はじめに
正直正しく出来るかは、わかりませんが現場の開発者からは度重なる修正の度にdostringを修正したり、設計書のメンテナンスをするのが面倒だしやりたくないという声をお聞きしました。リーダブルコードであれば自動的にdocstringを追加して、そこから自動的に概要設計書を作成出来たら現場のエンジニアが楽になるのでは?という想いから、実証実験をしてみることにしました。
ただしこの実験が成功するかは不明なので途中でポシャる可能性が大です。
実証実験環境
OpenAI ・・・ 無料枠のあるgemini-flashもありますが、一旦はオーソドックスなOpenAIもO4を使います。
Dify ・・・ 特段現段階ではDifyまで必要とは思っていませんが、単に使ってみたかったというので敢えて使っています。無くても大丈夫です。今の所は。
make.com ・・・ 今回のある意味メインですね。最終的にはgithubのリポジトリからdocstringが書いていないコードに対して自動的にコメントを追記して、pull requestを発行するのに使う予定です。
今回行う範囲 - Dify

ソースコードを変数: sourcecodeとして受け取って、4oでdocstringを追加するだけのフローです。
Difyの開始
Difyは、googleやgithubのアカウントでログイン出来ます。好きな方を選んでログインしてください。
https://cloud.dify.ai/signin
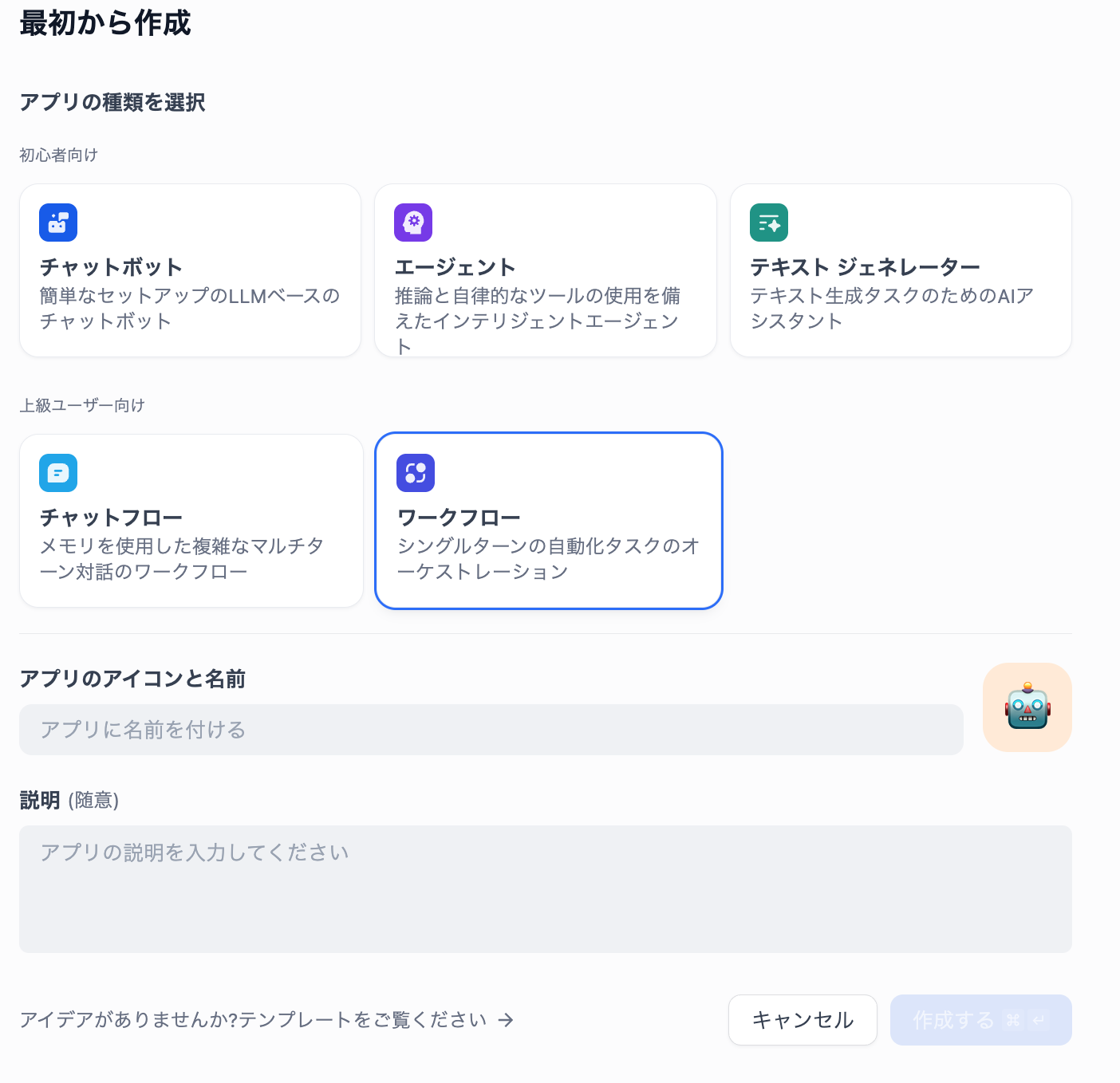
今回は「最初から作成」を選びます。

今回はユーザーとやり取りする事無く自動的に行うので
「ワークフロー」を選択します
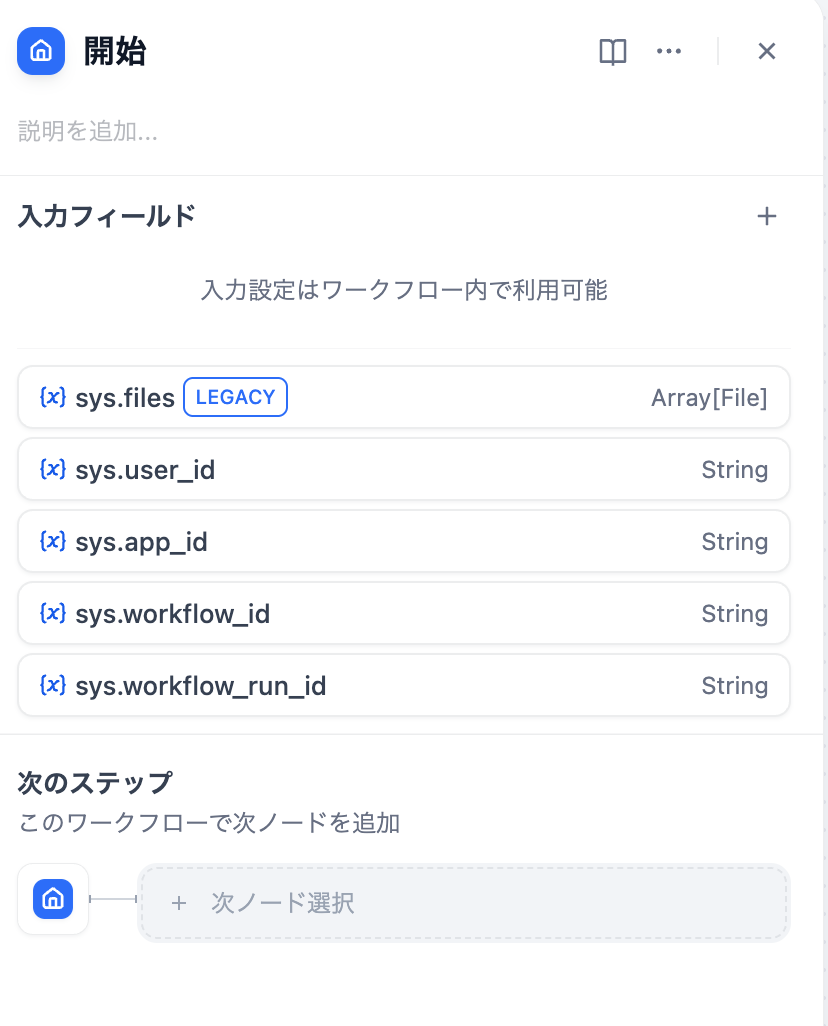
「開始」モジュールの設定
そうすると自動的に「開始」だけが作成されています。

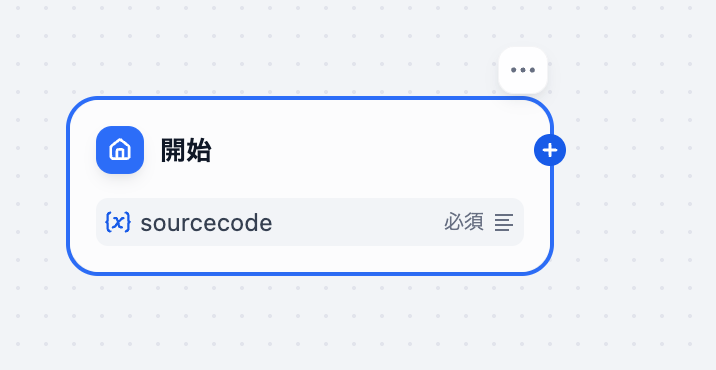
「開始」をクリックすると以下の画面になります。
今回は「入力フィード +」をクリックし、変数sourcecodeを設定します。
ソースコードの長いのがあるので、一旦20000ぐらいにしておきました。
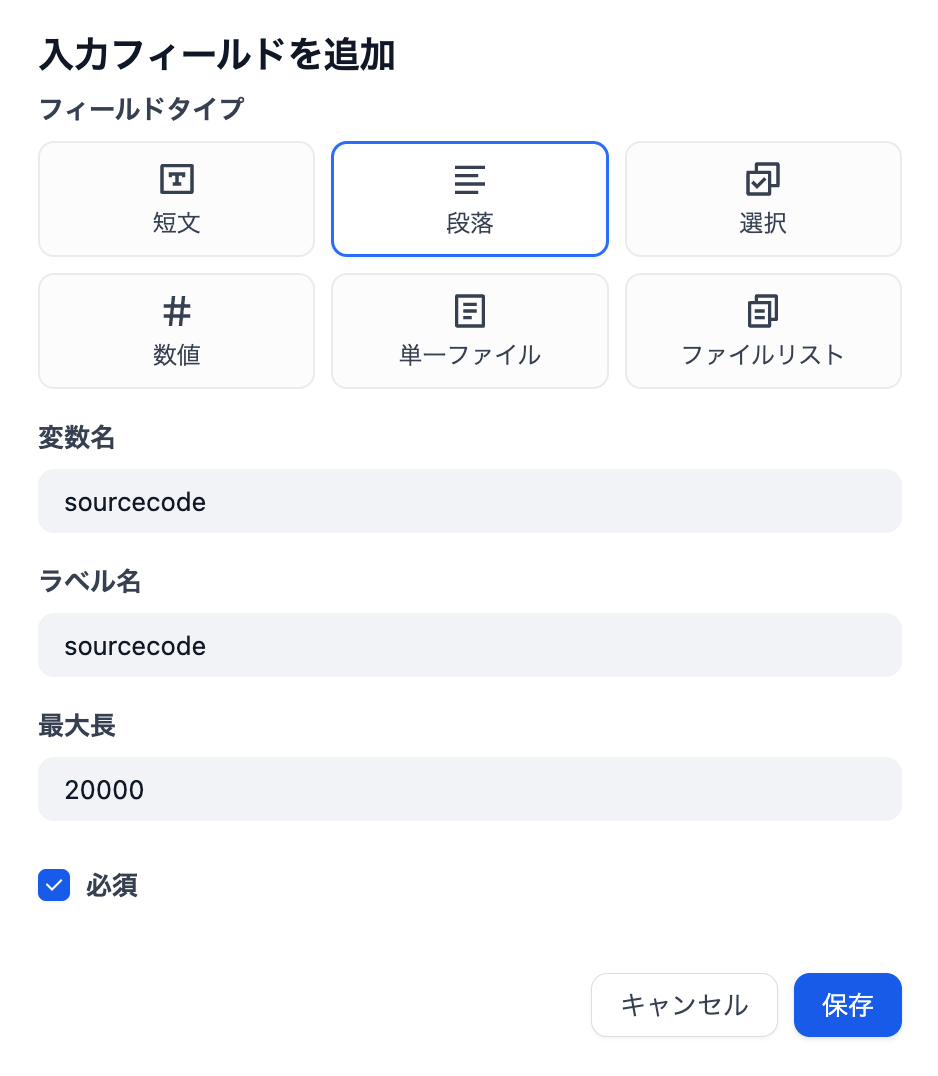
そうすると「開始」モジュールに{x}sourcecodeが表示されていたらオッケーです。
「OpenAI」プラグインの設定
OpenAIのAPIキーの発行は色々な所にドキュメントがあるので割愛します。
APIキーを取得した後にDifyの右上のDアイコンをクリックします。

「設定」を選択し「モデルプロバイダー」を選択します。
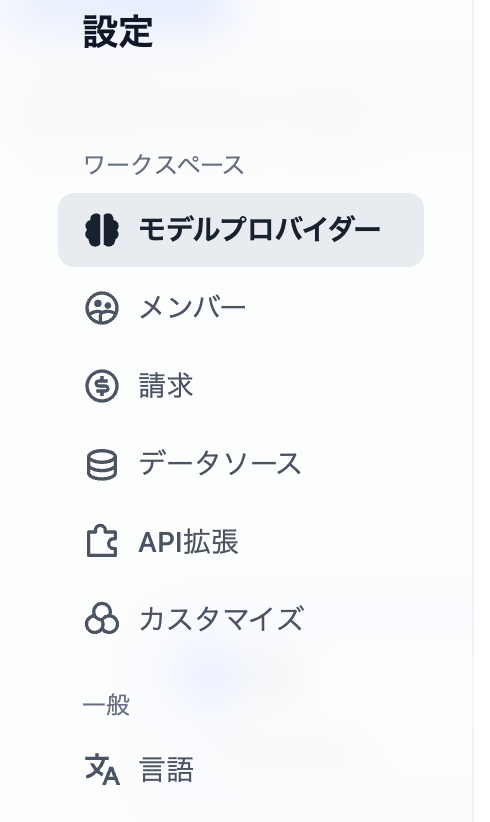
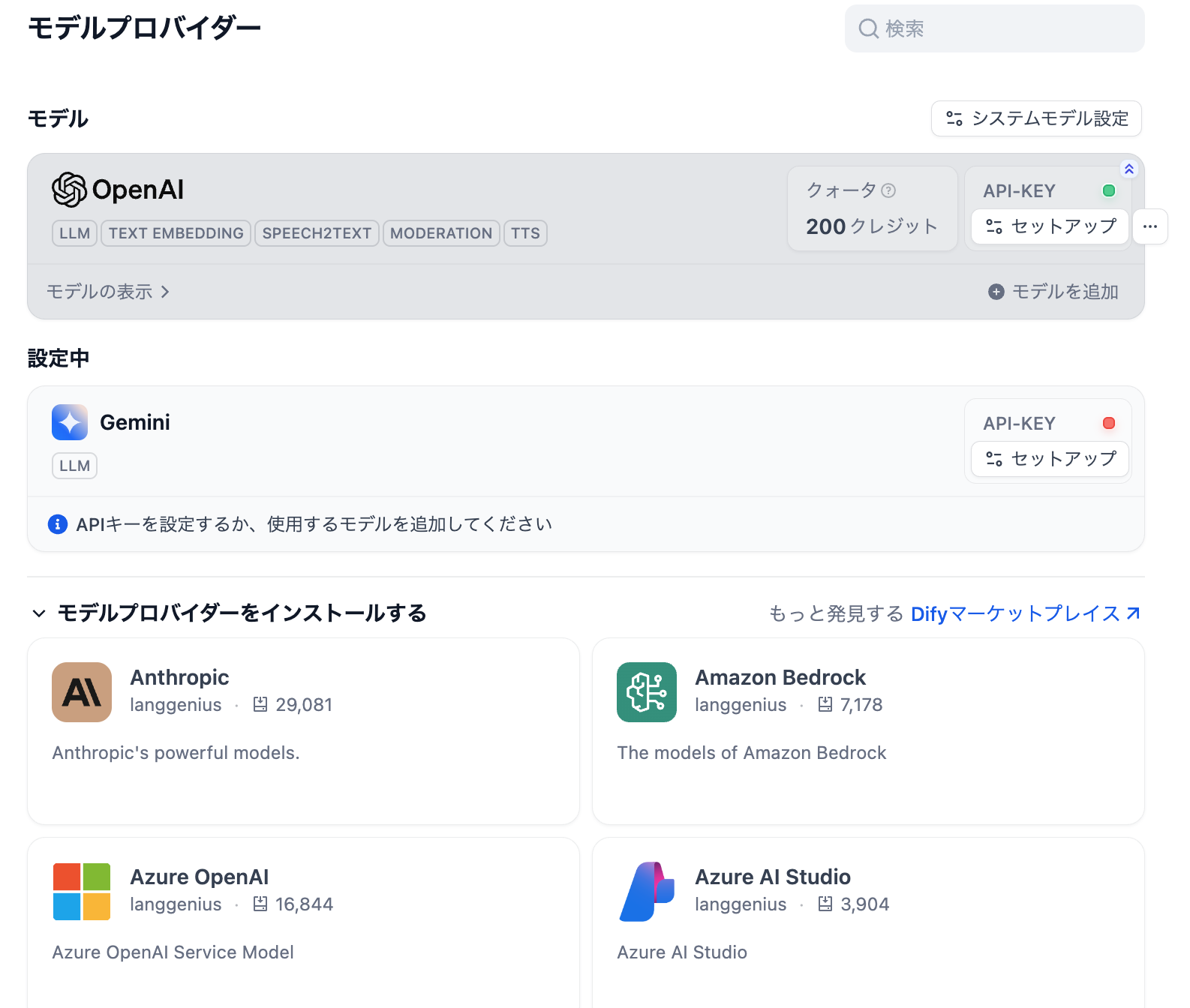
生成AIから使いたいモデルをインストールします。私の場合は既に「OpenAI」と「Gemini」をインストール済です
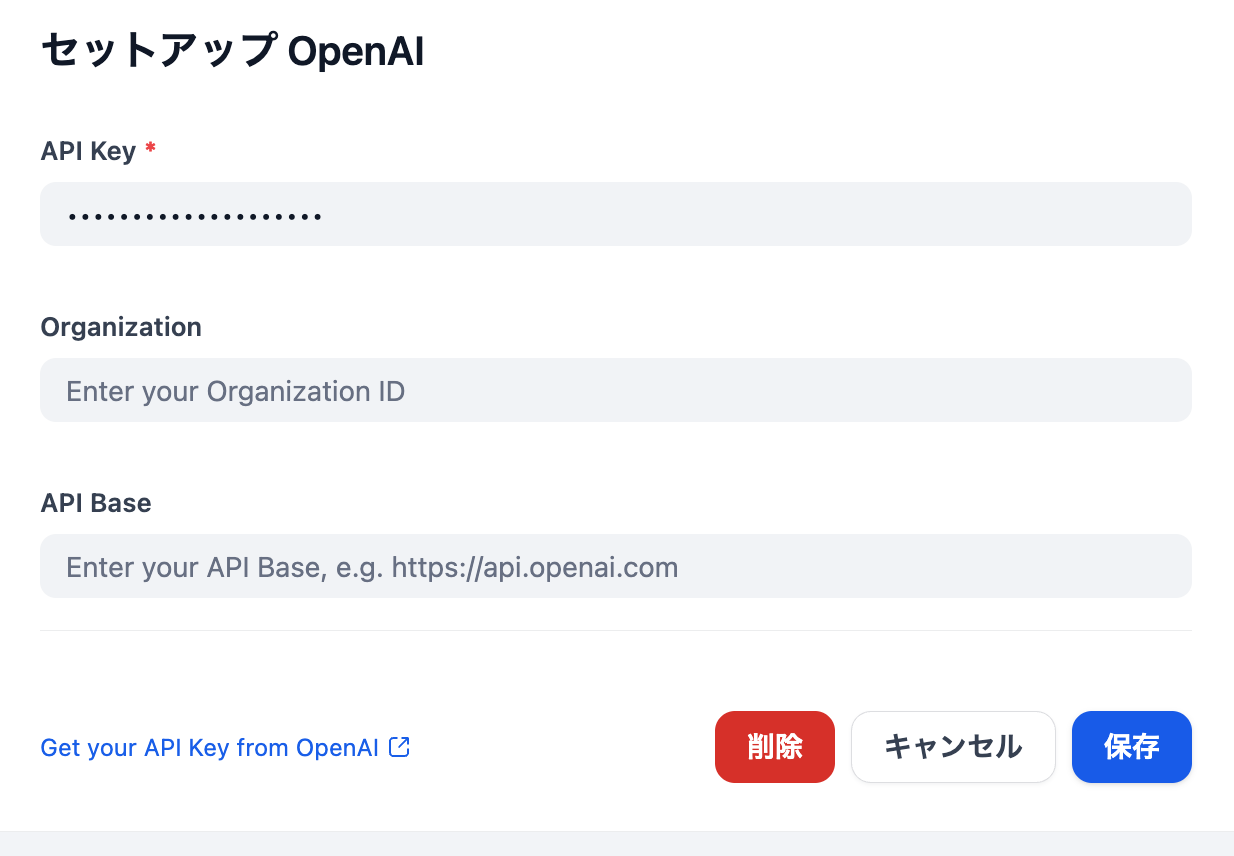
OpenAIの「セットアップ」からAPIキーを入力して保存します。
モデルプロバイダーの画面に戻ったときにAPI-KEYの右がグリーンランプになっていたらOKです
「LLM」モジュールの設定
では、先程の画面に戻ってLLMモジュールを追加します。
