※この記事はモチベーションクラウドシリーズアドベントカレンダー2020 22日目の記事です。
はじめに
私は、日頃行っている業務の中で、
- システムバグによる機能不全
- サードパーティーの不具合による広影響のトラブル
- ヒューマンエラーによる大惨事
などの**「インシデント」**が発生した際に、慌てずに対応ができるよう、対応方針の型化を進めています。
この型化を進める中で、インシデント対応時に陥りやすい落とし穴と、対応の際に意識するべきポイントが見えてきたので、本稿ではその内容を共有したいと思います!
発生するとやはり慌ててしまうインシデントの対応において、少しでも被害縮小のための参考になれば嬉しいです。
また、ご意見・フィードバック大歓迎なので是非よろしくお願いします!
インシデント対応における「4つの落とし穴」
システム開発を行っていると、保守運用をどれだけ心がけていても、突然に発生してしまうのがインシデントだと思います。
そんなインシデントが発生した際に
「対応すればするほど、新たな問題を生み出してしまう…」
「焦るばかりで、何をどの順番で対応すれば良いか一向に見えない…」
といった悩みを経験したことがある方もいらっしゃるのではないでしょうか。
私自身も失敗を繰り返す中で上記のような悩みは経験してきましたが、その原因から、インシデント対応で陥りやすい**「4つの落とし穴」**が見えてきました。
1. 対応方針を決めないまま、各メンバーが闇雲に調査を行い、チームが混乱する
2. エンジニアの中で、調査結果を書く場所がバラバラで、情報が錯綜する
3. 1つの事実から影響範囲を矮小化してしまい、必要な調査が為されない
4. 対応に抜け漏れが発生し、関係者に不安を与える
インシデント対応における「4つの解決ポイント」
そんな**「4つの落とし穴」を回避するために、以下の「4つの解決ポイント」**を定めました。
1. 役割を明確化せよ
2. 情報を一元管理せよ
3. 事実を切り分けて原因究明せよ
4. 振り返り、テンプレート化せよ
上記を意識することで、インシデント対応への安定性が以前に比べ格段に増しました。
以下、それぞれについて詳しく説明します。
①役割を明確化せよ
焦れば焦るほど**「まず自分の手を動かしたくなる」**のがエンジニアの性でしょう。
その結果、インシデント対応を進める中で、気がつけば
- 「他の人と同じ対応をやっていた…」
- 「自分がやっている調査が何の為かわからない…」
- 「誰が何を調査してるのかわからない…」
といった具合でチームが混乱状態に陥ります。
