はじめに
この記事は Goodpatch Advent Calendar 2019 の8日目です.
私が所属するグッドパッチでは2019年12月現在、デザイナー志望学生のための就活支援サービス 「ReDesigner for Student」 を開発・運営しています。
「ReDesigner for Student」には学生が作品をアップロードする機能があり、作品を企業や他の学生にシェアすることができます。6月の正式リリース後、しばらくの間画像ファイル形式(jpg, png, gif)のみに対応していましたが、学生からのフィードバックを受け、10月にPDF形式のアップロードに対応しました🎉
PDF形式への対応方法はいくつか考えられましたが、今回はフロント側でPDFを画像ファイルへと変換し、既存の画像アップロードAPIへ送信することにしました。
この記事では、上記を実現する実際のコードをお見せし、その説明をしたいと思います。
必要な仕様
既存の画像APIを用いて画像をアップロードするには、inputタグでファイル読み込みをしたときと同じく、File型の変数になっている必要があります。
入力と出力だけ書くと
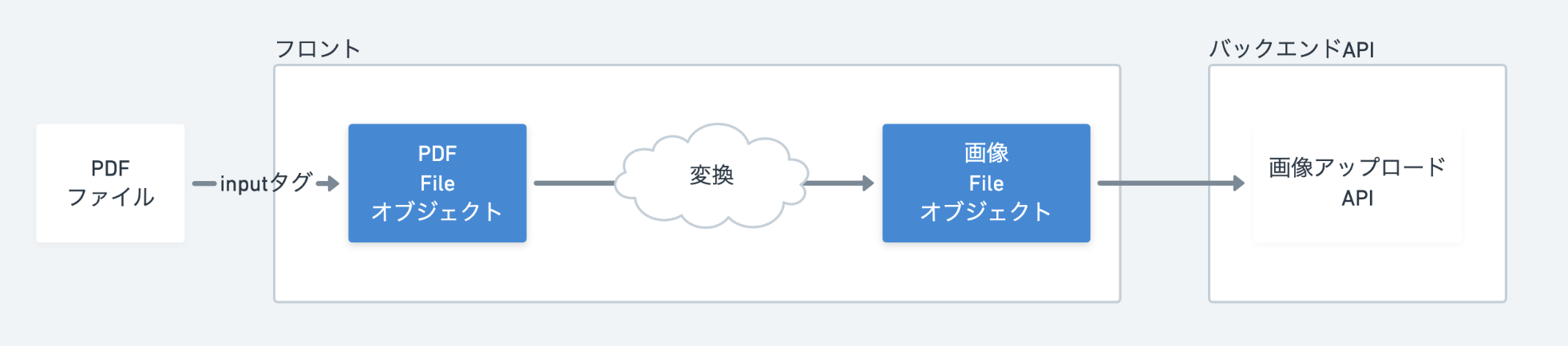
こうなります。
実現方法を調査した結果、以下のような手順で目的が達成できることがわかりました。
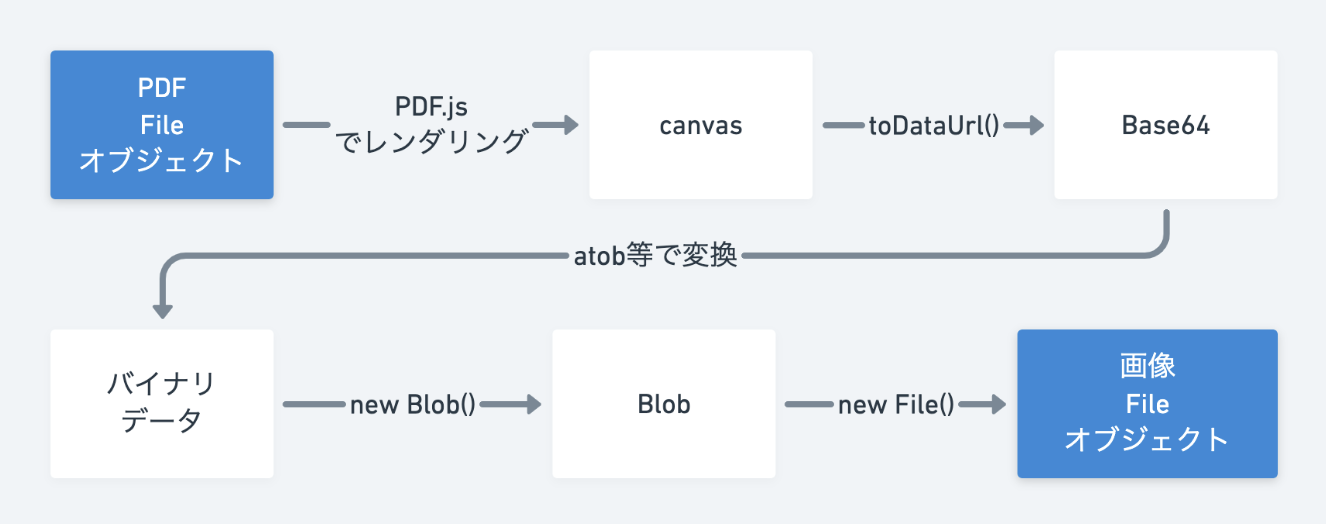
以下、説明のため、上記のデータ変換をNuxt.jsのpageコンポーネント上に実装していきます。
PDF → 画像ファイル 変換手順
PDF.jsについて
PDF をフロントエンド側で変換するために、PDF.jsを利用します。

https://mozilla.github.io/pdf.js/
PDF.js は Mozilla が開発しているJavaScriptライブラリで、PDFファイルのパースやcanvasへのレンダリングを行うことができます。
PDF.jsのインストール
$ npm i -s pdfjs-dist
※ pdfjs という名前のパッケージもあるようなので注意です。
PDFファイルを画像化してアップロードするページコンポーネント
先に最終的なコードを載せておきます。
(説明のため関数を一つにまとめていますが、再利用性や役割の分離のため、外部ファイルで定義すべきです)
<!-- pages/pdf.vue -->
<template>
<div>
<!-- PDFファイル選択 -->
<input
type="file"
accept="application/pdf"
@change.prevent="uploadPdf" />
<!-- レンダリング用canvas -->
<canvas ref="canvas" />
</div>
</template>
<script>
import PDFJS from 'pdfjs-dist'
export default {
methods: {
async uploadPdf(e) {
// PDFファイルデータをArrayBuffer型で取得
const fileData = await this.readFileAsync(e.target.files[0])
// PDFファイルのパース
const pdf = await PDFJS.getDocument({
data: fileData,
cMapUrl: '/cmaps/',
cMapPacked: true,
})
// 1ページ目をcanvasにレンダリング
const page = await pdf.getPage(1)
const canvas = this.$refs.canvas
const viewport = page.getViewport({ scale: 1 })
canvas.height = viewport.height
canvas.width = viewport.width
const context = canvas.getContext('2d')
var task = page.render({
canvasContext: context,
viewport: viewport,
})
await task.promise
// canvasにレンダリングされた画像をファイル化
const base64 = canvas.toDataURL('image/png')
const tmp = base64.split(',')
const data = atob(tmp[1])
const mime = tmp[0].split(':')[1].split(';')[0]
