TR;DR
以下のコマンドで ClickHouse をインストールあるいは Docker から実行できます
# Install
curl https://clickhouse.com/ | sh
clickhouse local -m
# From Docker
docker run --volume=$HOME:$HOME -it clickhouse/clickhouse-server:latest clickhouse-local -m
-m は multiline(改行即 Query 実行では無い)のオプション。
curl -O https://media.githubusercontent.com/media/datablist/sample-csv-files/main/files/customers/customers-100000.csv
head -n3 customers-100000.csv
Index,Customer Id,First Name,Last Name,Company,City,Country,Phone 1,Phone 2,Email,Subscription Date,Website
1,ffeCAb7AbcB0f07,Jared,Jarvis,Sanchez-Fletcher,Hatfieldshire,Eritrea,274.188.8773x41185,001-215-760-4642x969,gabriellehartman@benjamin.com,2021-11-11,https://www.mccarthy.info/
2,b687FfC4F1600eC,Marie,Malone,Mckay PLC,Robertsonburgh,Botswana,283-236-9529,(189)129-8356x63741,kstafford@sexton.com,2021-05-14,http://www.reynolds.com/
% clickhouse local -m
localhost :) from `customers-100000.csv` select * order by Index limit 3;
SELECT *
FROM `customers-100000.csv`
ORDER BY Index ASC
LIMIT 3
Query id: 49a58a45-3ade-4681-abf2-7455618f1a2b
┌─Index─┬─Customer Id─────┬─First Name─┬─Last Name─┬─Company──────────┬─City───────────┬─Country──┬─Phone 1────────────┬─Phone 2──────────────┬─Email─────────────────────────┬─Subscription Date─┬─Website────────────────────┐
│ 1 │ ffeCAb7AbcB0f07 │ Jared │ Jarvis │ Sanchez-Fletcher │ Hatfieldshire │ Eritrea │ 274.188.8773x41185 │ 001-215-760-4642x969 │ gabriellehartman@benjamin.com │ 2021-11-11 │ https://www.mccarthy.info/ │
│ 2 │ b687FfC4F1600eC │ Marie │ Malone │ Mckay PLC │ Robertsonburgh │ Botswana │ 283-236-9529 │ (189)129-8356x63741 │ kstafford@sexton.com │ 2021-05-14 │ http://www.reynolds.com/ │
│ 3 │ 9FF9ACbc69dcF9c │ Elijah │ Barrera │ Marks and Sons │ Kimbury │ Barbados │ 8252703789 │ 459-916-7241x0909 │ jeanettecross@brown.com │ 2021-03-17 │ https://neal.com/ │
└───────┴─────────────────┴────────────┴───────────┴──────────────────┴────────────────┴──────────┴────────────────────┴──────────────────────┴───────────────────────────────┴───────────────────┴────────────────────────────┘
3 rows in set. Elapsed: 0.085 sec.
localhost :) from `customers-100000.csv` as customers select customers.City, COUNT(*) group by 1 order by 2 desc limit 10;
SELECT
customers.City,
COUNT(*)
FROM `customers-100000.csv` AS customers
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10
Query id: bdc2f067-64b0-49fc-af8e-b62b32fc4c8c
┌─City────────────┬─count()─┐
│ Lake Frederick │ 16 │
│ West Alec │ 15 │
│ New Christopher │ 15 │
│ East Jeremy │ 15 │
│ East Lee │ 15 │
│ New Wayne │ 14 │
│ Lake Alexander │ 14 │
│ West Bailey │ 14 │
│ Port Brandy │ 13 │
│ West Carla │ 13 │
└─────────────────┴─────────┘
10 rows in set. Elapsed: 0.086 sec.
