はじめに
はじめまして。株式会社キカガクの河原です。
キカガクは、「AI を含めた先端技術の研修」を行っている会社です。
さっそくですが、CNN の構造ってどのように決めるのか、難しいと感じた方も多いのではないでしょうか。
- フィルタのサイズは、なぜ $3\times3$ が多いのか
- Convolution と Pooling は何回繰り返したらいいのか
- Convolution を何度も繰り返すと、計算量膨大になるのでは
みなさん、様々な疑問を抱いてるかと思います。
私自身、学び初めの頃は、どのように CNN のアーキテクチャを構成すればいいのか、理解出来ずにいました。
そこで、CNN の過去のモデルから紐解いて学ぶ事によって、上記の疑問が解消された背景から、本記事を書いていきます。
本記事を通して、皆様の抱いていた疑問が少しでも解消されれば幸いです。
本記事を参考にして欲しい方
- ニューラルネットワークの基礎、CNN の基礎を学んだことがある方
- 有名なモデルのアーキテクチャを学び CNN の理解を深めたい方
目次
- イントロダクション
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- まとめ
1. イントロダクション
これから、AlexNet と呼ばれるモデルが登場するきっかけとなった、ILSVRC (ImageNet Large Scale Visual Recognition Challenge) と呼ばれる大規模な画像認識コンテストについて紹介します。
ILSVRC では、ImageNet と呼ばれる、$256\times256$ の 100 万枚を超える画像を、1000 クラス分類にするデータセットが課題として使用されています。
余談ですが ImageNet では、下図のような画像が使用されており、私達でも、この画像をみて上手く分類できるのか難しいところです。

出典:ImageNet: A Large-Scale Hierarchical Image Database
2. AlexNet
先程紹介しました、ILSVRC における 2012 年優勝モデルが AlexNet です。