const buf = new Uint8Array(data.length)
for (let i = 0; i < data.length; i++) {
buf[i] = data.charCodeAt(i)
}
const blob = new Blob([buf], { type: mime })
const imageFile = new File([blob], 'image.png', {
lastModified: new Date().getTime(),
})
// multipart/form-data形式でアップロード
// ここはアップロード先のAPIの仕様によって変わります
const formData = new FormData()
formData.append('image_file', imageFile)
await this.$axios.post('APIのエンドポイント', formData)
},
readFileAsync(file) {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = () => {
resolve(reader.result)
}
reader.onerror = reject
reader.readAsArrayBuffer(file)
})
},
},
}
</script>
では細かく説明していきます。
PDFファイルデータをArrayBuffer型で取得
const fileData = await this.readFileAsync(e.target.files[0])
readFileAsync(file) {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = () => {
resolve(reader.result)
}
reader.onerror = reject
reader.(file)
})
},
PDF.jsが必要とする型でデータを取得します。
async/awaitの形式で書きたいので、Callbackで記述する処理をPromiseでラップしています。
PDFファイルのパース
const pdf = await PDFJS.getDocument({
data: fileData,
cMapUrl: '/cmaps/',
cMapPacked: true,
})
PDFファイルデータをパースし、ページ数やサイズなどのデータを取得できるようになります。
ここで重要なのは、cMapUrlとcMapPackedです。
PDFファイルをレンダリングするには、ファイル毎に定められたcmapファイルが必要となります。
しかし、cmapファイルのサイズは重く、1MB越えのものもあり、種類数も多いので、PDF.jsは必要に応じて追加でダウンロードする仕組みになっています。
その際に、PDF.jsが追加ダウンロードするときに参照するパスがcMapUrlであり、そのパスの示すフォルダにcmapファイルが配置されている必要があります。
cmapファイルが入ったcmapsフォルダは、下記のパスに存在します。
node_modules/pdfjs-dist/cmaps/
Nuxtであればこのフォルダを丸ごと static にコピーしてしまうのが手っ取り早いです。
その場合、cmapファイルのURLはhttps://hogehoge.com/cmaps/{cmapファイル名}となるので、サイトルート相対パスを利用して、cMapUrl: '/cmaps/'と設定します。
なお、cmapsファイルの追加ダウンロードはブラウザのCORS制限に引っかかるので、static以外の場所に設置する場合はCORSの設定を行う必要があります。
cmapファイルについては、以下がわかりやすいかと思います。
CMap・cmap(Character Map)
1ページ目をcanvasにレンダリング
const page = await pdf.getPage(1) // 1ページ目を指定
const canvas = this.$refs.canvas
const viewport = page.getViewport({ scale: 1 })
canvas.height = viewport.height
canvas.width = viewport.width
const context = canvas.getContext('2d')
var task = page.render({
canvasContext: context,
viewport: viewport,
})
await task.promise
テスト用に1ページ目だけをcanvasにレンダリングしています。