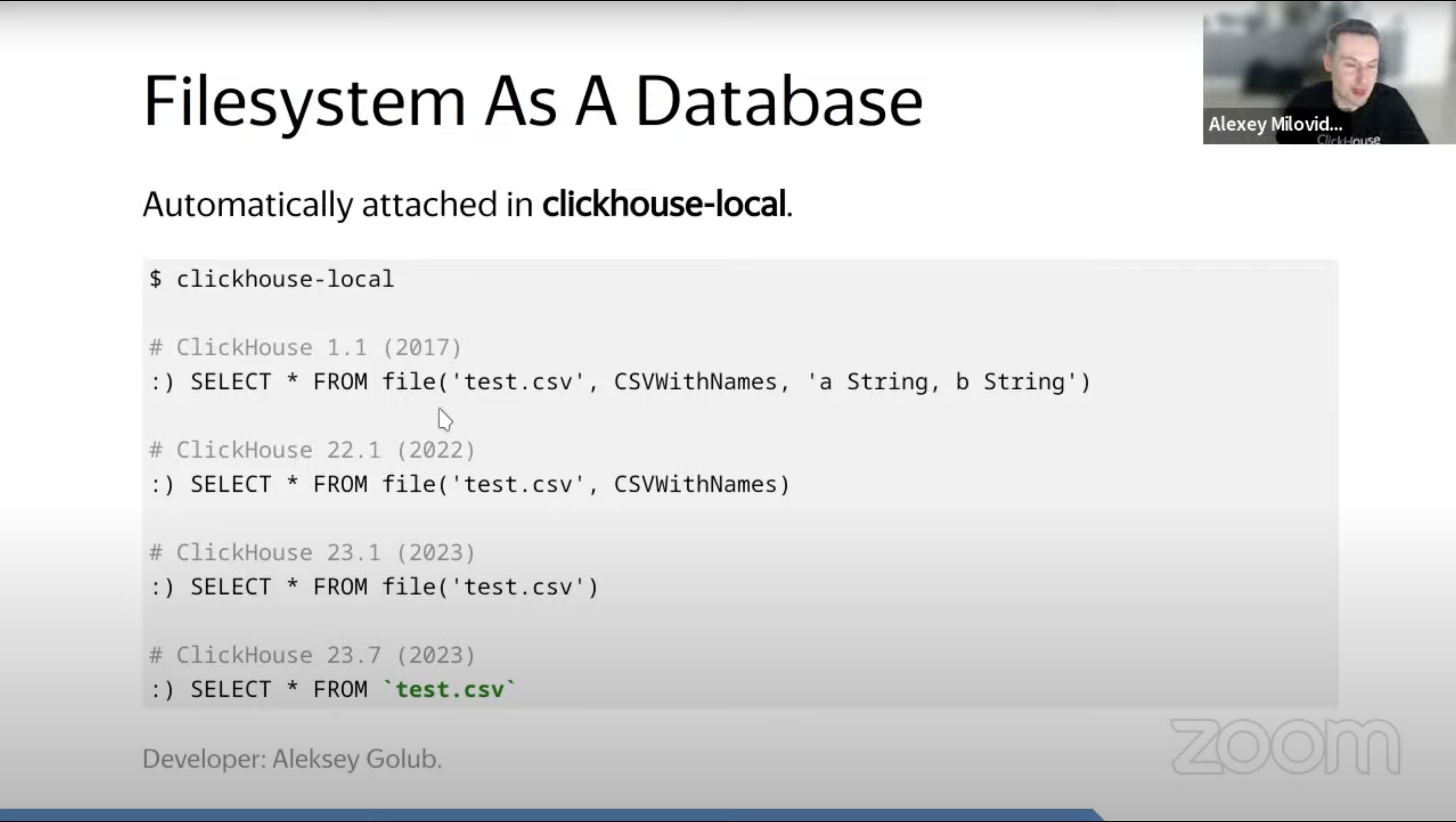
Note:
- ClickHouse では、
`filename`でファイルをテーブルとして読み込める。.csv,.tsv,.orc,.parquet等に対応しており、1行目がヘッダー like であれば、Header として読み取られる。-
`filename`記法はfile('file_name')の略、 -
https://www.youtube.com/live/TI1kONfON18?feature=share&t=3219\
- See Formats for Input and Output Data for all supported format.