そんな状況にならないため、発生を検知したら、まずは手を止めて、
- 全体の責任者/体制を決める
- 細かいタスクの担当者を決める
ここから始めることが大切です。
インシデント発生を検知したら、まずは全体責任者を決めます。
責任者は、インシデント解決に向けたTODOを洗い出し、担当するメンバーをアサインします。
関係者が出そろったら、全員でミーティングを実施し、TODOの詳細、進捗をすり合わせます。
このメンバー同士がお互い何を行っているかを十分にわかっている状態で、対応を進めていくことが、混乱を防ぐ重要なポイントでした。
②情報を一元管理せよ
インシデント対応において、それぞれのエンジニアが「重要だ」と感じるポイントは様々です。
例えば、インシデント対応の経験が多いエンジニアは、一旦お客様への被害を食い止めるための「暫定対応」が重要だと考える傾向がある一方、インシデント対応に慣れていないエンジニアは「恒久対応」が重要だと考える傾向があるように、私自身感じています。
その結果、開発組織内の各チームにおいて、自分達が重要だと感じる情報のみ蓄積される管理帳票をバラバラに持ってしまい、
- 「恒久対応策を考えたいのに、暫定対応でどんなことがされたのかわからない…」
- 「前に同じインシデント発生したけど、どんな再発防止策が取られているのかわからない…」
- 「エンジニアみんなが、なんかバラバラ動いてまとまりがない…」
といった**「情報の錯綜による対応の混乱」**が生じていました。
その状況を回避するため、今では
- インシデント対応に必要な情報は1つの管理帳票に全てまとめる
- インシデント対応の進捗を確認するためのミーティングを行う
ことを徹底しています。
実際に作成したインシデント管理帳票は、一部を抜粋すると以下のような感じです。

紹介したいポイントは沢山あるのですが、一つだけに絞ると、
「次回、対応進捗を確認するためのミーティングをいつやるのか」
を記載する部分を入れていることです。
シンプルなことですが、情報共有のための場を設けることは意外と関係者に忘れられがちだと感じています。
そのため、対応方針を決める初回のミーティング以降、進捗確認ミーティングを行う度に、アジェンダの最後で次回ミーティング日時を確認するようにしています。
その他、上記の帳票では「発生しているインシデントの重大度と緊急度の判断基準」や、③でも紹介する「原因究明に使えるフレームワーク」など、インシデント対応において必要な各々の情報を記載するシートを用意しています。
これにより、「この帳票さえあれば、インシデント対応で必要な情報が得られる」という認識がエンジニアの中に形成され、情報連携が以前よりもスムーズになりました。