画面の上で右クリックから「ブロックの追加」−「LLM」を選択するとLLMモジュールが追加されます
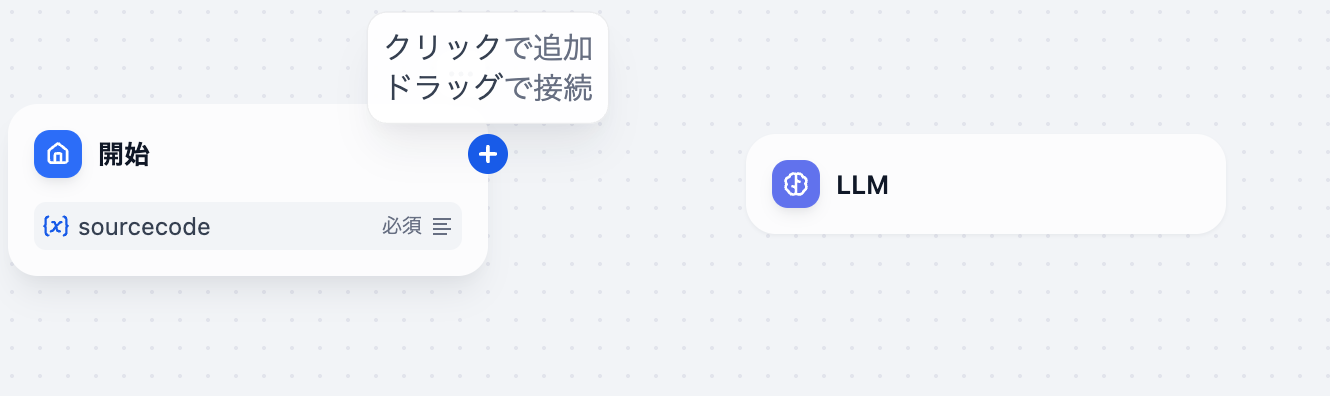
次に「開始」モジュールにカーソルを合わせて+印から「LLM」までドラッグすると結線されます

次にLLMをクリックして以下の設定をしていきます。
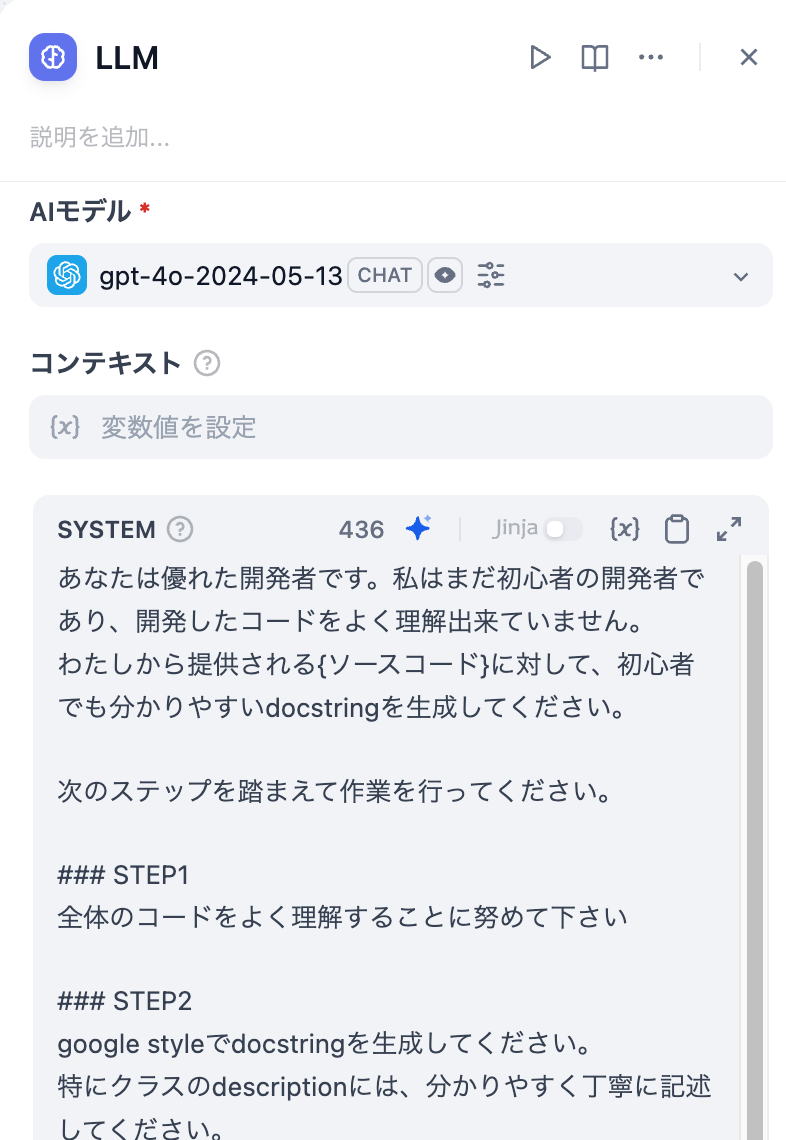
プロンプトはSYTEM,USERの二つを設定します。
あなたは優れた開発者です。私はまだ初心者の開発者であり、開発したコードをよく理解出来ていません。
わたしから提供される{ソースコード}に対して、初心者でも分かりやすいdocstringを生成してください。
次のステップを踏まえて作業を行ってください。
### STEP1
全体のコードをよく理解することに努めて下さい
### STEP2
google styleでdocstringを生成してください。
特にクラスのdescriptionには、分かりやすく丁寧に記述してください。
descriptionは日本語で記述してください。
### STEP3
元のコンテキストと比べてコードを間違って変更していないか確認してください。
変更されていた場合は元のコードに戻してください。
### 制約条件
- コードの修正は禁止です
- docstringはgoogle styleで記述してください
### 出力
- 最終的な出力は、コードとdocstringのみ
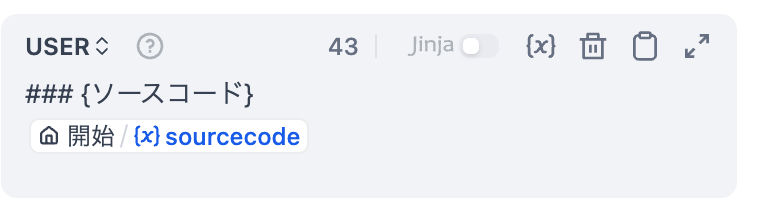
USER側のプロンプトには、変数:sourcecodeを設定します
「終了」モジュールの設定
LLMと終了モジュールも結線してください。
出力変数の値は、LLMモジュールからの出力を指定します。
以上で簡単な設定は終了です。
試しに実行
試しにこちらのパブリックサイトにあるソースで試してみました。
https://github.com/kingwkb/readability/blob/master/readability.py
ざっと見た感じ、上手く言っているようです(精度はまだまだ)
#coding=utf-8
# author: kingwkb
# blog : http://yanghao.org/blog/
#
# this is code demo: http://yanghao.org/tools/readability
from __future__ import division
import os
import sys
import urllib
import urlparse
import re
import HTMLParser
import math
import urlparse
import posixpath
import chardet
from BeautifulSoup import BeautifulSoup
#from bs4 import BeautifulSoup
class Readability:
"""
HTMLコンテンツから主な記事部分を抽出するためのクラスです。
このクラスは、与えられたHTMLの入力と対応するURLを使用して、視覚的に不要な
コンテンツ(広告、コメント、メニューなど)を取り除き、主な記事部分(タイトル
と内容)を抽出します。
Attributes:
regexps (dict): 不要なコンテンツを見分けるための正規表現パターンの辞書。
candidates (dict): 記事候補のノードとそのスコアの辞書。
input (str): 処理対象のHTMLコード。
url (str): 処理対象のページのURL。
html (BeautifulSoup object): 解析済みのBeautifulSoupオブジェクト。
title (str): 抽出された記事のタイトル。
content (str): 抽出された記事のコンテンツ。
"""
regexps = {
'unlikelyCandidates': re.compile("combx|comment|community|disqus|extra|foot|header|menu|"
"remark|rss|shoutbox|sidebar|sponsor|ad-break|agegate|"
"pagination|pager|popup|tweet|twitter",re.I),
'okMaybeItsACandidate': re.compile("and|article|body|column|main|shadow", re.I),
'positive': re.compile("article|body|content|entry|hentry|main|page|pagination|post|text|"
"blog|story",re.I),
'negative': re.compile("combx|comment|com|contact|foot|footer|footnote|masthead|media|"
"meta|outbrain|promo|related|scroll|shoutbox|sidebar|sponsor|"
"shopping|tags|tool|widget", re.I),
'extraneous': re.compile("print|archive|comment|discuss|e[\-]?mail|share|reply|all|login|"
"sign|single",re.I),
'divToPElements': re.compile("<(a|blockquote|dl|div|img|ol|p|pre|table|ul)",re.I),
'replaceBrs': re.compile("(<br[^>]*>[ \n\r\t]*){2,}",re.I),
'replaceFonts': re.compile("<(/?)font[^>]*>",re.I),
'trim': re.compile("^\s+|\s+$",re.I),
'normalize': re.compile("\s{2,}",re.I),
'killBreaks': re.compile("(<br\s*/?>(\s| ?)*)+",re.I),
'videos': re.compile("http://(www\.)?(youtube|vimeo)\.com",re.I),
'skipFootnoteLink': re.compile("^\s*(\[?[a-z0-9]{1,2}\]?|^|edit|citation needed)\s*$",re.I),
'nextLink': re.compile("(next|weiter|continue|>([^\|]|$)|»([^\|]|$))",re.I),