AlexNet が登場するまでは、 SVM やランダムフォレストなど、従来の機械学習の手法を用いて学習が行われていました。従来の手法では、正解率が約 70% ぐらいと続いており、精度の上昇が中々見受けられませんでした。
そんな中、ディープラーニングのモデルである AlexNet が登場し、これを境目に大きく精度が上がったという背景があります。
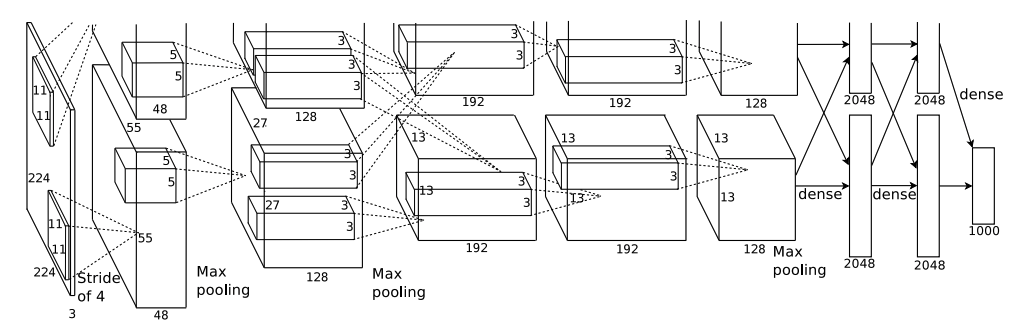
出典:ImageNet Classification with Deep Convolutional Neural Networks
それでは、本題の AlexNet のアーキテクチャについて見ていきましょう。
上記のアーキテクチャをみて難しいと感じるかもしれませんが、実はシンプルです。ここでは、重要なポイントだけに絞って解説していきます。
AlexNet のアーキテクチャを見ていただくと、 $224\times224$ の画像に対し、 $11\times11, \ 5\times5, \ 3\times3$ の畳み込みや、 MaxPooling=3, stride=4 などで構成されています。最終的には、ニューラルネットワークで扱えるベクトルに変換し 1000 クラス分類を行ってます。
ここまで聞くと難しいと感じるかもしれませんが、 一旦は、CNN の層をシンプルに積み上げていったものと思っていただければ大丈夫です。
【ポイント】
- k_size, padding, stride などに規則性がない
- ReLU 関数の利用 -> 以前よりも、数倍高速に学習可能になった
- Dropout の利用 -> 過学習の抑制
- GPU の学習 -> 並列処理
上記のポイントについて下記に論文を載せてますが、自身でわからないことを調べて頂くと、より理解が深まると思うので実践してみて下さい。
引用:ImageNet Classification with Deep Convolutional Neural Networks
4. VGGNet
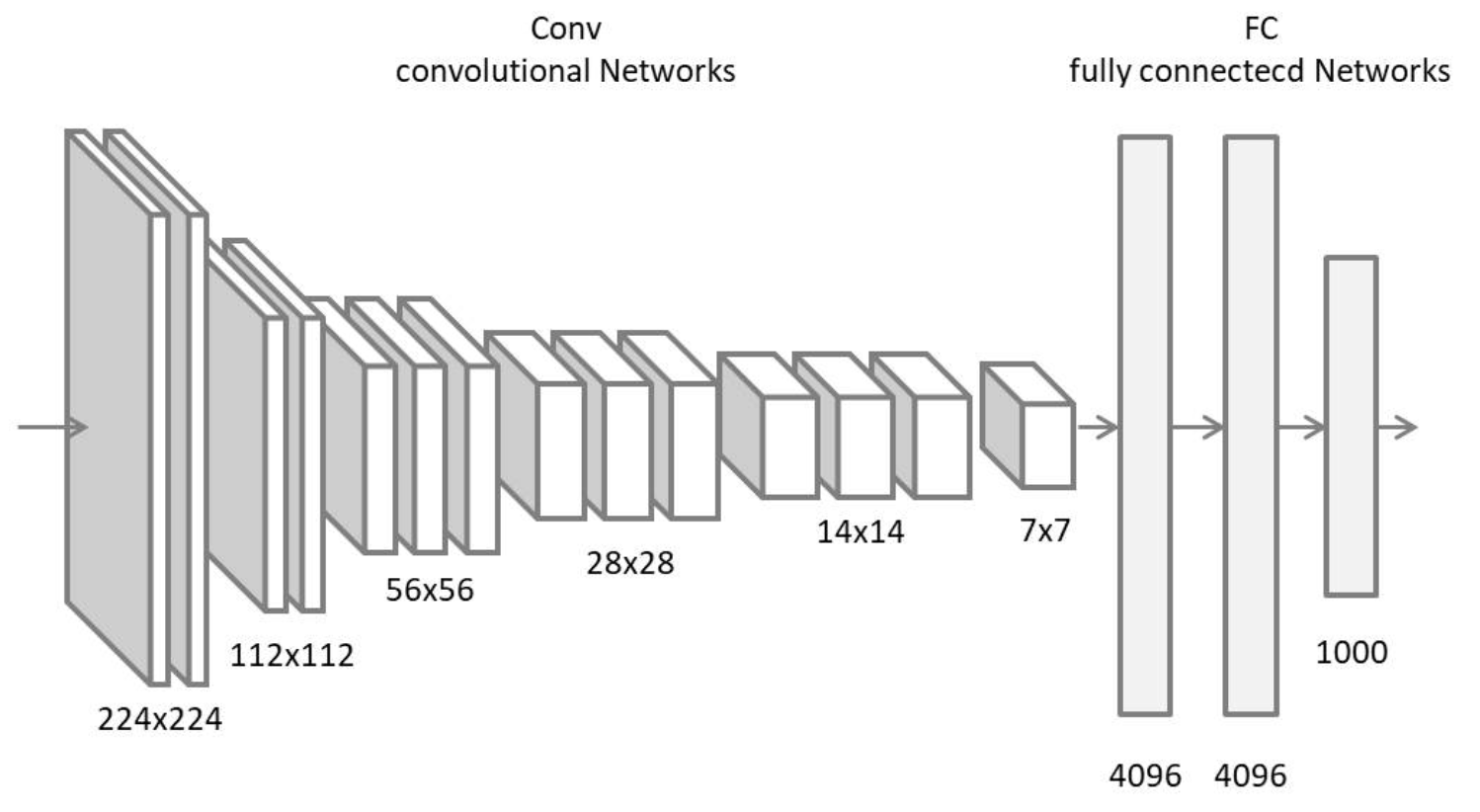
先程紹介した AlexNet は、精度の向上に大きく貢献しました。
