2025/2/4 に出た "Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG"(Agentic RAGの調査) v3 を訳したものです。
原文はこちら
概要
大規模言語モデル(LLM)は、人間のようなテキスト生成と自然言語理解を可能にすることで、人工知能(AI)を革新しました。しかし、静的な訓練データに依存しているため、動的で実時間のクエリに応答する能力が限られ、出力が時代遅れや不正確になる可能性があります。RAG は、この問題の解決策として登場し、LLM に実時間のデータ検索を統合することで、文脈に関連性があり最新のレスポンスを提供しています。しかし、従来のRAGシステムは静的なワークフローの制約で、多段階の推論や複雑なタスク管理に必要な適応性が欠けていました。
Agentic RAG は、これらの制限を超えるため、RAG パイプラインに自律型 AI Agent を組み込んでいます。これらの Agentic は、Agentic 設計パターンの反射、計画、ツールの使用、Multi Agent の協調を活用し、検索戦略を動的に管理し、文脈理解を段階的に洗練し、順次的なステップから適応的な協調まで、明確に定義された運用構造を通じてワークフローを適応させます。この統合により、Agentic RAGシステムは、さまざまなアプリケーションにおいて、前例のない柔軟性、スケーラビリティ、文脈認識を提供できるようになります。
この調査は、Agentic RAGの基本原理と RAG パラダイムの進化から始まり、包括的な探索を提供します。Agentic RAG アーキテクチャの詳細な分類を示し、ヘルスケア、金融、教育などの業界における主要なアプリケーションを強調し、実装戦略を検討しています。さらに、これらのシステムの拡張性、倫理的な意思決定の確保、実世界のアプリケーションのパフォーマンス最適化における課題に取り組み、Agentic RAG の実装のためのフレームワークとツールの詳細な洞察を提供しています。このサーベイの GitHub リンクは https://github.com/asinghcsu/AgenticRAG-Survey にあります。
1. 導入
大規模言語モデル(LLM)、例えば OpenAI の GPT-4、Google の PaLM、Meta の LLaMA は、人間のようなテキストを生成し、複雑な自然言語処理タスクを実行する能力により、人工知能(AI)を大きく変革しました。これらのモデルは、会話型 Agent、自動コンテンツ作成、リアルタイム翻訳など、多様な領域でイノベーションを推進しています。最近の進歩により、テキストから画像や動画を生成するなどのマルチモーダルタスクにまでその能力が拡張され、詳細な指示からビデオや画像の作成・編集が可能になり、生成AIの潜在的な応用範囲が広がっています。
これらの進歩にもかかわらず、LLM は静的な事前学習データに依存しているため、重大な制限に直面しています。この依存性は、しばしば情報の陳腐化、ハルシネーション、動的な実世界のシナリオへの適応能力の欠如をもたらします。これらの課題は、リアルタイムデータを統合し、文脈的な関連性と正確性を維持するために動的にレスポンスを洗練できるシステムの必要性を強調しています。
Retrieval-Augmented Generation(RAG) は、これらの課題に対する有望な解決策として登場しました。LLM の生成能力と外部検索メカニズムを組み合わせることで、RAG システムはレスポンスの関連性とタイムリー性を向上させます。これらのシステムは、ナレッジベース、API、またはウェブなどのソースからリアルタイムの情報を取得し、静的な学習データと動的なアプリケーションの要求の間のギャップを効果的に埋めます。しかし、従来の RAG ワークフローは、線形で静的な設計に制限されており、複雑な多段階推論の実行、深い文脈理解の統合、レスポンスの反復的な洗練能力が制限されています。
Agent の進化は、AIシステムの能力を大幅に向上させました。LLM 駆動の Agent や Mobile Agents を含む現代の Agent は、知覚、推論、タスクの自律的実行が可能な知的エンティティです。これらのAgentは、振り返り、計画、ツール使用、Multi Agent Collaboration などの Agentic パターンを活用して、意思決定と適応性を向上させています。
さらに、これらの Agent は、プロンプトチェーニング、ルーティング、並列化、オーケストレーター-ワーカーモデル、評価者-最適化者などのエージェンティックワークフローパターンを採用し、タスク実行の構造化と最適化を行います。これらのパターンを統合することで、Agentic RAG システムは動的なワークフローを効率的に管理し、複雑な問題解決シナリオに対処することができます。RAG とエージェンティックインテリジェンスの融合により、Agentic Retrieval-Augmented Generation(Agentic RAG)というパラダイムが生まれました。これは、Agent を RAG パイプラインに統合するものです。Agentic RAG は、動的な検索戦略、文脈理解、反復的な洗練を可能にし、適応的で効率的な情報処理を実現します。従来の RAG とは異なり、Agentic RAG は自律的な Agent を使用して検索を調整し、関連情報をフィルタリングし、レスポンスを洗練することで、精度と適応性が要求されるシナリオで優れた性能を発揮します。Agentic RAG の概要は Figure 1 に示されています。
この調査では、Agentic RAG の基本原則、分類、応用について探究します。RAG パラダイム(Naive RAG、Modular RAG、Graph RAG など)とそれらの Agentic RAG システムへの進化について包括的な概要を提供します。主な貢献には、Agentic RAG フレームワークの詳細な分類、ヘルスケア、金融、教育などの領域にわたる応用、実装戦略、ベンチマーク、倫理的考慮事項に関する洞察が含まれます。
本論文の構成は以下の通りです:セクション 2 では RAG とその進化を紹介し、従来のアプローチの限界を強調します。セクション 3 では Agentic インテリジェンスと Agentic パターンの原則を詳述します。セクション 4 ではAgentic ワークフローパターンを詳述します。セクション 5 では、Single Agent、Multi Agent、グラフベースのフレームワークを含む Agentic RAG システムの分類を提供します。セクション 6 では Agentic RAG フレームワークの比較分析を提供します。セクション 7 では Agentic RAG の応用を検討し、セクション 8 では実装ツールとフレームワークについて議論します。セクション 9 ではベンチマークとデータセットに焦点を当て、セクション 10 では Agentic RAG システムの将来の方向性で結論付けます。
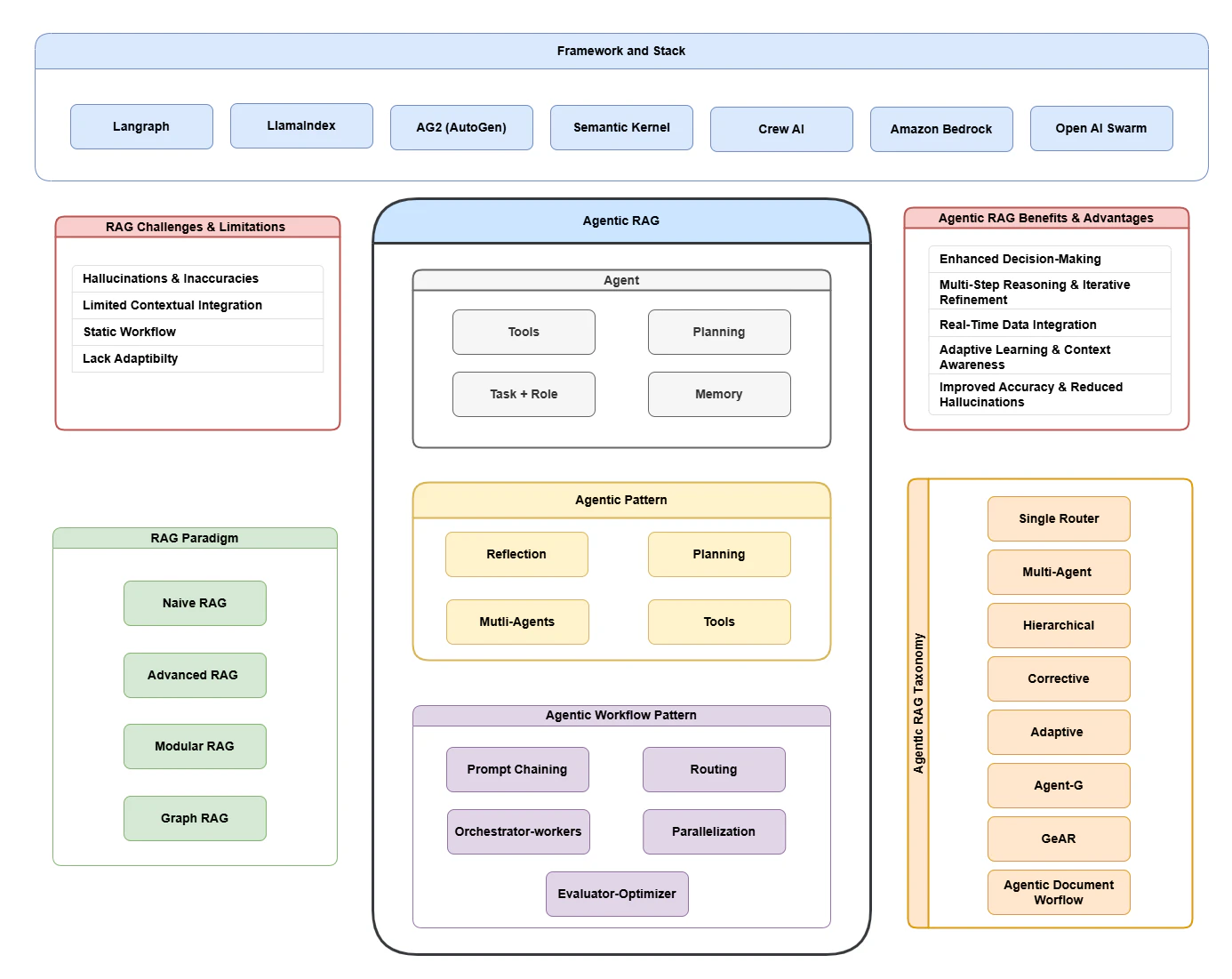
Figure 1: Agentic RAG 概要
2. RAG の基礎
2.1 RAG の概要
Retrieval-Augmented Generation (RAG) は、大規模言語モデル(LLM)の生成能力とリアルタイムのデータ検索を組み合わせた、人工知能分野における重要な進歩を表しています。LLM は自然言語処理において驚くべき能力を示してきましたが、静的な事前学習データに依存しているため、しばしば古い情報や不完全なレスポンスを生成してしまいます。RAG はこの制限に対処するため、外部ソースから関連情報を動的に検索し、それを生成プロセスに組み込むことで、文脈に即した最新の出力を可能にします。
2.2 RAG の主要コンポーネント
RAG システムのアーキテクチャは、3 つの主要コンポーネントを統合しています(Figure 2):
• Retrieval(検索):Knowledge Bases、API、ベクトル DB などの外部データソースへのクエリを担当します。高度な検索機能は、密ベクトル検索と transformer ベースのモデルを活用して、検索精度と意味的関連性を向上させます。
• Augmentation(拡張):検索されたデータを処理し、クエリのコンテキストに合わせて最も関連性の高い情報を抽出・要約します。
• Generation(生成):検索された情報と LLM の事前学習された知識を組み合わせて、一貫性があり文脈に適したレスポンスを生成します。
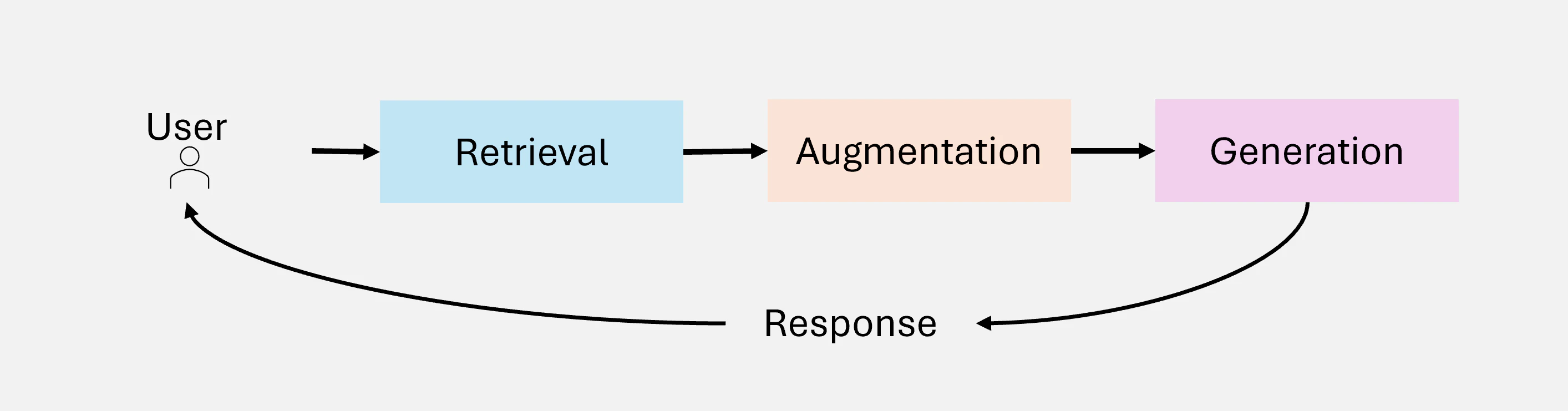
Figure 2:RAG の主要コンポーネント
