はじめに
本記事はNew Relic Advent Calendar 202410日目のエントリーです![]()
![]()
![]()
開発チーム内でのSLO1運用が軌道に乗り始めると、次のような課題が浮上することがあります。
それはSLOが開発チームだけの関心事とされ、ビジネスサイドから十分な理解を得るのが難しいという点です。
この記事では、このような課題に対処するための有効なアプローチとして 「ビジネスオブザーバビリティ」 を提案するとともに、New Relicの新機能Pathpoint2 の活用方法を紹介します。
対象読者
- ステークホルダーとのSLOの合意形成を効率的に進めたい方
- SLO違反のビジネスへの影響を正しく計測し、経営判断に活用したい方
- New Relicを活用したビジネスオブザーバビリティに興味がある方
SLOがBizサイドに理解されづらい問題
次の画像は、BizサイドにSLOの重要性を説明し、具体的な目標値について合意を得る際に直面しがちなシチュエーションを示しています。

この例では、DevサイドがBizサイドに対し、サービス稼働率のSLOについて説明を行い、合意を求めました。
その際の主な内容は以下の通りです。
SLOに関する説明内容
100%の信頼性維持が現実的でないこと
- 変更と更新の不可避性:新機能の追加やセキュリティ更新など、サービスを運用するうえでダウンタイムや一時的な不安定さは避けられない
- 外部要因の影響:天災、外部APIなど、サービス側では制御できない要因が存在する
- コストの非効率性:100%の信頼性を目指そうとすると、開発・運用・インフラのコストが著しく増大する(どこまでテストするか、冗長化するか問題)
エラーバジェット3の概要
- 99.5%の可用性では年間43.8時間、月間3.65時間の停止が許容される
- 99.9%の可用性では年間8.76時間、月間43.8分の停止が許容される
SLOを定める目的
- 完璧さを求めず、エラーバジェットの残量を見ながら信頼性を適切にコントロールしたい
- 残量に余裕があるとき:テストを簡略化し、すぐ切り戻せる状態で本番デプロイ → 開発効率Up
- 残量が枯渇しそうなとき:根本原因の調査や恒久対策を優先し、機能追加は後回し → 信頼性の回復を重視
次に、許容可能な停止時間の合意を得ようとしますが、
Bizサイドの視点では、SLOの重要性は理解するものの「許容可能なサービス停止時間」の設定は難しいと感じてしまいがちです。
BizサイドにとってSLOの判断が難しい理由
Devサイドからの「許容可能なサービス停止時間はどれくらいか?」というシンプルな問いに対し、Bizサイドは判断材料が不足していると感じることが多くあります。
その背景には、DevとBizが重視する観点や直面する課題が異なるという現実があります。
DevとBizの観点の違い
以下は、DevとBizが重視するポイントと、それぞれが避けたいと考える事例を比較した表です。
| チーム | 重視する観点 | 避けたい事例 |
|---|---|---|
| Dev | 信頼性や安定した性能の確保 | サービス停止、パフォーマンス遅延、エラー頻発 等 |
| Biz | ビジネス成果や収益の最大化 | 売上減少、顧客離れ、機会損失 等 |
Devサイドは技術的な問題の回避を重視し、サービスの信頼性や性能の維持に注力します。
一方で、Bizサイドはこれらの問題が売上や顧客満足度といったビジネス指標に与える影響に注目しています。
ビジネス的な影響判断の難しさ
たとえば、1時間のサービス停止が発生した場合、Devサイドにとってはただの「1時間の停止」に過ぎないかもしれません。
しかしBizサイドは「1時間の停止」がビジネスに与える影響を考慮します。
その損失は発生した時間帯(平日、休日、深夜、ランチタイム、通勤時間など)によって大きく異なるため、単純に評価するのは難しいと感じるのです。
そして、この課題はサービス停止時間だけにとどまりません。
たとえば、SLOがレイテンシやエラー率といった指標で設定されている場合でも、目標値からの乖離が具体的にどのようなビジネス損失を招くのかが明確でなければ、Bizサイドは適切な評価や判断を下すのが難しいと感じたままでしょう。
課題の本質
DevとBizが重視する視点の違いは、SLOの共通理解や目標設定を難しくする要因の一つと考えられます。
このギャップを埋めるためには、技術的なデータをビジネス指標に翻訳し、両者が共通の言語で議論できる基盤を整えることが有効です。
DevとBizの共通認識を深めるビジネスオブザーバビリティ
Bizサイドが関心を持つのは、「サービス停止時間」そのものではなく、それがもたらす「機会損失額」や「顧客離れのリスク」といった具体的なビジネス影響です。
そのため、許容される不具合の範囲をBizサイドと合意するには、Devサイドが観測する指標(例:サービス停止時間、致命的エラーの発生期間、応答遅延の発生状況など)を単なる数値として提示するだけでは不十分で、それらを「機会損失額」や「登録者の減少数」などのBiz視点で理解しやすい形に翻訳して共有する工夫が求められます。
こうした取り組みを可能にするには、DevとBizそれぞれが重視する指標のオブザーバビリティ(可観測性)を高め、両者の視点を結びつける仕組みが重要です。
これを実現する鍵となるのが、「ビジネスオブザーバビリティ」 です。
ビジネスオブザーバビリティについては次の記事がとても参考になります。
▼参考記事▼
こちらの記事ではビジネスオブザーバビリティを以下のように解説しています。
ビジネスオブザーバビリティとは?