しかし、カーネルサイズなどに規則性がなく、汎用性が低いモデルになってしまうという懸念点がありました。
それを改善すべく、出てきたのが VGGNet です。
VGGNet は 2014 年の ILSVRC で 2 位になったモデルです。
1 位ではないのですが、シンプルな構造で出来ているということから、一躍有名になったモデルです。
これまでの研究では、ネットワークを深くすれば、精度が向上すると考えられていました。
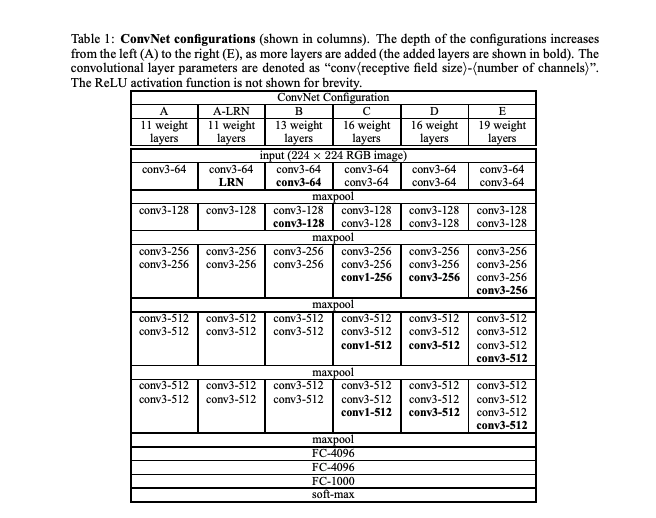
この考えから、VGGNet では、$3\times3$ のフィルタを採用した結果、16-19 層まで深くすることに成功し、精度の向上と、パラメータ数も削減出来ました。
【特徴】
- $3\times3$ フィルタのみを使用 ( $1\times1$ も一部使用)
- 同一チャネルに、複数の畳み込み層と MaxPooling を 1 セットとし繰り返す
-
MaxPooling 後の出力チャネル数を 2 倍にする
出典:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
フィルタの値によって、どれくらいパラメータを削減できるのか解説します。
- $7\times7$ での畳み込みを 1 回行う場合
- $3\times3$ での畳み込みを 3 回繰り返す場合
こちら、同じサイズの特徴マップを出力されます。
下図で比較すると分かりやすく、両者同じサイズになっていることを確認できます。
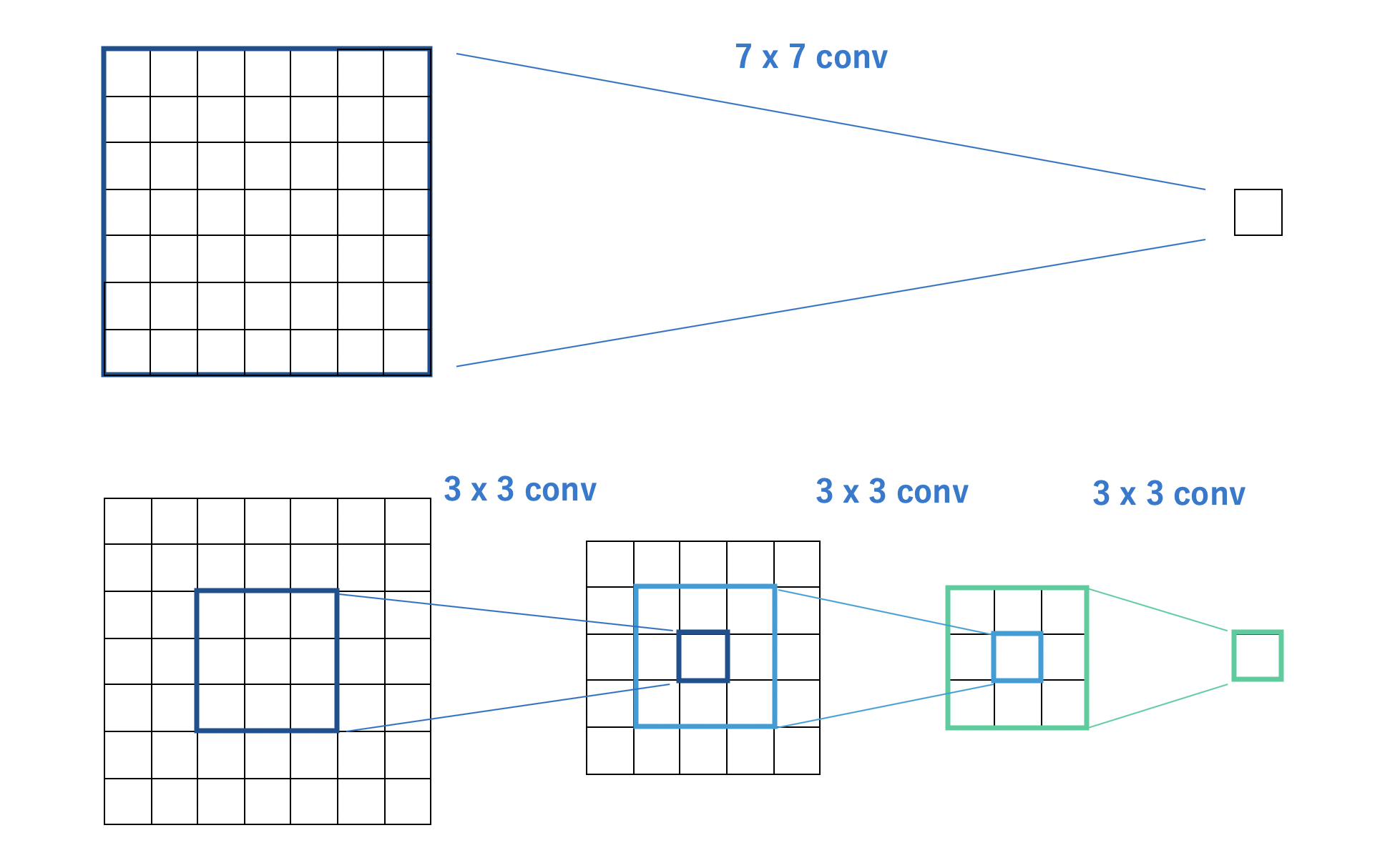
次に、どの程度パラメータを削減できるのか、計算式を用いて見ていきましょう。
【下記の条件の場合】
- 入力の特徴マップのチャネル数が 16
- 出力の特徴マップのチャネル数が 32
- バイアスは考慮しない
$7\times7$ の畳み込みを 1 回行う場合
$$7\times7\times16\times32=25,088$$
$3\times3$ の畳み込みを 3 回行う場合
【追加条件】
- ストライド 1
- パディングなし
- 1 層目チャネル数: 16->16