'prevLink': re.compile("(prev|earl|old|new|<|«)",re.I)
}
def __init__(self, input, url):
"""
初期化メソッドです。HTMLコードとURLを使用してReadabilityオブジェクトを初期化します。
使用例::
url = "http://yanghao.org/blog/"
htmlcode = urllib2.urlopen(url).read().decode('utf-8')
readability = Readability(htmlcode, url)
print readability.title
print readability.content
Args:
input (str): 処理対象のHTMLコード。
url (str): 処理対象のページのURL。
"""
self.candidates = {}
self.input = input
self.url = url
self.input = self.regexps['replaceBrs'].sub("</p><p>", self.input)
self.input = self.regexps['replaceFonts'].sub("<\g<1>span>", self.input)
self.html = BeautifulSoup(self.input)
self.removeScript()
self.removeStyle()
self.removeLink()
self.title = self.getArticleTitle()
self.content = self.grabArticle()
def removeScript(self):
"""HTMLからすべての<script>タグを除去します。"""
for elem in self.html.findAll("script"):
elem.extract()
def removeStyle(self):
"""HTMLからすべての<style>タグを除去します。"""
for elem in self.html.findAll("style"):
elem.extract()
def removeLink(self):
"""HTMLからすべての<link>タグを除去します。"""
for elem in self.html.findAll("link"):
elem.extract()
def grabArticle(self):
"""HTMLから記事を抽出します。
Returns:
str: 抽出された記事のHTMLコード。
"""
for elem in self.html.findAll(True):
unlikelyMatchString = elem.get('id', '') + elem.get('class', '')
if self.regexps['unlikelyCandidates'].search(unlikelyMatchString) and \
not self.regexps['okMaybeItsACandidate'].search(unlikelyMatchString) and \
elem.name != 'body':