2.3 RAG パラダイムの進化
Retrieval-Augmented Generation(RAG)の分野は、文脈的な正確性、スケーラビリティ、多段階推論が重要となる現実世界のアプリケーションの複雑性の増大に対応するため、大きく進化してきました。単純なキーワードベースの検索から始まったこの分野は、多様なデータソースと自律的な意思決定プロセスを統合できる洗練された、モジュール化された、適応性のあるシステムへと移行しました。この進化は、RAG システムが複雑なクエリを効率的かつ効果的に処理する必要性の高まりを強調しています。
このセクションでは、RAG パラダイムの進展を検討し、主要な発展段階 — Naive RAG、Advanced RAG、Modular RAG、Graph RAG、Agentic RAG — をそれぞれの特徴、強み、限界とともに紹介します。これらのパラダイムの進化を理解することで、読者は検索と生成能力の進歩とそれらの様々な分野での応用を理解することができます。
2.3.1 Naive RAG
Naive RAG は、RAG の基本的な実装を表しています。Figure 3 は、キーワードベースの検索と静的データセットに焦点を当てた、Naive RAG のシンプルな検索-読み取りワークフローを示しています。これらのシステムは、TF-IDF や BM25 などのシンプルなキーワードベースの検索技術を使用して、静的データセットからドキュメントを取得します。取得されたドキュメントは、言語モデルの生成能力を強化するために使用されます。
Figure 3: Naive RAG の概要
Naive RAG は、その単純さと実装の容易さが特徴で、コンテキストが単純な事実ベースのクエリを含むタスクに適しています。しかし、以下のようないくつかの制限があります:
-
コンテキスト認識の欠如:語彙的なマッチングに依存し、semantic な理解ではないため、取得されたドキュメントはクエリの semantic なニュアンスを捉えられないことがよくある
-
断片的な出力:高度な前処理やコンテキストの統合が欠如しているため、つながりがなく一般的なレスポンスを出す
-
スケーラビリティ:キーワードベースの検索技術は大規模なデータセットでは苦戦し、最も関連性の高い情報を特定できないことがある
これらの制限にもかかわらず、Naive RAG は検索と生成を統合するための重要な概念実証を提供し、より洗練されたパラダイムの基礎を築きました。
2.3.2 Advanced RAG
Advanced RAG は、意味的理解と強化された検索技術を組み込むことで、Naive RAG の制限を克服しています。Figure 4 は、Advanced RAG の検索における意味的な強化と、反復的で文脈を認識したパイプラインを示しています。これらのシステムは、Dense Passage Retrieval (DPR)などの密な検索モデルやニューラルランキングアルゴリズムを活用して、検索の精度を向上させています。
Figure 4 : Advanced RAG の概要
Advanced RAG の主な特徴は以下の通りです:
-
密ベクトル検索:クエリとドキュメントは高次元ベクトル空間で表現され、ユーザーのクエリと取得されたドキュメント間のより良い意味的な整合性を実現
-
コンテキストに基づくリランキング:ニューラルモデルが取得したドキュメントを再ランク付けし、文脈的に最も関連性の高い情報を優先
-
反復的な検索:Advanced RAG は複数ホップの検索メカニズムを導入し、複雑なクエリに対して複数のドキュメントにわたる推論を可能に
これらの進歩により、Advanced RAG は研究の統合やパーソナライズされた推奨など、高い精度と繊細な理解を必要とするアプリケーションに適しています。ただし、大規模なデータセットや多段階のクエリを扱う際には、計算オーバーヘッドや拡張性の制限といった課題が依然として存在します。
2.3.3 Modular RAG
Modular RAG は、RAG パラダイムの最新の進化形であり、柔軟性とカスタマイズ性を重視しています。これらのシステムは検索と生成のパイプラインを独立した再利用可能なコンポーネントに分解し、ドメイン固有の最適化とタスクへの適応性を可能にします。Figure 5 は、ハイブリッド検索戦略、構成可能なパイプライン、外部ツールの統合を示すモジュラーアーキテクチャを示しています。
Modular RAG の主な革新点は以下の通りです:
-
ハイブリッド検索戦略:スパース検索手法(スパースエンコーダー-BM25など)と密な検索技術(DPR - Dense Passage Retrievalなど)を組み合わせることで、多様なクエリタイプに対する精度を最大化
-
ツール統合:リアルタイムデータ分析やドメイン固有の計算など、特殊なタスクを処理するための外部 API、データベース、計算ツールを組み込む
-
構成可能なパイプライン:検索器、生成器、その他のコンポーネントを独立して置き換え、強化、または再構成できるようにし、特定のユースケースへの高い適応性を可能に
例えば、金融分析用に設計された Modular RAG システムは、API を通じてリアルタイムの株価を取得し、密な検索を使用して過去のトレンドを分析し、カスタマイズされた言語モデルを通じて実用的な投資洞察を生成することができます。このモジュール性とカスタマイズ性により、Modular RAG は複雑のマルチドメインタスクに理想的であり、スケーラビリティと精度の両方を提供します。
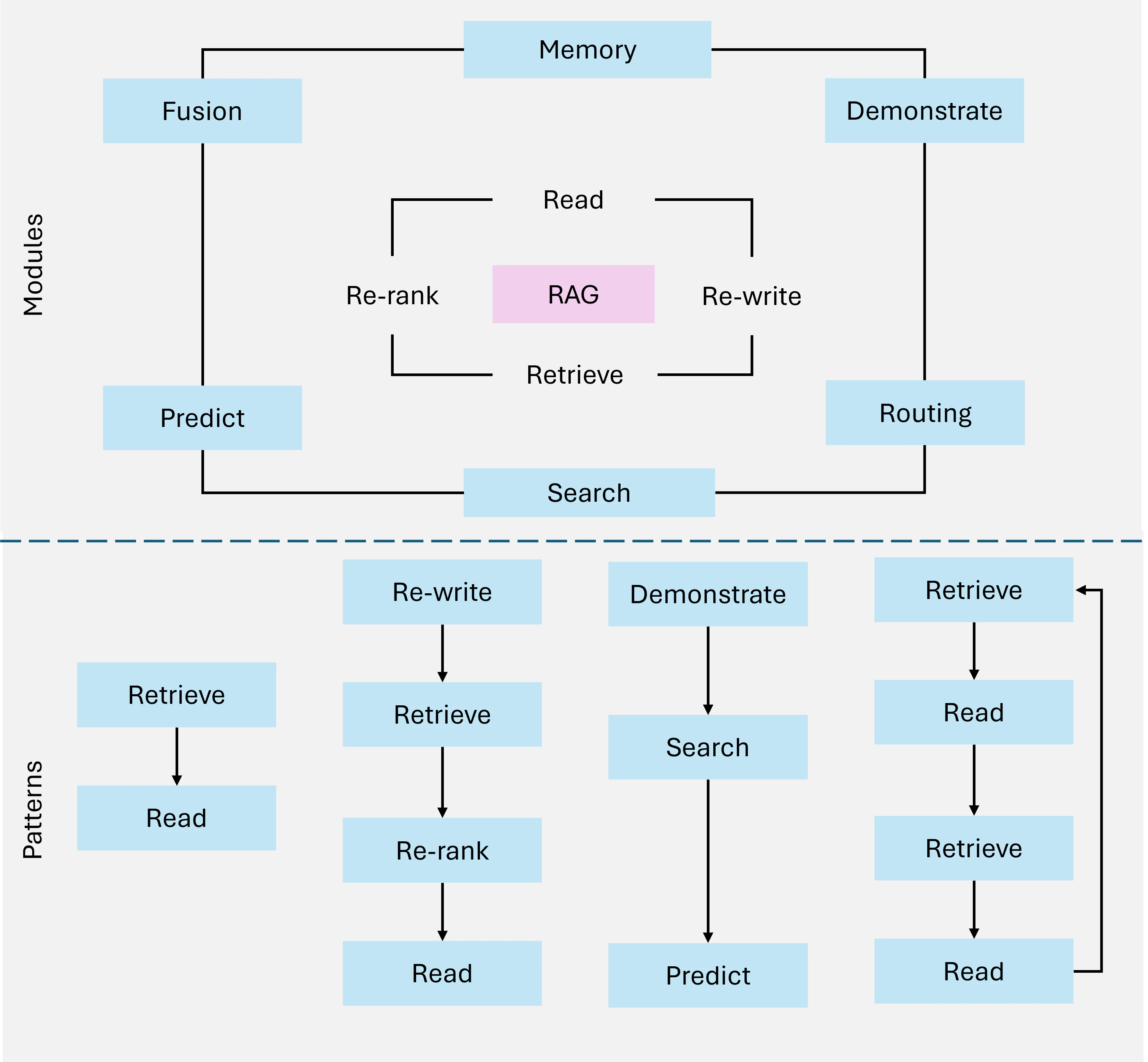
Figure 5: Modular RAG の概要
2.3.4 Graph RAG
Graph RAG は、Figure 6 に示されているように、グラフベースのデータ構造を統合することで従来の RAG を拡張したものです。これらのシステムは、グラフデータ内の関係性と階層構造を活用して、マルチホップ推論とコンテキストの強化を実現します。グラフベースの検索を組み込むことで、Graph RAG は特に関係性の理解を必要とするタスクにおいて、より豊かで正確な生成出力を可能にします。
Graph RAG の特徴は以下の通りです:
- ノード接続性:エンティティ間の関係性を捉え、それに基づいて推論
- 階層的知識管理:グラフベースの階層構造を通じて、構造化データと非構造化データを扱う
- コンテキスト強化:グラフベースのパスを活用して関係性の理解を深化
一方、Graph RAG には以下のような制限があります:
- 限定的なスケーラビリティ:グラフ構造への依存により、特に大規模なデータソースを扱う場合にスケーラビリティが制限される可能性
- データ依存性:意味のある出力を得るには高品質なグラフデータが不可欠であり、非構造化データや適切にアノテーションされていないデータセットでの適用が制限
- 統合の複雑さ:グラフデータと非構造化検索システムの統合により、設計と実装の複雑さが増加
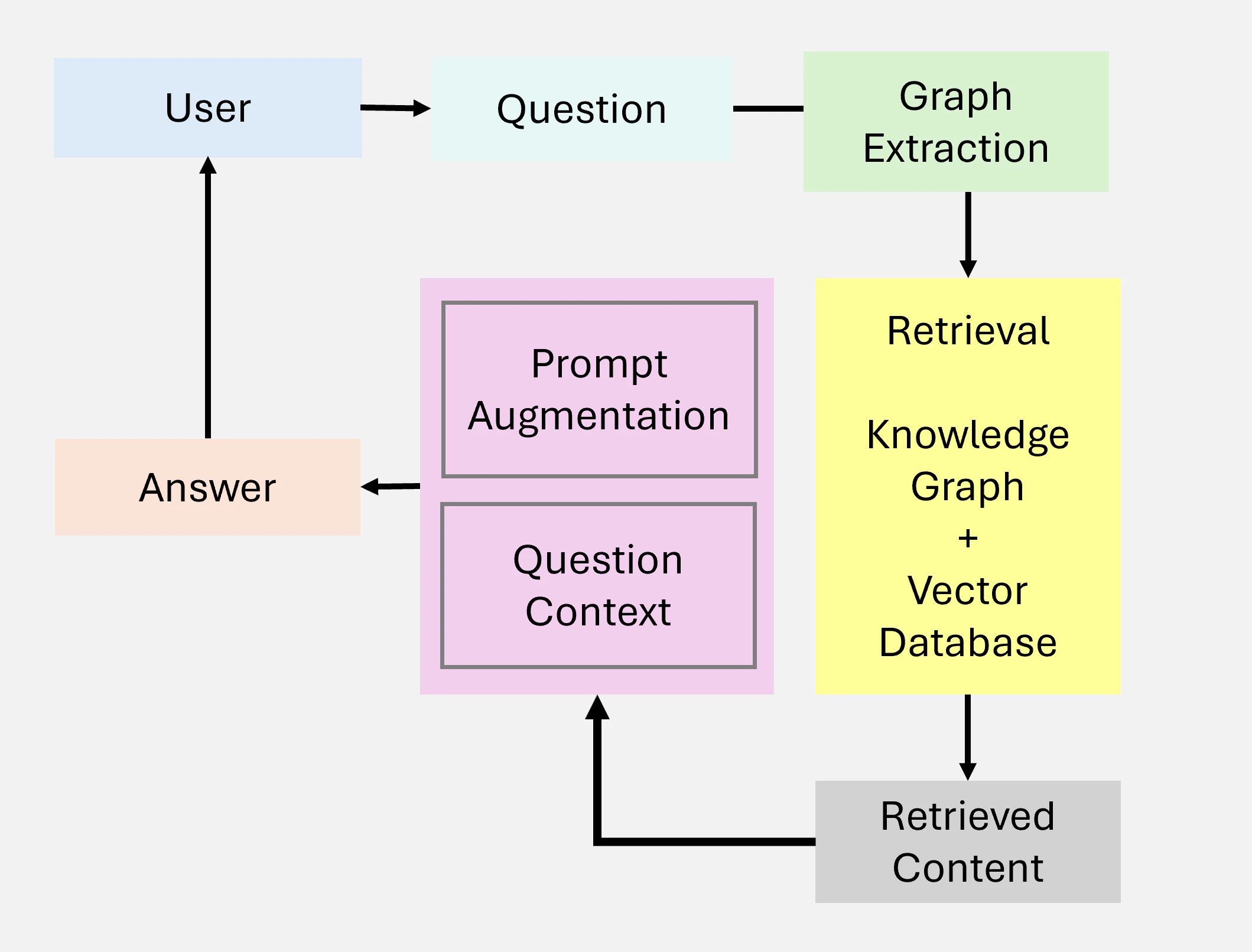
Figure 6 : Graph RAG 概要
Graph RAGは、医療診断、法的調査、そして構造化された関係性に基づく推論が重要な他の分野のアプリケーションに適しています。
2.3.5 Agentic RAG
Agentic RAG は、動的な意思決定とワークフロー最適化が可能な自律型 Agent を導入することによって、パラダイムシフトを表しています。静的なシステムとは異なり、Agentic RAG は複雑でリアルタイムなマルチドメインのクエリに対応するため、反復的な改善と適応的な検索戦略を採用しています。このパラダイムは、検索と生成プロセスのモジュール性を活用しながら、Agent ベースの自律性を導入しています。
Agentic RAGの主な特徴は以下の通りです:
- 自律的な意思決定:Agent はクエリの複雑さに基づいて、検索戦略を独自に評価・管理
- 反復的な改善:検索の精度とレスポンスの関連性を向上させるためのフィードバックループを組み込む
- ワークフロー最適化:リアルタイムアプリケーションでの効率性を実現するために、タスクを動的に編成
その進歩にもかかわらず、Agentic RAGには以下のような課題があります:
- 連携の複雑さ:Agent 間の相互作用の管理には高度な調整メカニズムが必要
- 計算オーバーヘッド:複数のAgent を使用することで、複雑なワークフローにおけるリソース要件が増加
- スケーラビリティの制限:スケーラブルではありますが、システムの動的な性質により、大量のクエリ処理時に計算リソースの負荷がかかる可能性
Agentic RAGは、動的な適応性とコンテキストの精度が最も重要となるカスタマーサポート、金融分析、適応型学習プラットフォームなどの領域で特に優れた性能を発揮します。