③事実を切り分けて原因究明せよ
1つだけの事実から、影響範囲を矮小化し、調査をストップしてしまうことはよくあります。
特にインシデント対応に慣れていないメンバーのみで、調査を行う際によくある落とし穴の1つです。
- 「早くインシデントを解決しなければいけない」という焦り
- 「自分の使用環境で起こっている事実だけが正しい」という思い込み
から、本来の調査対象を見落としてしまうことがあります。
そういったことがないよう、抜けもれのない網羅的な原因調査をするためには、わかった事実を適切に切り分けて整理する必要があります。
弊社では、以下の4つの観点を**「IS / IS NOT」**に分けて整理しています。
(IS / IS NOT:問題を切り分けるためのフレームワーク)
- what:何(誰)が、どうした
- where:どこの(どれの)、どの部分
- when:いつの、どんな時
- extent:どれくらい、どんな傾向(パターン)
具体的には以下の写真のような感じです。
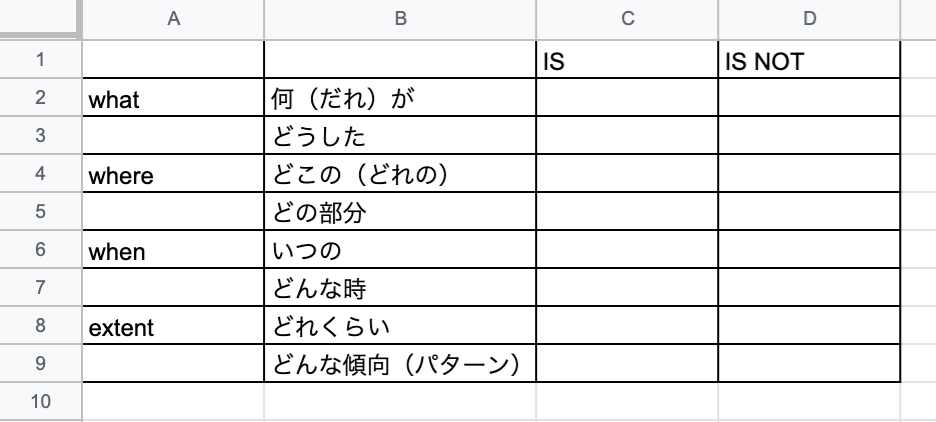
これは、②で述べた管理帳票にも組み込んであります。
このフレームワークにより、無意識に偏ってしまう思考が可視化され、調査もれが少なくなりました。
④振り返り、テンプレート化せよ
上記で説明した管理帳票も、初めから完璧な物を作るのは難しく、使っている内に様々な観点から改善ポイントが出てきます。
ただ、そのように各々の関係者が感じている改善ポイントも、伝えられるのを待っているだけでは、なかなか届いてこないのが実情かと思います。
そのため、インシデントへの一連の対応が完了した後は、対応に携わっていただいた開発や現場のメンバーに、
管理帳票に対するフィードバックをもらうようにしています。
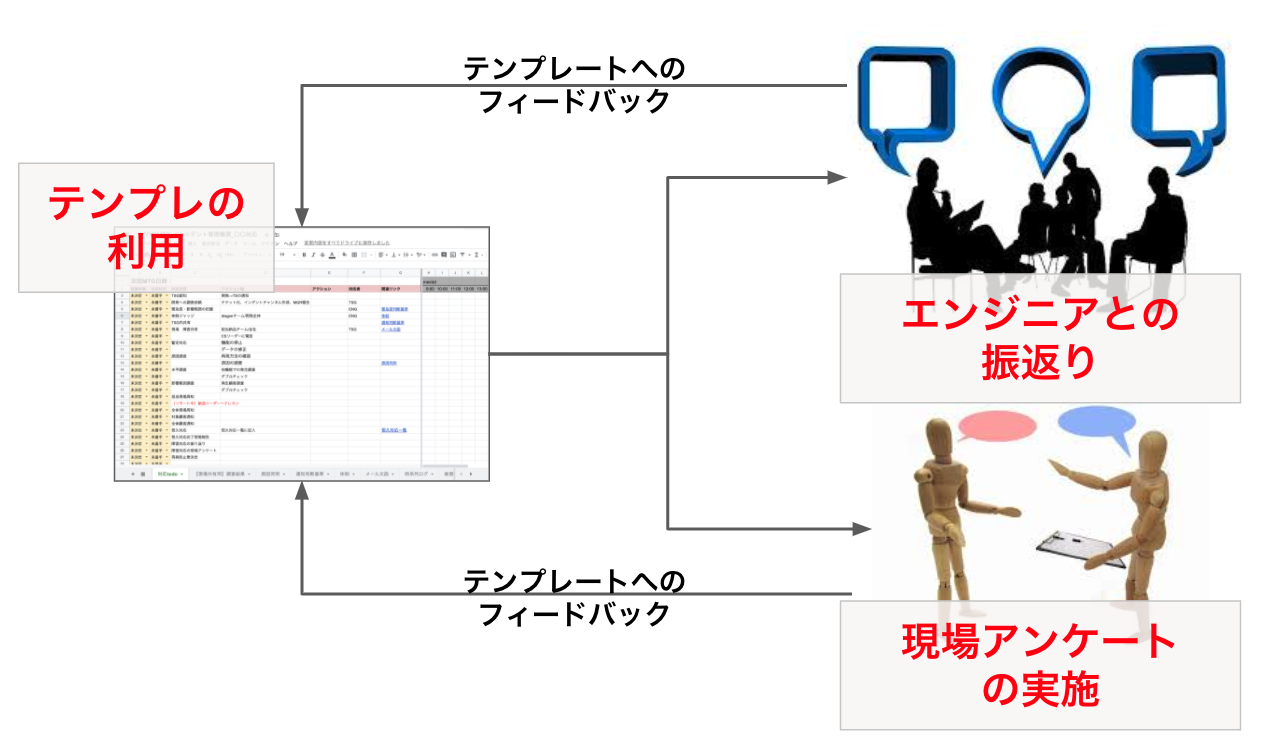
このように、作成した帳票自体を都度アップデートさせていくことで、インシデント発生時の対応力を属人化させず、チームとして向上させていくことが大事だと思っています。
例えばインシデント対応の業務を後輩に引き継いだ時に、この管理帳票の内容を伝え、またアップデートさせていくことを行ってもらうだけで、組織として継続的に対応力が上がっていくような状態が理想的だと思っています。
おわりに
上記が、私が意識しているインシデント対応のポイントです。
何か他のポイント等ありましたら、是非コメントをよろしくお願いします。
ここまでお読みいただき、ありがとうございました!!