オブザーバビリティ予測レポート(2023年版)の調査によれば、実際に 発生したインシデントのビジネス影響やビジネス上のコンテキストを把握できている組織の割合はわずか27% という調査結果が出ており、依然として多くの現場でシステムとビジネスが分断している状況が伺えます。
そのような状況では、顧客価値を最大化し、収益向上につながるROIの高い意思決定はできません。

上記のような課題に対応するためには、システムのパフォーマンスと、業務プロセスやコストや収益などと関連付けて、それらの相互作用をリアルタイムに把握できる必要があります。
New Relicはそれを『ビジネスオブザーバビリティ』と呼んでいます。
ビジネスオブザーバビリティの実践
本記事では、Devサイドではすでにシステムの性能指標を詳細に計測し、BizサイドにSLOの合意を得ようとするレベルまでオブザーバビリティを確保している想定のため、Bizサイド向けのアプローチに焦点を当てます。
Bizの指標となるデータをNew Relicに蓄積する
Bizサイドが関心を持つ指標(例:売上、受注数、会員数、再生数など)はサービス内容に依存するため、標準のモニタリングでは自動収集されません。これらのデータをモニタリング対象にするには、システム側で必要なデータを カスタムメトリクス4 としてNew Relicに送信し、蓄積する仕組みを実装する必要があります。
データ送信の方法として、以下の2つが考えられます。
| タイミング | 実装方法 | 例 |
|---|---|---|
| リアルタイム | 既存システムのトランザクション内に送信処理を組み込む | 受注成立時にデバイス情報や売上データを即時送信 |
| 定期実行 | データ集計と送信処理を作成し、New Relic Flex5やスケジューラー(cron, EventBridgeなど)を介して定期送信する | リアルタイム送信が難しいデータや、定期的な可視化で十分なデータ |
これらの方法を組み合わせることで、Bizサイドの主要指標を効率的にNew Relicへ蓄積させることができます。
蓄積されたデータを活用する
New Relicに蓄積されたDevとBizのデータを活用するには、以下の2つのアプローチを組み合わせると効果的です。
| アプローチ | 概要 | 特徴 |
|---|---|---|
| ビジネスダッシュボード | DevとBizそれぞれの指標を可視化し、相関性を分析するカスタムダッシュボードを作成する | 自由度が高いが工数がかかる。詳細な分析に最適 |
| New Relic Pathpoint | ビジネスプロセスの健全性を簡潔に可視化し、システムの問題が業務に与える影響を把握しやすくするツール | 簡単に開始でき、全体像の把握に向いている |