- 2 層目チャネル数: 16->16
- 3 層目チャネル数: 16->32
$$3\times3\times16\times16\times2 + 3\times3\times16\times32 = 9,216$$
となり、同じ範囲を半分程度のパラメータ数で確認できます。
このように、 $3\times3$ を用いると、パラメータ数が削減できただけでなく、精度の向上も確認できたため、ここから CNN のモデルは $3\times3$ をフィルタサイズの中心として研究されることになりました。
5. GoogLeNet
GoogLeNet は、2014 年の ILSVRC で優勝したモデルです。
このアーキテクチャのポイントは、ネットワーク内部の計算効率の改善にあります。
下図が GoogLeNet のアーキテクチャです。
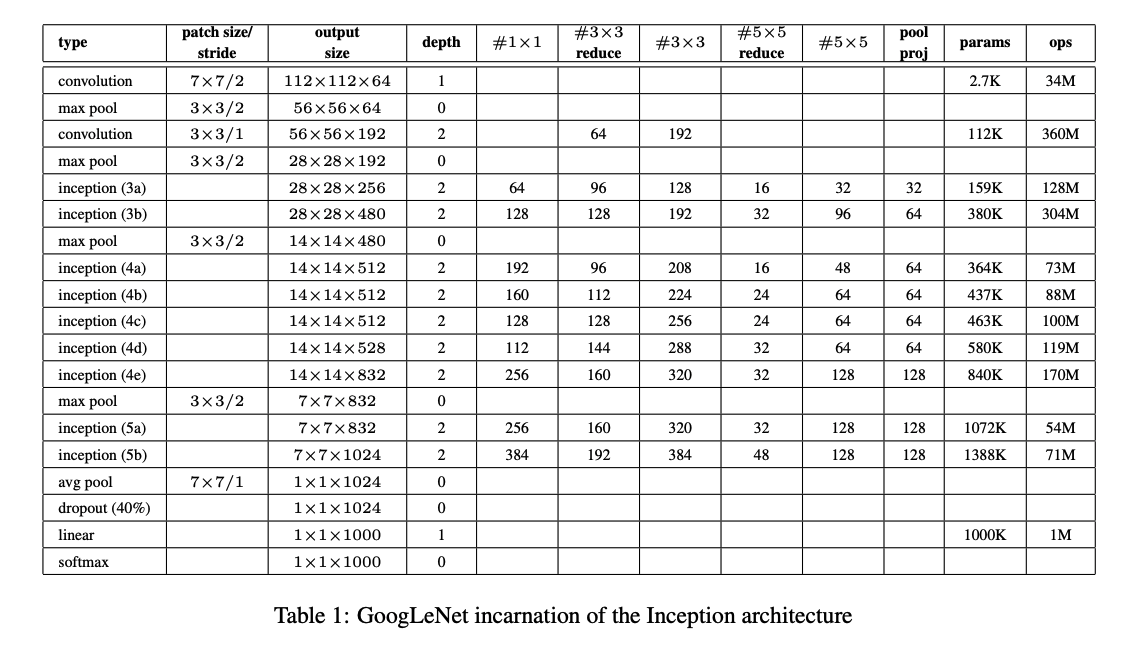
出典:Going deeper with convolutions
【ポイント】
- Inception モジュール
- Global Average Pooling (GAP)
- Auxiliary Loss -> 勾配消失を防ぐため
Inception モジュール
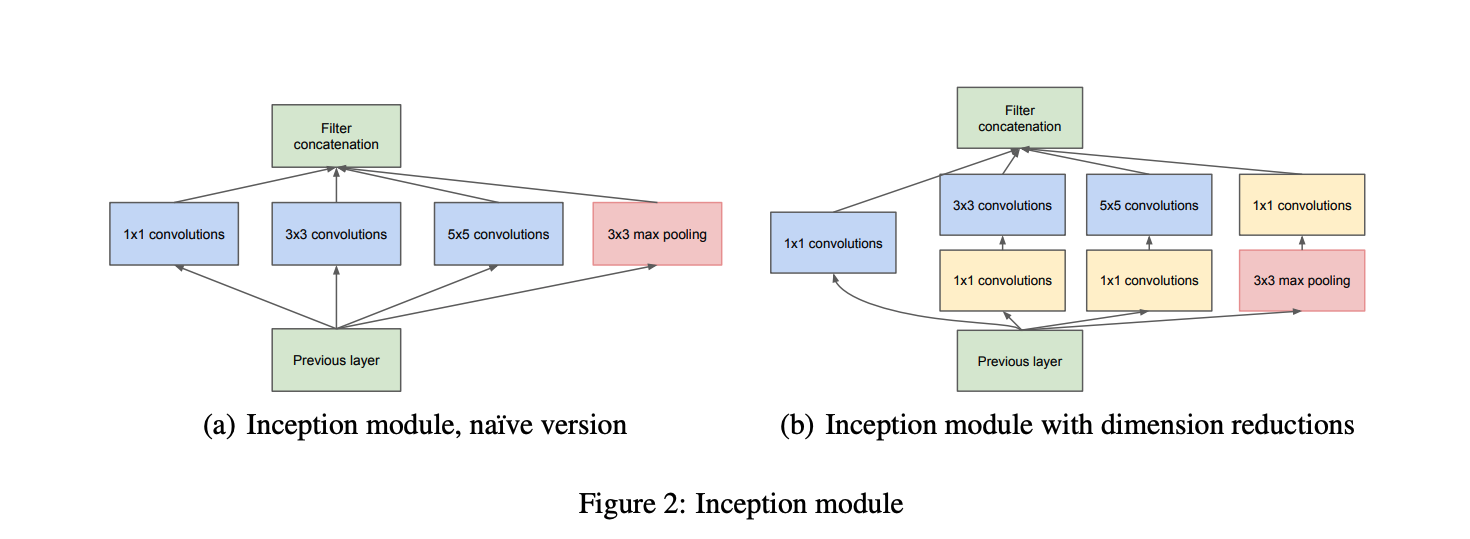
出典:Going deeper with convolutions
上図を見て頂くと、今までのアーキテクチャとは違って、難しいと感じるかもしれません。
しかし、こちらも行ってることはシンプルです。
【目的】
- パラメータの削減
- 表現力の維持
Inception モジュールでは、複数のネットワークを 1 つにまとめ、モジュールを積み重ねる、Network In Network の構成になっています。
そして、Inception モジュールの内部では、上図 (a) のように、異なるフィルタサイズの複数の畳み込み層を同時に通して、結合する処理が行われます。
これは、パラメータ数を削減して計算コストを下げつつ、複雑なアーキテクチャを組むための工夫になります。