elem.extract()
continue
if elem.name == 'div':
s = elem.renderContents(encoding=None)
if not self.regexps['divToPElements'].search(s):
elem.name = 'p'
for node in self.html.findAll('p'):
parentNode = node.parent
grandParentNode = parentNode.parent
innerText = node.text
if not parentNode or len(innerText) < 20:
continue
parentHash = hash(str(parentNode))
grandParentHash = hash(str(grandParentNode))
if parentHash not in self.candidates:
self.candidates[parentHash] = self.initializeNode(parentNode)
if grandParentNode and grandParentHash not in self.candidates:
self.candidates[grandParentHash] = self.initializeNode(grandParentNode)
contentScore = 1
contentScore += innerText.count(',')
contentScore += innerText.count(u',')
contentScore += min(math.floor(len(innerText) / 100), 3)
self.candidates[parentHash]['score'] += contentScore
if grandParentNode:
self.candidates[grandParentHash]['score'] += contentScore / 2
topCandidate = None
for key in self.candidates:
self.candidates[key]['score'] = self.candidates[key]['score'] * \
(1 - self.getLinkDensity(self.candidates[key]['node']))
if not topCandidate or self.candidates[key]['score'] > topCandidate['score']:
topCandidate = self.candidates[key]
content = ''
if topCandidate:
content = topCandidate['node']
content = self.cleanArticle(content)
return content
def cleanArticle(self, content):
"""記事のHTMLコードをクリーンアップします。
Args:
content (BeautifulSoup object): クリーンアップ対象のHTMLコンテンツ。
Returns:
str: クリーンアップ後の記事のHTMLコード。
"""