ビジネスダッシュボード
DevとBizが重視する指標を統合的に可視化するダッシュボードを構築し、それらの関連性を確認します。
このダッシュボードは、システムの性能指標(例:応答時間やエラー率)とビジネス指標(例:売上や注文数)の関係性を可視化し、パフォーマンスの変動がビジネスに与える影響を直感的に把握できるようにすることを目的としています。
表示項目例(ECサイト向けビジネスダッシュボード)
| カテゴリー | 内容 |
|---|---|
| Summary | 注文数、売上、エラーバジェット(売上目標の?% − 機会損失額)、主要データの概要表示(Billboard) |
| APM | トランザクションの処理時間推移(CUJごとのDuration)、エラーの推移(CUJ/メッセージごと) |
| Browser | Core Web Vitalsの推移(主要ページごと), エラーの推移(CUJ/メッセージごと) |
| Mobile | クラッシュ率推移 |
| ビジネス指標 | 受注件数推移、販路別売上推移(iOSアプリ/Androidアプリ/PC/スマホ) |
特に注目すべきは、エラーバジェットが単なる停止時間の指標ではなく、DevとBizが合意した売上目標の一部から不具合による機会損失額を引いた金額で表現されている点です。
ダッシュボードのさらなる活用テクニック
New Relic Change Tracking6の活用:デプロイの影響によるパフォーマンスの変化を追跡
NRQLのCOMPARE WITH句の活用:前日比や先週比のデータを可視化して機会損失を把握
Core Web Vitalsの長期データ保存:必要に応じてイベントをメトリクスに変換し、長期分析を可能に
▼参考記事▼
New Relic Pathpoint
New Relic Pathpointを利用すると、ユーザージャーニーごとに問題の発生箇所を視覚的に把握できます。
このツールは、ビジネス全体の健全性を俯瞰で捉えつつ、システム内の問題がどこで、どのように発生しているのか、そしてそれがビジネスKPIにどのような影響を与えているのかを迅速に把握するための優れたUIを提供してくれます。
▼参考記事 その1▼
以下は、参考記事より引用した紹介文と画面イメージです。
Pathpointのメイン画面

PathpointでビジネスKPIに影響を与えている原因を確認しているところ
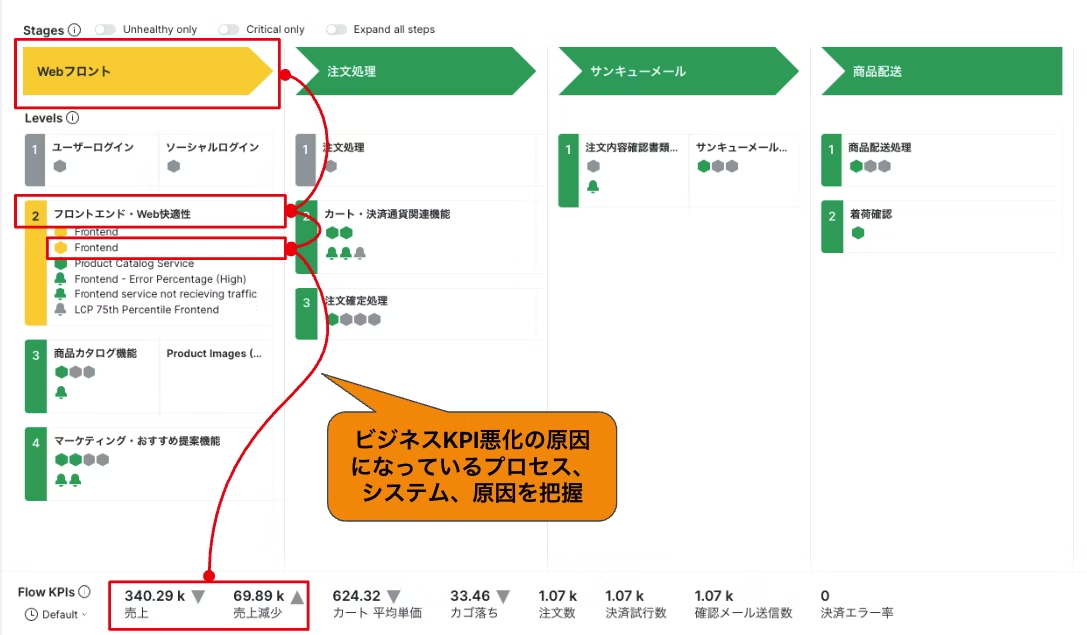
PathpointでビジネスKPIに影響を与えている原因をドリルダウンして追求しているところ
