元の生成値とともにユーザーに提供することで、ファクトチェックのメカニズムとして機能させます。
外部のデータソースから取得した値を論文中では Data Commons 統計値 (DC-SV, Data Commons Statical Value) と読んでいます。
RIG を抽象化した場合必ずしも Data Commons がデータソースとは限らないですが、DC-SV とここでも呼ぶこととします。
このモデルでは、元の LLM-SV の後に LLM-SV を説明するための(≒ 筆者推論: DC-SV を問い合わせるための)自然言語のクエリを出力させます。
例)
Q: 2024 年の日本の人口は?
Model: およそ 1 億 2000 万人 || [DC("2024 年の日本の人口は?")] です。
本項の Fine Tuning したモデルというのはまさにこのような出力をするように Fine Tuning されたものです。
そのモデル自体は Hugging Face 及び Kuggle で公開されています。
Hugging Face
Kaggle
gemma-2-27b を instruction tuning した gemma-2-27b をさらに合成データで先程のような出力をするように Fine Tuning しています。
GGUF で量子化したモデルがたくさんある(筆者確認時点で8つ)ので、こちらを使ってみるといいでしょう。
今回論文で使っている datagemma-rig-27b-it には、データの入出力例が書かれているのでそちらを読むと、同様の入出力であることがわかる。
# 筆者にて読みやすさのため改行を挿入
What are some interesting trends in Sunnyvale spanning gender,
age, race, immigration, health conditions, economic conditions, crime and education?
Sunnyvale, CA has seen significant progress in gender, age, and educational demographics in recent years. Here's a breakdown:
**Gender:**
* **Overall:** Sunnyvale has a relatively equal gender distribution, with a slight skew towards male residents.
* **Recent Shifts:**
* **2010-2020:** The female population in Sunnyvale has been steadily increasing, reaching a [__DC__("what was the percentage of females in Sunnyvale, CA in 2020?") --> "51.6%"] majority in 2020. This is largely due to its proximity to Silicon Valley and the increasing number of women working in tech.
* **Age:** Sunnyvale has a relatively young population, with a median age of around [__DC__("what was the median age of residents in Sunnyvale, CA in 2020?") --> "35"]. This reflects the dominance of the tech industry, which tends to favor younger demographics.
* **Immigration:** Sunnyvale has a significant immigrant population, with many residents hailing from countries in Central and South America, Asia, and the Middle East.
**Age:**
* **Recent Shifts:**
* **2010-2020:** Sunnyvale has seen a slight decrease in the median age, driven by a competitive job market and a desire for better work-life balance.
* **Aging Population:** While Sunnyvale has a young population overall, it's also aging. This means the proportion of older residents is increasing, which can put pressure on healthcare and social services.
**Race & Ethnicity:**
* **Majority-Minority City:** Sunnyvale is a majority-minority city, meaning that no single racial or ethnic group constitutes a majority of the population.
* **Key Demographics:**
* **White:** [__DC__("what percentage of residents in Sunnyvale, CA are white in 2020?") --> "55.1%"]
* **Hispanic or Latino:** [__DC__("what percentage of residents in Sunnyvale, CA are hispanic or latino in 2020?") --> "30.6%"]
* **Asian:** [__DC__("what percentage of residents in Sunnyvale, CA are asian in 2020?") --> "16.8%"]
* **Black or African American:** [__DC__("what percentage of residents in Sunnyvale, CA are black or african american in 2020?") --> "3.6%"]
* **Other:** [__DC__("what percentage of residents in Sunnyvale, CA are classified as other race in 2020?") --> "0.5%"]
* **Trends & Issues:**
* **Tech Dominance:** Sunnyvale's proximity to tech jobs drives a younger, more diverse workforce.
* **Education & Income:**
A highly educated population in Sunnyvale translates to a highly skilled workforce, commanding higher salaries on average.
* **Racial & Ethnic Diversity:**
The city's commitment to diversity and inclusion is reflected in its demographics.
* **Aging Population:**
The aging population presents challenges for healthcare and social services, while a younger population puts pressure on schools and childcare.
**Economic Conditions:**
* **Low Unemployment Rate:** Sunnyvale consistently boasts a low unemployment rate, indicating a strong tech sector.
* **High Median Household Income:**
The median household income in Sunnyvale is significantly higher than the national average, driven by the high demand for skilled labor in the area.
* **Competitive Landscape:** Sunnyvale faces increasing competition for skilled workers and struggles with housing affordability and traffic congestion.
**Education Levels:**
* **High Percentage of Adults with Bachelor's Degree or Higher:**
A highly educated population is a key driver of the city's workforce and economy.
* **Emphasis on STEM Education & Innovation:**
Sunnyvale schools place a strong emphasis on STEM education and innovation, reflecting the region's tech-driven culture.
**Challenges:**
* **Gender Gap:**
The tech industry has a persistent gender gap, with women holding a smaller percentage of jobs than men.