Table 1: RAG パラダイムの比較分析
| パラダイム | 主な特徴 | 長所 |
|---|---|---|
| Naive RAG | • キーワードベースの検索(TF-IDF、BM25など) | • シンプルで実装が容易 • 事実ベースのクエリに適している |
| Advanced RAG | • 密な検索モデル(DPRなど) • ニューラルランキングと再ランキング • マルチホップ検索 |
• 高精度な検索 • 文脈的な関連性の向上 |
| Modular RAG | • ハイブリッド検索(疎と密) • ツールとAPIの統合 • 組み立て可能なドメイン特化パイプライン |
• 高い柔軟性とカスタマイズ性 • 多様なアプリケーションに適している • スケーラブル |
| Graph RAG | • グラフベースの構造の統合 • マルチホップ推論 • ノードを介した文脈の強化 |
• 関係性推論能力 • 幻覚を軽減 • 構造化データタスクに最適 |
| Agentic RAG | • 自律型 Agent • 動的な意思決定 • 反復的な改善とワークフロー最適化 |
• リアルタイムの変更に適応可能 • マルチドメインタスクに対してスケーラブル • 高精度 |
2.4 従来の RAG の課題と制限
従来の RAG は、リアルタイムのデータ検索を統合することで大規模言語モデル(LLM)の能力を大幅に拡張してきました。しかし、これらのシステムは依然として、複雑な実世界のアプリケーションにおける有効性を妨げる重要な課題に直面しています。最も顕著な制限は、コンテキストの統合、多段階推論、スケーラビリティとレイテンシーの問題に関するものです。
2.4.1 コンテキストの統合
RAGシステムが関連情報の検索に成功した場合でも、検索結果と生成結果間でチグハグなことがあります。検索パイプラインの静的な性質と限定的な文脈認識により、断片的、一貫性のない、または過度に一般的な出力を引き起こします。
例: 「アルツハイマーに関する研究の最新の進歩と早期治療への影響は何か?」といったクエリに対して、関連する研究論文や医療ガイドラインを取得できるかもしれません。しかし、従来の RAG は、これらの知見を新しい治療法と特定の患者シナリオを結びつける一貫した説明に統合できないことがよくあります。同様に、「乾燥地域における小規模農業に最適な持続可能な実践とは?」というクエリに対して、従来の RAG は一般的な農業方法に関する文書を検索するかもしれませんが、乾燥環境に特化した重要な持続可能性の実践を見落としがちです。
2.4.2 多段階推論
実世界のクエリの多くは、複数のステップにわたる情報の検索と統合を必要とする反復的または多段階の推論を必要とします。従来の RAG は、中間的な洞察やユーザーフィードバックに基づいて検索を改善する能力が不十分で、不完全または断片的なレスポンスとなってしまいます。
例: 「ヨーロッパの再生可能エネルギー政策から得られる教訓を発展途上国にどのように適用でき、その潜在的な経済的影響は何か?」といった複雑なクエリには、政策データ、発展途上地域の文脈化、経済分析など、複数種類の情報の調整が必要です。従来のRAGシステムは、通常、これらの異なる要素を一貫したレスポンスに結びつけることができません。
2.5 Agentic RAG: パラダイムシフト
従来の RAG は、静的なワークフローと限定的な適応性により、動的な多段階推論や複雑な実世界のタスクの処理に苦心することが多くあります。これらの制限により、Agentic Intelligence の統合が促進され、Agentic RAG が生まれました。動的な意思決定、反復的推論、適応的な検索戦略が可能な自律Agentを組み込むことで、Agentic RAG は初期のパラダイムのモジュール性を基盤としながら、その本質的な制約を克服しています。この進化により、より複雑なマルチドメインタスクを、向上した精度と文脈理解で処理することが可能になり、Agentic RAG は次世代 AI アプリケーションの要となっています。特に、Agentic RAG は最適化されたワークフローによってレイテンシーを削減し、出力を反復的に改善することで、従来の RAG のスケーラビリティと有効性を歴史的に妨げてきた課題に取り組んでいます。
3 Agentic Intelligence の核となる原則と背景
Agentic Intelligence は、Agentic RAG の基盤を形成し、従来の RAG の静的で受動的な性質を超越することを可能にします。動的な意思決定、反復的推論、協調的ワークフローが可能な自律 Agent を統合することで、Agentic RAG は向上した適応性と精度を示します。このセクションでは、Agentic Intelligence を支える核となる原則を探ります。
AI Agent のコンポーネント
本質的に、AI Agent は以下のコンポーネントで構成されます (Figure 7: AI Agents の概要)
-
LLM(定義された役割とタスク):Agent の主要な推論エンジンおよび対話インターフェースとして機能。ユーザーのクエリを解釈し、レスポンスを生成し、一貫性を維持
-
Memory(Short-Term and Long-Term):対話全体にわたるコンテキストと関連データを捕捉します。Short-Term Memory は直接の会話状態を追跡し、Long-Term Memory は蓄積された知識と Agent の経験を保存
-
Planning(振り返りと自己批評):Reflection(振り返り、反省)、クエリのルーティング、または自己批評を通じて Agent の反復的推論プロセスを導き、複雑なタスクを効果的に分解
-
Tools(ベクトル検索、ウェブ検索、APIなど):テキスト生成を超えて Agent の能力を拡張し、外部リソース、リアルタイムデータ、または特殊な計算へのアクセスを可能に
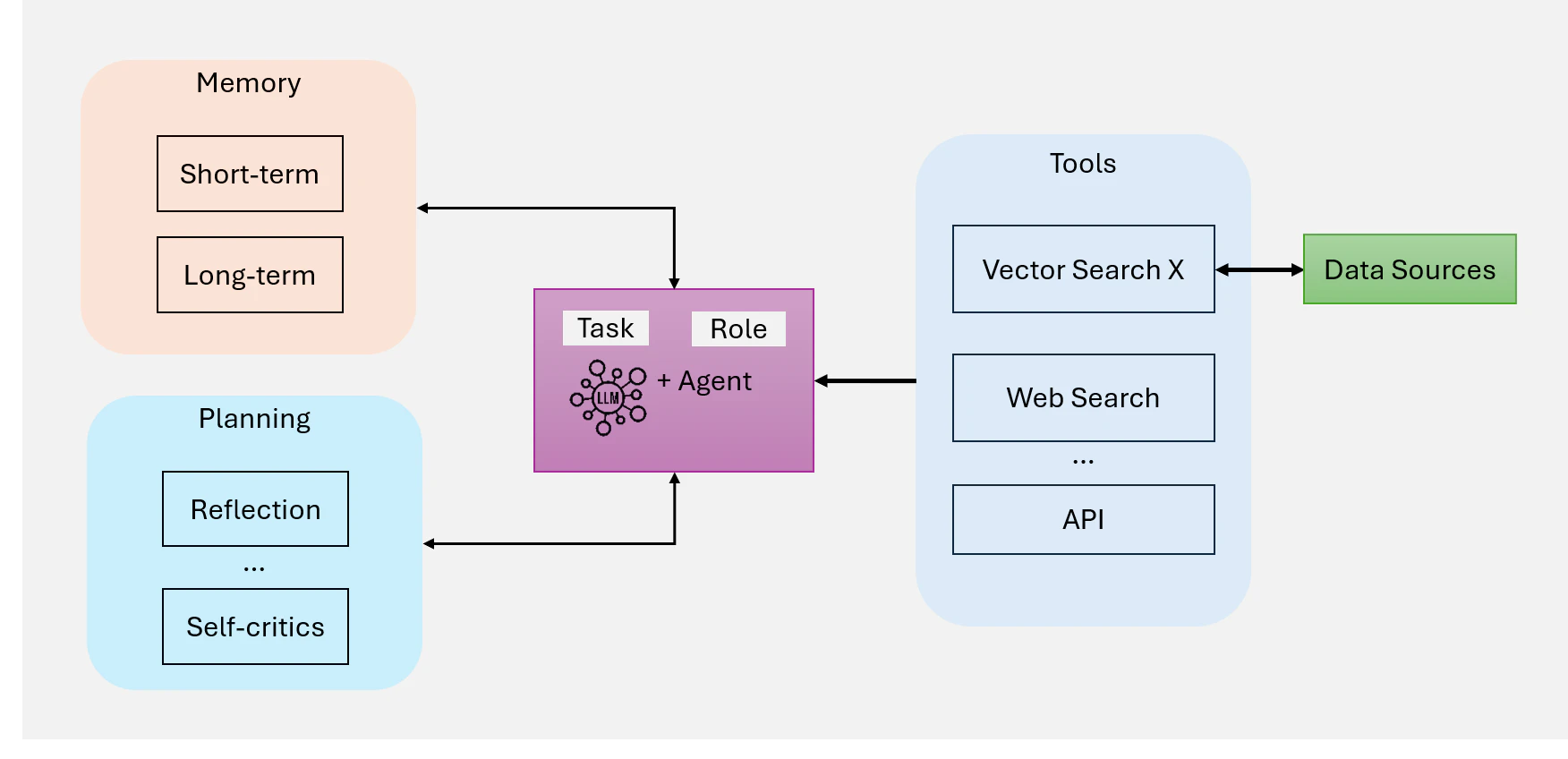
Figure 7: Agents の概要
Agentic パターンは、Agentic RAG における Agent の行動を導く構造化された方法論を提供します。これらのパターンにより、Agent は動的に適応し、計画を立て、協力することができ、システムが複雑な実世界のタスクを精度とスケーラビリティを持って処理できることを保証します。4 つの重要なパターンが Agentic ワークフローを支えています:
3.1 Reflection
Reflection は、Agentic ワークフローにおける基礎的な設計パターンであり、Agent が出力を反復的に評価し改善することを可能にします。自己フィードバックメカニズムを組み込むことで、Agent はコード生成、テキスト作成、質問レスポンスなどのタスクにおいて、エラー、不整合、改善が必要な領域を特定し対処することができ、パフォーマンスを向上させます(Figure 8 に示す通り)。実践的な使用では、Reflection は、Agent に対して正確性、スタイル、効率性について出力を批評するよう促し、そのフィードバックを後続の反復に組み込むことを含みます。ユニットテストやウェブ検索などの外部ツールは、結果を検証し、ギャップを浮き彫りにすることで、このプロセスをさらに強化することができます。
Multi Agents において Reflection は、ある Agent が出力を生成し、別の Agent がそれを批評するなど、異なる役割を含むことができ、協調的な改善を促進します。例えば、法的調査において、Agent は検索された判例法を再評価することでレスポンスを反復的に改善し、正確性と包括性を確保することができます。Reflection は、Self-Refine 、Reflexion、CRITIC などの研究において、顕著なパフォーマンスの改善を実証しています。
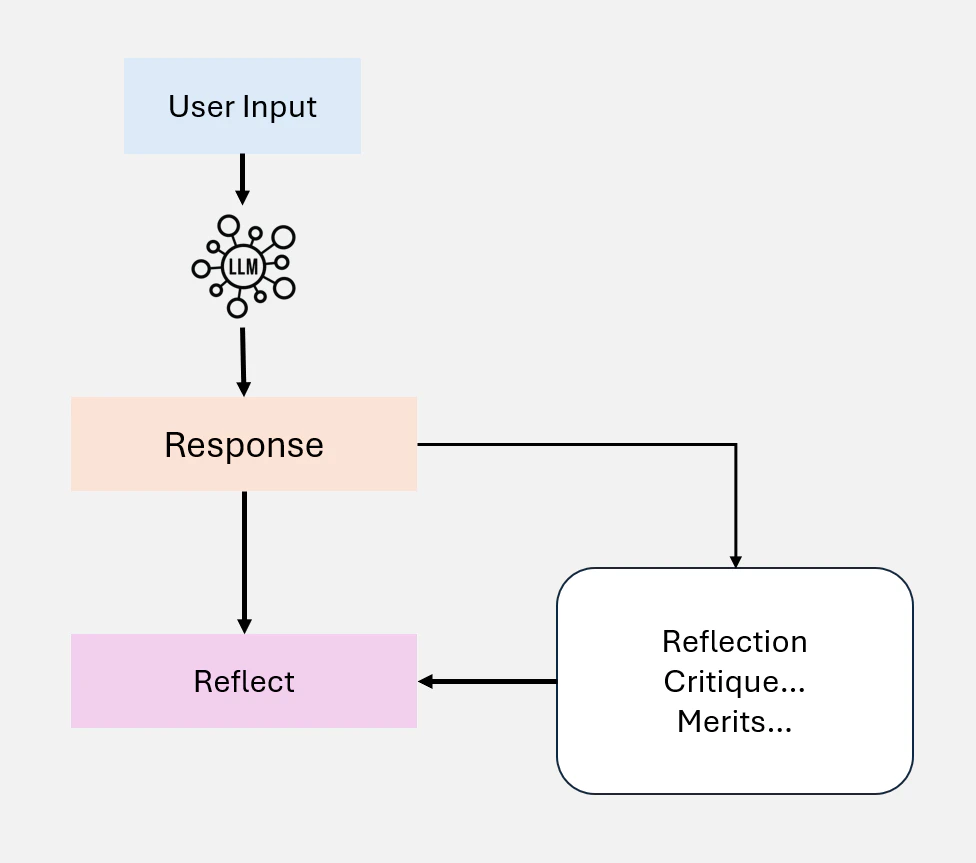
Figure 8: Self-Reflection の概要
3.2 Planning
Planning は Agentic ワークフローにおける重要な設計パターンであり、Agent が複雑なタスクを小さな管理可能なサブタスクに自律的に分解することを可能にします。この能力は、Figure 9(a) に示すように、動的で不確実なシナリオにおけるマルチホップ推論と反復的な問題解決に不可欠です。