先程、複数のネットワークを 1 つにまとめ、モジュールを積み重ねる、Network In Network の構成と説明しましたが、こちらを用いると、どの程度パラメータを削減できるのか見ていきましょう。
【下記の条件の場合】
- 入力の特徴マップのチャネル数が 192
- 出力の特徴マップのチャネル数が 96
$5\times5$ の畳み込み層の場合
$$
\begin{array}{c}
5 \times 5 \times 192 \times 96 = 460,800
\end{array}
$$
一方で、下図の(a) の Inception モジュールを使用した場合、下記となり
$$
\begin{split}\begin{array}{c}
&(1 \times 1 \times 192 \times 24)\\
&+ (3 \times 3 \times 192 \times 24)\\
&+ ( 5 \times 5 \times 192 \times 24)\\
&= 161,280
\end{array}\end{split}
$$
パラメータの数を大きく削減できることがわかります。
出典:Going deeper with convolutions
Inception モジュールは、さらにチャネル方向の次元削減も考慮したパターンも提案されており、上図の (b) がその構成になります。
こちらを見て頂くと、$3×3$ や $5×5$ の畳み込み層の前に $1×1$ の畳み込み層を重ねています。
このように、$1×1$ の畳み込み層を通して一度チャネル数を減らしてから、より計算コストのかかる $3×3$ や $5×5$ の畳み込み層に通すことで、全体のパラメータ数を減らす考え方になります。
こちらも、どの程度パラメータを削減できるのか見ていきましょう。
【下記の条件の場合】
- 入力の特徴マップのチャネル数が 192
- 中間 (1×1 畳み込み層を通した後 ) の特徴マップのチャネル数が 16
- 出力の特徴マップのチャネル数が 96
$$
\begin{split}\begin{aligned}
&(1 \times 1 \times 192 \times 24) \\