-
- ClickHouse (他の DB もいくつか)は、
SELECT/FROMの順番を交換して書くFROM ~ SELECT ~記法に対応している。
始めに
データ分析・キャンペーンの抽出作業・障害対応等に取り組んでいると、大量のCSVやTSVファイルを処理したり、既に抽出済のデータに対してちょっとした集計や JOIN を行いたいという経験があると思います。
これらのタスクは、データが データベースに入っていて、SQL で実行できれば楽なもののです。しかし既にデータが SQL として手元にある場合、そのためにわざわざ手元で DB を立ち上げて Import しなおすほどではなく、久しぶりに man join して思い出しながらコマンドラインオプションと戦ったり、意を決して Excel で VLOOKUP する場合が多いと思います。
しかし現在、CSV に対して、SQL で Query を実行できるツールが多くあります。
特に、『SQL のような独自言語』、ではなく SQL を基本的にカバーし、更に追加の分析関数をサポートしているものがあります。
例えば以下のようなものです。
-
ClickHouse-local: ClickHouseのコマンドラインツールで、データベースサーバを立ち上げることなく、ローカルのCSVやTSVファイルに対してSQLを使ってデータ処理を行うことができる。
-
DuckDB: 分析ワークロードに最適化されたオープンソースの列指向データベース管理システム(DBMS)。Pythonデータ構造と簡単に連携することができ、
-
SQLite: ローカルのデータベース操作に非常に一般的に使用される軽量DBMS。(軽量だが、簡易というわけではなく、昨今のスマートフォンアプリを支える重要なパーツの一つ)
また、SQL そのものでは無いですが、Pands, Dask といった Python Library も、CSV を取りこんで簡単な集計を行う、ということを行う事が出来ます。
上記3つの中でも、ここでは ClickHouse をローカルモードで動かす clickhouse local を紹介します。
データベースサーバを立ち上げることなく、ローカルのCSVやTSVファイルに直接SQLを使ってデータ処理を行うことができます。
Start clickhouse local
Docker で起動するのが楽だと思います。Mac / Linux であれば以下のコマンドで、Docker Container 内からも home directory が見える状態で clickhouse-local が起動します。
docker run --volume=$HOME:$HOME -it clickhouse/clickhouse-server:latest clickhouse-local -m
ClickHouse にはインストール用の oneliner があるため、実マシンにインストールするのも楽です。
(結果を書き出すことが多い場合にはオススメ)
curl https://clickhouse.com/ | sh
clickhouse local -m
ClickHouse local version 23.7.1.2471 (official build).
localhost :)
File の JOIN
こんな二つのファイルがあったとき
% cat /tmp/transaction.csv
transaction_id,item_id,amount,updated_at
1,A,1,2023-07-29 00:00:00
2,B,1,2023-07-30 00:00:00
3,A,2,2023-07-30 00:00:00
% cat /tmp/master.csv
rownum,item_id,item_name
1,A,セーター
2,B,ジーンズ
3,C,C
この状態で、以下の SQL で JOIN できます。
SELECT *
FROM `/private/tmp/transaction.csv` AS transaction
LEFT JOIN `/private/tmp/master.csv` AS master USING (item_id)
localhost :) select * from `/private/tmp/transaction.csv` AS transaction left outer join `/private/tmp/master.csv` using (item_id);
SELECT *
FROM `/private/tmp/transaction.csv` AS transaction
LEFT JOIN `/private/tmp/master.csv` AS master USING (item_id)
Query id: e3629a3f-0742-49b0-9203-e4090c7080b8
┌─transaction_id─┬─item_id─┬─amount─┬────────────────────updated_at─┬─rownum─┬─item_name─┐
│ 1 │ A │ 1 │ 2023-07-29 00:00:00.000000000 │ 1 │ セーター │
│ 2 │ B │ 1 │ 2023-07-30 00:00:00.000000000 │ 2 │ ジーンズ │
│ 3 │ A │ 2 │ 2023-07-30 00:00:00.000000000 │ 1 │ セーター │
└────────────────┴─────────┴────────┴───────────────────────────────┴────────┴───────────┘
3 rows in set. Elapsed: 0.004 sec.