Planning を活用することで、Agent は大きな目標を達成するために必要なステップの順序を動的に決定することができます。この適応性により、Agent は事前に定義できないタスクを処理することができ、意思決定における柔軟性を確保します。Planning は強力ですが、Reflection のような決定論的なワークフローと比較して、より予測が難しい結果を生み出す可能性があります。Planning は特に、事前に定義されたワークフローでは不十分な、動的な適応を必要とするタスクに適しています。技術が成熟するにつれて、様々な分野での革新的なアプリケーションを推進する可能性は今後も成長し続けるでしょう。
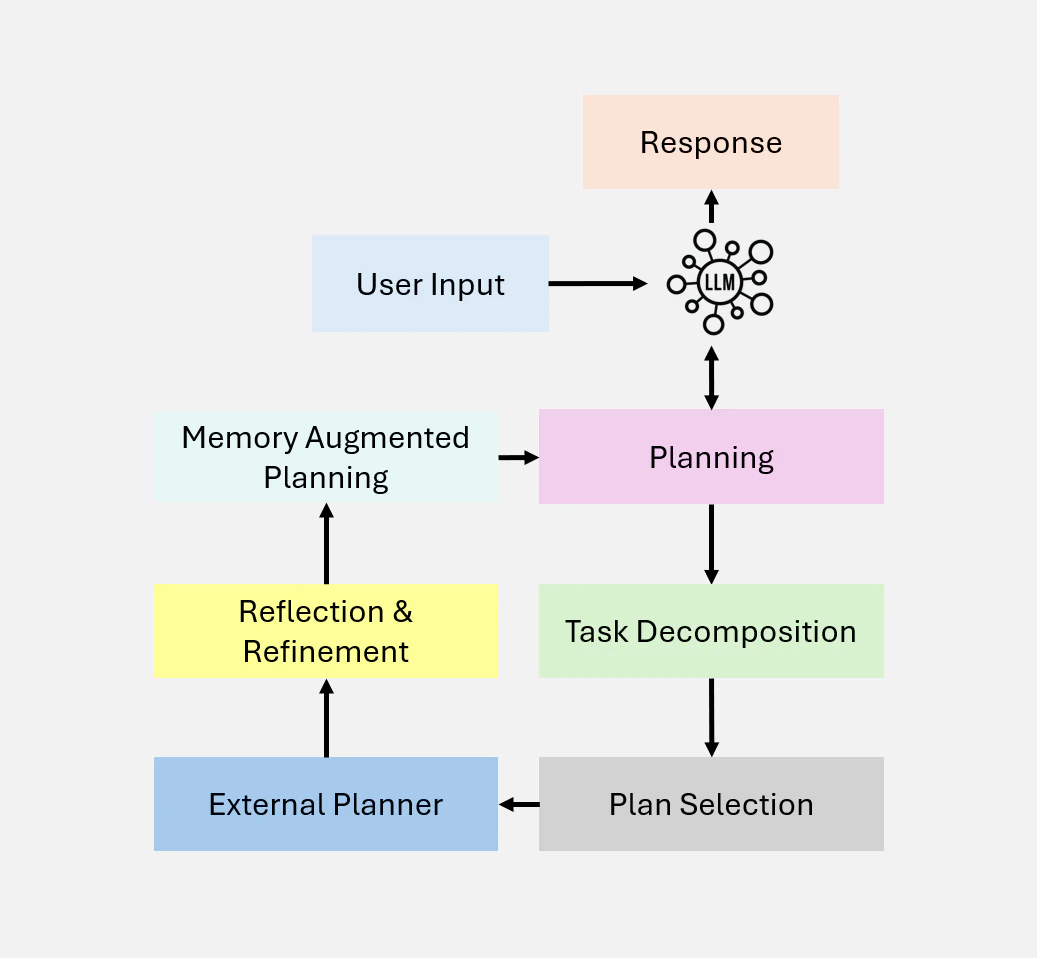
Figure 9-(a): Agentic Planning の概要
3.3 Tool Use
Tool Use は、Figure 9-(b) に示すように、Agent が外部ツール、API、計算リソースと対話することで、その能力を拡張することを可能にします。このパターンにより、Agent は事前学習された知識を超えて、情報収集、計算の実行、データの操作を行うことができます。ワークフローにツールを動的に統合することで、Agent は複雑なタスクに適応し、より正確で文脈に即した出力を提供することができます。
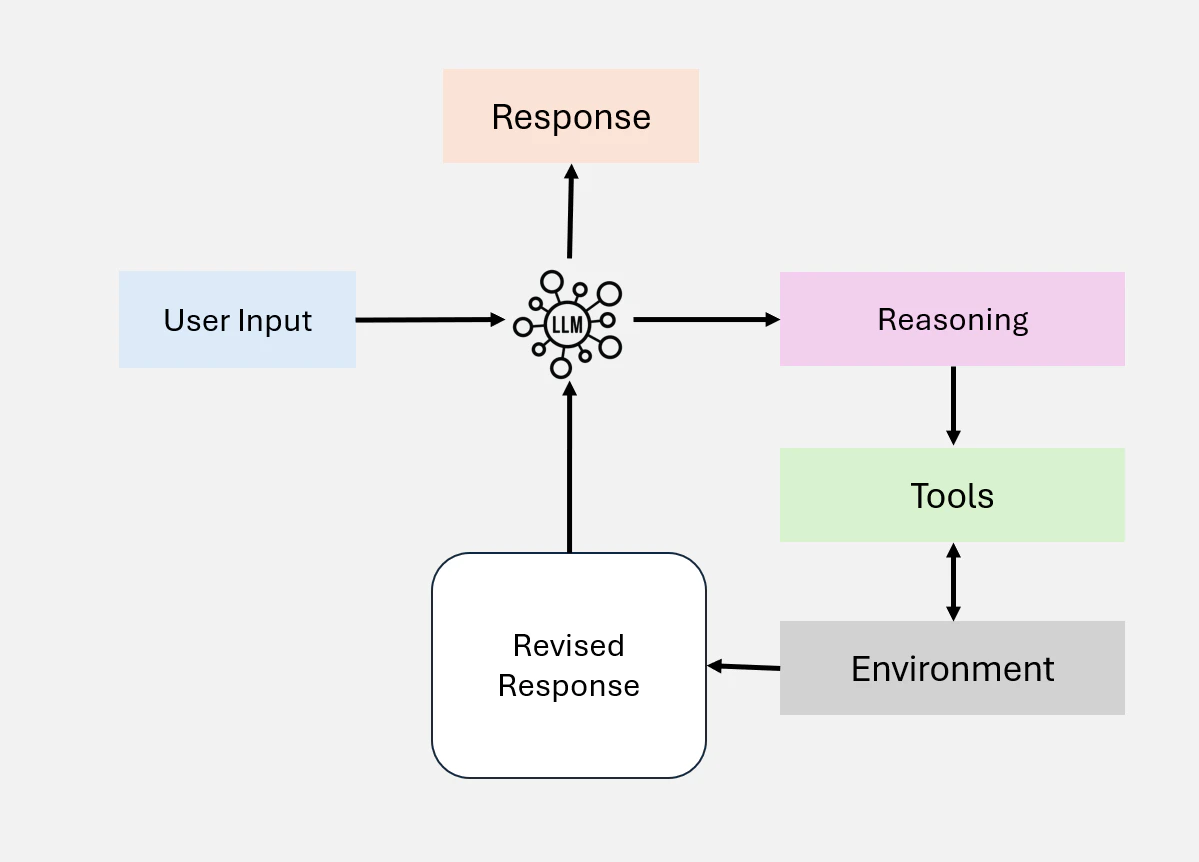
現代の Agentic ワークフローは、情報検索、計算推論、外部システムとのインターフェースなど、様々なアプリケーションにツール使用を組み込んでいます。このパターンの実装は、GPT-4 の関数呼び出し機能や、多数の tool へのアクセスを管理できるシステムなどの進歩により、大きく進化しています。これらの発展により、Agent が与えられたタスクに最も適切なツールを自律的に選択し実行する高度なワークフローが可能になっています。
Tool Use は Agentic Workflow を大幅に強化しますが、特に利用可能なオプションが多数ある場合のツール選択の最適化には依然として課題が残っています。RAG からインスピレーションを得た、ヒューリスティックベースの選択などの技術が、この問題の対処に提案されています。
Figure 9-(b): Tool Use の概要
3.4 Multi-Agent
Multi-Agent Collaboration は、タスクの専門化と並列処理を可能にする Agentic ワークフローの重要な設計パターンです。Agent 同士が通信し中間結果を共有することで、全体のワークフローの効率性と一貫性を確保します。専門化されたエージェント間でサブタスクを分散させることで、このパターンは複雑なワークフローのスケーラビリティと適応性を向上させます。Multi-Agents により、開発者は複雑なタスクを、異なる Agent に割り当てられる小さな管理可能なサブタスクへ分解できます。このアプローチは、タスクのパフォーマンスを向上させるだけでなく、複雑な相互作用を管理するための堅牢なフレームワークも提供します。各 agent は独自の memory とワークフローで動作し、Tool Use、Reflection、Planning を含むことができ、動的で協調的な問題解決を可能にします(Figure 10)。
Multi-Agent Collaboration は大きな可能性を秘めていますが、Reflection や Tool Use のようなより成熟したワークフローと比較すると、予測が難しい設計パターンです。しかし、AutoGen、Crew AI、LangGraph などの新興フレームワークが、効果的な multi-agent ソリューションを実装するための新しい道を開いています。
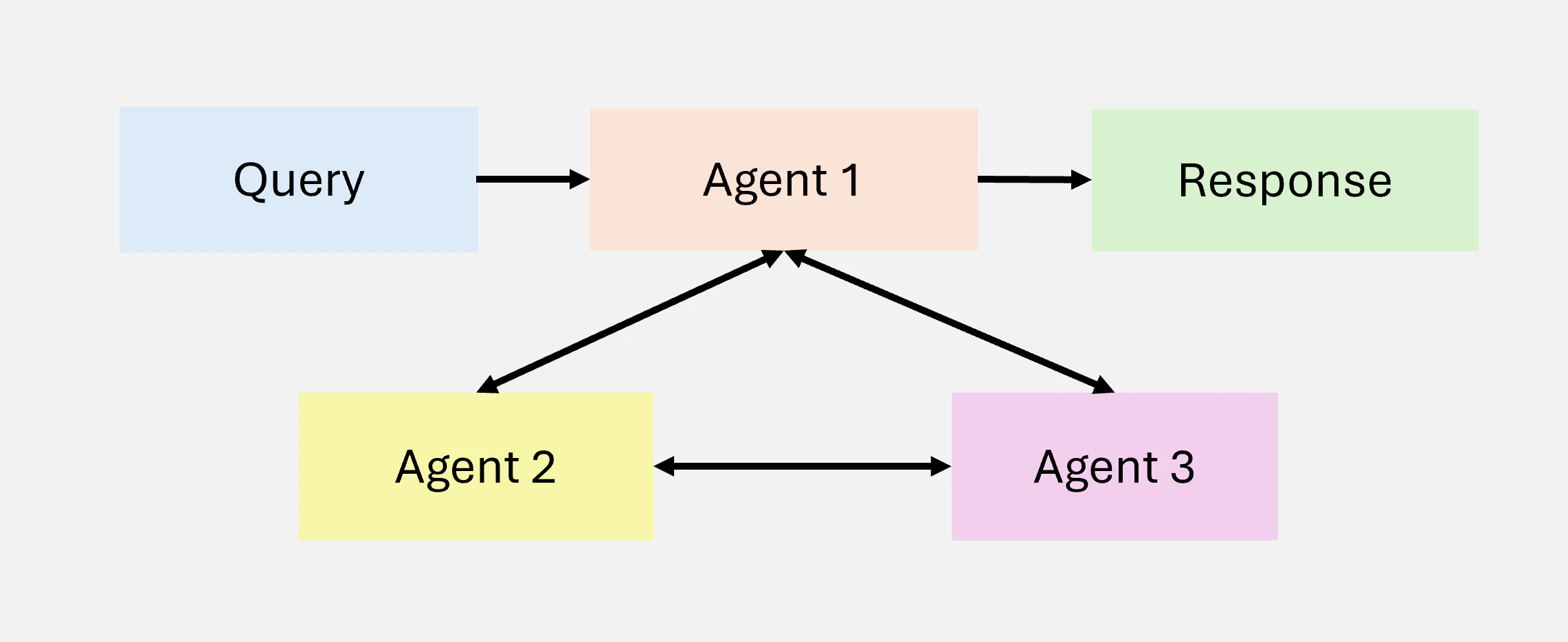
Figure 10: MultiAgent の概要
これらの設計パターンは、Agentic RAG の成功の基盤を形成しています。単純な順次的ステップから、より適応的で協調的なプロセスまで、これらのパターンによってワークフローを構造化することで、システムは実世界環境の多様で絶えず変化する要求に対して、検索と生成の戦略を動的に適応させることが可能になります。これらのパターンを活用することで、Agent は従来の RAG の能力を大きく超える、反復的でコンテキストを意識したタスクを処理することができます。
4 Agentic ワークフローパターン: 動的協調に向けた適応戦略
Agentic ワークフローパターンは、LM ベースのアプリケーションにおいて、性能、精度、効率性を最適化するための構造を提供します。タスクの複雑さと処理要件に応じて、異なるアプローチが適切です。
4.1 Prompt Chaining: 逐次処理による精度の向上
Prompt Chaining は、複雑なタスクを複数のステップに分解し、各ステップが前のステップの結果に基づいて構築される手法です。この構造化されたアプローチは、次のステップへ進む前に各サブタスクを単純化することで精度を向上させます。ただし、逐次処理による待ち時間の増加が生じます。
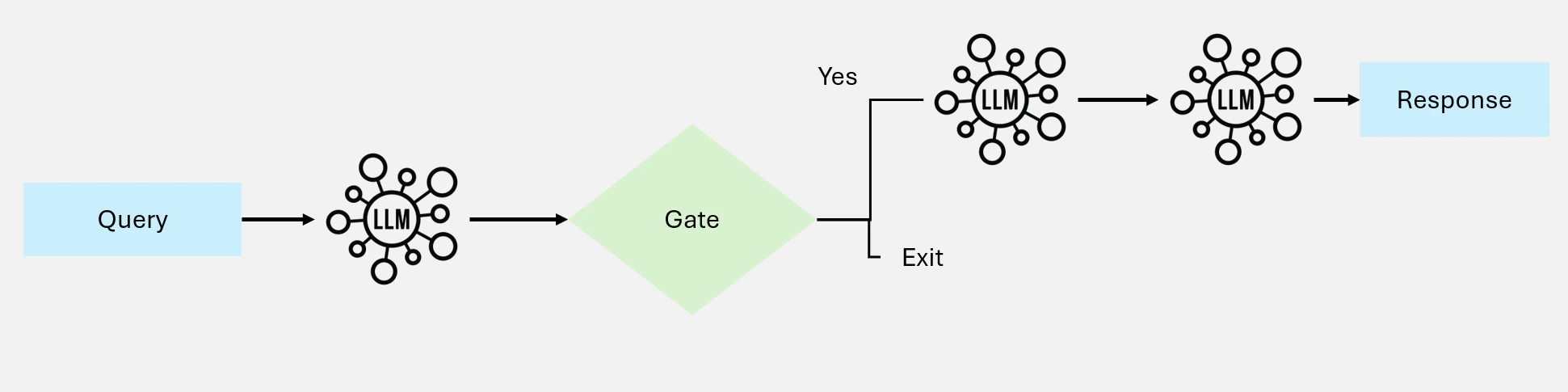
Figure 11: Prompt Chaining ワークフローの図解
使いどころ: このワークフローは、タスクが最終的な出力に寄与する固定的なサブタスクへ分解できる場合に最も効果的です。特に、段階的な推論が精度を向上させるシナリオで有用です。
適用例:
- ある言語でマーケティングコンテンツを作成し、ニュアンスを保ちながら別の言語に翻訳
- 文書作成において、最初に概要を生成し、その完全性を確認した後、本文全体を展開
4.2 ルーティング: 専門化されたプロセスへの入力の振り分け
ルーティングは入力を分類し、適切な専門プロンプトやプロセスに振り分けることを含みます。この方法により、異なるクエリやタスクを個別に処理することができ、効率性とレスポンスの質を向上させることができます。
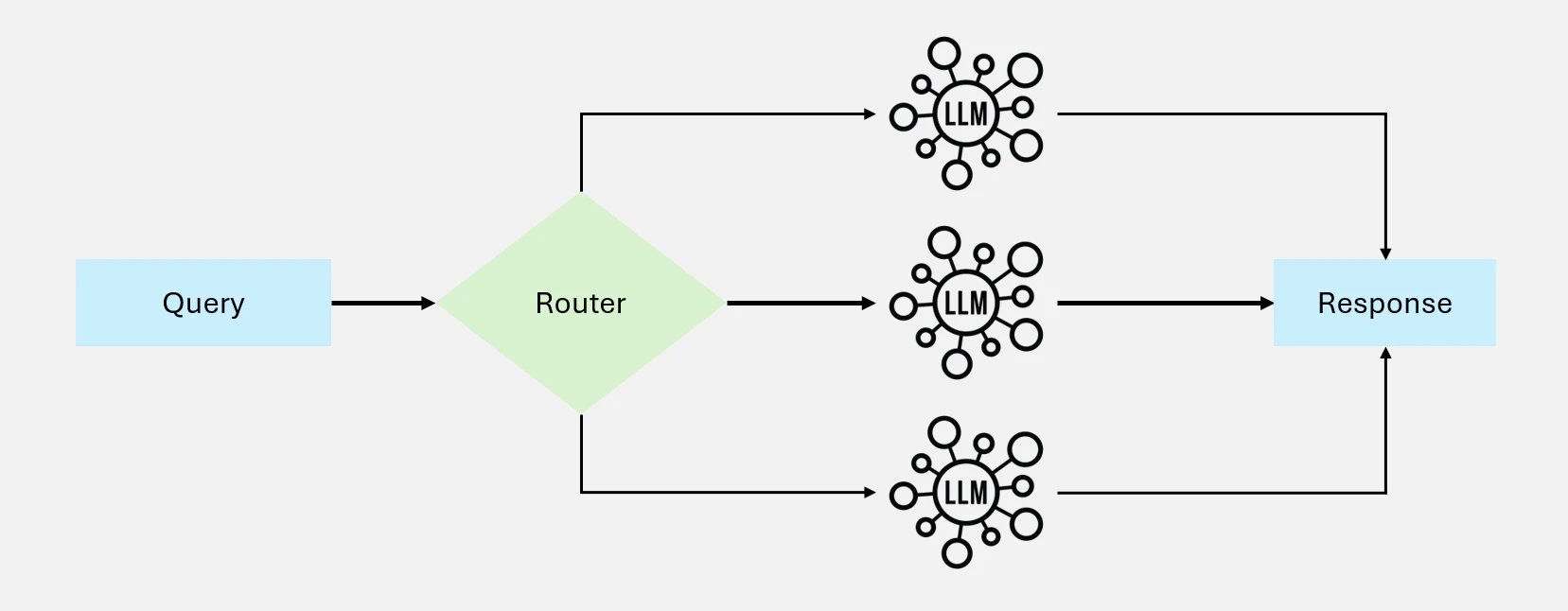
Figure12: ルーティングワークフロー図解
使いどころ:
異なる種類の入力に対して個別の処理戦略が必要なシナリオに最適で、各カテゴリーのパフォーマンスを最適化することができます。
適用例:
- カスタマーサービスの問い合わせを、技術サポート、返金要求、一般的な問い合わせなどのカテゴリーに振り分け
- コスト効率を考慮して、単純な問い合わせは小規模なモデルに割り当て、複雑な要求は高度なモデルに振り分け
4.3 並列化: 並列実行による処理の高速化
並列化とは、タスクを同時に実行される独立したプロセスに分割することで、待ち時間を削減し、処理能力を向上させる手法です。
並列化は以下の2つに分類できます:
- セクショニング方式:タスクを独立した小タスクに分割して処理
- 投票方式:精度向上のため、同じ処理を複数回実行して結果を照合
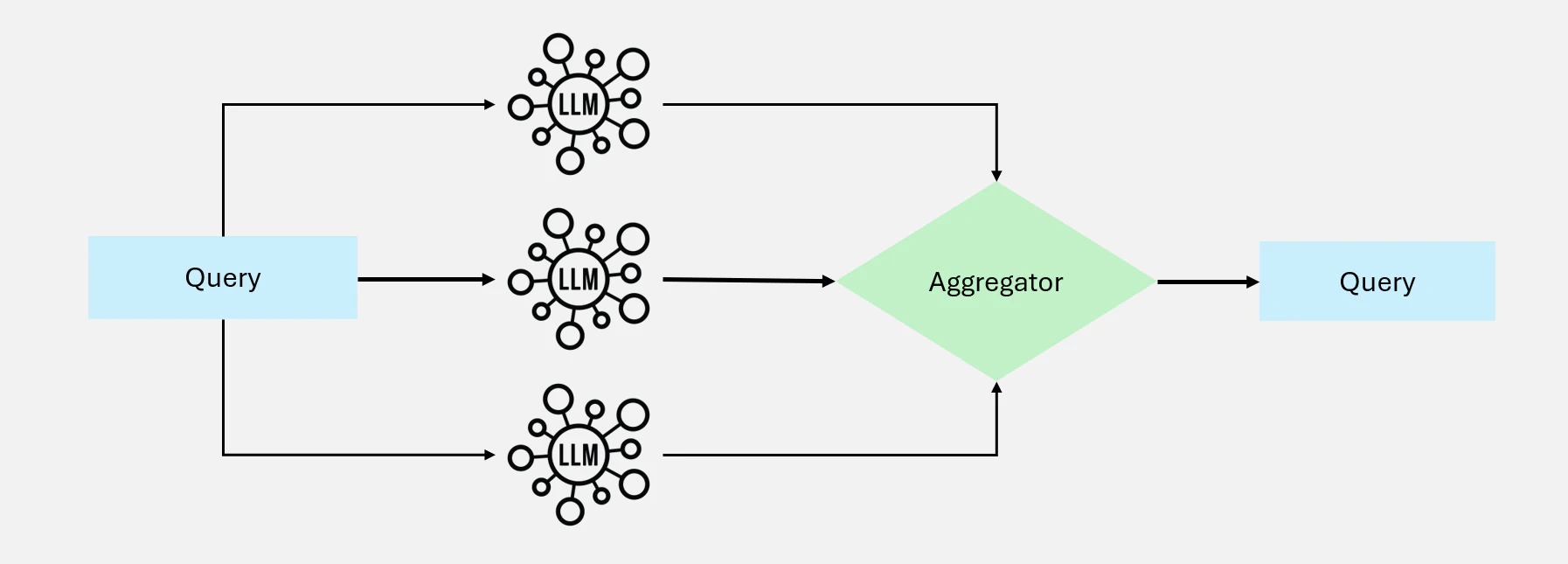
Figure 13: 並列化ワークフロー図解
使いどころ:
タスクを独立して実行できる場合の処理速度向上や、複数の出力結果を用いて信頼性を高めたい場合に有効な手法です。
適用例:
- セクショニング: コンテンツモデレーションのようなタスクを分割し、1 つのモデルがインプットをスクリーニングし、別のモデルがレスポンスを生成
- 投票: 複数のモデルを使用して、脆弱性のチェックやコンテンツモデレーションの決定を相互に確認
4.4 Orchestrator-Workers: 動的タスク移譲
このワークフローは、タスクを動的にサブタスクに分割し、専門のワーカーモデルに割り当て、結果をコンパイルする中央オーケストレーターモデルを特徴としています。並列化とは異なり、入力の複雑さに応じて適応します。
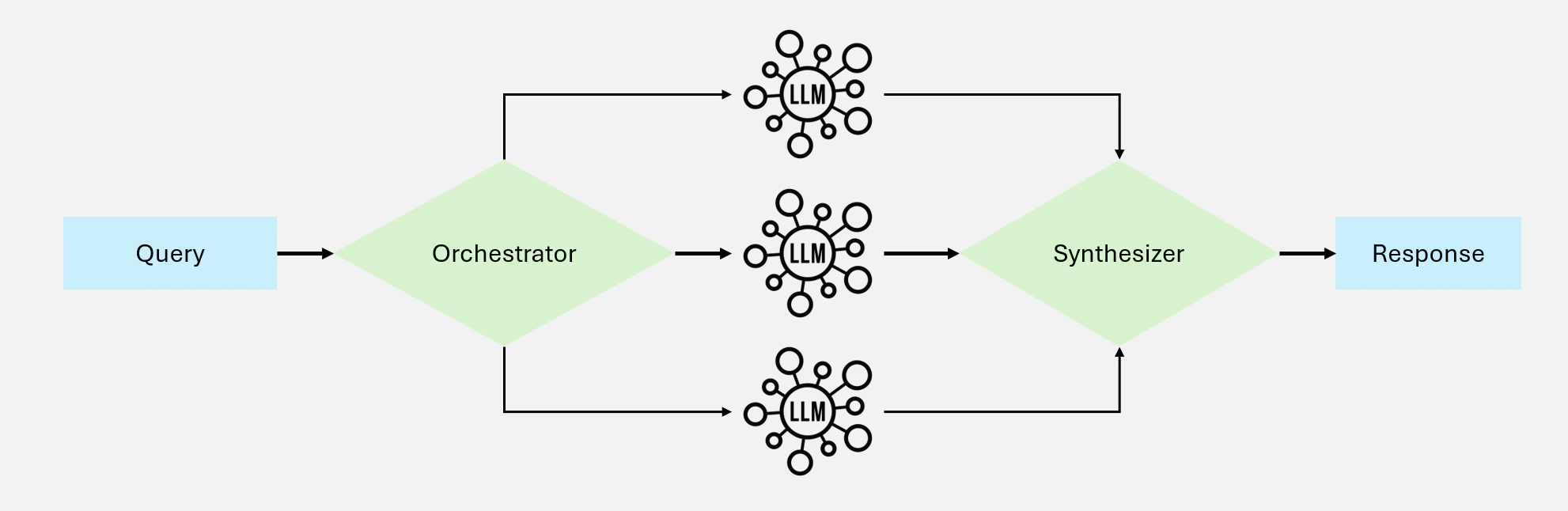
Figure 14: Orchestrator-Workers ワークフロー図解
使いどころ:
動的な分解と即時の適応が必要で、サブタスクが事前に定義されていないタスクに最適です。
適用例:
- コードベースの中の複数のファイルを、要求された変更の性質に基づいて自動的に修正
- 複数のソースから関連情報を収集・統合し、リアルタイムで調査
4.5 Evaluator-Optimizer: 反復を通じた出力の洗練
Evaluator-Optimizer のワークフローは初期出力を生成し、評価モデルからのフィードバックに基づいて洗練することで、コンテンツを段階的に改善します。
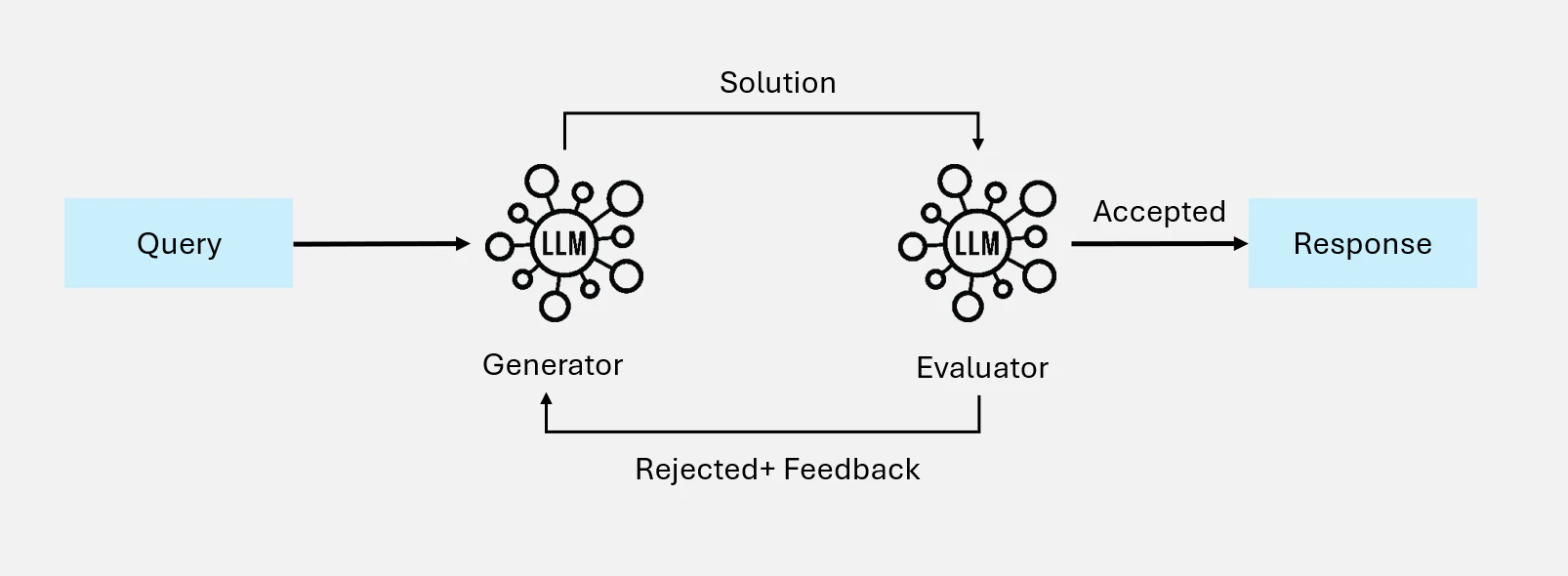
Figure 15: Evaluator-Optimizer ワークフロー図解
使いどころ:
反復的な洗練がレスポンスの質を大幅に向上させる場合、特に明確な評価基準が存在する場合に効果的です。
適用例:
- 複数の評価と洗練サイクルを通じて文学翻訳を改善