* **Age Diversity:**
While Sunnyvale has a young population overall, it's important to ensure a balance of age groups in the workforce.
* **Immigration Policy:**
Immigration policy debates and enforcement can create uncertainty and hardship for immigrant communities.
**Resources:**
* **Sunnyvale Chamber of Commerce:** https://www.sunnyvalecoc.org/
* **City of Sunnyvale:** https://www.sunnyvale.ca.gov/
* **Stanford University:** https://www.stanford.edu/
**Note:**
These are just overarching trends. It's important to consult reliable sources like the U.S. Census Bureau and the Bureau of Labor Statistics for more detailed and up-to-date information.
いくつか論文の例と、モデルのサンプル入出力で違うところを上げておくと、
- 必ずしも数字の後に自然言語クエリが出力されるわけではない
筆者解釈: このモデルが吐き出す数字そのものにハルシネーションを含む可能性があるため、それはそのほうがいいと思う。ただし、原文ではOur approach is to fine-tune the LLM to produce a natural language query describing the LLM-SV, appearing alongside the original LLM-SV .とあるとおり、LLM-SV を出力するとにこだわりがありそうで、そこはよくわからない - 論文中は || [DC("XX")] という書き方だったが、 モデルは [DC(XX)--> "YY"] という形で書く
筆者解釈: 後のステップの構造化されたクエリを出力するための工夫と思われる。また最後の LLM を使って置換し、数字の大きさで表現(大きくなった、小さくなった、など)を変えると思われる
さて、このように回答の素案の中に自然言語クエリを埋め込むのが RIG における重要な特徴のようだが、なぜあえて自然言語のクエリで構造化されたクエリ(Ex:SQL) ではないのかが論文中に 3 つ明記されている。
- 自然言語クエリは構造化クエリよりも簡単である
- DataCommons とのデータとのマッピングを Fine Tuninng で教え込むのは大変
- LLM にクエリを自然言語で表現することは、文脈から関係を推定するより簡単
(筆者解釈:
まず 1 つ目と 2 つ目の理由は以下の例で考えられそうです。
上に 2024 年の日本の人口について問い合わせする例を記述しましたが、実際に SQL でクエリを作るとしたら以下のようなクエリになるでしょう。
select
population
from
demographics
where
country = 'Japan'
and year = 2024
;
このとき、population, country, yaar というカラム名や、demographics というテーブル名(あるいはときにデータベース名やスキーマ名が入る場合も) といったことを LLM に覚えさせるのは大変です(2 の理由)。加えて、LLM の難易度として、正確な SQL を書くよりは自然言語で 2024 年の日本の人口は?というクエリを出力させたほうが楽でしょう。また、LLM-SV は複数ある可能性があるためその都度 LLM-SV を問い合わせる SQL を出力するのはタスクとして難しいというのは理解できます。ここからはさらなる推測ですが、関連して 3 で前後の文脈を読んだ SQL を出力するよりは、やはり自然言語クエリを出力するほうが楽でしょう。これは、難しいタスクを複数のステップに分けてそれぞれモデルに出力させたほうが精度は向上しやすいのと同じであると考えられます。
一方、どこかでクエリを投げるときには一般的なデータベース及び本論文の場合は DataCommons で定義したクエリの形式(=構造化されたクエリ)に則る必要があり、まだ解決されていません。
)
このモデルでは 700 個のユーザークエリのセットで学習したそうで、ベースモデルから 400 の統計情報を含む回答を選択し、より高性能な LLM (論文では Gemini 1.5 Pro) を用いて、Data Commons に対する自然言語クエリをするよう指示したものを出力させます(3-shots)。このとき統計値と単位(ある場合のみ)のみに注釈をつけるよう指示しています。そしてそれを学習させますが、上手く Gemini Pro 1.5 Pro が出力しなかった場合は人が直したそうです。
つまり、結局のところ統計値を含む回答は自然言語クエリをつけて出力するように fine tuning しました。
クエリ変換
前のステップで Fine Tune したモデルが回答の LLM-SV に対して自然言語クエリをつけて結果を返しているので、それに対する後続処理を行います。具体的には、自然言語クエリを構造化クエリにします。
まず、クエリをコンポーネントに分解します。
1 つ以上の(=必ず 1 つはある) unemployment rate(失業率), demographics(人口) などの統計変数やトピック、1 つ以上の(=必ず 1 つはある) California(カリフォルニア) などの場所、そして有限の属性セット(ランキング、比較、変化率、etc...), です。
変数と場所はさらに Data Commons の対応する ID にマッピングされます。
各コンポーネントに対して自然言語処理を適用します。統計変数にはセマンティックサーチインデックス、場所には文字列ベースの固有表現認識、属性検出には正規表現ベースのヒューリスティックセットを使用します。
この中身について実装を覗いてみます。
こちらにノートブックがあるので、処理を追ってみます。
まず、
…
import data_gemma as dg
…
ans = dg.RIGFlow(llm=datagemma_model_wrapper, data_fetcher=dc, verbose=False).query(query=QUERY)