&+ (1 \times 1 \times 192 \times 16) + (3 \times 3 \times 16 \times 24) \\
&+ (1 \times 1 \times 192 \times 16) + (5 \times 5 \times 16 \times 24) \\
&+ (1 \times 1 \times 192 \times 24) \\
&= 28,416
\end{aligned}\end{split}
$$
上記の計算結果から、(a) のパターンでは、パラメータ数が、161,280 だったので、大きくパラメータ数を削減できたことが確認できました。
Global Average Pooling (GAP)
2 つ目のポイントは、 Global Average Pooling (GAP) の導入です。
こちらは、CNN で抽出した特徴マップを、全結合層へつなぐ際に用いられます。
これまでに、CNN を学んだ方は Flatten という処理をご存知かと思います。
Flatten とは、テンソルと呼ばれる形から、全結合層で扱える形であるベクトルに直す際に用いられていました。
しかし、パラメータの数が膨大になってしまうといったデメリットも出てきます。
そこで、GAP では、下図のように各チャネルごとの平均値を特徴マップごとに 1 つの値を渡すため、パラメータ削減することができます。
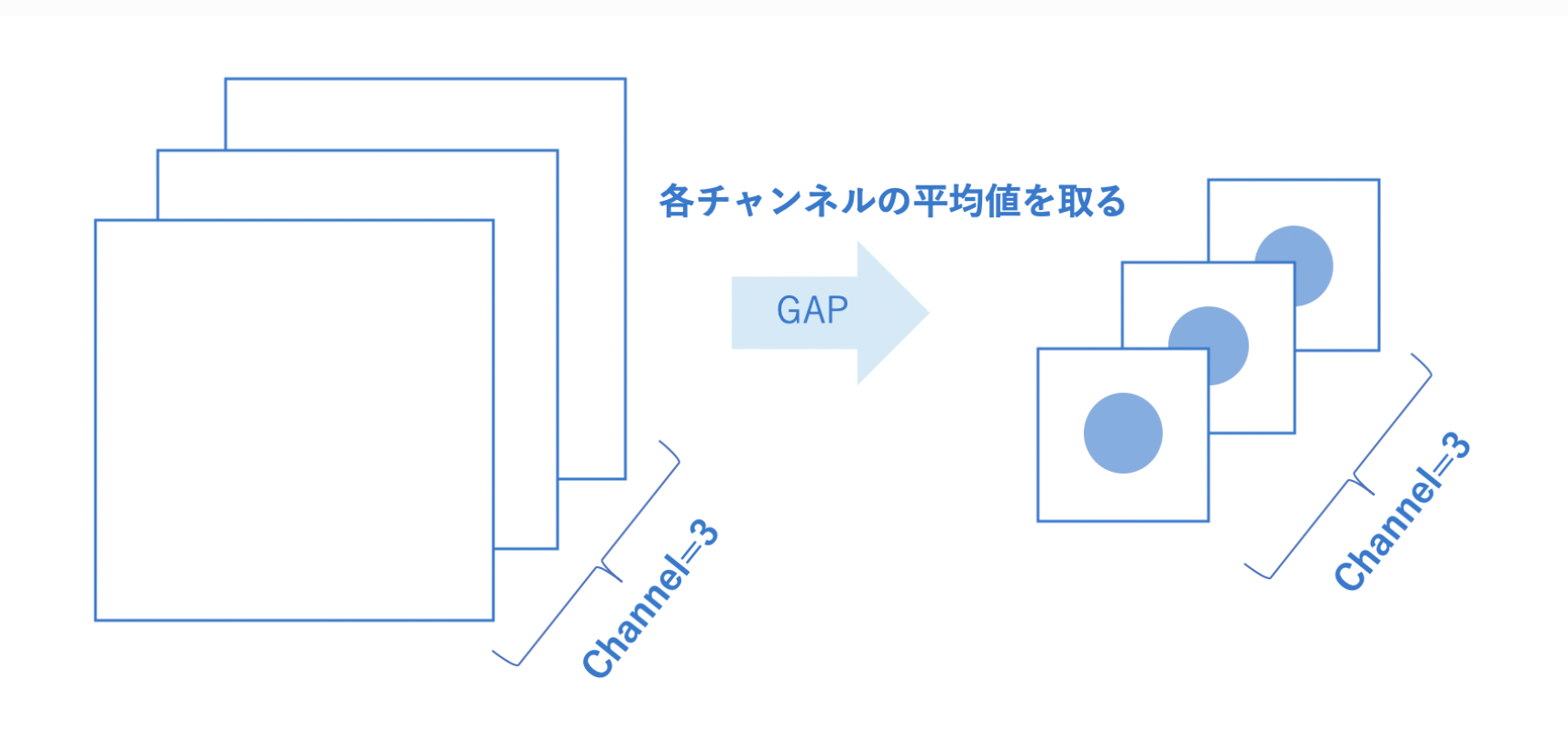
最終層の特徴マップのサイズが $7×7×512$ であった場合、Flatten を用いると、$7×7×512=25,088$ となります。
そこで、Global Average Pooling (GAP) を用いると、特徴マップのチャネルごとの平均値を出力してくれるので、512 ベクトルとなり、1/49 のパラメータ削減になることが分かります。
6. ResNet
ResNet (Residual Networks) は、2015 年の ILSVRC で優勝したモデルです。
VGGNet で示されたように、ネットワークを深くすることは表現能力を向上させ、精度を向上させました。
しかし、あまりにも深いネットワークは、逆伝播の際に勾配消失問題が起こっていました。