- 追加の反復でサーチ結果を洗練させる複数ラウンドの研究クエリを実施
5 Agentic RAG の分類学
Agentic RAG は、その複雑さと設計原則に基づいて、異なるアーキテクチャフレームワークに分類することができます。これには、Single-Agent, Multi-Agent, Hierarchical Agentic アーキテクチャが含まれます。各フレームワークは、特定の課題に対処し、多様なアプリケーションのパフォーマンスを最適化するように設計されています。このセクションでは、これらのアーキテクチャの詳細な分類を提供し、その特徴、長所、制限について説明します。
5.1 Single_agent Agentic RAG: ルーター
Single Agentic RAG: Single Agent が情報の検索、ルーティング、統合を管理する中央集権的な意思決定システムとして機能します(Figure 16に示すとおり)。このアーキテクチャは、これらのタスクを1つの統合されたエージェントに集約することでシステムを簡素化し、ツールやデータソースが限られたセットアップに特に効果的です。
ワークフロー
- クエリの送信と評価:
プロセスはユーザーがクエリを送信することから始まります。Coordinating Agent (またはmaster retrieval agent)がクエリを受け取り、最適な情報源を判断するために分析を行います。 - Knowledge Source の選択:
クエリのタイプに基づいて、調整エージェントは以下のような様々な検索オプションから選択します:- RDB: テーブルデータのアクセスが必要なクエリに対して、PostgreSQL や MySQL などのデータベースと連携する Text-to-SQL エンジンを使用
- Semantic Search:非構造化情報を扱う場合、ベクトル検索を使用して関連文書(PDF、書籍、組織の記録など)を取得
- Web 検索:リアルタイムまたは広範な文脈情報のために、システムはウェブ検索ツールを活用して最新のオンラインデータにアクセスします。
- Recommendation システム: パーソナライズされたまたは文脈に応じたクエリに対して、システムはカスタマイズされた提案を提供するレコメンデーションエンジンを活用します。
- データ統合とLLM 合成:選択されたソースから関連データが取得されると、それは大規模言語モデル(LLM)に渡されます。LLM は収集された情報を統合し、複数のソースからの洞察を一貫性のある文脈に即したレスポンスへまとめます。
- 出力生成:最後に、システムは元のクエリに対する包括的なユーザー向けの回答を提供します。このレスポンスは実用的で簡潔な形式で提示され、必要に応じて使用したソースへの参照や引用を含めることができます。
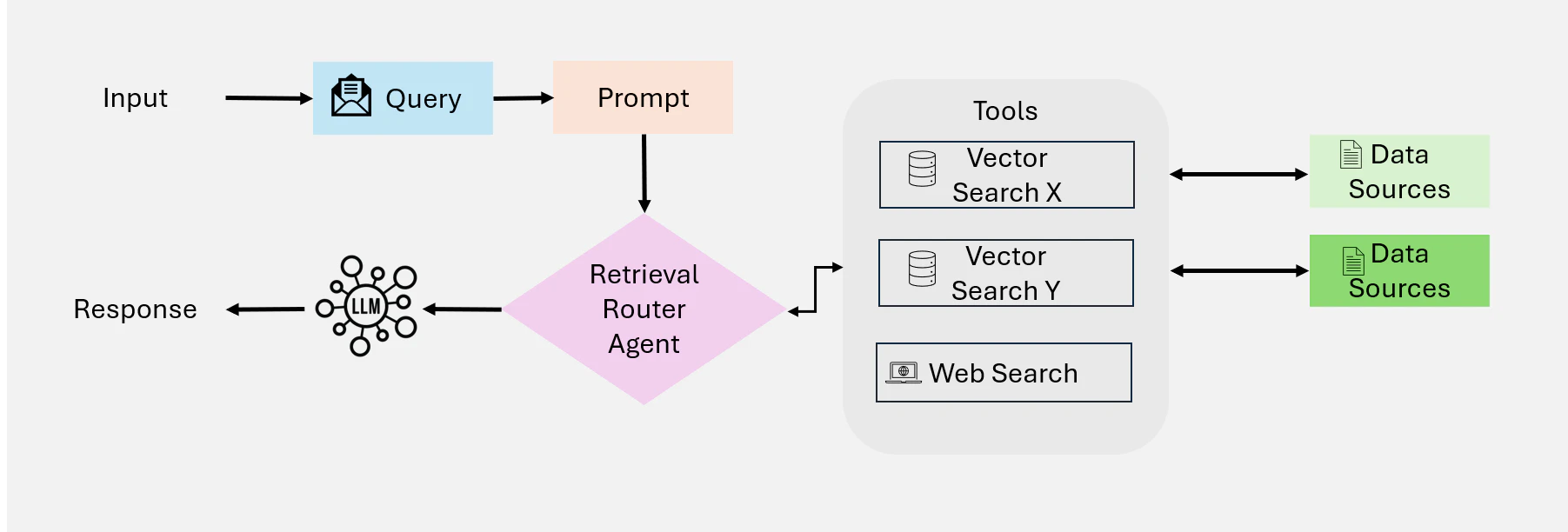
Figure 16: Single Agentic RAG 概要
主な特徴と利点
- 集中型の単純さ: Single Agent がすべての検索とルーティングタスクを処理するため、アーキテクチャの設計、実装、保守が容易
- 効率性とリソースの最適化: Agent の数が少なくシンプルに調整できるため、システムの計算リソース要求が少なく、クエリをより迅速に処理可能
- 動的ルーティング: Agent がリアルタイムで各クエリを評価し、最適な Knowledge Source (RDB, セSemantic Search, Web 検索など)を選択
- Tool 間の汎用性:様々なデータソースと外部 API をサポートし、構造化および非構造化ワークフローの両方に対応
- シンプルなシステムに最適: 明確に定義されたタスクや限定的な統合要件(文書検索、SQL ベースのワークフローなど)を持つアプリケーションに適す
Prompt:
システムプロセス(Single-Agent ワークフロー):
1. クエリの送信と評価:
* ユーザーがクエリを送信し、Coodinating Agent が受信
* Coodinating Agent がクエリを分析し、最適な情報源を判断
2. Knowledge Source の選択
* 注文管理データベースから追跡詳細を取得
* 配送業者の API から最新情報を取得
* 必要に応じて天候や物流遅延など、配送に影響を与えるローカルな状況を特定するために Web 検索を実施
3. データ統合と LLM 合成
* 関連データが LLM に渡され、情報が一環したレスポンスに合成される
4. 出力生成
* システムが実用的で完結なレスポンスを生成し、ライブ追跡更新と潜在的な代替案を提供
レスポンス:
統合レスポンス: 「お客察まの荷物は現在配送中で、明日の夕方に到着予定です。UPS のライブ追跡によると、地域の配送センターに到着しています。」
5.2 Multi-Agent Agentic RAG:
Multi-Agent RAG は、複雑なワークフローと多様なクエリタイプを処理するために、複数の専門化された Agent を活用する、Modular 式でスケーラブルな Single-Agent アーキテクチャの進化形を表しています(Figure 17に示す通り)。推論、検索、レスポンス生成といったすべてのタスクを 1 つの Agent に依存するのではなく、このシステムは特定の役割やデータソースに最適化された複数の Agent に責任を分散させています。
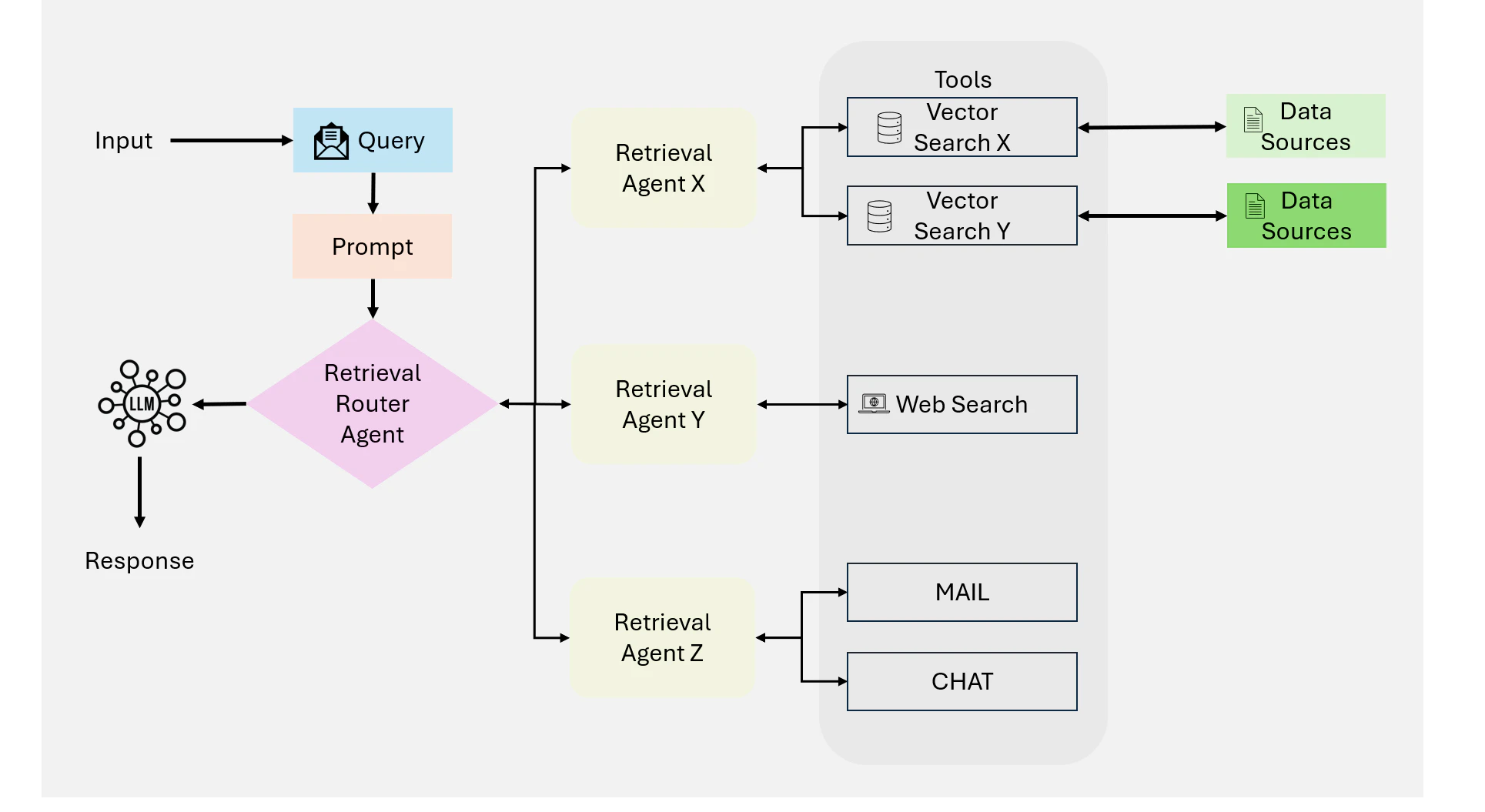
Figure 17: Multi-Agent Agentic RAG の概要
ワークフロー
-
クエリの送信: プロセスはユーザークエリから始まり、Coordinator Agent または Master Retrieve Agentに送られます。この Agent は中央の Orchestrator として機能し、クエリの要件に基づいて専門の Retrieval Agent にクエリを委任します
-
専門 Retrieval Agent: クエリは複数の Retrieval Agents 間で分散され、それぞれが特定のタイプのデータソースまたはタスクに焦点を当てます。例えば:
• Agent 1:PostgreSQL や MySQL などの SQL ベースのデータベースとの対話など、構造化クエリを処理します。
• Agent 2:PDF、書籍、内部記録などのソースから非構造化データを取得するためのセマンティック検索を管理します。
• Agent 3:Web 検索や API からリアルタイムの公開情報を取得することに焦点を当てます。
• Agent 4:ユーザーの行動やプロファイルに基づいてコンテキストを考慮した提案を提供する推薦システムを専門とします。 -
ツールアクセスとデータ検索:各 Agent は、そのドメイン内の適切なツールやデータソースにクエリをルーティングします:
• ベクトル検索:意味的関連性のため
• Text-to-SQL:構造化データのため
• ウェブ検索:リアルタイムの公開情報のため
• API:外部サービスまたは独自システムへのアクセスのため
検索プロセスは並列で実行され、多様なクエリタイプの効率的な処理を可能にします。 -
データ統合と LLM 合成検索: 検索が完了すると、すべての Agent からのデータは LLM にわたり、LLM は与えられた情報を、複数のソースからの洞察をシームレスに統合し、一貫性のある文脈に即したレスポンスへ合成
-
出力生成: システムは包括的なレスポンスを生成し、ユーザーにとって実行可能な簡潔な形式でユーザーに返却します
主な特徴と利点
- モジュール性:各 Agent が独立して動作し、システム要件に基づいて Agent の追加や削除がシームレスに行える
- スケーラビリティ:複数の Agent による並列処理により、システムは大量のクエリを効率的に処理できる
- タスク専門化:各 Agent は特定のタイプのクエリやデータソースに最適化され、精度と検索の関連性を向上させる
- 効率性:専門化された Agent 間でタスクを分散することで、システムはボトルネックを最小限に抑え、複雑なワークフローのパフォーマンスを向上させる
- 汎用性:研究、分析、意思決定、カスタマーサポートなど、ドメインをまたいだアプリケーションに適する
課題
- 連携の複雑さ:Agent 間の通信とタスク委譲の管理には、高度な調整メカニズムが必要
- 計算オーバーヘッド:複数の Agent の並列処理によりリソース使用量が増加する可能性
- データ統合:多様なソースからの出力を一貫した応答に統合することは難しく、高度な LLM が必要
Prompt: ヨーロッパにおける再生可能エネルギー導入の経済的・環境的影響はなんですか?