self.cleanStyle(content)
self.clean(content, 'h1')
self.clean(content, 'object')
self.cleanConditionally(content, "form")
if len(content.findAll('h2')) == 1:
self.clean(content, 'h2')
self.clean(content, 'iframe')
self.cleanConditionally(content, "table")
self.cleanConditionally(content, "ul")
self.cleanConditionally(content, "div")
self.fixImagesPath(content)
content = content.renderContents(encoding=None)
content = self.regexps['killBreaks'].sub("<br />", content)
return content
def clean(self, e, tag):
"""特定のタグを含む要素をHTMLから除去します。
Args:
e (BeautifulSoup object): クリーンアップ対象のHTMLコンテンツ。
tag (str): 除去対象のタグ名。
"""
targetList = e.findAll(tag)
isEmbed = 0
if tag == 'object' or tag == 'embed':
isEmbed = 1
for target in targetList:
attributeValues = ""
for attribute in target.attrs:
attributeValues += target[attribute[0]]
if isEmbed and self.regexps['videos'].search(attributeValues):
continue
if isEmbed and self.regexps['videos'].search(target.renderContents(encoding=None)):
continue
target.extract()
def cleanStyle(self, e):
"""HTML要素からすべてのスタイル、クラス、IDを除去します。
Args:
e (BeautifulSoup object): クリーンアップ対象のHTMLコンテンツ。
"""
for elem in e.findAll(True):
del elem['class']
del elem['id']
del elem['style']
def cleanConditionally(self, e, tag):
"""特定の条件に基づいてHTMLからタグを持つ要素を除去します。
Args:
e (BeautifulSoup object): クリーンアップ対象のHTMLコンテンツ。
tag (str): 除去対象のタグ名。
"""
tagsList = e.findAll(tag)
for node in tagsList:
weight = self.getClassWeight(node)
hashNode = hash(str(node))
if hashNode in self.candidates:
contentScore = self.candidates[hashNode]['score']
else:
contentScore = 0
if weight + contentScore < 0:
node.extract()
else:
p = len(node.findAll("p"))
img = len(node.findAll("img"))
li = len(node.findAll("li")) - 100
input = len(node.findAll("input"))
embedCount = 0
embeds = node.findAll("embed")
for embed in embeds:
if not self.regexps['videos'].search(embed['src']):
embedCount += 1
linkDensity = self.getLinkDensity(node)
contentLength = len(node.text)
toRemove = False
if img > p:
toRemove = True
elif li > p and tag != "ul" and tag != "ol":
toRemove = True
elif input > math.floor(p / 3):
toRemove = True
elif contentLength < 25 and (img == 0 or img > 2):
toRemove = True
elif weight < 25 and linkDensity > 0.2:
toRemove = True
elif weight >= 25 and linkDensity > 0.5:
toRemove = True
elif (embedCount == 1 and contentLength < 35) or embedCount > 1:
toRemove = True
if toRemove:
node.extract()
def getArticleTitle(self):
"""HTMLから記事のタイトルを抽出します。
Returns:
str: 抽出された記事のタイトル。タイトルが見つからない場合は空文字を返します。
"""
title = ''
try:
title = self.html.find('title').text
except:
pass
return title
def initializeNode(self, node):
"""ノードを初期化し、スコアを設定します。
Args:
node (BeautifulSoup object): 初期化対象のノード。
Returns:
dict: スコアとノードを含む辞書。
"""
contentScore = 0
if node.name == 'div':
contentScore += 5
elif node.name == 'blockquote':
contentScore += 3
elif node.name == 'form':
contentScore -= 3
elif node.name == 'th':
contentScore -= 5
contentScore += self.getClassWeight(node)