…
とあるので、data_gemma から RIGFlow を見てみます。
53 行目に query メソッドがあり、ここを追っていくと良さそうです。
76 行目に
# Make DC calls.
llm_text = llm_resp.response
q2llmval, q2resp, dc_duration = self._call_dc(llm_text)
# Sanity check DC call and response using LLM, and keep only the "good"
# ones.
if self.validate_dc_responses:
q2resp = validate.run_validation(q2resp, self.llm, self.options,
llm_calls)
とあり、_call_dc が DataCommons にリクエストをしているように見えます。
def _call_dc(
self, llm_text: str
) -> tuple[dict[str, list[str]], dict[str, base.DataCommonsCall], float]:
"""Calls DC."""
start = time.time()
q2llmval: dict[str, list[str]] = {}
for match in re.findall(_DC_PATTERN, llm_text):
q2llmval.setdefault(match[0], []).append(match[1])
try:
q2resp = self.data_fetcher.calln(list(q2llmval.keys()),
self.data_fetcher.point)
except Exception as e:
logging.warning(e)
q2resp = {}
pass
return q2llmval, q2resp, time.time() - start
_call_dc では、最初にモデルが出力した LLM-SV 及び自然言語クエリを含むテキストから [__DC__("クエリ") --> "値"] に引っかかる部分を抽出します。
そして、data_fetcher.calln() で検索します。data_fetcher の実態は 38 行目に記載があるとおり、DataCommons クラスですので、そちらから calln メソッドを見てみます。
def calln(
self, queries: list[str], func: Callable[[str], base.DataCommonsCall]
) -> dict[str, base.DataCommonsCall]:
"""Calls Data Commons API in parallel if needed."""
if self.num_threads == 1:
results = [func(q) for q in queries]
else:
# TODO: Check why this ~breaks in Colab Borg runtime
with concurrent.futures.ThreadPoolExecutor(self.num_threads) as executor:
futures = [executor.submit(func, query) for query in queries]
results = [f.result() for f in futures]
q2resp: dict[str, base.DataCommonsCall] = {}
for i, (q, r) in enumerate(zip(queries, results)):
r.id = i + 1
q2resp[q] = r
return q2resp
calln に func 引数 でクエリを処理する関数が入ってます。
呼び出し側は self.data_fetcher.point を指定していたので、こちらを見てます。
すると、以下のところで API をコールしているのがわかります。
def point(self, query: str) -> base.DataCommonsCall:
"""Calls Data Commons API."""
self.options.vlog(f'... calling DC with "{query}"')
response = self._call_api(query, _POINT_PARAMS)
この _call_api を追ってみましょう。
def _call_api(self, query: str, extra_params: str) -> Any:
query = query.strip().replace(' ', '+')
url = _BASE_URL.format(env=self.env) + f'?&q={query}&{extra_params}'
if self.api_key:
url = f'{url}&key={self.api_key}'
# print(f'DC: Calling {url}')
return self.session.get(url).json()
すると Python の requests モジュールを使って http で API をコールしているだけです。
つまり、クエリ変換は、[__DC__("クエリ") --> "値"] に引っかかる部分を抽出したあとそれをリクエストの形式を整えて http で API を叩いているだけ、と取って良さそうです。その結果よくわからないけど、構造化クエリが出力される、と(中身は結局わからん)。
実行
自然言語クエリをクエリ変換で構造化クエリにしたあとそれを実行します。
構造化クエリ実行のレスポンスには、(オプションで単位を含んだ)数値が返ります。
モデルが生成した LLM-SV + 自然言語クエリを含む回答の、自然言語クエリの部分をレスポンス及び引用をつけて処理が完了です。
結局 RIG って?どうやって応用するの?
RIG の肝としては、回答に LLM-SV を含また上でその LLM-SV の値をデータソースから問い合わせるクエリを出力し、そこに代入するというのが肝のようです。(私見マシマシ)
また、今まで自然言語クエリで直接検索サービス(Vector 検索、キーワード検索)していたところに対して、構造化クエリを持ち込んいる、というのも新規性を感じました。
ただし、DataCommons という特殊なデータソース(スキーマが決まっていて、誰かがメンテして…という条件がつく)であるから出来たというのは考えられます。
これを一般化、抽象化すると、スキーマが決まっている SQL データベースできれいにすべてのデータが保存されている、などの前提があれば可能性を感じます。
つまり、数値つきの回答を生成し、その数値を検索するSQLを生成、実行し、その数値を置き換える、のような形を取ればよく、それは自然言語クエリからスキーマ情報を読み取ってクエリを生成する、などをすればよいわけです。
もちろん必ずしも SQL 及び RDB である必要はなく、リクエストをきれいに生成できればなんでもいいはずですが。
というわけでとても実験的な技術ということで今すぐどうこうという話ではなさそうですが、楽しそうです。
次回予告
結局 DataCommons において精度はどうだったのか!?お楽しみに!