システムプロセス(Multi-Agent ワークフロー):
* Agent 1: SQL ベースのクエリを使用して経済 DB から統計データを取得
* Agent 2: Semantic Search Tool を使用して関連する学術論文を検索
* Agent 3: 再生可能エネルギーに関する最新のニュースと制作更新について Web 検索を実行
* Agent 4: レポートや専門家のコメントなどの関連コンテンツを提案するため、推薦システムに相談
レスポンス:
統合レスポンス:
「EUの政策報告によると、ヨーロッパにおける再生可能エネルギーの導入により、過去10年間で温室効果ガスの排出量が20%削減されました。経済的には、再生可能エネルギーへの投資により約120万人の雇用が創出され、特に太陽光発電と風力発電の分野で大きな成長が見られました。また、最近の学術研究では、送電網の安定性とエネルギー貯蔵コストにおける潜在的なトレードオフも指摘されています。」
5.3 Hierarchical Agentic RAG
Hierarchical Agentic RAGは、Figure 18 に示すように、情報検索と処理に構造化された多層アプローチを採用し、効率性と戦略的意思決定の両方を向上させます。Agent は階層的に組織され、上位の Agent が下位の Agent を監督し指示を行います。この構造により多層的な意思決定が可能となり、クエリが最も適切なリソースによって処理されることを保証します。
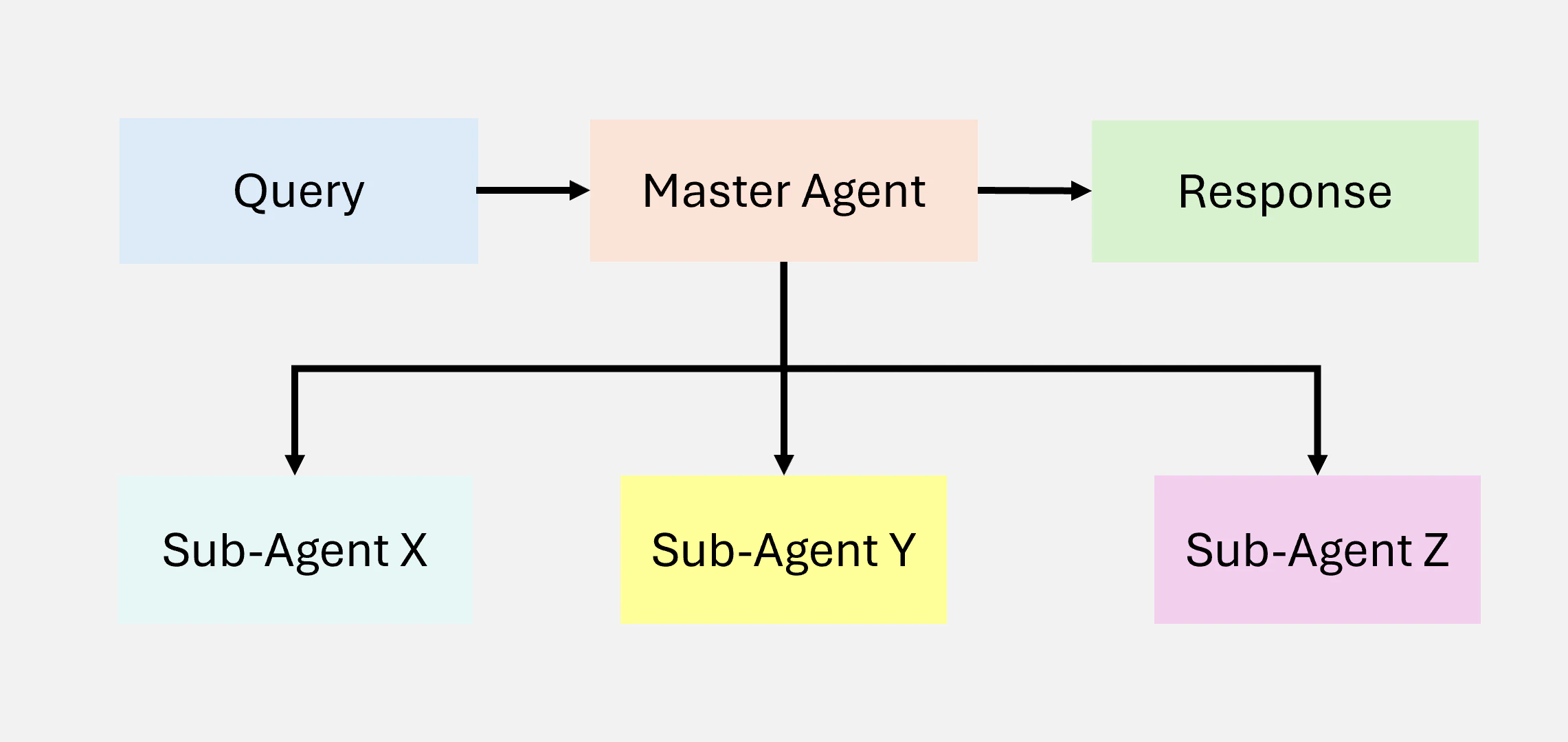
Figure 18: Hierarchical Agentic RAG の図解
ワークフロー
- クエリ受付:ユーザーがクエリを送信し、初期評価と委任を担当する top-tier Agent が受付
- 戦略的意思決定:top-tier Agent がクエリの複雑さを評価し、どのサブ Agent やデータソースを優先するかを決定します。クエリの領域に基づいて、特定のデータベース、API、または検索ツールがより信頼できるか、または関連性が高いと判断される場合がある
- Subordinate Agent への委任:top-tier Agentが、特定の検索方法(SQLデータベース、ウェブ検索、独自システムなど)に特化した下位レベルの Agent にタスクを割り当てます。これらの Agent は独立して割り当てられたタスクを実行
- 集約と統合:上位レベル Agent が Subordinate Agent からの結果を収集・統合し、情報を一貫した応答へと統合
- レスポンスの配信:最終的に統合された回答がユーザーに返され、応答が包括的かつ文脈的に適切であることを確保
主な特徴と利点
- 戦略的優先順位付け:top-tier Agentは、クエリの複雑さ、信頼性、またはコンテキストに基づいてデータソースやタスクの優先順位を付けることができる
- スケーラビリティ:複数の Agent tier 間でタスクを分散することで、非常に複雑な、または多面的なクエリの処理が可能に
- 強化された意思決定:上位レベルの Agent が戦略的な監督を適用し、応答全体の正確性と一貫性を向上
課題
- 調整の複雑さ:複数レベルにまたがる Agent 間の堅牢なコミュニケーションを維持することで、オーケストレーションのオーバーヘッドが増加する可能性
- リソース配分:ボトルネックを避けるためにティア間でタスクを効率的に分散させるのは難しい
Prompt: 再生可能エネルギーの現在の市場動向を考慮した場合、最適な投資オプションは何でしょうか?
システムプロセス (Hierarchical Agentic Workflow):
1. Top-Tier Agent: クエリの複雑さを評価し、信頼性の低いデータソースよりも、信頼できる金融データベースと経済指標を優先
2. Mid-Level Agent: 独自の API と構造化された SQL データベースからリアルタイムの市場データ(株価、セクターパフォーマンスなど)を取得
3. Lower-Level Agent(s): 最近の政策発表についてウェブ検索を実施し、専門家の意見やニュース分析を追跡する推奨システムを参照
4. 集約と統合: Top-Tier Agentが結果をまとめ、定量的データと政策の洞察を統合
レスポンス:
統合されたレスポンス:「現在の市場データによると、再生可能エネルギー株は、政府の支援政策と投資家の関心の高まりに後押しされ、過去四半期で15%の成長を示しています。アナリストらは特に風力および太陽光発電セクターが引き続き勢いを維持する可能性がある一方、グリーン水素などの新興技術は適度なリスクがあるものの、潜在的に高いリターンをもたらす可能性があると示唆しています。」
5.4 Agentic Corrective RAG
Corrective RAG:文書の利用を強化し、Figure 19 で示されているようにレスポンス生成の品質を向上させるため、検索結果を自己修正するメカニズムを導入します。ワークフローに Intelligent Agent を組み込むことで、Corrective RAG はコンテキスト文書とレスポンスの反復的な改善を確実に行い、エラーを最小限に抑え、関連性を最大化します。
Corrective RAG の主要なアイデア:Corrective RAG の核となる原則は、検索された文書を動的に評価し、修正アクションを実行し、生成されるレスポンスの品質を向上させるためにクエリを改善する能力にあります。Corrective RAG は以下のようにアプローチを調整します:
-
文書の関連性評価:検索された文書は、Relevance Evaluation Agent によって関連性が評価されます。関連性の閾値を下回る文書は修正ステップを引き起こす
-
クエリの改善と拡張:Query Refinement Agent によってクエリが改善され、より良い結果を得るために意味的理解を活用して検索を最適化
-
外部ソースからの動的検索:コンテキストが不十分な場合、External Knowledge Retrieval Agent は Web 検索を実行するか、代替データソースにアクセスして、取得した文書を補完
-
レスポンス生成:検証および精緻化されたすべての情報は、最終的なレスポンス生成のために Response Synthesis Agent へ渡す
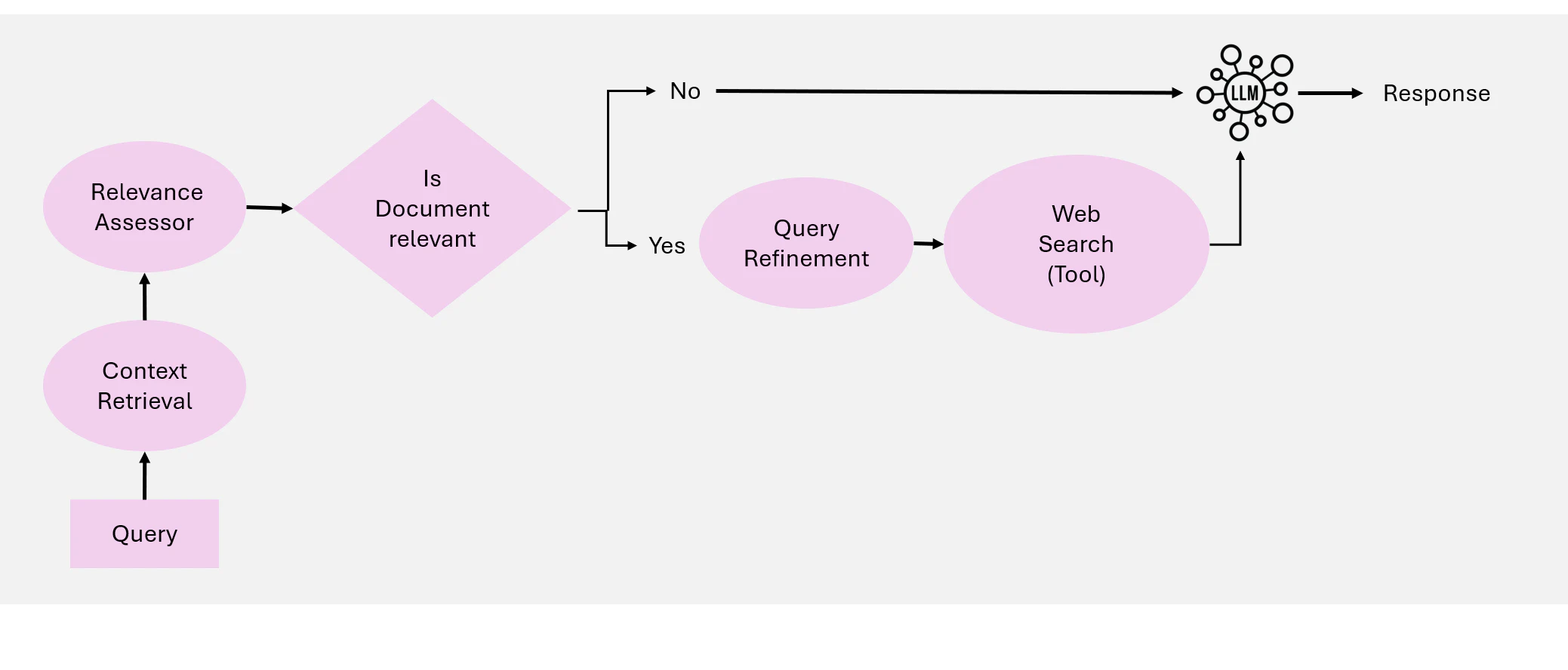
Figure 19: Agentic Corrective RAG の概要
ワークフロー: Corrective RAG システムは 5 つの主要な Agent で構成されています:
- Context Retrieval Agent: ベクトル DB から初期コンテキストドキュメントを取得する役割を担う
- Relevance Evaluation Agent: 取得したドキュメントの関連性を評価し、関連性のない、または曖昧なドキュメントに対して修正アクションのフラグ立て
- Query Refinement Agent: 意味的な理解を活用して結果を最適化し、検索結果を改善するためにクエリを書き換え
- External Knowledge Retrieval Agent: コンテキストドキュメントが不十分な場合に Web 検索を実行したり、代替データソースにアクセス
- Response Synthesis Agent: 検証されたすべての情報を一貫性のある正確なレスポンスに統合
主要な特徴と利点:
• 反復的な修正: 関連性のない、または曖昧な検索結果を動的に特定し修正することで、高いレスポンスの正確性を確保します。
• 動的な適応性: リアルタイムのウェブ検索とクエリ改善を組み込み、検索精度を向上させます。
• Agent のモジュール性: 各 Agent が専門的なタスクを実行し、効率的でスケーラブルな運用を確保します。
• 事実性の保証: 取得および生成されたすべてのコンテンツを検証することで、幻覚や誤情報のリスクを最小限に抑えます。
プロンプト: 生成 AI 研究における最新の発見は何ですか?
システムプロセス (Corrective RAG ワークフロー):
1. クエリ送信: ユーザーがシステムにクエリを送信
2. コンテキスト取得:
* Context Retrieval Agent が生成AIに関する公開論文のデータベースから初期文書を取得
* 取得された文書は評価のため次のステップに渡される
3. 関連性評価:
* Relevance Evaluation Agent がクエリとの整合性について文書を評価
* 文書は関連性あり、曖昧、関連性なしのカテゴリーに分類。関連性のない文書は是正措置のためにフラグ立て
4. 是正措置(必要な場合):
* Query Refinement Agent が具体性と関連性を向上させるためにクエリを書き換え
* External Knowledge Retrieval Agent が外部ソースから追加の論文やレポートを取得するために Web 検索を実行
5. レスポンス生成:
* Response Synthesis Agent が検証済みの文書を統合して、一貫性のある包括的な要約を作成
レスポンス:
統合レスポンス: 「生成AIにおける最近の発見では、拡散モデル、テキストから動画への変換タスクにおける強化学習、大規模モデルトレーニングの最適化技術における進歩が強調されています。」
5.5 Adaptive Agentic RAG
Adaptive RAG は、入力クエリの複雑さに基づいてクエリ処理戦略を動的に調整することで、大規模言語モデル(LLM)の柔軟性と効率性を向上させます。静的な検索ワークフローとは異なり、Adaptive RAG はクエリの複雑さを評価し、最適なアプローチを決定するための分類器を採用しています。Figure 20 に示されているように、単一ステップの検索から多段階の推論まで、あるいは単純なクエリの場合は検索を完全に省略することまで、様々なアプローチを取ることができます。
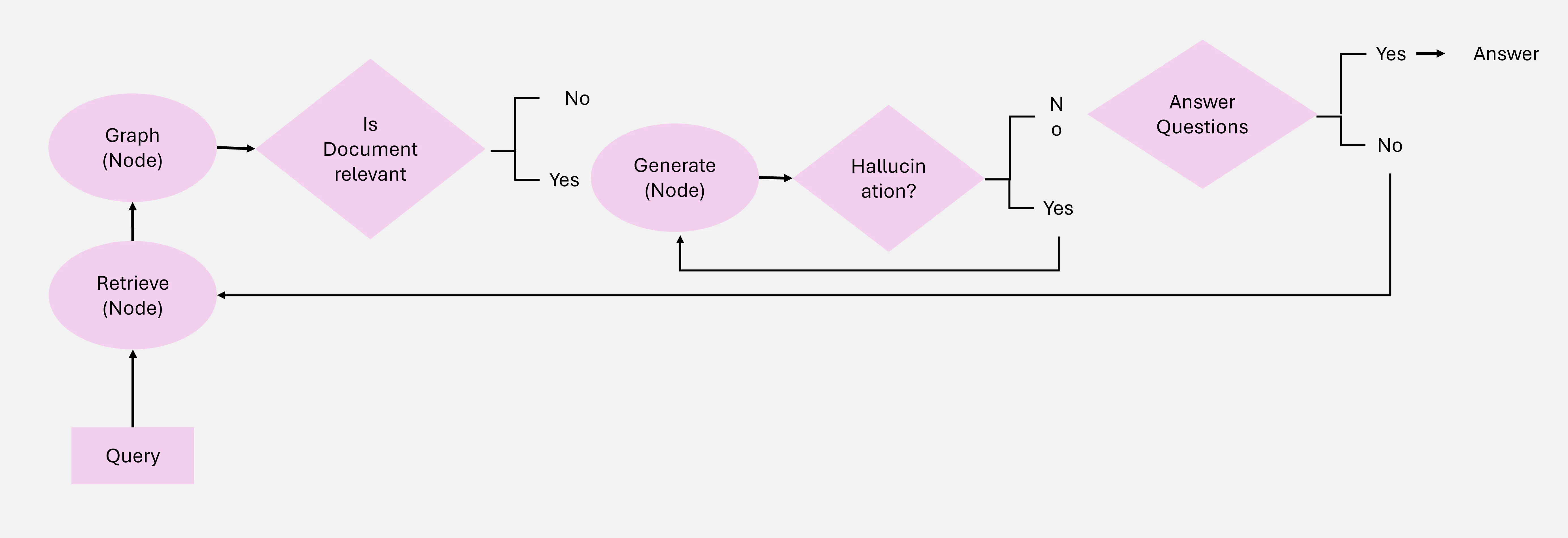
Figure 20: Adaptive Agentic RAG の概要
Adaptive RAGの主要なアイディア
Adaptive RAG の中核となる原則は、クエリの複雑さに基づいて検索戦略を動的に調整する能力にあります。Adaptive RAG は以下のように対応を調整します:
-
単純なクエリ:追加の検索が不要な事実ベースの質問(例:「水の沸点は何度ですか?」)に対して、システムは既存の知識を使用して直接回答を生成
-
簡単なクエリ:最小限のコンテキストを必要とする中程度の複雑さのタスク(例:「最新の電気料金の状況はどうなっていますか?」)に対して、システムは関連する詳細を取得するために単一ステップの検索を実行
-
複雑なクエリ:反復的な推論を必要とする多層的なクエリ(例:「X市の人口は過去10年でどのように変化し、その要因は何ですか?」)に対して、システムは多段階の検索を採用し、中間結果を段階的に改善して包括的な回答を提供
ワークフロー:Adaptive RAGシステムは3つの主要なコンポーネントで構成
- 分類器の役割:
- 小規模な言語モデルがクエリを分析して、その複雑さを予測
- 分類器は、過去のモデルの結果とクエリパターンから導出された自動ラベル付きデータセットを使用して訓練
- 動的戦略選択:
- 単純なクエリに対しては、不要な検索を避け、LLMを直接活用してレスポンスを生成
- 簡単なクエリに対しては、関連するコンテキストを取得するために単一ステップの検索プロセスを採用
- 複雑なクエリに対しては、反復的な改善と強化された推論を確保するために多段階検索を有効化
- LLM統合:
- LLM は検索された情報を一貫性のあるレスポンスに統合
- LLMと分類器の間の反復的な相互作用により、複雑なクエリの改善が可能に
主な特徴と利点
- 動的適応性:クエリの複雑さに基づいて検索戦略を調整し、計算効率とレスポンスの正確性の両方を最適化
- リソース効率:単純なクエリに対する不要なオーバーヘッドを最小限に抑えながら、複雑なクエリに対する徹底的な処理を確保
- 向上した精度:反復的な改善により、複雑なクエリが高精度で解決
- 柔軟性:ドメイン固有のツールや外部 API など、追加のパスを組み込むように拡張可能
Prompt: 私の荷物が遅延しているのはなぜですか?また、どのような代替案がありますか?