FROM を先に書く場合は以下
FROM `/private/tmp/transaction.csv` AS transaction
LEFT JOIN `/private/tmp/master.csv` AS master USING (item_id)
SELECT *;
実際には、何回も使う条件は WITH としても書いておけます。
WITH
transaction as (SELECT * FROM `/private/tmp/transaction.csv`),
master as (SELECT * FROM `/private/tmp/master.csv`)
SELECT *
FROM transaction
LEFT OUTER JOIN master USING(item_id);
localhost :) WITH
transaction as (SELECT * FROM `/private/tmp/transaction.csv`),
master as (SELECT * FROM `/private/tmp/master.csv`)
SELECT *
FROM transaction
LEFT OUTER JOIN master USING(item_id)
;
WITH
transaction AS
(
SELECT *
FROM `/private/tmp/transaction.csv`
),
master AS
(
SELECT *
FROM `/private/tmp/master.csv`
)
SELECT *
FROM transaction
LEFT JOIN master USING (item_id)
Query id: 9dc51727-53cb-4c57-b3e7-00d3c3a36587
┌─transaction_id─┬─item_id─┬─amount─┬────────────────────updated_at─┬─rownum─┬─item_name─┐
│ 1 │ A │ 1 │ 2023-07-29 00:00:00.000000000 │ 1 │ セーター │
│ 2 │ B │ 1 │ 2023-07-30 00:00:00.000000000 │ 2 │ ジーンズ │
│ 3 │ A │ 2 │ 2023-07-30 00:00:00.000000000 │ 1 │ セーター │
└────────────────┴─────────┴────────┴───────────────────────────────┴────────┴───────────┘
3 rows in set. Elapsed: 0.002 sec.
HowTo 100選
CSVWithNames の結果がおかしい
Scheme Inference の結果がおかしいからといって、file('file_name', 'CSVWithNames', 'col Int32') 等と指定すると、せっかく推論してくれた他のカラムも全て指定しなければならなくなる。
そのため、その代わりに schema_inference_hints 設定を利用する方が良い。
localhost :) describe file(`/tmp/master.csv`, 'CSVWithNames');
DESCRIBE TABLE file(`/tmp/master.csv`, 'CSVWithNames')
Query id: 9dddf4dd-b774-47a8-bb43-f3371c40c8cc
┌─name──────┬─type─────────────┬─default_type─┬─default_expression─┬─comment─┬─codec_expression─┬─ttl_expression─┐
│ item_id │ Nullable(String) │ │ │ │ │ │
│ item_name │ Nullable(String) │ │ │ │ │ │
└───────────┴──────────────────┴──────────────┴────────────────────┴─────────┴──────────────────┴────────────────┘
2 rows in set. Elapsed: 0.002 sec.
localhost :) describe file(`/tmp/master.csv`, 'CSVWithNames') SETTINGS schema_inference_hints = 'item_id LowCardinality(String)';
DESCRIBE TABLE file(`/tmp/master.csv`, 'CSVWithNames')
SETTINGS schema_inference_hints = 'item_id LowCardinality(String)'
Query id: a7482ad7-603c-4402-817c-4fa87094f52e
┌─name──────┬─type───────────────────┬─default_type─┬─default_expression─┬─comment─┬─codec_expression─┬─ttl_expression─┐
│ item_id │ LowCardinality(String) │ │ │ │ │ │
│ item_name │ Nullable(String) │ │ │ │ │ │
└───────────┴────────────────────────┴──────────────┴────────────────────┴─────────┴──────────────────┴────────────────┘
2 rows in set. Elapsed: 0.001 sec.
外部テーブルと JOIN したい
できる。
MySQL の "Database" (= Scheme) をまるっと参照することが出来る。
CREATE DATABASE my_mysql_server
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
とやると、ClickHouse 内で my_mysql_server.table_name で、リモート MySQL サーバーの table_name を参照出来る。あとは JOIN 句などで使える。
宗教上の理由で 時刻 Format は ISO8601 である必要がある。
Input: date_time_input_format を使う
SET date_time_input_format = 'best_effort'
Output: date_time_output_format を使う。
SET date_time_output_format = 'iso';