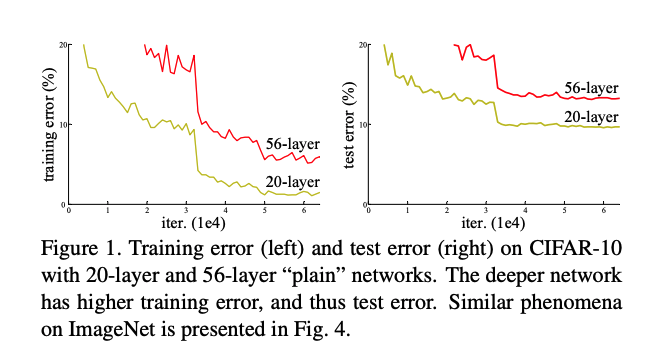
出典:Deep Residual Learning for Image Recognition
この問題を解決すべく、出てきたのが ResNet になります。
どのように解決したのか、簡単にポイントを解説します。
【ポイント】
- Residual モジュール
- Bottleneck モジュール
- He の初期化
- Batch Normalization
- 様々なバリエーション
Residual モジュール
ResNet の特徴は、名前の由来にもなっている Residual モジュールを採用している点です。
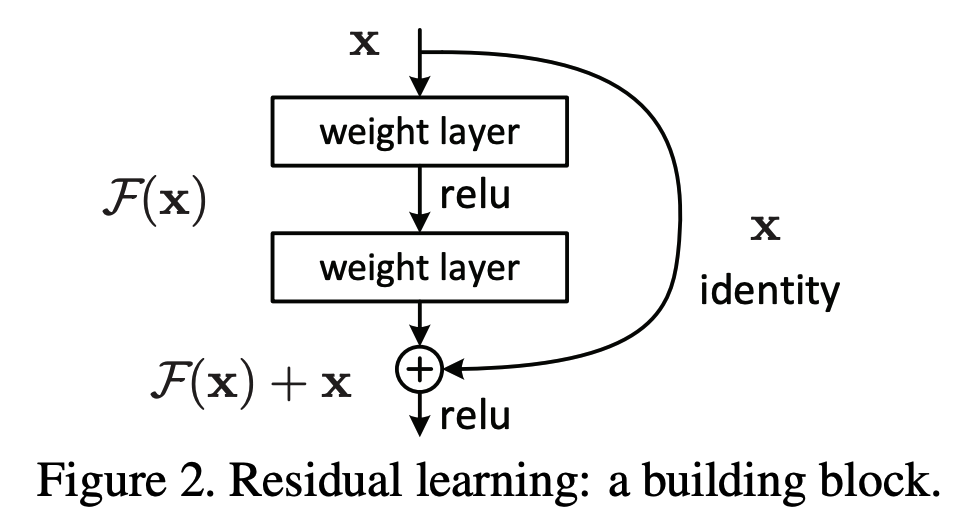
出典:Deep Residual Learning for Image Recognition
仕組みとしては、畳み込み層への入力を分岐させ、1 層先の畳み込み層の出力と結合させます。
こうすることで、逆伝播の際に微分を行うと、通常に加えて 1 増えます。
$$\frac{d}{d x}(f(x) + x) = \frac{d}{d x}f(x) + 1$$
このように、学習したい関数との差 (residual) を学習させることで勾配消失を回避しています。
これにより、勾配消失を防いで層を深くすることが可能となりました。
Bottleneck モジュール
Residual モジュールに、$1\times1$ の畳み込みを加えてパラメータを削減し、より効率的に学習を行えるモジュールも提案されました。
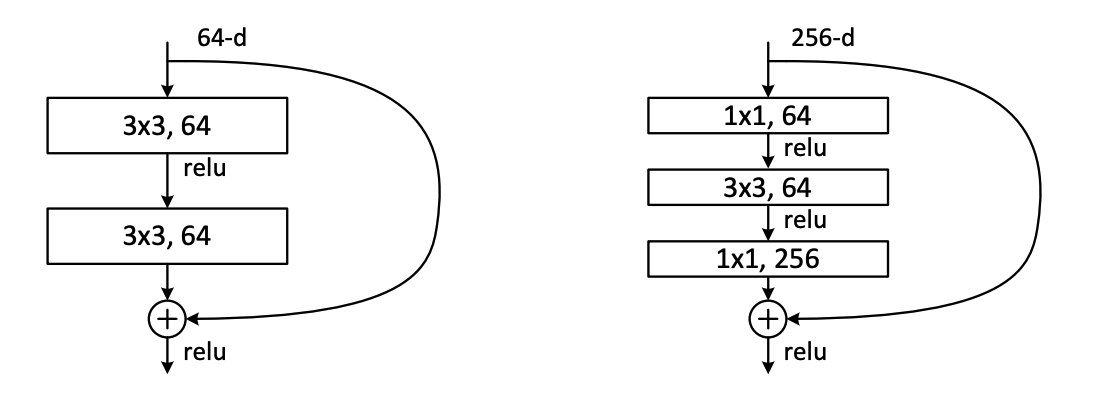
出典:Deep Residual Learning for Image Recognition
こちらは、$1\times1$ でチャネル数が小さくなった後、元の大きさに戻って出ていく様が、ボトルネックの形状と似ていることから、Bottleneck モジュールとも呼ばれます。
次元削減のイメージに関しては、Inception モジュールを参考にしてみて下さい。
He の初期化