システムプロセス(Adaptive RAG ワークフロー):
1. クエリ分類:
* 分類システムがクエリを分析し、複数ステップの推論が必要な複雑なケースと判断
2. 動的戦略選択:
* 複雑性の分類に基づき、システムが複数ステップの検索プロセスを起動
3. 複数ステップ検索:
* 注文データベースから追跡詳細を取得
* 配送業者APIからリアルタイムのステータス更新を取得
* 天候状況や地域の混乱などの外部要因についてウェブ検索を実行
4. レスポンス生成:
* LLMが取得した全情報を統合し、包括的で実行可能なレスポンスを生成
レスポンス:
統合レスポンス:「お客様の荷物は、お住まいの地域の悪天候により遅延しています。現在、地域の配送センターにあり、2日以内に配達される予定です。alternatively、施設での直接受け取りも可能です。」
5.6 Graph-Based Agentic RAG
5.6.1 Agnet-G: Agentic Framework for Graph RAG
Agent-G は、Graph Knowledge Bases と非構造化文書検索を統合する新しい Agentic アーキテクチャを導入します。構造化データと非構造化データソースを組み合わせることで、このフレームワークは推論と検索精度を向上させた RAG システムを実現します。モジュール式の検索バンク、動的な Agent 間の相互作用、フィードバックループを採用することで、Figure 21 に示すように高品質な出力を確保します。

Figure 21: Graph RAG のための Agentic Framework Agent-G の概要
Agent-G の主要なアイデア
Agent-G の中核原理は、Graph Knowledge Bases とテキスト文書の両方を活用し、専門化 Agent へ動的に検索タスクを割り当てる能力にあります。Agent-G は以下のように検索戦略を調整します:
- Graph Knowledge Bases:構造化データを使用して関係性、階層、つながりを抽出(例:ヘルスケアにおける疾病と症状のマッピング)
- 非構造化文書:従来のテキスト検索システムがグラフデータを補完する文脈情報を提供
- Critic Module:検索された情報の関連性と品質を評価し、クエリとの整合性を確保
- フィードバックループ:反復的な検証と再クエリを通じて検索と統合を改善
ワークフロー: Agent-Gシステムは4つの主要コンポーネントで構成
- Retriever Bank:
- グラフベースまたは非構造化データの検索に特化したエージェントのモジュール式セット
- クエリの要件に基づいて関連ソースを動的に選択するエージェント
- Critic Module:
- 検索されたデータの関連性と品質を検証
- 信頼性の低い結果を再検索または改善のためにフラグ付け
- 動的 Agent 連携:
- タスク固有のエージェントが協力して多様なデータタイプを統合
- グラフとテキストソース全体で一貫した検索と統合を確保
- LLM統合:
- 検証されたデータを一貫性のあるレスポンスに統合
- Critic からの反復的フィードバックによりクエリの意図との整合性を確保
主要な特徴と利点
- 強化された推論: グラフからの構造化された関係性と非構造化文書からの文脈情報を組み合わせる
- 動的適応性: クエリの要件に基づいて検索戦略を動的に調整
- 改善された精度: Critic module が不適切または低品質なデータのリスクを軽減
- スケーラブルなモジュール性: 専門タスク用の新しいエージェントの追加をサポートし、スケーラビリティを向上
Prompt: 2型糖尿病の一般的な症状は何で、それらは心臓病とどのように関連していますか?
システムプロセス(Agent-G ワークフロー):
1. クエリの受信と割り当て: システムはクエリを受信し、質問に包括的に答えるためにグラフ構造化データと非構造化データの両方が必要であることを特定
2. Graph Retriever:
* 医療知識グラフから2型糖尿病と心臓病の関係を抽出します。
* グラフの階層と関係性を探ることで、肥満や高血圧などの共通のリスク要因を特定します。
3. Document Retriever:
* 医学文献から2型糖尿病の症状(例:口渇増加、頻尿、疲労)の説明を取得
* グラフベースの知見を補完する文脈情報を追加
4. Critic Module:
* 取得したグラフデータと文書データの関連性と品質を評価
* 信頼性の低い結果に対して、改善や再クエリのフラグを立て
5. レスポンス合成:LLM は Graph Retriever と Document Retriever からの検証済みデータを、クエリの意図に沿った一貫したレスポンスに統合
レスポンス:
統合レスポンス:「2型糖尿病の症状には、口渇増加、頻尿、疲労が含まれます。研究によると、糖尿病と心臓病には50%の相関があり、主に肥満や高血圧などの共通のリスク要因を通じて関連しています。」
5.6.2 GeAR: Graph-Enhanced Agent for Retrieval-Augmented Generation
GeAR は、グラフベースの検索メカニズムを組み込むことで、従来の RAG を強化する Agentic Framework を導入します。グラフ拡張技術と Agent ベースのアーキテクチャを活用することで、GeAR は Figure 22 に示すように、マルチホップ検索シナリオの課題に対処し、複雑なクエリを処理するシステムの能力を向上させます。
GeAR の主要なアイデア
GeAR は以下の2つの主要な革新によってRAGの性能を向上させます:
- グラフ拡張: 従来のベース検索(例:BM25)を強化し、グラフ構造データを含めた検索プロセスに拡張することで、エンティティ間の複雑な関係と依存関係を捉えることを可能に
- Agent Framework: グラフ拡張を活用してより効果的に検索タスクを管理する Agent ベースのアーキテクチャを組み込み、検索プロセスにおける動的で自律的な意思決定を可能に
ワークフロー:
GeAR は以下のコンポーネントを通じて動作:
- グラフ拡張モジュール:
- 検索プロセスにグラフベースのデータを統合し、検索中にエンティティ間の関係を考慮することを可能に
- 接続されたエンティティを含むように検索空間を拡張することで、マルチホップクエリを処理するベース検索の能力を強化
- Agent ベースの検索:
- 検索プロセスを管理する Agent Framework を採用し、クエリの複雑さに基づいて検索戦略を動的に選択・組み合わせることを可能に
- Agent は検索された情報の関連性と正確性を向上させるために、グラフ拡張された検索パスを自律的に活用
- LLM統合:
- グラフ拡張によって強化された検索情報を、Large Language Model(LLM)の機能と組み合わせ、一貫性のある文脈に即したレスポンスを生成
- この統合により、生成プロセスが非構造化文書と構造化グラフデータの両方に基づいて行われることを保証
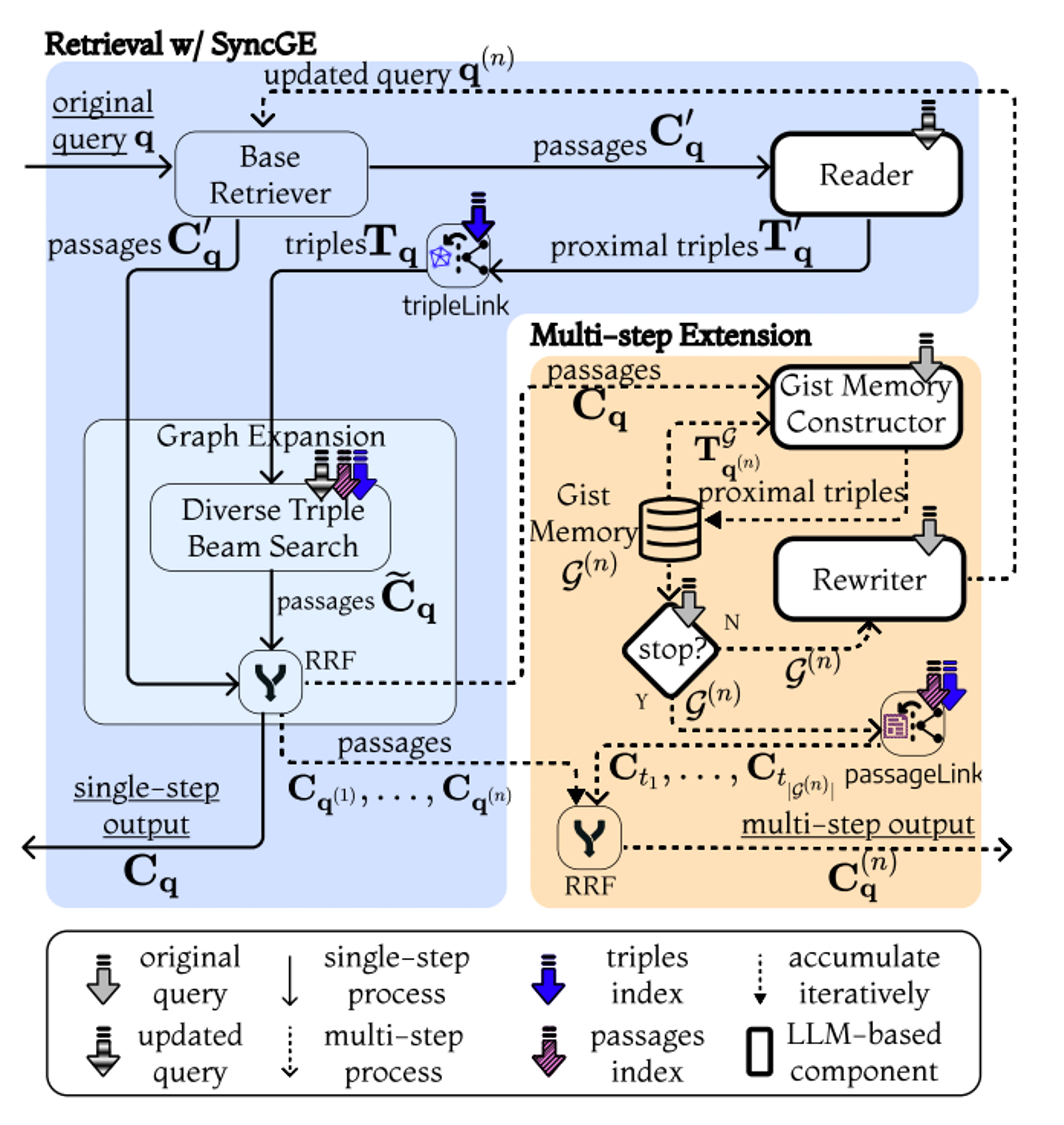
Figure 22: GeAR: Graph-Enhanced Agent for Retrieval-Augmented Generation の概要
主な特長と利点
- 強化されたマルチホップ検索: GeARのグラフ拡張により、複数の相互接続された情報に対する推論を必要とする複雑なクエリを処理することが可能
- Agentic Decision-Making: Agent Framework により、検索戦略の動的かつ自律的な選択が可能となり、効率性と関連性が向上
• 精度の向上: 構造化されたグラフデータを組み込むことで、GeAR は検索された情報の精度を高め、より正確で文脈に適したレスポンスを実現します。
• スケーラビリティ: Agent Framework のモジュール性により、必要に応じて追加の検索戦略やデータソースを統合することが可能です。
Prompt: J.K.ローリングのメンターに影響を与えた作家は誰ですか?
システムプロセス(GeAR ワークフロー):
1. Top-Tier Agent: クエリのマルチホップ性を評価し、質問に答えるためにはグラフ拡張と文書検索の組み合わせが必要だと判断
2. グラフ拡張モジュール:
* J.K.ローリングのメンターがクエリの重要なエンティティであると特定します。
* 文学的関係のグラフ構造データを探索して、そのメンターへの文学的影響を追跡します。
3. Agent-Based 検索:
* Agentが自律的にグラフ拡張された検索パスを選択し、メンターの影響に関する関連情報を収集
* メンターとその影響に関する非構造化の詳細情報を取得するために、テキストデータソースに問い合わせることで追加のコンテキストを統合
4. レスポンス合成:LLM を使用してグラフと文書検索プロセスからの洞察を組み合わせ、クエリの複雑な関係を正確に反映したレスポンスを生成します。
レスポンス:
統合レスポンス: 「J.K.ローリングのメンター[メンター名]は、[著名な作品やジャンル]で知られる[作家名]から大きな影響を受けました。この関係は、影響力のあるアイデアが多くの場合、複数の世代の作家を通じて伝わっていく文学史の重層的な関係性を示しています。」
5.7 Agentic Document Workflows in Agentic RAG
Agentic Document Workflows (ADW) は、E2E の Knowledge Work Automation を可能にすることで、従来の RAG パラダイムを拡張します。これらのワークフローは、文書解析、検索、推論、および構造化された出力を Intelligent Agent と統合することで、複雑な文書中心のプロセスを統制します。ADW は状態を維持し、複数ステップのワークフローを調整し、文書にドメイン固有のロジックを適用することで、Intelligent Document Processing (IDP) と RAG の限界に対処します。
ワークフロー
- 文書解析と情報構造化:
- 請求書番号、日付、ベンダー情報、明細項目、支払条件などの関連データフィールドを抽出するために、エンタープライズグレードのツール(LlamaParseなど)を使用して文書を解析
- 構造化データは後続の処理のために整理
- プロセス全体での状態維持:
- システムは文書のコンテキストに関する状態を維持し、複数ステップのワークフロー全体での一貫性と関連性を確保
- 様々な処理段階における文書の進行状況を追跡
- 知識検索:
- 外部 Knowledge Bases(LlamaCloudなど)やベクトルインデックスから関連する参照情報を検索
- 意思決定を強化するためのリアルタイムのドメイン固有ガイドラインを取得
- Agentic Orchestration:
- Intelligent Agent がビジネスルールを適用し、マルチホップ推論を実行し、実行可能な推奨事項を生成
- パーサー、リトリーバー、外部APIなどのコンポーネントをシームレスに統合するよう Orchestration
- ユーザーが実行可能な出力生成:
- 出力は特定のユースケースに合わせて構造化された形式で提示
- 推奨事項と抽出された洞察は、簡潔で実行可能なレポートにまとめる
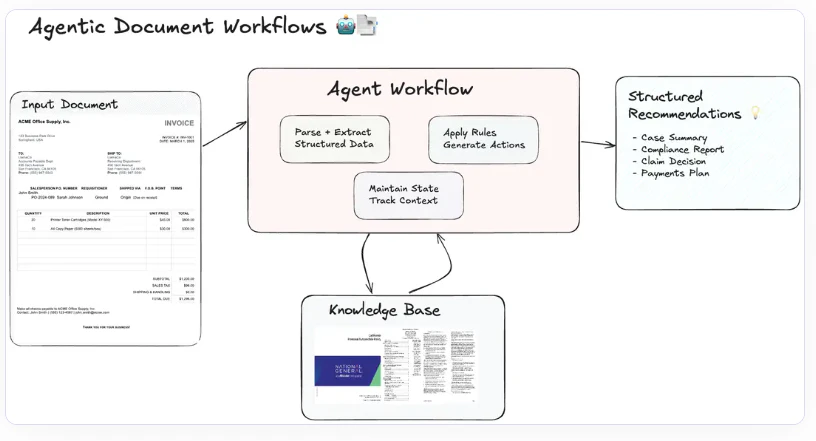
Figure 23: Agentic Document Workflows (ADW) の概要
Prompt: 提出された請求書とベンダー契約条件に基づいて支払い推奨レポートを生成
システムプロセス(ADWワークフロー):
1. 請求書を解析して、請求書番号、日付、ベンダー情報、明細項目、支払条件などの重要な詳細を抽出
2. 対応するベンダー契約を取得して、支払条件を確認し、適用可能な割引やコンプライアンス要件を特定
3. 当初支払額、早期支払割引の可能性、予算影響分析、戦略的支払アクションを含む支払推奨レポートを生成
レスポンス:
統合レスポンス:「請求書INV-2025-045(15,000.00ドル)の処理が完了しました。2025年4月10日までに支払う場合、2%の早期支払割引が適用され、支払額は14,700.00ドルに減額されます。小計が10,000.00ドルを超えたため、5%の大口注文割引が適用されました。2%の節約と今後のプロジェクトフェーズのための適時な資金配分を確保するため、早期支払いの承認が推奨されます。」
主な特徴と利点
- 状態管理: 文書のコンテキストとワークフローの段階を追跡し、プロセス全体での一貫性を確保
- 複数ステップのOrchestration: 複数のコンポーネントと外部ツールを含む複雑なワークフローを処理
- ドメイン固有の知識: 正確な推奨事項のために、カスタマイズされたビジネスルールとガイドラインを適用
- スケーラビリティ: Modular かつ動的な Agent 統合により、大規模な文書処理をサポート
- 生産性の向上:反復的なタスクを自動化しながら、意思決定における人間の専門知識を補強
6. Agentic RAG Framework の比較分析
Table 2 は、Traditional RAG、Agentic RAG、Agentic Document Workflows (ADW) という3つのアーキテクチャフレームワークの包括的な比較分析を提供しています。この分析は、それぞれの長所、短所、最適なシナリオを浮き彫りにし、様々なユースケースにおけるそれらの適用可能性について有益な洞察を提供しています。
Table 2: 比較分析: Traditional RAG vs Agentic RAG vs Agentic Document Workflows (ADW)
| 機能 | 従来型RAG | Agentic RAG | Agentic Document Workflows(ADW) |
|---|---|---|---|
| 焦点 | 単独の検索と生成タスク | マルチエージェントの連携と推論 | 文書中心のエンドツーエンドワークフロー |
| コンテキスト維持 | 限定的 | Memory Module | マルチステップワークフローでの状態維持 |
| 動的適応性 | 最小限 | 高い | 文書ワークフローに合わせた調整 |
| ワークフロー制御 | なし | Multi Agent タスクの統制 | マルチステップ文書処理の統合 |
| 外部ツール/ API 活用 | 基本的な統合(検索ツールなど) | API や Knowledge Base による拡張 | ビジネスルールやドメイン固有ツールの深い統合 |
| スケーラビリティ | 小規模データセットまたはクエリに限定 | Multi Agent システムに対応 | マルチドメイン企業ワークフローに対応 |
| 複雑な推論 | 基本的(単純なQ&Aなど) | Agent によるマルチステップ推論 | 文書全体での構造化された推論 |
| 主な用途 | Q&A システム、知識検索 | マルチドメインの知識と推論 | 契約書レビュー、請求書処理、請求分析 |
| 長所 | シンプル、素早い設定 | 高精度、協調的推論 | エンドツーエンド自動化、ドメイン固有の知能 |
| 課題 | 文脈理解の不足 | 連携の複雑さ | リソースのオーバーヘッド、ドメインの標準化 |
この比較分析は、Traditional RAG から Agentic RAG、さらに Agentic Document Workflows (ADW) への進化の軌跡を浮き彫りにしています。Traditional RAG は基本的なタスクに対してシンプルさと容易な導入を提供する一方、Agentic RAG はマルチエージェントの協調を通じて強化された推論とスケーラビリティを導入しています。ADW はこれらの進歩を基盤として、エンドツーエンドの自動化とドメイン固有プロセスとの統合を促進する堅牢なドキュメント中心のワークフローを提供することで、さらに発展を遂げています。特定のアプリケーション要件と運用上の要求を満たすために最適なアーキテクチャを選択する上で、各フレームワークの長所と限界を理解することが極めて重要です。
7. Agentic RAG の適用
Agentic Retrieval-Augmented Generation (RAG) は、様々な分野で革新的な可能性を示してきました。リアルタイムのデータ検索、生成能力、自律的な意思決定を組み合わせることで、これらのシステムは複雑で動的、かつマルチモーダルな課題に対応します。このセクションでは Agentic RAG の主要な応用について探り、これらのシステムがカスタマーサポート、ヘルスケア、金融、教育、法務ワークフロー、クリエイティブ産業などをどのように形作っているかについて詳細な洞察を提供します。
7.1 カスタマーサポートとバーチャルアシスタント
Agentic RAG は、リアルタイムで文脈を理解した質問解決を可能にすることで、カスタマーサポートに革命をもたらしています。従来のチャットボットやバーチャルアシスタントは、静的な知識ベースに依存することが多く、一般的または古い情報に基づいたレスポンスしか提供できませんでした。対照的に、Agentic RAG システムは最も関連性の高い情報を動的に検索し、ユーザーの文脈に適応して、パーソナライズされたレスポンスを生成します。
ユースケース:Twitch 広告販売の強化
例えば、Twitch は Amazon Bedrock を使用した agentic ワークフローと RAG を活用して、広告販売を効率化しました。このシステムは広告主データ、過去のキャンペーン実績、視聴者層データを動的に検索し、詳細な広告提案を生成することで、運用効率を大幅に向上させました。
主な利点:
- レスポンス品質の向上:パーソナライズされた文脈を理解したレスポンスによりユーザーエンゲージメントを向上
- 運用効率:複雑な問い合わせを自動化することで、人間のサポートエージェントの作業負荷を軽減
- リアルタイムの適応性:サービス停止や価格更新などの変化するデータを動的に統合
7.2 ヘルスケアとパーソナライズド医療
ヘルスケアにおいて、患者固有のデータと最新の医学研究を統合することは、情報に基づいた意思決定に不可欠です。Agentic RAG システムは、リアルタイムの臨床ガイドライン、医学文献、患者の履歴を検索することで、診断と治療計画において臨床医を支援します。
ユースケース:患者ケースサマリー
Agentic RAG は、患者ケースサマリーの生成に適用されています。例えば、電子カルテ(EHR)と最新の医学文献を統合することで、臨床医がより迅速で情報に基づいた判断を下せるよう、包括的なサマリーを生成します。