return {'score': contentScore, 'node': node}
def getClassWeight(self, node):
"""ノードのクラスとIDに基づいて重みを計算します。
Args:
node (BeautifulSoup object): 重み計算対象のノード。
Returns:
int: 計算された重み。
"""
weight = 0
if 'class' in node:
if self.regexps['negative'].search(node['class']):
weight -= 25
if self.regexps['positive'].search(node['class']):
weight += 25
if 'id' in node:
if self.regexps['negative'].search(node['id']):
weight -= 25
if self.regexps['positive'].search(node['id']):
weight += 25
return weight
def getLinkDensity(self, node):
"""ノードのリンク密度を計算します。
Args:
node (BeautifulSoup object): 計算対象のノード。
Returns:
float: 計算されたリンク密度。
"""
links = node.findAll('a')
textLength = len(node.text)
if textLength == 0:
return 0
linkLength = 0
for link in links:
linkLength += len(link.text)
return linkLength / textLength
def fixImagesPath(self, node):
"""画像のパスを修正します。
Args:
node (BeautifulSoup object): 修正対象のノード。
"""
imgs = node.findAll('img')
for img in imgs:
src = img.get('src', None)
if not src:
img.extract()
continue
if 'http://' != src[:7] and 'https://' != src[:8]:
newSrc = urlparse.urljoin(self.url, src)
newSrcArr = urlparse.urlparse(newSrc)
newPath = posixpath.normpath(newSrcArr[2])
newSrc = urlparse.urlunparse((newSrcArr.scheme, newSrcArr.netloc, newPath,
newSrcArr.params, newSrcArr.query, newSrcArr.fragment))
img['src'] = newSrc
さいごに
今回はDify x OpenAI 4oでdocstringを作ってみました。正直docstringに向いているエンジンとは言いがたい4oでもこのぐらいは出来たので、概要設計の作成は期待出来そうです。
次回はこのDifyワークフローを使って、githubのリポジトリから自動的にdocstring生成してみます。