活性化関数に ReLU を用いる際の、最適な重みの初期値もここで提案されました。
これまでは、初期値をランダムに決めて SGD (最適化手法) などでパラメータを修正していました。
He の初期化では、ランダムではなく、重みの初期値を平均 0、標準偏差 $\sqrt{\frac{2}{n}}$ の正規分布から生成します。
Batch Normalization
Batch Normalization を行うことで、内部共変量シフトを軽減しました。
内部共変量シフトというのは、パラメータの更新によって、次の層への入力の分布がバッチ毎に大きく変化し分布が変わってしまうという問題です。これにより、学習が効率的に進まない問題がありました。
その分布を極力変えずに学習を行うのが、 Batch Normalization になります。これにより、学習を安定化・高速化されました。
様々なバリエーション
ResNet では、152 層まで深くしたアーキテクチャが提案されています。
これまでに紹介したモデルに比べると、大幅に層を深くすることに成功しています。
各バリエーションの構成は以下の通りです。
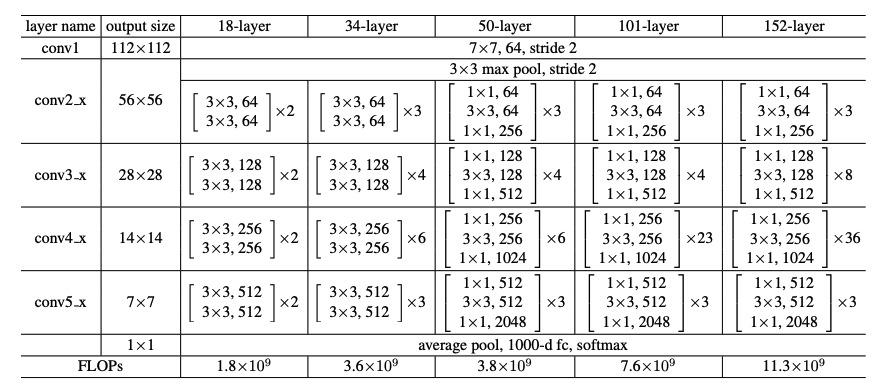
出典:Deep Residual Learning for Image Recognition
7. まとめ
ここまで読んで、みなさんの感じていた CNN の疑問について、少しは解消されましたでしょうか。
$3\times3$ のフィルタがよく利用されている背景
どのように、パラメータを削減するのかなど、有名なモデルから学べることはたくさんあります。
また、その他の有名なモデルからも学べることはたくさんありますので、興味を持った方は学習してみて下さい。
本記事を通して、少しでもディープラーニングへの興味、 CNN の構造の理解が深まれば幸いです。
お知らせ

動画を通じて、ディープラーニングが一から学習できる大人気コースの脱ブラックボックスが無料になりました。
手書きの数学とハンズオン形式のプログラミングによって、初学者でも安心して一から学習できます。
機械学習やディープラーニングを基礎から実践を学びたい方は、ぜひ教材の1つとしてご利用ください!