主な利点:
- パーソナライズドケア:個々の患者のニーズに合わせた推奨を提供
- 時間効率:関連研究の検索を効率化し、医療提供者の貴重な時間を節約
- 正確性:最新のエビデンスと患者固有のパラメータに基づく推奨を確保
7.3 法務契約分析
Agentic RAG は、迅速な文書分析と意思決定のためのツールを提供することで、法務ワークフローを再定義しています。
ユースケース:契約レビュー
法務向け Agentic RAG は、契約を分析し、重要な条項を抽出し、潜在的なリスクを特定することができます。意味検索機能と法的 Knowledge Graph を組み合わせることで、契約レビューの煩雑なプロセスを自動化し、コンプライアンスを確保しリスクを軽減します。
主な利点:
- リスク特定:標準条項から逸脱する条項を自動的にフラグ付け
- 効率性:契約レビュープロセスにかかる時間を削減
- スケーラビリティ:大量の契約を同時に処理
7.4 金融とリスク分析
Agentic RAG は、投資判断、市場分析、リスク管理のためのリアルタイムの洞察を提供することで、金融業界を変革しています。これらのシステムは、ライブデータストリーム、過去のトレンド、予測モデリングを統合して実用的な出力を生成します。
ユースケース: 自動車保険の請求処理
自動車保険において、Agentic RAG は請求処理を自動化できます。例えば、保険の詳細を検索し、事故データと組み合わせることで、規制要件に準拠しながら請求の推奨事項を生成します。
主な利点:
- リアルタイム分析:ライブ市場データに基づく洞察を提供
- リスク軽減:予測分析と多段階推論を使用して潜在的なリスクを特定
- 意思決定の向上:過去のデータとライブデータを組み合わせて包括的な戦略を立案
7.5 教育とパーソナライズド学習
教育は、Agentic RAG が大きな進展を見せているもう一つの分野です。これらのシステムは、学習者の進捗と好みに合わせた説明、学習教材、フィードバックを生成することで、適応型学習を可能にします。
ユースケース: 研究論文の生成
高等教育において、Agentic RAG は複数のソースから主要な知見を統合することで研究者を支援しています。例えば、「量子コンピューティングの最新の進歩は何か?」という質問に対して、参考文献を含む簡潔なサマリーを提供し、研究の質と効率を向上させます。
主な利点:
• カスタマイズされた学習パス:個々の学生のニーズと成績レベルに合わせてコンテンツを適応
• 魅力的なインタラクション:インタラクティブな説明とパーソナライズされたフィードバックを提供
• スケーラビリティ:多様な教育環境での大規模な展開をサポート
7.6 マルチモーダルワークフローにおけるグラフ強化アプリケーション
Graph-Enhanced Agentic RAG (GEAR) は、グラフ構造と検索メカニズムを組み合わせ、相互接続されたデータソースが不可欠なマルチモーダルワークフローで特に効果を発揮します。
ユースケース: 市場調査レポートの生成
GEAR は、マーケティングキャンペーンのためのテキスト、画像、動画の統合を可能にします。例えば、「エコフレンドリー製品の新興トレンドは何か?」という質問に対して、顧客の好み、競合分析、マルチメディアコンテンツを含む詳細なレポートを生成します。
主な利点:
- マルチモーダル機能:テキスト、画像、動画データを統合して包括的な出力を生成
- 創造性の向上:マーケティングとエンターテインメントのための革新的なアイデアとソリューションを生成
- 動的適応性:進化する市場トレンドと顧客ニーズに適応
Agentic RAG の応用は幅広い産業にまたがり、その汎用性と革新的な可能性を示しています。パーソナライズされたカスタマーサポートから適応型教育、グラフ強化マルチモーダルワークフローまで、これらのシステムは複雑で動的、かつ知識集約的な課題に対応します。検索、生成、エージェント型インテリジェンスを統合することで、Agentic RAG は次世代の AI アプリケーションへの道を切り開いています。
8 Agentic RAGのための Tool と Framework
Agentic Retrieval-Augmented Generation (RAG) は、検索、生成、Agentic Intelligence を組み合わせることで、大きな進化を遂げています。これらのシステムは、意思決定、クエリの再構築、適応型ワークフローを統合することで、従来の RAG を拡張します。以下の Tool と Framework は、実世界のアプリケーションの複雑な要件に対応する、Agentic RAG 開発のための堅牢なサポートを提供します。
主要な Tool と Framework:
-
LangChain と LangGraph: LangChain は RAG パイプラインを構築するための Modular Component を提供し、検索機能、生成機能、外部 Tool をシームレスに統合します。LangGraph は、ループ、状態の永続化、Human in the loop のインタラクションをサポートするグラフベースのワークフローを導入することで、これを補完し、Agent における高度な Orchestration と自己修正メカニズムを可能にします
-
LlamaIndex: LlamaIndex の Agentic Document Workflows (ADW)は、文書処理、検索、構造化された推論の完全な自動化を可能にします。コンプライアンス分析や文脈理解などのタスクのために、サブエージェントがより小さな文書セットを管理し、トップレベルのエージェントを通じて調整するメタエージェントアーキテクチャを導入しています。
-
Hugging Face Transformers と Qdrant: Hugging Face は embedding と生成タスクのための事前学習モデルを提供し、Qdrant は適応型ベクトル検索機能で検索ワークフローを強化し、Agent がスパースベクトルと密ベクトルの手法を動的に切り替えてパフォーマンスを最適化できるようにします
-
CrewAI と AutoGen: これらの Framework は Multi-Agent アーキテクチャを重視しています。CrewAI は階層的・順次的なプロセス、堅牢な memory システム、Tool 統合をサポートします。AG2(以前は AutoGen として知られていた)は、コード生成、ツール実行、意思決定の高度なサポートを備えた Multi-Agent Collaborationに優れています
-
OpenAI Swarm Framework: Agent の自律性と構造化された Collaboration を重視した、人間工学に基づく軽量な Multi-Agent Orchestration のための教育用 Framework
-
Vertex AIを使用した Agentic RAG: Google による Vertex AI は、Agentic Retrieval-Augmented Generation (RAG) とシームレスに統合され、堅牢で文脈を理解した検索と意思決定ワークフローを活用しながら、機械学習モデルの構築、デプロイ、スケーリングのためのプラットフォームを提供します
-
Semantic Kernel: Semantic Kernel は、Microsoft によるオープンソースの SDK で、大規模言語モデル(LLM)をアプリケーションに統合します。Agent パターンをサポートし、自然言語理解、タスク自動化、意思決定のための自律型 AI エージェントの作成を可能にします。ServiceNow の P1 インシデント管理などのシナリオで使用され、リアルタイムの Collaboration、タスク実行の自動化、コンテキスト情報の検索をシームレスに実現します
-
Agentic RAG のための Amazon Bedrock: Amazon Bedrock は Agentic Retrieval-Augmented Generation (RAG) ワークフローを実装するための堅牢なプラットフォームを提供します。
-
IBM Watson と Agentic RAG: IBM の watsonx.ai は、Granite-3-8B-Instruct モデルを使用して外部情報を統合し、レスポンスの正確性を向上させることで、複雑なクエリに答える Agentic RAG システムの構築をサポートします
-
Neo4j とベクトル DB: 著名なオープンソースのグラフデータベースである Neo4j は、複雑な関係と意味検索の処理に優れています。Neo4j と並んで、Weaviate、Pinecone、Milvus、Qdrantなどのベクトル DB は、効率的な類似性検索と検索機能を提供し、高性能な Agentic Retrieval-Augmented Generation (RAG)ワークフローの基盤を形成しています
9 ベンチマークとデータセット
現在のベンチマークとデータセットは、Agentic およびグラフベースの拡張機能を含む RAG の評価に関する貴重な洞察を提供します。一部は RAG 専用に設計されていますが、他のものは様々なシナリオでの検索、推論、生成能力をテストするために適応されています。データセットは RAG の検索、推論、生成コンポーネントのテストに不可欠です。Table 3は RAG 評価のためのダウンストリームタスクに基づいた主要なデータセットについて説明しています。
ベンチマークは、構造化されたタスクと指標を提供することで、RAG の評価を標準化する上で重要な役割を果たします。以下のベンチマークは特に関連性が高いです:
-
BEIR(情報検索のベンチマーク): 生物情報学、金融、質問応答など、多様な領域にわたる 17 のデータセットを包含する、情報検索タスクにおける embedding モデルを評価するための多目的ベンチマーク
-
MS MARCO(Microsoft 機械読解): パッセージランキングと質問応答に焦点を当てたこのベンチマークは、RAG の密な検索タスクに広く使用されています
-
TREC(テキスト検索会議、ディープラーニングトラック): 検索パイプラインにおけるランキングモデルの品質を重視した、パッセージおよびドキュメント検索用のデータセットを提供します
-
MuSiQue(マルチホップ逐次質問): 複数のドキュメントにまたがるマルチホップ推論のためのベンチマークで、切断された文脈からの情報の検索と統合の重要性を強調します
-
2WikiMultihopQA: 2 つの Wikipedia 記事をまたぐマルチホップQAタスク用に設計されたデータセットで、複数のソースにわたる知識の接続能力に焦点を当てています
-
AgentG(知識融合のための Agentic RAG): Agentic RAG タスク向けに調整されたこのベンチマークは、複数の Knowledge Bases にまたがる動的な情報統合を評価します
-
HotpotQA: 相互接続された文脈にわたる検索と推論を必要とするマルチホップ QA ベンチマークで、複雑な RAG ワークフローの評価に適しています
-
RAGBench: 産業分野にわたる 100,000 の例を特徴とする大規模な説明可能なベンチマークで、実用的な RAG メトリクスのための TRACe 評価フレームワークを備えています
-
BERGEN(Retrieval-Augmented Generation のベンチマーク): 標準化された実験による RAG の体系的なベンチマークのためのライブラリです
-
FlashRAG Toolkit: 12 の RAG 手法を実装し、効率的で標準化された RAG 評価をサポートする32のベンチマークデータセットを含みます
-
GNN-RAG: このベンチマークは、ノードレベルとエッジレベルの予測などのタスクでグラフベースの RAG を評価し、Knowledge Graph Question Answering(KGQA)における検索品質と推論性能に焦点を当てています
Table 3: RAG評価のためのダウンストリームタスクとデータセット
| Category | Task Type | Datasets and References |
|---|---|---|
| QA | Single-hop QA | Natural Questions (NQ), TriviaQA, SQuAD, Web Questions (WebQ), PopQA, MS MARCO |
| Multi-hop QA | HotpotQA, 2WikiMultiHopQA, MuSiQue | |
| Long-form QA | ELI5, NarrativeQA (NQA), ASQA, QMSum | |
| Domain-specific QA | Qasper, COVID-QA, CMB/MMCU Medical | |
| Multi-choice QA | QuALITY, ARC (No reference available), CommonsenseQA | |
| Graph-based QA | Graph QA | GraphQA |
| Event Argument Extraction | WikiEvent, RAMS | |
| Dialog | Open-domain Dialog | Wizard of Wikipedia (WoW) |
| Personalized Dialog | KBP, DuleMon | |
| Task-oriented Dialog | CamRest | |
| Recommendation | Personalized Content | Amazon Datasets (Toys, Sports, Beauty) |
| Reasoning | Commonsense Reasoning | HellaSwag, CommonsenseQA |
| CoT Reasoning | CoT Reasoning | |
| Complex Reasoning | CSQA | |
| Others | Language Understanding | MMLU (No reference available), WikiText-103 |
| Fact Checking/Verification | FEVER, PubHealth | |
| Strategy QA | StrategyQA | |
| Summarization | Text Summarization | WikiASP, XSum |
| Long-form Summarization | NarrativeQA (NQA), QMSum | |
| Text Generation | Biography | Biography Dataset (No reference available) |
| Text Classification | Sentiment Analysis | SST-2 |
| General Classification | VioLens, TREC | |
| Code Search | Programming Search | CodeSearchNet |
| Robustness | Retrieval Robustness | NoMIRACL |
| Language Modeling Robustness | WikiText-103 | |
| Math | Math Reasoning | GSM8K |
| Machine Translation | Translation Tasks | JRC-Acquis |
10 まとめ
代理的な Agentic Retrieval-Augmented Generation (RAG)は、従来の RAG の限界を自律型 Agentの統合によって克服する、画期的な人工知能の進歩を表しています。Agent の知性を活用することで、これらのシステムには動的な意思決定、反復的な推論、協調的なワークフローなどの機能が導入され、複雑な現実世界のタスクをより高い精度と適応性で処理できるようになりました。
この調査では、RAG の進化の過程を、初期の実装から、Modular RAG などの先進的なパラダイムまで探っています。Agent を RAG パイプラインに統合することが重要な進展として浮かび上がり、固定的なワークフローや限定的な文脈適応性を克服した Agentic RAG が登場しました。ヘルスケア、金融、教育、クリエイティブ産業などでの応用例が、これらのシステムの変革的な可能性を示しています。それらは個別化された、リアルタイムの、文脈に適応した解決策を提供できるのです。
期待されるものの Agentic RAG にはいくつかの課題があり、さらなる研究と革新が必要とされています。Multi-Agent アーキテクチャの調整の複雑さ、スケーラビリティ、レイテンシの問題、そして倫理的な考慮事項などに取り組む必要があります。また、Agent の機能を評価するための特化したベンチマークやデータセットの不足も大きな障壁となっています。Multi-Agent Collaboration や動的な適応性といった Agentic RAGの独自の側面を捉えるための評価手法の開発が、この分野の発展には不可欠です。
今後を見据えると、RAG と Agentic intelligence の融合は、動的で複雑な環境における AI の役割を再定義する可能性を秘めています。これらの課題に取り組み、将来の方向性を探ることで、研究者や実務者はAgentic RAG の可能性を最大限に引き出し、産業や分野を超えた革新的なアプリケーションへの道を切り開くことができます。AI が進化し続ける中、Agentic RAG は、急速に変化する世界の要求に応える、適応性があり、文脈を理解し、影響力のあるソリューションを生み出すための礎となっています。
99 翻訳注
自分が翻訳しながら読んだので、表記揺れは多々あると思いますが以下を意識しています。直して欲しいところがあったらコメントいただければできる範囲で修正します。
- Agent -> Agent そのまま
- Agentic RAG -> Agentic RAG そのまま
- Prompt Chaining : Prompt Chaning そのまま
- RAG system -> RAG
- retrieve -> 検索(本来の(?)情報の取得的な意味とちょっとズレている気もするけど)
- Multi-Step Reasoning -> 多段階推論 (推論は predict, inference, reasoning いろいろありますね・・・)
- Contextual XX -> コンテキスト XX 、コンテキストの〜