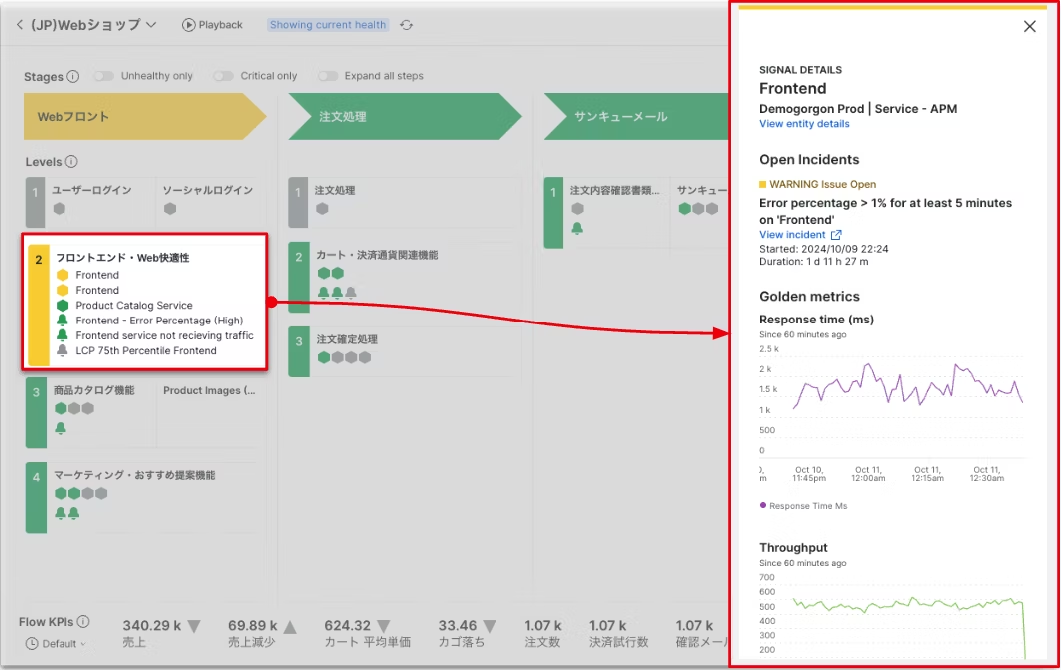
実際の画面を確認するとイメージが掴めるかと思います。
気になる方は、以下の参考記事で詳細を確認し、ぜひ実践してみましょう!
▼参考記事 その2▼
まとめ
いかがでしたでしょうか?
システム性能指標とビジネス成果指標を関連づけたビジネスオブザーバビリティを活用することで、以下の2つの成果が期待できます。
SLOの理解と合意に向けた精度向上
技術指標(例:サービス停止時間やレスポンスタイム)は、Bizサイドにとって理解しづらいことがありますが、これらを機会損失の金銭的価値などで可視化することで、SLOの理解や合意をよりスムーズに進められる可能性があります。
さらに、エラー率や応答時間の変動が売上や顧客満足度に与える影響を把握することで、DevとBiz間の効果的なコミュニケーションを促進し、優先順位の設定や迅速な意思決定を支援することができるでしょう。
ビジネスインパクトの可視化とデータ駆動の意思決定支援
システム性能の変化がビジネスに与える影響を可視化することで、たとえば「性能改善にリソースを投入すべきか」といった意思決定を、より具体的なデータに基づいて行う助けになるでしょう。
これにより、技術負債の解消や性能維持の重要性を共有し、効果的なシステム投資を支える経営判断の促進が期待されます。
以上、New Relicでビジネスオブザーバビリティを向上させて、DevとBizの共通理解を深めていきましょう!
ちょっとだけ宣伝
NRUG SRE支部本 好評発売中です♪
-
SLO(Service Level Objective)=ユーザー満足度を示す指標に対して集計期間と目標値を割合で定めたサービスレベル目標のこと(例:サービスの稼働率が1ヶ月で99%以上 など) ↩
-
エラーバジェット=100%-SLOで割り出せる、許容される不具合の量のこと ↩
-
カスタムメトリクス:New Relic APIを経由して、New Relicに自動的に追跡されないデータを任意のメトリクスとして記録させる機能のこと 参考:カスタムメトリック(APM、ブラウザ、モバイル)を収集する ↩
-
New Relic Flex:New Relic Infrastructureエージェントを介してノーコードもしくはローコードでNew Relicにカスタムメトリクスを送信できる機能のこと 参考:New Relic Flexのドキュメント ↩
-
New Relic Change Tracking:デプロイなどの最近の変更がエンドユーザーに与える影響を確認できる変更追跡機能のこと 参考:New Relic での変更を表示および分析する方法 ↩