描画が完了すると最後の行の task.promise が resolve されます。
canvasにレンダリングされた画像をファイル化
const base64 = canvas.toDataURL('image/png')
const tmp = base64.split(',')
const data = atob(tmp[1])
const mime = tmp[0].split(':')[1].split(';')[0]
const buf = new Uint8Array(data.length)
for (let i = 0; i < data.length; i++) {
buf[i] = data.charCodeAt(i)
}
const blob = new Blob([buf], { type: mime })
const imageFile = new File([blob], 'image.png', {
lastModified: new Date().getTime(),
})
canvasからBase64文字列を取得し、それをバイナリデータ → Blob → Fileと変換していきます。
ここまで来れば、画像ファイルをinputタグで読み込んだ時と全く同じ状態になります。あとはこのデータを既存の画像アップロード用APIに投げてあげればOKです!
注意点
サイズの大きなPDFファイルへの対策
利用側が大きなPDFをレンダリングさせようとすると、メモリが不足したり、アップロードできないファイルサイズになる可能性があります。
ページ情報はページ情報を読み込んだときに取得できるので、閾値を設けてこの値以下に倍率を調整すると良いかと思います。
以下は最大幅を決め、それに合わせて全体をサイズ変更させる例です。
const MAX_PORTFOLIO_PDF_IMAGE_WIDTH = 1920
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
const page = await pdf.getPage(1)
let viewport = page.getViewport({ scale: 1 })
if (viewport.width > MAX_PORTFOLIO_PDF_IMAGE_WIDTH) {
const newScale = MAX_PORTFOLIO_PDF_IMAGE_WIDTH / viewport.width
viewport = page.getViewport({ scale: newScale })
}
canvas.height = viewport.height
canvas.width = viewport.width
パスワードつきPDFファイルへの対応
学生向けのサービスのため、パスワードつきPDFはほとんど使われないと考え、パスワードを入力する機能の実装は行わないことにしました。しかし、なぜ読み込めないのか表示することは必要です。
パスワード付きPDFファイルの場合 PDFJS.getDocument() の実行時に PasswordException がthrowされるので、それをcatchしてエラーを通知します。
try{
const pdf = await PDFJS.getDocument({
data: fileData,
cMapUrl: '/cmaps/',
cMapPacked: true,
})
} catch (err) {
if (err instanceof PasswordException) {
alert('パスワード付きPDFは使用できません')
} else {
console.error(err);
}
ファイルサイズについて
PDFが文字やベクター画像で構成されているとき、データ量は画像変換してしまうと増えてしまうため、今回やったような仕組みが適切だとは限りません。サービスごとに適切な仕組みを選択してください。
おわりに
今回紹介した方法を応用して、生成したデータをファイルとしてダウンロードしたり、表示したりなど、サーバーを介さず色々な機能を作ることができます。
PCやスマホの性能が高くなったおかげでフロントエンドでもさまざまな処理ができるようになりました。覚えることが多くて大変ですが、色々できるのは楽しいですね!
それでは!
補足
ちなみに、Vue用に作られたPDF.jsラッパーとして vue-pdf というライブラリがあるのですが、cmapを設定する機能が実装されていないため、使う場合はForkして手直しする必要があります。(もしかしたら200件近くあるvue-pdfのforkの中にcmaps指定対応しているものもあるかもしれませんが、探しておりません ![]() )
)